1.安装centos7.8
1.1 下载centos7.8镜像
下载地址:http://mirrors.aliyun.com/centos/7/isos/x86_64/
1.2 安装centos7.8
创建新的虚拟机
选择自定义—>下一步
点击下一步
点击稍后安装操作系统,然后下一步
选择Linux—>版本选择CentOS 7 64位
设置虚拟机名称以及虚拟机存放位置—>点击下一步
设置处理器数量及处理器的内核数—>点击下一步
设置虚拟机内存,此虚拟机设置为4G,如果宿主机器内存大的话可以适当调整虚拟机内存
选择NAT模式—>下一步
选择LSI Logic—>下一步
选择SCSI—>下一步
选择创建新虚拟机—>下一步
磁盘大小设置为900G—>选择将虚拟磁盘存储为单个文件—>下一步
点击下一步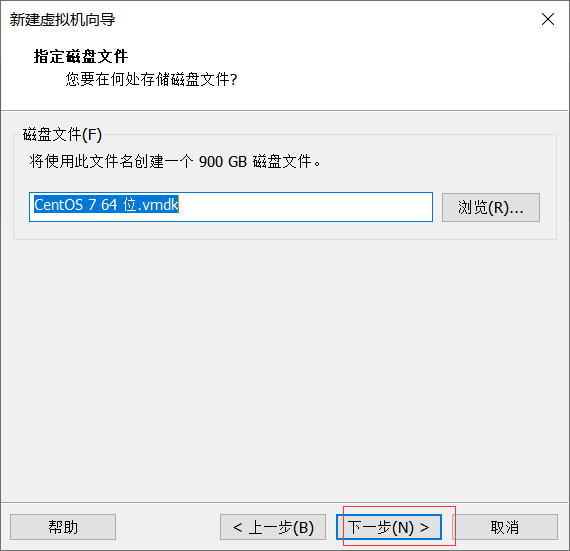
点击完成
编辑虚拟机
选择镜像文件
开启虚拟机
使用键盘上的上箭头↑,移动到Install CentOS 7,然后回车,开始安装CentOS7.5
敲回车
选择English—>continue
设置时区

选择要安装的软件

接下来点击 INSTALLATION DESTINATION 按钮,选择 CentOS 操作系统安装的目标盘:








配置网络,设置静态IP为192.168.200.111






配置LANGUAGE SUPPORT

点击Begin Install
为root设置密码,设置为111111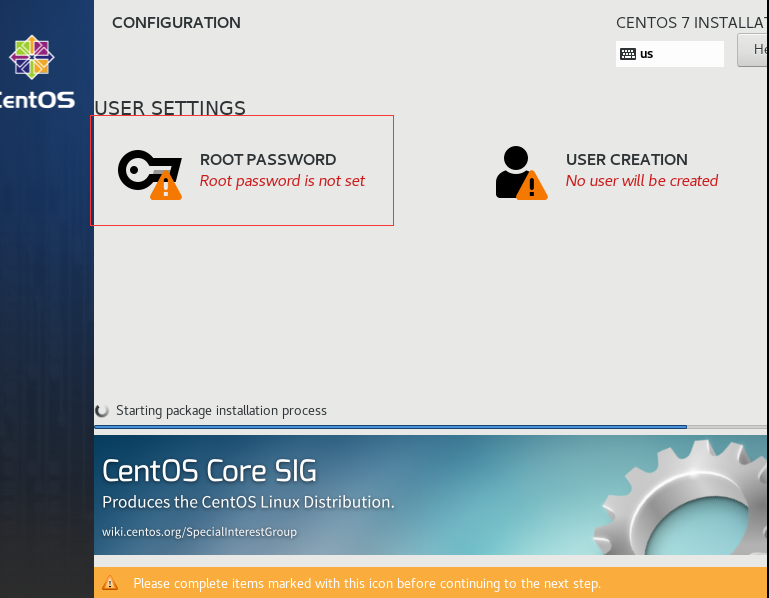

创建hadoop用户,密码也是111111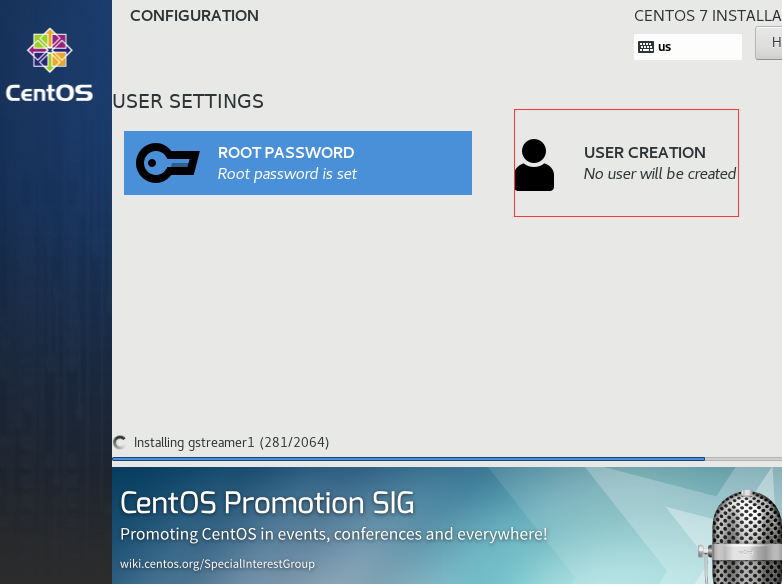

等待安装,直到出现以下界面:
出现如下 INITIAL SETUP 屏幕提示:


点击 FINISH CONFIGURATION 按钮,稍等片刻,等待服务器完成启动:
至此,你安装完了 CentOS 7.5 操作系统。
1.3 使用root用户登录系统
点击not listed


1.4 设置主机名
设置主机名为test
hostnamectl set-hostname test
reboot
hostname配置成功
1.5 配置网卡ip

1.6 配置/etc/hosts文件
cat>>/etc/hosts<
192.168.100.13 test
EOF
1.7 关闭防火墙
停止firewall
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service

关闭SELinux
getenforce
vi /etc/selinux/config
将以下的行
SELINUX=enforcing
修改为
SELINUX=disabled
然后重新启动服务器
reboot
2.配置hadoop用户
创建HADOOP安装目录
mkdir /opt/hadoop-2.7.7
chown -R hadoop.hadoop /opt/hadoop-2.7.7
ln -s /opt/hadoop-2.7.7 /opt/hadoop
chown -R hadoop.hadoop /opt/hadoop
为hadoop用户设置shell限制
To improve the performance of the software on Linux systems, you must increase the shell limits for the hadoop user
1. Add the following lines to the /etc/security/limits.conf file:
cat>>/etc/security/limits.conf<
hadoop hard nproc 16384
hadoop soft nofile 1024
hadoop hard nofile 65536
EOF
_ _
2. Add or edit the following line in the /etc/pam.d/login file, if it does not already exist:
cat>>/etc/pam.d/login<
EOF
配置Hadoop用户的环境文件
su - hadoop
cd
cat > ~hadoop/.bashrc <
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
JAVA_HOME=/usr/jdk
export JAVA_HOME
HADOOP_HOME=/opt/hadoop
export HADOOP_HOME
HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export HADOOP_CONF_DIR
export SPARK_HOME=/opt/spark
PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$SPARK_HOME/bin:\$SPARK_HOME/sbin:\$JAVA_HOME/bin:\$PATH
export PATH
EOF
3.编译Hadoop2.7.7
3.1 编译环境:
CentOS 7.8 x86_64
jdk-8u241-linux-x64.tar.gz
maven3.5.4
protocbuf 2.5.0
3.2 编译前准备:
3.2.1 安装编译hadoop的额外要求包
额外需要安装如下的软件包:
yum -y install gcc gcc-c++ ncurses ncurses-devel bison libgcrypt perl make cmake cmake-gui
yum -y install svn ncurses-devel gcc*
yum -y install lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel
yum -y install gcc-c++ build-essential autoconf automake libtool cmake zlib1g-dev pkg-config libssl-devua svn openssl-devel ncurses-devel
3.2.2 安装Java 8环境
下载Java 8SE
jdk-8u241-linux-x64.tar.gz
安装Java 8SE
cd /root/Desktop/1 #该目录是介质所在目录
tar xvfz jdk-8u241-linux-x64.tar.gz -C /usr
ln -s /usr/jdk1.8.0_241 /usr/jdk
cat>> /etc/profile<<EOF
JAVA_HOME=/usr/jdk
export JAVA_HOME
CLASSPATH=.:\$JAVA_HOME/lib:\$CLASSPATH
export CLASSPATH
PATH=\$JAVA_HOME/bin:\$PATH
export PATH
EOF
source /etc/profile
3.2.3 安装maven
下载:apache-maven-3.6.4-bin.tar.gz
安装
cd /root/Desktop/1 #该目录是介质所在目录
tar xvf apache-maven-3.5.4-bin.tar -C /usr
mv /usr/apache-maven-3.5.4 /usr/maven
将maven镜像仓库替换成阿里云镜像仓库
cd /usr/maven/conf/
vi settings.xml
在
Esc—>wq保存退出
cd /root
mkdir .m2
cp /usr/maven/conf/settings.xml ./.m2/
cat>> /etc/profile<<EOF
MAVEN_HOME=/usr/maven
export MAVEN_HOME
PATH=/usr/maven/bin:\$PATH
export PATH
EOF
source /etc/profile
检查安装是否正确
mvn -version
3.2.4 安装protobuf 2.5.0
下载地址:
http://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz
安装:
cd /root/Desktop/1 #该目录是介质所在目录
tar xvfz protobuf-2.5.0.tar.gz -C /usr
cd /usr/protobuf-2.5.0
./configure
make -j 4
make check
make install
ldconfig
检查安装是否正确(如果能正确显示版本号,则说明安装正确)
protoc —version
3.2.5 安装findbugs
cd /root/Desktop/1 #该目录是介质所在目录
tar xvf findbugs-3.0.1.tar -C /usr
cat>> /etc/profile<
export FINDBUGS_HOME=/usr/findbugs-3.0.1
export PATH=\$PATH:\$FINDBUGS_HOME/bin
EOF
source /etc/profile
findbugs -version
3.2.6 安装Snappy
cd /root/Desktop/1 #该目录是介质所在目录
tar xvfz snappy-1.1.3.tar.gz -C /usr
cd /usr/snappy-1.1.3/
./configure
make -j 4
make install
ldconfig
3.2.7 安装ant
cd /root/Desktop/1 #该目录是介质所在目录
tar xvfz apache-ant-1.9.4-bin.tar.gz -C /usr
cat>> /etc/profile<<EOF
export ANT_HOME=/usr/apache-ant-1.9.4
export PATH=\$ANT_HOME/bin:\$PATH
EOF
source /etc/profile
ant -version
3.3 编译Hadoop 2.7.7
编译之前防止java.lang.OutOfMemoryError:Java heap space堆栈问题,在centos系统执行
export MAVEN_OPTS=”-Xms256m -Xmx512m”
下载hadoop 2.7.7源码,
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
解压缩源代码
cd /root/Desktop/1 #该目录是介质所在目录
tar xvfz hadoop-2.7.7-src.tar.gz -C /usr
在hadoop源码目录下进行编译:
export MAVEN_OPTS=”-Xms256m -Xmx512m”
cd /usr/hadoop-2.7.7-src
mvn package -Pdist,native,docs -DskipTests -Dtar
如果出错,执行如下命令:
mvn clean package -Pdist,native -DskipTests -Dtar -Dsnappy.lib=/usr/local/lib -Dbundle.snappy -Drequire.openssl
直到最后出现BUILD SUCCESS,说明编译成功。
3.4 编译成功后HADOOP安装包的位置
源码目录下 hadoop-dist/target/hadoop-2.7.7.tar.gz
cd hadoop-dist/target/
ls
将hadoop-2.7.7.tar.gz复制到/home/hadoop/Desktop/1 /下
cp hadoop-2.7.7.tar.gz /home/hadoop/Desktop/1 /
4.安装hadoop2.7.7
su - hadoop
用hadoop用户执行如下命令:
cd /home/hadoop/Desktop/1 #该目录是介质所在目录
tar xvfz hadoop-2.7.7.tar.gz -C /opt
5.配置ssh本机无密码登录
以hadoop用户身份,执行如下命令,生成密钥对:
先回到主目录
cd
ssh-keygen -t rsa -P ‘’
点击回车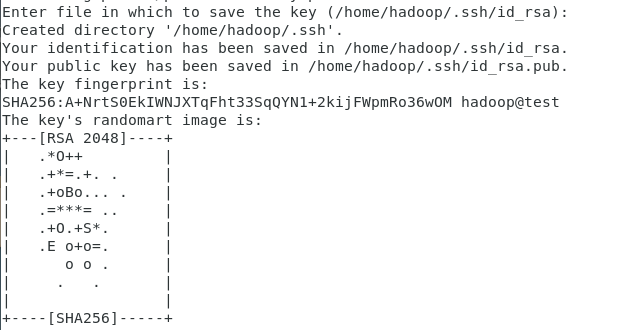
把公钥文件写入授权文件中,并赋值权限,
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
以hadoop用户身份,验证本机的无密码ssh(必须执行以下验证!)
[hadoop@test ~]$ ssh test
[hadoop@test ~]$ ssh localhost
[hadoop@test ~]$ ssh 0.0.0.0
[hadoop@test ~]$ ssh 127.0.0.1
6.配置单节点伪分布式(Pseudo-Distributed)Hadoop环境
配置文件etc/hadoop/core-site.xml
cd /opt/hadoop
vi /opt/hadoop/etc/hadoop/core-site.xml
配置文件etc/hadoop/hdfs-site.xml
cd /opt/hadoop
vi /opt/hadoop/etc/hadoop/hdfs-site.xml
配置文件etc/hadoop/slaves
cd /opt/hadoop
vi /opt/hadoop/etc/hadoop/slaves
test
创建HDFS使用的Linux目录
用hadoop用户创建目录:
mkdir -p /home/hadoop/dfs/name
mkdir -p /home/hadoop/dfs/data
mkdir -p /home/hadoop/dfs/temp
格式化文件系统
hdfs namenode -format
启动HDFS
start-dfs.sh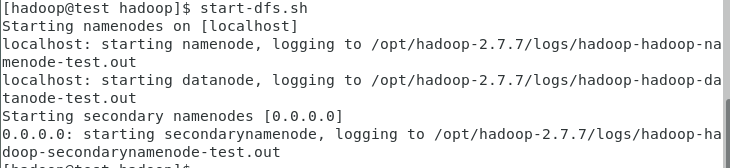
浏览NameNode的web接口jps
http://localhost:50070/

查看HDFS启动后的情况
jps
在HDFS上创建目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
测试
start-yarn.sh
cd /opt/hadoop-2.7.7
hdfs dfs -put etc/hadoop input
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output ‘dfs[a-z.]+’
hdfs dfs -get output output
cat output/
或者
hdfs dfs -cat output/
清除测试数据
rm -rf output
hdfs dfs -rm -r /user/hadoop/input
hdfs dfs -rm -r /user/hadoop/output
HDFS集群管理命令
查看集群状态: hdfs dfsadmin -report
查看文件块组成: hdfs fsck / -files -blocks
停止HDFS
stop-dfs.sh
停止yarn
stop-yarn.sh
7.配置单节点上的YARN
配置文件etc/hadoop/mapred-site.xml
cd /opt/hadoop/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vi /opt/hadoop/etc/hadoop/mapred-site.xml
配置文件etc/hadoop/yarn-site.xml
cd /opt/hadoop
vi etc/hadoop/yarn-site.xml
启动YARN
start-yarn.sh
查看启动后的情况
浏览ResourceManager的web接口
http://localhost:8088/
http://192.168.100.13:8088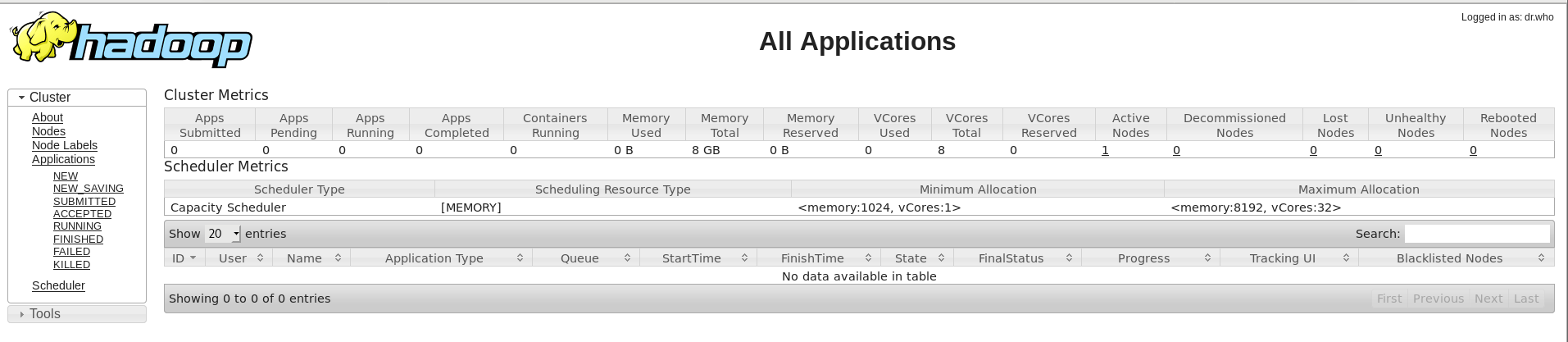
停止YARN
stop-yarn.sh
8.测试:运行示例程序
测试前要启动HDFS和YARN!
start-dfs.sh
start-yarn.sh
jps
8.1 查看可用的实例列表
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar ./hadoop-mapreduce-examples-2.7.7.jar 
8.2例子1 计算PI
运行带有2个map和10000000个样本的pi实例
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar ./hadoop-mapreduce-examples-2.7.7.jar pi 2 10000000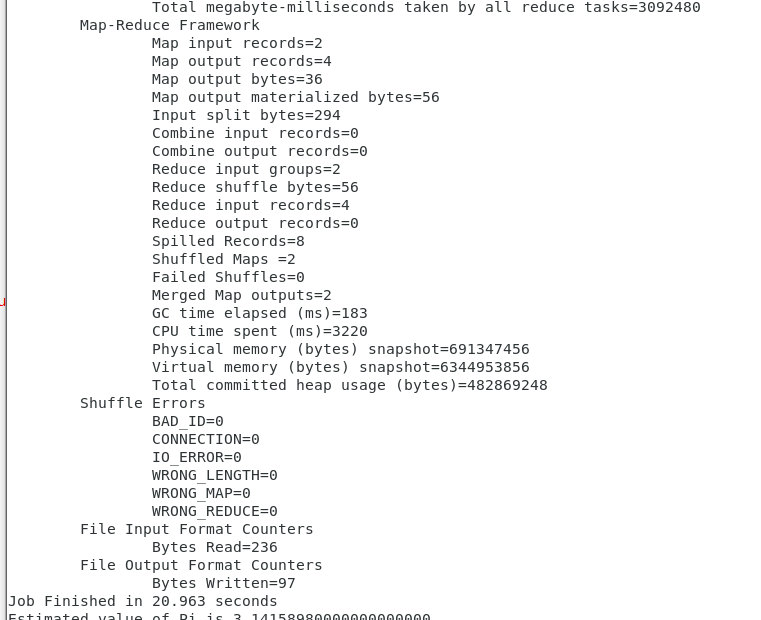
使用Web GUI监控实例
http://192.168.100.13:8088/
8.3例子2 运行Terasort测试
1)运行teragen生成随机数据进行排序
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.7.7.jar teragen 10000 /user/terasort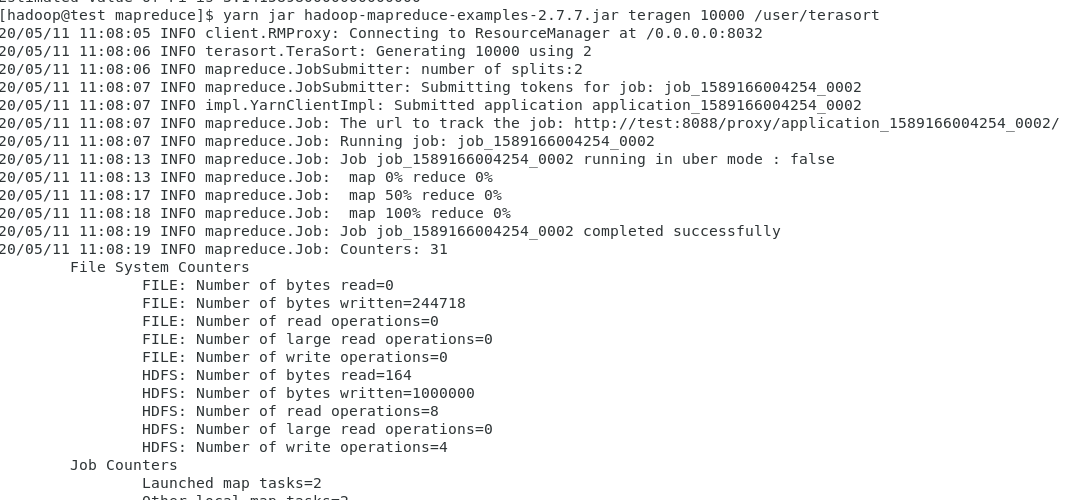
10000表示10000KB=10MB
再次实验需要删除/user/terasort
hdfs dfs -ls /user
hdfs dfs -rm -r /user/terasort
====
(如果你的机器I/O快的话,将命令修改为如下)
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.7.7.jar teragen 100000000 /user/terasort
====
2)运行terasort对数据进行排序
创建结果目录
hdfs dfs -mkdir /user/terasortResult
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.7.7.jar terasort \
/user/terasort /user/terasortResult
3)验证排序后的teragen
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-examples-2.7.7.jar teravalidate \
/user/terasortResult /user/terasortvalidate
4)删除测试用目录
hdfs dfs -rm -r /user/terasort
hdfs dfs -rm -r /user/terasortResult
hdfs dfs -rm -r /user/terasortvalidate
8.4例子3 DFS IO基准测试
在写模式下运行名为TestDFSIO的HDFS基准测试应用程序:
运行带有2个128MB文件
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-client-jobclient-2.7.7-tests.jar TestDFSIO \
-write -nrFiles 2 -fileSize 128
在读模式下运行TestDFSIO
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-client-jobclient-2.7.7-tests.jar TestDFSIO \
-read -nrFiles 2 -fileSize 128
清理刚才的数据
cd /opt/hadoop/share/hadoop/mapreduce
yarn jar hadoop-mapreduce-client-jobclient-2.7.7-tests.jar TestDFSIO \
-clean
9.Hadoop Eclipse开发环境安装
9.1前提条件
已经安装配置单节点伪分布式(Pseudo-Distributed)Hadoop 2.7.7环境
9.2编译hadoop eclipse插件
参考:https://www.yuque.com/duyanyao/bn83p9/wua2t7
现在直接使用编译好的插件
9.3安装Eclipse上的Hadoop插件
cd /home/hadoop/Desktop/1/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin
cp hadoop-eclipse-plugin-2.7.7.jar /opt/eclipse/plugins
9.4配置hadoop用户的eclipse环境变量
cd
cat > ~hadoop/.bashrc <
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
JAVA_HOME=/usr/jdk
export JAVA_HOME
HADOOP_HOME=/opt/hadoop
export HADOOP_HOME
HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export HADOOP_CONF_DIR
HBASE_HOME=/opt/hbase
export HBASE_HOME
ECLIPSE_HOME=/opt/eclipse
export ECLIPSE_HOME
PATH=\$ECLIPSE_HOME/:\$HBASE_HOME/bin:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$JAVA_HOME/bin:\$PATH
export PATH
EOF
9.5启动并配置Eclipse for Hadoop
查看eclipse版本
打开/opt/eclipse/readme目录


eclipse版本是4.7.0。
eclipse3.5以前:_hadoop-eclipse-plugin-2.7.3.jar存放到/plugins目录
_eclipse3.5及以后版本:_hadoop-eclipse-plugin-2.7.3.jar存放到/dropins目录_
执行以下操作:
cd /home/hadoop/Desktop/1/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin
cp hadoop-eclipse-plugin-2.7.7.jar /opt/eclipse/dropins/
eclipse安装结束后,先退出hadoop用户,重新用hadoop用户登录Linux,然后再执行下面的命令,重新启动eclipse。
目前命令行启动出错
/opt/eclipse/eclipse
找到/opt/eclipse/eclipse打开
启动eclipse后可以开始配置Hadoop编程环境:











10.调试运行hadoop的第一个示例程序WordCount
启动eclipse
用hadoop用户运行如下命令:
eclipse
勾选Use this as the default and do not ask again,这样以后再启动eclipse时就不会再出现该窗口!
启动hadoop
使用hadoop用户执行
start-dfs.sh
start-yarn.sh
jps
创建一个TestWordCount项目


创建一个com.dyy.wordcount包和**WordMapper类
 **
**
WordMapper类代码:
package com.dyy.wordcount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 创建一个 WordMapper类 继承于 Mapper抽象类
public class WordMapper extends Mapper<Object, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// Mapper抽象类的核心方法,三个参数
public void map(Object key, // 首字符偏移量
Text value, // 文件的一行内容
Context context) // Mapper端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens())
{
word.set(itr.nextToken());
context.write(word, one);
}
}
}
创建一个WordReducer类**
package com.dyy.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// 创建一个 WordReducer类 继承于 Reducer抽象类
public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
private IntWritable result = new IntWritable(); // 用于记录 key 的最终的词频数
// Reducer抽象类的核心方法,三个参数
public void reduce(Text key, // Map端 输出的 key 值
Iterable<IntWritable> values, // Map端 输出的 Value 集合(相同key的集合)
Context context) // Reduce 端的上下文,与 OutputCollector 和 Reporter 的功能类似
throws IOException, InterruptedException
{
int sum = 0;
for (IntWritable val : values) // 遍历 values集合,并把值相加
{
sum += val.get();
}
result.set(sum); // 得到最终词频数
context.write(key, result); // 写入结果
}
}
创建一个WordMain类
package com.dyy.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain
{
public static void main(String[] args) throws Exception
{
// Configuration类:读取Hadoop的配置文件,如 site-core.xml...;
// 也可用set方法重新设置(会覆盖):conf.set("fs.default.name", "hdfs://xxxx:9000")
Configuration conf = new Configuration();
// 将命令行中参数自动设置到变量conf中
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/**
* 这里必须有输入输出
*/
if (otherArgs.length != 2)
{
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf); // 新建一个 job,传入配置信息
job.setJarByClass(WordMain.class); // 设置 job 的主类
job.setMapperClass(WordMapper.class); // 设置 job 的 Mapper 类
job.setCombinerClass(WordReducer.class); // 设置 job 的 作业合成类
job.setReducerClass(WordReducer.class); // 设置 job 的 Reducer 类
job.setOutputKeyClass(Text.class); // 设置 job 输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置 job 输出值类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // 文件输入
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // 文件输出
System.exit(job.waitForCompletion(true) ? 0 : 1); // 等待完成退出
}
}
将源代码导出为wordcount.jar文件



运行wordcount.jar
cat >file1.txt<
mapreduce is very good
EOF
cat >file2.txt<
mapreduce is very good
EOF
cat >file3.txt<
mapreduce is very good
EOF
在HDFS上创建运行需要的目录
hdfs dfs -rm -r /user/hadoop/input
hdfs dfs -rm -r /user/hadoop/output
hdfs dfs -mkdir /user/hadoop/input
将要处理的数据拷贝到HDFS中
hdfs dfs -put file.txt /user/hadoop/input
运行wordcount程序
hdfs dfs -rm -r /user/hadoop/output
hadoop jar wordcount.jar \
/user/hadoop/input/file /user/hadoop/output
====
hdfs dfs -rm -r /user/hadoop/output
yarn jar wordcount.jar \
/user/hadoop/input/file* /user/hadoop/output
查看运行结果
错误:
Could not resolve host: mirrorlist.centos.org; Unknown error
没联网,联网解决
IP字段错了,应该是192.168.100.11 设置成了192.168.200.11
https://serverfault.com/questions/904304/could-not-resolve-host-mirrorlist-centos-org-centos-7
https://blog.csdn.net/daiyudong2020/article/details/54784172
https://blog.csdn.net/liujianfei526/article/details/45936739
ls: Call From test/192.168.100.13 to localhost:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
tar: Error is not recoverable: exiting now
https://blog.csdn.net/cp_panda_5/article/details/79192688
[hadoop@test eclipse]$ ./eclipse
Eclipse: Cannot open display:
org.eclipse.m2e.logback.configuration: The org.eclipse.m2e.logback.configuration bundle was activated before the state location was initialized. Will retry after the state location is initialized.
Eclipse: Cannot open display:
Eclipse:
An error has occurred. See the log file
/opt/eclipse/configuration/1589428254648.log.
hadoop+eclipse在/plugin目录导入hadoop-eclipse-plugin-2.7.7.jar插件无法识别插件问题
https://blog.csdn.net/qq_14809913/article/details/81705273

报错:An internal error occurred during: “Connecting to DFS MyHadoopDevelop”. org/apache/htrace/SamplerBuilder
解决:重新编译插件
org.eclipse.swt.SWTError: No more handles [gtk_init_check() failed]
at org.eclipse.swt.SWT.error(SWT.java:4559)
at org.eclipse.swt.widgets.Display.createDisplay(Display.java:955)
at org.eclipse.swt.widgets.Display.create(Display.java:942)
解决:重启虚拟机

若有收获,就点个赞吧
0 人点赞
