- HTTP 协议基于底层的 TCP/IP 协议,所以必须要用 IP 地址建立连接;
- 如果不知道 IP 地址,就要用 DNS 协议去解析得到 IP 地址,否则就会连接失败;
- 建立 TCP 连接后会顺序收发数据,请求方和应答方都必须依据 HTTP 规范构建和解析报文;
- 为了减少响应时间,整个过程中的每一个环节都会有缓存,能够实现“短路”操作;
- 虽然现实中的 HTTP 传输过程非常复杂,但理论上仍然可以简化成实验里的“两点”模型。
思考:解释一下在浏览器里点击页面链接后发生了哪些事情吗?
https://mp.weixin.qq.com/s/nMlZWZO6foRUPFK34ouPhg
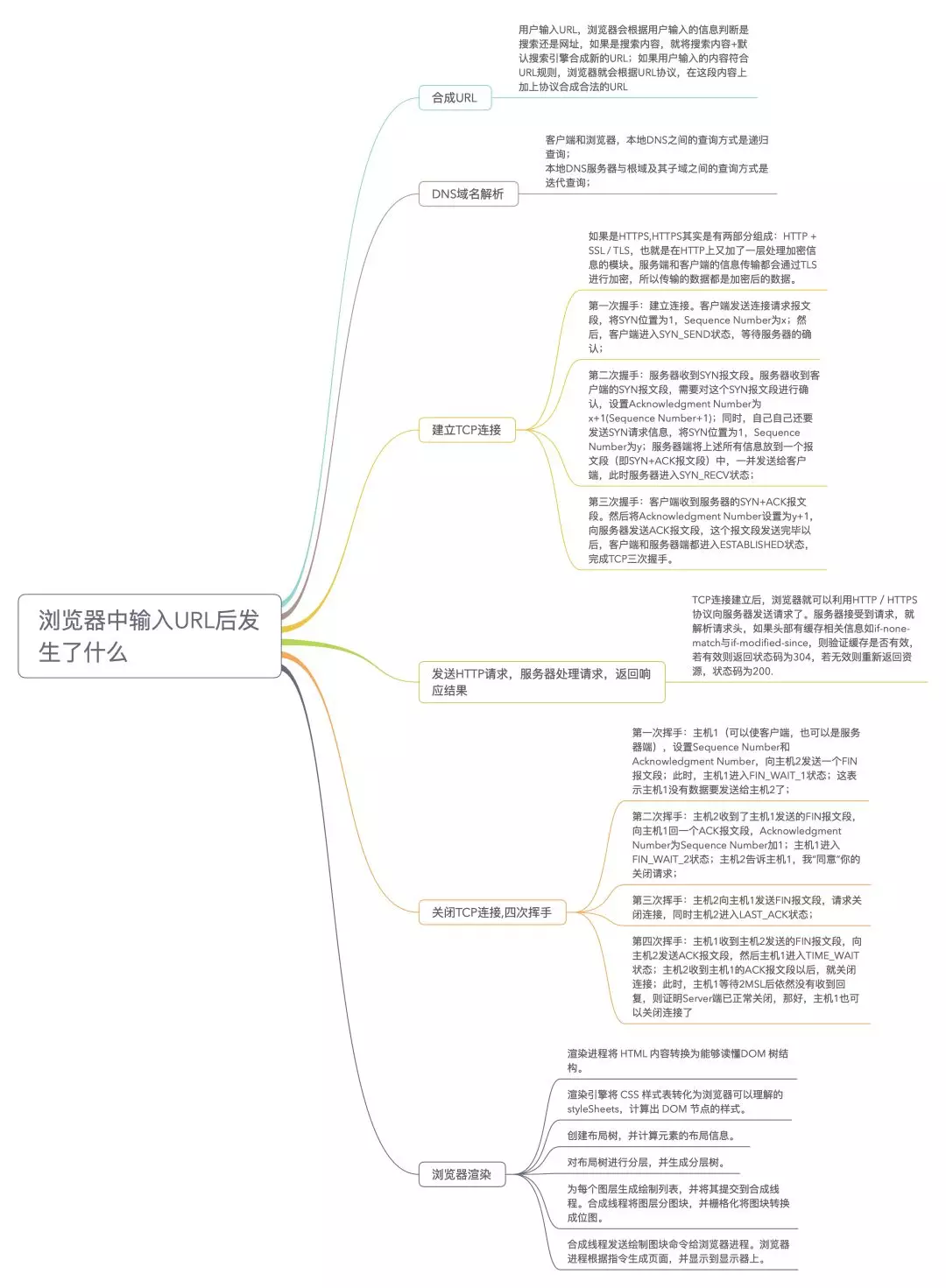
1、如果域名不是ip,需要走域名解析成ip的逻辑,优先级顺序为: 1 浏览器缓存 > 2 系统缓存 > 3 本地hosts >4 根域名 > 5 顶级dns服务器(如 com) > 6 二级dns服务器(baidu.com) > 7 三级dns服务器(www.baidu.com),如果客户端指向的dns服务器为非官方的如 8.8.8.8,那在第4步之前可能还有一层cache,当然最后解析的ip有可能是cdn的,如果cdn失效了就直接穿透到源ip,当然这个服务器这一部分可能做了四层负载均衡的设置,所以有可能每次获取的服务器ip都不一祥,也有可能到了服务器ngx层做了七层转发,所以虽然获得的ip一样,但是内部可能转发给了很多内网服务器
2、通过中间各种路由器的转发,找到了最终服务器,进行tcp三次握手,数据请求,请求分两种一种是uri请求,一种是浏览器咸吃萝卜淡操心的请求网站图标ico的资源请求,然后服务端收到请求后进行请求分析,最终返回http报文,再通过tcp这个连接隧道返回给用户端,用户端收到后再告诉服务端已经收到结果的信号(ack),然后客户端有一套解析规则,如果是html,可能还有额外的外部连接请求,是跟刚才的请求流程是同理的(假设是http1.1),只不过没有了tcp三次握手的过程,最终用户看到了百度的搜索页面。当然如果dns没解析成功,浏览器直接就报错了,不会继续请求接下来的资源

若有收获,就点个赞吧
0 人点赞
