Node.js
https://github.com/smallC-L-Y/Demo/blob/notes/nodeJS%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0.md
https://github.com/SunGodAppollo/node.js/tree/learn
如何通过饿了么 Node.js 面试 https://github.com/ElemeFE/node-interview/tree/master/sections/zh-cn
- nodejs,只是一个js运行时环境,解析和执行js代码,让js可以脱离浏览器来运行,
- node.js中的js没有BOM、DOM只是为js提供了一些操作浏览器级别的API,例如文件的读写、网络服务的构建、网络通信、http服务器
一、nodejs的特点
事件驱动
在前端为Ajax请求绑定success时间,在发出请求后,只需要在请求成功时执行相应的业务逻辑即可。
非阻塞IO模型(异步调用)
绝大多数的操作都是以异步的方式进行调用,每个调用之间不用等待之前的I/O调用结束,如网路请求,读取文件。
单线程
保持了js在浏览器中单线程的特点
好处:
不用想多线程那样处处在意状态的同步问题,没有死锁,不用创建多个线程,没有线程切换带来的性能开销。
缺点:
- 无法利用多核CPU(Node提供了child_process模块,来实现进程的复制)
- 错误会引起整个应用的退出。
- 大量计算占用CPU导致无法继续调用异步I/O
Node采用WebWorker思路解决单线程中的大计算量问题:child_process,子进程。
通过将计算分发到各个子进程,然后再通过进程之间的事件消息来传递结果。通过Master-Worker的管理方式,很好的管理各个工作进程。
面试题:
二、Nodejs的简单应用:
1.读写文件
//读文件
var fs = require('fs')//读文件fs.readFile('./hello2.txt',*function* (*err*,*data*) {//成功if(data){console.log(data.toString())}//失败if(err) {console.log('读取文件失败')}})*//写文件*fs.writeFile('./hello1.txt',"大家好,我是nodejs",*function* (*err*) {console.log('文件写入成功')})
2.简单的http请求
需要引入http核心模块,使用 http.createServer() 方法创建一个web服务器 ,返回一个server实例,服务器需要接收请求,处理响应数据。
// 1.加载http核心模块**var* http = require('http')*//2.使用http.createServer() 方法创建一个web服务器 返回一个server实例**var* server = http.createServer()*//3.服务器接收请求 处理请求 响应数据**//当客户端请求过来,就会自动触发服务器的request请求事件 ,然后执行回调函数*server.on('request',*function* () {console.log('收到客户端的请求了')})*//4,绑定端口号,启动服务器*server.listen(3000,*function* () {console.log('服务器启动成功了,可以通过http://127.0.0.1:3000来访问一下')})
3.http响应请求
var http = require('http')var server = http.createServer()// request 请求事件处理函数,需要接收两个参数*// Request 请求对象 获取客户端的请求信息*// Response 响应对象 给客户端发送响应数据 有三个重要函数,用于返回响应头、响应内容,以及结束请求。server.on('request',*function* (*Request*,*Response*) {console.log('收到客户端的请求了,请求路径是:' + Request.url)//1. writeHead 设置状态码 设置响应数据类型response.writeHead(200, {'content-type':'text/plain;charset=utf-8'})//2.write Response 对象有一个方法:write,可以用来给客户端发送响应数据 可以使用多次,但是最后一定要用end来结束响应,否则客户端会一直等待Response.write('hello')Response.write('nodejs')//3. 结束响应 必须被调用一次,如果不调用,客户端将永远处于等待状态。Response.end()})//关闭服务器server.on('close', ()=>{console.log('服务器关闭成功')})server.close() // 底层相当于调用了 server.emit('close')server.listen(3000,*function* () {console.log('服务器启动成功了,可以通过http://127.0.0.1:3000来访问一下')})
Get方式获取请求参数
get请求请求参数直接嵌套在路径中,而url属性是完整的请求路径,因此可以手动解析url获得请求参数。Nodejs的url模块中parse函数就提供了这个功能。
const http = require('http')const url = require('url')const serve = http.createServer((req,res) =>{let params = url.parse(req.url, true)console.log(params) // 解析后的参数console.log(params.query) // 请求参数res.end('Get')})serve.listen(8088, ()=>{console.log('running...')})
Post方式获取请求参数
post请求参数不在路径 url上,而是通过请求体传递的。但是 http 并没有一个属性内容是请求体,原因是等待请求体传输可能是一件耗时的工作,比如,上传文件。而很多时候并不需要例会请求体的内容,恶意的POST请求会消耗服务器资源,所以nodejs不会解析请求体的。我们可以借助querystring模块进行参数解析
const http = require('http')const url = require('url')const querysrting = require('querystring')const serve = http.createServer((req,res)=>{let params = ''req.on('data', (chunk) =>{ //当有data传过来的时候就会触发data事件,对参数进行拼接params += chunk})req.on('end', () =>{console.log(querysrting.parse(params)) // 使用querysrting模块将字符串转成js对象})})serve.listen(8088, ()=>{console.log('running...')})
4.路径分发
根据不同的请求路径,做不同的响应处理。
首先要获取请求路径, req.url获取到的就是端口号之后的那一部分路径,然后根据不同的路径返回不同的内容
*const* http = require('http')*const* server = http.createServer()server.on('request', *function* (*req*,*res*) {console.log('收到客户端的请求了,请求路径是:' + req.url)*// res.write('hello') //这种方式比较麻烦**//发送响应数据并且结束响应**// res.end('hello')**//根据不同的请求路径返回 不同的响应结果**//1.获取请求路径 req.url 获取到的就是端口号之后的那一部分路径**var* url = req.url*//2.根据路径处理响应*if (url === '/') {res.end('index page')}else if (url === '/login') {res.end('login page')}else if (url === '/products') {*var* products = [{name:'苹果X',price:8888},{name:'华为p40',price:5000},{name:'小米10',price:4999},]res.end(JSON.stringify(products))}else {res.end('404 Not Found')}})server.listen(3000,*function* () {console.log('服务器启动成功,可以访问了')})
5.nodejs中的核心模块
require是一个方法,它的作用就是用来加载模块的,在node中,模块有三种:
- 1.具名模块,例如:fs、http
- 2.用户自己的编写的文件模块 在引入的时候相对路径必须加 ./
- 3.第三方模块
console.log('a start')require('./b') //遇到requre就去加载对应模块console.log('a end')
在node中没有全局作用域,只有模块作用域
要想模块之间通信,不仅要导入模块,而且还需要另一个模块导出一个接口对象,这样才可以在一个文件模块中使用另一个模块文件的变量
b.js
exports.foo = 'bbbb'exports.add = function (x, y) {return x+y}
a.js
console.log('a start')var bExports = require('./b') //遇到requre就去加载对应模块console.log(bExports.foo)console.log(bExports.add(10,30))console.log('a end')
6.响应内容类型
在服务端默认发送的数据是 utf8编码的内容
但是浏览器不知道是utf8编码内容,它会按照当前操作系统的默认编码去解析,中文操作系统默认是 gbk,所以解析之后会出现乱码情况。
解决方法是正确告诉浏览器我给你发送发的内容是什么编码,在http协议中,Content-Type 就是用来告诉浏览器我给你发送分数据内容是什么类型
const http = require('http')const server = http.createServer()server.on('request', function (req, res) {if (req.url === '/plain') {res.setHeader('Content-Type','text/plain;charset=utf-8')res.end('你好,nodejs')}else if (req.url === '/html') {res.setHeader('Content-Type','text/html;charset=utf-8')res.end('<p>hello html <a>点我</a></p>')}})server.listen(3000, function () {console.log('Server is running...')})
7. 响应文件内容
将html文件返回给浏览器
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request', function (req,res) {let url = req.urlif(url === '/') {fs.readFile('./resource/index.html', function (err,data) {if(err) {res.setHeader('Contend-Type','text/plain;charset=utf-8')res.end('文件读取失败,请稍后重试')}else {res.setHeader('Content-Type','text/html;charset=utf-8')res.end(data)}})}else if(url === '/img') {fs.readFile('./resource/store.png', function (err,data) {if(err){res.setHeader('Contend-Type','text/plain;charset=utf-8')res.end('图片获取失败,请稍后重试')}else {res.setHeader('Contend-Type','image/jpeg')res.end(data)}})}})server.listen(3000,function () {console.log('Server is running...')})
- 结合fs 发送文件中的数据
- Content-Type 告诉浏览器数据类型是什么
- 不同的资源对应的Content-Type是不一样的,图片不需要指定编码,一般只为字符数据指定编码
- Content-Type 对照表 http://tool.oschina.net/commons
8.初步实现Apache的功能
希望资源访问路径不要写死,而是根据url中写入的路径进行查询展示
const http = require('http')const fs = require('fs')const Server = http.createServer()Server.on('request',function(req, res) {let url = req.urllet filePath = '/index.html'let wwwDir = 'D:/资料库/学习资料/黑马程序员node/02/code/www'if (url !== '/') {filePath = url}console.log(filePath, wwwDir + filePath)fs.readFile(wwwDir + filePath, function(err,data){if(err) {return res.end('404 Not Found')}res.end(data)})})Server.listen(5000, function () {console.log('runnning...')})
以读文件的方式读取资源所对的路径。
9.在node中使用模板引擎
使用art-template插件实现模板引擎渲染
const template = require('art-template')const fs = require('fs')fs.readFile('./tpl.html', function (err,data) {if(err){return console.log('读取文件失败')}let ret = template.render(data.toString(),{name:'Jack',age:18,province:'北京市',hobbies:['写代码','唱歌','打游戏']})console.log(ret)})
tpl.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title></head><body><p>大家好,我叫:{{ name }}</p><p>我今年{{ age }}岁了</p><h1>我来自{{ province }}</h1><p>我喜欢:{{each hobbies }} {{ value }} {{/each}}</p></body></html>
template.render(模板,渲染数据对象)
10.服务端渲染和客户端渲染的区别
11.后端渲染的留言板
11.1、模板
app.js后端文件
const http = require('http')const fs = require('fs')http.createServer(function (req,res) {let url = req.urlif(url === '/') {fs.readFile('./view/index.html',function(err,data) {if(err){return res.end('404 Not Found.')}res.end(data)})}// res.end('hello')}).listen(5000, function () {console.log('running...')})
当请求路径是 / 时,就去读取index.html
index.html 首页
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><link rel="stylesheet" href="../public/css/bootstrap.min.css"></head><body><h1>你好</h1></body><script src="../public/js/index.js"></script></html>
post.html 留言板
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><link rel="stylesheet" href="../public/css/bootstrap.min.css"></head><body></body></html>
对于html中的外链静态资源文件需要统一处理才能访问到,否则会一直是pendding状态
11.2、静态资源开放目录
const http = require('http')const fs = require('fs')http.createServer(function (req,res) {let url = req.urlif (url === '/') {fs.readFile('./view/index.html', function (err,data) {if (err) {return res.end('404 Not Found.')}res.end(data)})}else if (url.indexOf('/public/') === 0) {fs.readFile('.' + url, function (err,data) {if(err){return end('404 Not Found')}res.end(data)})}// res.end('hello')}).listen(5000, function () {console.log('running...')})
将静态资源统一放到public目录下,然后通过indexOf判断请求路径中是否有public,如果有就是去访问这个目录下的静态资源。
11.3、渲染评论首页
app.js
const http = require('http')const fs = require('fs')const template = require('art-template')let comments = [{name:'小明',message:'今天吃什么',dateTime:'2020-6-18'},{name:'小丽',message:'逛街去',dateTime:'2020-6-18'},{name:'小红',message:'吃火锅',dateTime:'2020-6-18'},{name:'小黑',message:'你们都走了我好孤独',dateTime:'2020-6-18'}]http.createServer(function (req,res) {let url = req.urlif (url === '/') { //首页路径处理fs.readFile('./view/index.html', function (err,data) {if (err) {return res.end('404 Not Found.')}let htmlStr = template.render(data.toString(), {comments:comments})res.end(htmlStr)})}else if (url.indexOf('/public/') === 0) { //静态资源路径处理fs.readFile('.' + url, function (err,data) {if(err){return res.end('404 Not Found')}res.end(data)})}else if (url === '/post') {fs.readFile('./view/post.html', function (err, data) {if (err) {return res.end('404 Not Found')}res.end(data)})}else { // 其它路径处理,统一跳转到404页面fs.readFile('./view/404.html', function (err,data) {if (err) {return res.end('404 Not Found.')}res.end(data)})}// res.end('hello')}).listen(5000, function () {console.log('running...')})
comments 存放评论数据,当访问首页的时候通过template.render方法渲染这些数据,第一个参数是模板文件,第二个参数是渲染数据。
index.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><link rel="stylesheet" href="../public/css/bootstrap.min.css"></head><body><div class="header container"><div class="page-header"><h1>留言板</h1><a class="btn btn-success" href="/post">发表留言</a></div></div><div class="comments container"><ul class="list-group">{{each comments}}<li class="list-group-item">{{$value.name}}说:{{$value.message}}<span class="float-right">{{$value.dateTime}}</span></li>{{/each}}</ul></div></body><script src="../public/js/index.js"></script></html>
在模板中通过{{each comments}}方法进行渲染页面。
11.4、处理表单get提交留言信息url.parse
需要提交的表单控件元素必须要有name属性
表单提交分为:
- 默认的提交行为
action: 表单提交地址 method: 请求方法 - 异步提交
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title><link rel="stylesheet" href="../public/css/bootstrap.min.css"></head><body><div class="header container"><div class="page-header"><h1><a href="/">首页</a><small>发表评论</small></h1></div></div><div class="commerts container"><form action="/pinglun" method="GET"><div class="form-group"><label for="input_name">昵称</label><input type="text" name="name" class="form-control" required minlength="2" placehoder="请输入您的昵称"></div><div class="form-group"><label for="textarea_message">留言内容</label><textarea name="message" id="textarea_message" required cols="30" rows="10" class="form-control"></textarea></div><button type="submit" class="btn btn-primary">发表留言</button></form></div></body></html>
这样我们的请求路径会把留言信息拼接到 url 后面,我们可以通过nodejs的 url.parse 方法将 url 进行解析
url.parse,将路径解析成一个方便操作的对象,第二个参数为 true 表示将查询参数转为对象,通过query属性访问获取
const http = require('http')const fs = require('fs')const template = require('art-template')const url = require('url')const { parse } = require('path')let comments = [{name:'小明',message:'今天吃什么',dateTime:'2020-6-18'},{name:'小丽',message:'逛街去',dateTime:'2020-6-18'},{name:'小红',message:'吃火锅',dateTime:'2020-6-18'},{name:'小黑',message:'你们都走了我好孤独',dateTime:'2020-6-18'}]http.createServer(function (req,res) {// let url = req.url//使用url.parse方法将路径解析成一个方便操作的对象,第二个参数为true表示将查询参数转为对象,通过query属性访问获取let parseObj = url.parse(req.url,true)//单独获取不包含查询字符串的部分 (该路径不包含 ? 之后的内容)let pathname = parseObj.pathnameif (pathname === '/') { //首页路径处理fs.readFile('./view/index.html', function (err,data) {if (err) {return res.end('404 Not Found.')}let htmlStr = template.render(data.toString(), {comments:comments})res.end(htmlStr)})}else if (pathname.indexOf('/public/') === 0) { //静态资源路径处理fs.readFile('.' + pathname, function (err,data) {if(err){return res.end('404 Not Found')}res.end(data)})}else if (pathname === '/post') {fs.readFile('./view/post.html', function (err, data) {if (err) {return res.end('404 Not Found')}res.end(data)})}else if (pathname === '/pinglun') {// res.end(JSON.stringify(parseObj.query))//使用parse方法将请求路径中的查询字符串解析成了一个对象,//所以接下来要做的就是// 1.获取表单提交信息 parseObj.query// 2.生成日期,存储到数组中// 3.让用户重定向到首页let comment = parseObj.querycomment.dateTime = '2020-6-20'comments.unshift(comment)} else { // 其它路径处理,统一跳转到404页面fs.readFile('./view/404.html', function (err,data) {if (err) {return res.end('404 Not Found.')}res.end(data)})}// res.end('hello')}).listen(5000, function () {console.log('running...')})
当pathname === ‘/pinglun’ 的时候将转换后的查询字符串对象push到comments中,接下来就是要重定向到首页
11.5、提交成功重定向到首页
else if (pathname === '/pinglun') {// res.end(JSON.stringify(parseObj.query))//使用parse方法将请求路径中的查询字符串解析成了一个对象,//所以接下来要做的就是// 1.获取表单提交信息 parseObj.query// 2.生成日期,存储到数组中// 3.让用户重定向到首页let comment = parseObj.querycomment.dateTime = '2020-6-20'comments.unshift(comment)//服务端这个时候已经把数据存储好了,接下来就是让用户重新请求 / 首页了// 如何通过服务器让客户端重定向// 1. 在状态码中设置302 临时重定向// 2. 在响应头中通过Location 告诉用户往哪儿重定向//如果客户端收到服务器的响应状态码是 302 就会自动去响应头中找 Location ,并自动跳转res.statusCode = 302res.setHeader('Location', '/')res.end()}
使用statusCode方法设置状态码302 临时重定向
使用setHeader 方法在响应头中设置Location,告诉浏览器要跳转的地址
三、node中的模块系统
1.基本规则
使用Node编写应用程序主要就是在使用:
- EcmaScript语言
- 和浏览器一样,在Node中没有Bom和Dom
- 核心模块
- 文件操作的fs
- http服务操作的http
- url路径操作模块
- path路径处理模块
- os操作系统信息
- 第三方模块
- art-template
- 必须通过npm来下载才可以使用
- 自己写的模块
- 自己创建的文件
2.什么是模块化
https://www.jianshu.com/p/8573cdcde863
- 文件作用域(模块是独立的,在不同的文件使用必须要重新引用)【在node中没有全局作用域,它是文件模块作用域】
- 通信规则
- 加载require
- 导出exports
3.CommonJS模块规范
在Node中的JavaScript还有一个重要的概念,模块系统。
CommonJS主要用在Node开发上,每个文件就是一个模块,每个文件都有自己的一个作用域。通过module.exports或者exports暴露给外界。其他模块可以通过require()引入模块依赖,require 函数可以引入Node的内置模块、自定义模块和npm等第三方模块。
package.json是CommonJS规定的用来面熟包的文件,完全符合规范的文件应包含以package.json下字段。
- 模块作用域
- 使用require方法来加载模块
- 使用exports接口对象来导出模板中的成员加载
require
语法:
var 自定义变量名 = require('模块')
作用:
- 执行被加载模块中的代码
-
导出
exports Node中是模块作用域,默认文件中所有的成员只在当前模块有效
对于希望可以被其他模块访问到的成员,我们需要把这些公开的成员都挂载到
exports接口对象中就可以了
导出多个成员(必须在对象中):exports.a = 123;exports.b = function(){console.log('bbb')};exports.c = {foo:"bar"};exports.d = 'hello';
导出单个成员(拿到的就是函数,字符串):
module.exports = 'hello';
以下情况会覆盖:
module.exports = 'hello';//后者会覆盖前者module.exports = function add(x,y) {return x+y;}
也可以通过以下方法来导出多个成员:
module.exports = {foo = 'hello',add:function(){return x+y;}};
4.模块原理
exports和module.exports的一个引用:
console.log(exports === module.exports); //trueexports.foo = 'bar';//等价于module.exports.foo = 'bar';当给exports重新赋值后,exports!= module.exports.最终return的是module.exports,无论exports中的成员是什么都没用。真正去使用的时候:导出单个成员:exports.xxx = xxx;导出多个成员:module.exports 或者 modeule.exports = {};
总结
// 引用服务var http = require('http');var fs = require('fs');// 引用模板var template = require('art-template');// 创建服务var server = http.createServer();// 公共路径var wwwDir = 'D:/app/www';server.on('request', function (req, res) {var url = req.url;// 读取文件fs.readFile('./template-apche.html', function (err, data) {if (err) {return res.end('404 Not Found');}fs.readdir(wwwDir, function (err, files) {if (err) {return res.end('Can not find www Dir.')}// 使用模板引擎解析替换data中的模板字符串// 去xmpTempleteList.html中编写模板语法var htmlStr = template.render(data.toString(), {title: 'D:/app/www/ 的索引',files:files});// 发送响应数据res.end(htmlStr);})})});server.listen(3000, function () {console.log('running....');})
5.加载规则
- 核心模块 http,fs 等直接返回模块
- / 开头加载全局的文件,再加载文件夹
- ./ 和 ../ 开头先加载文件,再加载文件夹
- 非核心模块,路径里也没有 / ./ ../ 的则去 node_module 里加载文件夹
加载文件 X:X -> X.js -> X.json -> X.node
加载文件夹: X/package.json 里得到 main 字段为 M,加载文件 M。找不到再 加载文件 index
————————————————————————————以上是简单理解——————————————————————
- 1、先计算模块路径
- 2、如果模块在缓存里面,取出缓存
- 3、否则根据计算出来的模块路径加载模块
- 4、输出模块的exports属性即可
在node中引入模块,需要经过三个步骤:
- 路径分析
- 文件定位
- 编译执行
核心模块文件已经被编译到了二进制文件中了,我们只需要按照名字来加载就可以了,不需要文件定位和编译执行,并且在路径分析中优先判断。
文件模块则是运行时动态加载,需要完整的路径分析、文件定位、编译执行。
5.1 优先从缓存加载
node会对引入过的模块进行缓存,以减少二次引入时的开销。node缓存的是编译和执行之后的对象。核心模块的缓存检查先于文件模块的缓存检查。
5.2 路径分析
核心模块:
不需要路径分析。
文件模块:
其实就是加载自己写的JS文件,require会将路径转为真实路径,并以真实路径作为索引。
第三方模块:
没有文件路径,Node将试图去当前目录的node_modules文件夹里搜索。如果当前目录的node_modules里没有找到,Node会从父目录的node_modules里搜索,这样递归下去直到根目录。
5.3 文件定位
文件扩展名分析
如果require标识符中不包含文件扩展名,node就会按照 .js、.json 、.node的次序补足扩展名,依次尝试。
目录分析
从package.json中得到main字段对应的文件,将他和文件扩展名目录对比定位,没有package.json会将index作为默认文件。
5.4 模块编译
编译和执行是引入文件模块的最后一个阶段。定位到具体文件后,Node会新建一个模块对象,然后通过路径载入并编译。对于不同的文件扩展名,其载入的方式也有所不同,具体如下。
- .js文件。通过fs模块同步读取文件后编译执行。
- .node文件。这是用C/C++编写的扩展文件,通过dlopen()方法加载最后的编译生成的文件。
- .json文件。通过fs模块同步读取文件后,用JSON.parse()解析返回结果。
- 其余扩展名文件。它们都被当作.js文件解析。(因为node只能解析js文件,其他文件最后都会被转化成js文件,故当其余扩展名文件出现时,node无法识别,故将其认为是默认扩展名进行解析,即.js)
每一个编译成功的模块都会将文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。
js模块编译
node会对获取的js文件内容进行头尾包装,在头部添加(function(require、exports、module、_filename、_dirname) {\n, 在尾部添加 \n} 具体如下:
(function(require、exports、module、_filename、_dirname){var math = require('math');exports.area = function(radius){return Math.PI * radius * radius;}})
这样每个模块文件之间都进行了作用于隔离。不污染全局,最后,将当前模块对象的exports属性,require()方法,module(模块对象本身),以及在文件定位中得到的完整文件路径和文件目录作为参数传递给一个function()对象执行。
JSON文件编译
Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋给模块对象的exports,以供外部调用。
JSON文件在用作项目的配置文件时比较有用。如果你定义了JSON文件作为配置,那就不用调用fs模块去异步读取和解析,直接调用require()引入即可。此外,你还可以享受到模块缓存的便利,并且二次引入时也没有性能影响。
核心模块编译
这里只说一下js核心模块编译。
首先需要将所有的js核心模块编译为C++代码。
其次,再执行编译,和文件模块的编译相同,也要头尾包装,不同的是获取源代码(核心模块是从内存中获取)的方式和缓存执行结果的位置不同。
编译成功的核心模块会缓存到NativeModule.Cache对象上,文件模块则缓存到Module._cache对象上
总结
// 如果非路径形式的标识// 路径形式的标识:// ./ 当前目录 不可省略// ../ 上一级目录 不可省略// /xxx也就是D:/xxx// 带有绝对路径几乎不用(D:/a/foo.js)// 首位表示的是当前文件模块所属磁盘根目录// require('./a');// 核心模块// 核心模块本质也是文件,核心模块文件已经被编译到了二进制文件中了,我们只需要按照名字来加载就可以了require('fs');// 第三方模块// 凡是第三方模块都必须通过npm下载(npm i node_modules),使用的时候就可以通过require('包名')来加载才可以使用// 第三方包的名字不可能和核心模块的名字是一样的// 既不是核心模块,也不是路径形式的模块// 先找到当前文所述目录的node_modules// 然后找node_modules/art-template目录// node_modules/art-template/package.json// node_modules/art-template/package.json中的main属性// main属性记录了art-template的入口模块// 然后加载使用这个第三方包// 实际上最终加载的还是文件// 如果package.json不存在或者mian指定的入口模块不存在// 则node会自动找该目录下的index.js// 也就是说index.js是一个备选项,如果main没有指定,则加载index.js文件//// 如果条件都不满足则会进入上一级目录进行查找// 注意:一个项目只有一个node_modules,放在项目根目录中,子目录可以直接调用根目录的文件var template = require('art-template');
五、npm
- node package manage(node包管理器)
- 通过npm命令安装jQuery包(npm install —save jquery),在安装时加上—save会主动生成说明书文件信息(将安装文件的信息添加到package.json里面)
1.常用命令
- npm init(生成package.json说明书文件)
- npm init -y(可以跳过向导,快速生成)
- npm install
- 一次性把dependencies选项中的依赖项全部安装
- 简写(npm i)
- npm install 包名
- 只下载
- 简写(npm i 包名)
- npm install —save 包名
- 下载并且保存依赖项(package.json文件中的dependencies选项)
- 简写(npm i 包名)
- npm uninstall 包名
- 只删除,如果有依赖项会依然保存
- 简写(npm un 包名)
- npm uninstall —save 包名
- 删除的同时也会把依赖信息全部删除
- 简写(npm un 包名)
- npm help
- 查看使用帮助
- npm 命令 —help
- 查看具体命令的使用帮助(npm uninstall —help)
2.解决npm被墙问题
npm存储包文件的服务器在国外,有时候会被墙,速度很慢,所以需要解决这个问题。
https://developer.aliyun.com/mirror/NPM?from=tnpm淘宝的开发团队把npm在国内做了一个镜像(也就是一个备份)。
安装淘宝的cnpm:
npm install -g cnpm --registry=https://registry.npm.taobao.org;#在任意目录执行都可以#--global表示安装到全局,而非当前目录#--global不能省略,否则不管用npm install --global cnpm
安装包的时候把以前的npm替换成cnpm。
#走国外的npm服务器下载jQuery包,速度比较慢npm install jQuery;#使用cnpm就会通过淘宝的服务器来下载jQuerycnpm install jQuery;
如果不想安装cnpm又想使用淘宝的服务器来下载:
npm install jquery --registry=https://npm.taobao.org;
但是每次手动加参数就很麻烦,所以我们可以把这个选项加入到配置文件中:
npm config set registry https://npm.taobao.org;#查看npm配置信息npm config list;
只要经过上面的配置命令,则以后所有的npm install都会通过淘宝的服务器来下载
3.package.json
每一个项目都要有一个package.json文件(包描述文件,就像产品的说明书一样)
这个文件可以通过npm init自动初始化出来
D:\code\node中的模块系统>npm initThis utility will walk you through creating a package.json file.It only covers the most common items, and tries to guess sensible defaults.See `npm help json` for definitive documentation on these fieldsand exactly what they do.Use `npm install <pkg>` afterwards to install a package andsave it as a dependency in the package.json file.Press ^C at any time to quit.package name: (node中的模块系统)Sorry, name can only contain URL-friendly characters.package name: (node中的模块系统) clsversion: (1.0.0)description: 这是一个测试项目entry point: (main.js)test command:git repository:keywords:author: xiaochenlicense: (ISC)About to write to D:\code\node中的模块系统\package.json:{"name": "cls","version": "1.0.0","description": "这是一个测试项目","main": "main.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"author": "xiaochen","license": "ISC"}Is this OK? (yes) yes
对于目前来讲,最有用的是dependencies选项,可以用来帮助我们保存第三方包的依赖信息。
如果node_modules删除了也不用担心,只需要在控制面板中npm install就会自动把package.json中的dependencies中所有的依赖项全部都下载回来。
- 建议每个项目的根目录下都有一个
package.json文件 - 建议执行
npm install 包名的时候都加上--save选项,目的是用来保存依赖信息
4.package.json和package-lock.json
npm 5以前是不会有package-lock.json这个文件
npm5以后才加入这个文件
当你安装包的时候,npm都会生成或者更新package-lock.json这个文件
- npm5以后的版本安装都不要加
--save参数,它会自动保存依赖信息 当你安装包的时候,会自动创建或者更新
package-lock.json文件package-lock.json
这个文件会包含
node_modules
中所有包的信息(版本,下载地址。。。)
- 这样的话重新
npm install的时候速度就可以提升
- 这样的话重新
从文件来看,有一个
lock
称之为锁
- 这个
lock使用来锁版本的 - 如果项目依赖了
1.1.1版本 - 如果你重新install其实会下载最新版本,而不是
1.1.1 package-lock.json的另外一个作用就是锁定版本号,防止自动升级
- 这个
5.path路径操作模块
- path.basename:获取路径的文件名,默认包含扩展名
- path.dirname:获取路径中的目录部分
- path.extname:获取一个路径中的扩展名部分
- path.parse:把路径转换为对象
- root:根路径
- dir:目录
- base:包含后缀名的文件名
- ext:后缀名
- name:不包含后缀名的文件名
- path.join:拼接路径
- path.isAbsolute:判断一个路径是否为绝对路径
6.Node中的其它成员(dirname,filename)
在每个模块中,除了require,exports等模块相关的API之外,还有两个特殊的成员:
__dirname,是一个成员,可以用来动态获取当前文件模块所属目录的绝对路径__filename,可以用来动态获取当前文件的绝对路径(包含文件名)__dirname和filename是不受执行node命令所属路径影响的
在文件操作中,使用相对路径是不可靠的,因为node中文件操作的路径被设计为相对于执行node命令所处的路径。
所以为了解决这个问题,只需要把相对路径变为绝对路径(绝对路径不受任何影响)就可以了。
就可以使用__dirname或者__filename来帮助我们解决这个问题
在拼接路径的过程中,为了避免手动拼接带来的一些低级错误,推荐使用path.join()来辅助拼接
var fs = require('fs');var path = require('path');// console.log(__dirname + 'a.txt');// path.join方法会将文件操作中的相对路径都统一的转为动态的绝对路径fs.readFile(path.join(__dirname + '/a.txt'),'utf8',function(err,data){if(err){throw err}console.log(data);});
补充:模块中的路径标识和这里的路径没关系,不受影响(就是相对于文件模块)
注意: 模块中的路径标识和文件操作中的相对路径标识不一致 模块中的路径标识就是相对于当前文件模块,不受node命令所处路径影响
六、Express
作者:Tj
原生的http在某些方面表现不足以应对我们的开发需求,所以就需要使用框架来加快我们的开发效率,框架的目的就是提高效率,让我们的代码高度统一。
安装:
cnpm install express
起步:
const express = require('express')const app = express()app.get('/',function (req,res) {res.send('hello 你好a')})app.get('/login', function (req,res) {res.send(`<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title></head><body>你好,人生</body></html>`)})app.listen(3000, function () {console.log('express app is running...')})
可以看到我们访问某个路径的时候只需要 app.get 即可获取对应内容,而不需要再像之前一样需要通过 一层一层的 if 条件判断,然后 fs.readfile 来读取文件内容。
1.基本路由
路由:请求方法 + 请求路径 + 请求处理函数
get:
当以get方法请求时,执行对应处理函数
app.get('/',function (req,res) {res.send('hello 你好a')})
post:
当以post方法请求时,执行对应处理函数
app.post('/',function(req,res){res.send('hello world');})
2.Express静态服务API
// app.use不仅仅是用来处理静态资源的,还可以做很多工作(body-parser的配置)app.use(express.static('public'));app.use(express.static('files'));app.use('/stataic',express.static('public'));// 引入expressvar express = require('express');// 创建appvar app = express();// 开放静态资源// 1.当以/public/开头的时候,去./public/目录中找对应资源// 访问:http://127.0.0.1:3000/public/login.htmlapp.use('/public/',express.static('./public/'));// 2.当省略第一个参数的时候,可以通过省略/public的方式来访问// 访问:http://127.0.0.1:3000/login.html// app.use(express.static('./public/'));// 3.访问:http://127.0.0.1:3000/a/login.html// a相当于public的别名// app.use('/a/',express.static('./public/'));//app.get('/',function(req,res){res.end('hello world');});app.listen(3000,function(){console.log('express app is runing...');});
3.在Express中配置使用art-templete模板引擎
- art-template官方文档
在node中,有很多第三方模板引擎都可以使用,不是只有
art-template
- 还有ejs,jade(pug),handlebars,nunjucks
安装:
npm install --save art-templatenpm install --save express-art-template//两个一起安装npm i --save art-template express-art-template
配置:
app.engine('html', require('express-art-template'));
使用:
app.get('/',function(req,res){// express默认会去views目录找index.htmlres.render('index.html',{title:'hello world'});})
如果希望修改默认的views视图渲染存储目录,可以:
// 第一个参数views千万不要写错app.set('views',目录路径);
4.使用Express重写留言板
目录:
app.js
const express = require('express')const app = express()app.use('/public/', express.static('./public/'))app.engine('html',require('express-art-template'))let comments = [{name:'小明',message:'今天吃什么',dateTime:'2020-6-18'},{name:'小丽',message:'逛街去',dateTime:'2020-6-18'},{name:'小红',message:'吃火锅',dateTime:'2020-6-18'},{name:'小黑',message:'你们都走了我好孤独',dateTime:'2020-6-18'}]Date.prototype.Format = function (fmt) { // author: meizzvar o = {"M+": this.getMonth() + 1, // 月份"d+": this.getDate(), // 日"h+": this.getHours(), // 小时"m+": this.getMinutes(), // 分"s+": this.getSeconds(), // 秒"q+": Math.floor((this.getMonth() + 3) / 3), // 季度"S": this.getMilliseconds() // 毫秒};if (/(y+)/.test(fmt))fmt = fmt.replace(RegExp.$1, (this.getFullYear() + "").substr(4 - RegExp.$1.length));for (var k in o)if (new RegExp("(" + k + ")").test(fmt)) fmt = fmt.replace(RegExp.$1, (RegExp.$1.length == 1) ? (o[k]) : (("00" + o[k]).substr(("" + o[k]).length)));return fmt;}app.get('/',function (req,res) {res.render('index.html', {comments:comments})})app.get('/post',function (req,res) {res.render('post.html')})app.get('/pinglun', function (req,res) {let comment = req.querycomment.dateTime = new Date().Format("yyyy-MM-dd")comments.unshift(comment)res.redirect('/') //等价于下面// res.status = 302// res.setHeader('Location','/')})app.listen(3000, function () {console.log('express app is running...')})
相比之前的写法更加简洁
5.在Express中获取post表单请求体数据
对于get方法请求数据可以直接通过req.query来获取数据,但是post方法的数据不能直接获取。
在express中没有内置获取post表单请求体的api,因此使用一个第三方包 body-parser
安装方法:
npm install --save body-parser
使用方法:
通过req.body 这个api拿到请求体数据
var express = require('express')#记得导包var bodyParser = require('body-parser')var app = express()#关键代码app.use(bodyParser.urlencoded({ extended: false }))app.use(bodyParser.json())//post方法处理表单请求体数据app.post('/post', function (req,res) {//1.获取表单请求体数据//2.处理//3.发送响应let comment = req.bodycomment.dateTime = new Date().Format("yyyy-MM-dd")comments.unshift(comment)res.redirect('/')})
七、Express-crud项目
1.路由设计
| 请求方法 | 请求路径 | get参数 | post参数 | 备注 |
|---|---|---|---|---|
| GET | /students | 渲染首页 | ||
| GET | /students/new | 渲染添加学生页面 | ||
| POST | /students/new | name,age,gender,hobbies | 处理添加学生请求 | |
| GET | /students/edit | id | 渲染编辑页面 | |
| POST | /students/edit | id,name,age,gender,hobbies | 处理编辑请求 | |
| GET | /students/delete | id | 处理删除请求 |
2.提取路由模块
方法一:
router.js
module.exports = function (app) {app.get('/students', function (req, res) {//readFile 的第二个参数是可选的,utf8 是告诉浏览器按照utf8编码格式进行转换,除了这样,也可以通过data.toString() 的方式fs.readFile('./db.json', function (err, data) {if (err) {return res.status(500).send('Server error.')}res.render('index.html',{fruits:['苹果','香蕉','橘子','西瓜'],students: JSON.parse(data).students})})})app.get('/students/new', function (req, res) {})app.get('/students/new', function (req, res) {})app.get('/students/new', function (req, res) {})app.get('/students/new', function (req, res) {})app.get('/students/new', function (req, res) {})app.get('/students/new', function (req, res) {})}
在app.js中引入,并传入参数router(app)
//引入路由模块const router = require('./router')const app = express()const fs = require('fs')app.engine('html', require('express-art-template'));app.use('/node_modules/',express.static('./node_modules'))app.use('/public/',express.static('./public'))router(app)app.listen(3000, function () {console.log('running...')})
方法二:
使用express的路由容器
const fs = require('fs')// Express 提供了一种更好得方式专门用来包装路由const express = require('express')//1.创建一个路由容器const router = express.Router()//2.把路由挂载到router路由容器中router.get('/students', function (req, res) {//readFile 的第二个参数是可选的,utf8 是告诉浏览器按照utf8编码格式进行转换,除了这样,也可以通过data.toString() 的方式fs.readFile('./db.json', function (err, data) {if (err) {return res.status(500).send('Server error.')}res.render('index.html',{fruits:['苹果','香蕉','橘子','西瓜'],students: JSON.parse(data).students})})})router.get('/students/new', function (req, res) {})router.get('/students/new', function (req, res) {})router.get('/students/new', function (req, res) {})router.get('/students/new', function (req, res) {})router.get('/students/new', function (req, res) {})router.get('/students/new', function (req, res) {})module.exports = router
在app.js中通过use调用app.use(router)
const express = require('express')//引入路由模块const router = require('./router')const app = express()const fs = require('fs')app.engine('html', require('express-art-template'));app.use('/node_modules/',express.static('./node_modules'))app.use('/public/',express.static('./public'))//把路由容器挂载到app服务中app.use(router)// router(app)app.listen(3000, function () {console.log('running...')})
3.设计操作数据的API文件模块
/*** 数据操作文件模块* 职责:操作文件中的数据,只处理数据,不关心业务*/const fs = require('fs')const { json } = require('body-parser')var dbPath = './db.json'/*** 获取学生列表* return []* callback 中的参数,* 第一个err* 成功是null* 错误是错误对象* 第二个参数data* 成功是 数组* 错误是undefined*/exports.find = function (callback) {//这个方法是异步读取数据的,被调用的时候不能直接返回数据//如果需要获取一个函数中异步操作的结果,则必须通过回调函数,回调函数:获取异步操作的结果// fs.readFile(dbPath, function (err, data) {// JSON.parse(data).students// })// 方法一:使用 fs.readFileSync 同步读取//方法二:使用回调函数fs.readFile(dbPath, function (err, data) {if(err) {return callback(err) //失败调用失败函数}callback(null, JSON.parse(data).students) //成功调用成功函数})}/*** 添加保存学生将学生数据push到文件*/exports.save = function (student, callback) {fs.readFile(dbPath,'utf8', function (err, data) {if (err) {return callback(err)}let students = JSON.parse(data).students//处理id 唯一的 不重复if(students.length > 0){student.id = students[students.length - 1].id + 1}else {student.id = 1}students.unshift(student)var ret = JSON.stringify({students:students})fs.writeFile(dbPath, ret, function(err) {if (err) {return callback(err)}//成功就没有错,所以错误对象就是nullcallback(null)})})}/*** 更新学生根据id找到对应学生信息将新的数据项item拷贝将更新后的数据转为字符串写入文件*/exports.updataById = function (student, callback) { //student 是要修改的数据//读文件fs.readFile(dbPath,'utf8', function (err, data) {if (err) {return callback(err)}let students = JSON.parse(data).students//注意:这里统一把 id 改为 数字类型student.id = parseInt(student.id)//要修改谁就需要把谁找出来//当某个遍历项符合条件时,会终止遍历,同时返回let stu = students.find( function (item) {return item.id === student.id})//这种方法不行// stu.name = student.name// stu.age = stu.age//修改 遍历拷贝对象for( let key in student) {console.log(key)stu[key] = student[key]}var ret = JSON.stringify({students:students})//写入文件fs.writeFile(dbPath, ret, function(err) {if (err) {return callback(err)}//成功就没有错,所以错误对象就是nullcallback(null)})})}// updataById({// id:1,// name:'xx',// age:15,// }, function (err) {// })/*** 删除学生:找到对应学生信息通过splice方法删除将数据转为字符串类型的再保存写入到文件中*/exports.deleteById = function (id, callback) {fs.readFile(dbPath, 'utf8', function (err, data) {if (err) {return callback(err)}let students = JSON.parse(data).students// findIndex 方法专门用来根据条件查找元素的下标let deleteId = students.findIndex(function (item) {return item.id === parseInt(id)})// 根据下标从数组中删除对应学生students.splice(deleteId, 1)//转为字符串再保存var ret = JSON.stringify({students:students})//写入文件fs.writeFile(dbPath, ret, function(err) {if (err) {return callback(err)}//成功就没有错,所以错误对象就是nullcallback(null)})})}/*** 根据 id 获取学生信息对象* @param {*} id* @param {*} callback*/exports.findById = function (id, callback) {//读取文件fs.readFile(dbPath, 'utf8', function (err, data) {if (err) {return callback(err)}let students = JSON.parse(data).students//找符合条件的let ret = students.find(function (item) {return item.id === id})callback(null, ret)})}
es6中的find和findIndex:
find接受一个方法作为参数,方法内部返回一个条件
find会便利所有的元素,执行你给定的带有条件返回值的函数
符合该条件的元素会作为find方法的返回值
如果遍历结束还没有符合该条件的元素,则返回undefined
八、MongoDB
1.关系型数据库(表就是关系,或者说表与表之间存在关系)。
- 所有的关系型数据库都需要通过
sql语言来操作 - 所有的关系型数据库在操作之前都需要设计表结构
- 而且数据表还支持约束
- 唯一的
- 主键
- 默认值
- 非空
2.非关系型数据库
- 非关系型数据库非常的灵活
- 有的非关系型数据库就是key-value对儿
- 但MongDB是长得最像关系型数据库的非关系型数据库
- 数据库 -》 数据库
- 数据表 -》 集合(数组)
- 表记录 -》文档对象
一个数据库中可以有多个数据库,一个数据库中可以有多个集合(数组),一个集合中可以有多个文档(表记录)
{qq:{user:[{},{},{}...]}}
- 也就是说你可以任意的往里面存数据,没有结构性这么一说
3.安装
- 下载
安装
npm i mongoose
配置环境变量
- 最后输入
mongod --version测试是否安装成功
4.启动和关闭数据库
启动:
# mongodb 默认使用执行mongod 命令所处盼复根目录下的/data/db作为自己的数据存储目录# 所以在第一次执行该命令之前先自己手动新建一个 /data/dbmongod
如果想要修改默认的数据存储目录,可以:
mongod --dbpath = 数据存储目录路径
停止:
在开启服务的控制台,直接Ctrl+C;或者直接关闭开启服务的控制台。
5.连接数据库
连接:
# 该命令默认连接本机的 MongoDB 服务mongo
退出:
# 在连接状态输入 exit 退出连接exit
6.基本命令
show dbs
查看数据库列表(数据库中的所有数据库)
db
查看当前连接的数据库
use 数据库名称
切换到指定的数据库,(如果没有会新建)
show collections
查看当前目录下的所有数据表
db.表名.find()
查看表中的详细信息
7.在Node中如何操作MongoDB数据库
7.1使用官方的MongoDB包来操作
7.2使用第三方包mongoose来操作MongoDB数据库
第三方包:mongoose基于MongoDB官方的mongodb包再一次做了封装,名字叫mongoose,是WordPress项目团队开发的。
8.学习指南(步骤)
官方学习文档:https://mongoosejs.com/docs/index.html
9.设计Scheme 发布Model (创建表)
// 1.引包// 注意:按照后才能require使用var mongoose = require('mongoose');// 拿到schema图表var Schema = mongoose.Schema;// 2.连接数据库// 指定连接数据库后不需要存在,当你插入第一条数据库后会自动创建数据库mongoose.connect('mongodb://localhost/test',{useNewUrlParser: true, useUnifiedTopology: true});// 3.设计集合结构(表结构)// 用户表var userSchema = new Schema({username: { //姓名type: String,require: true //添加约束,保证数据的完整性,让数据按规矩统一},password: {type: String,require: true},email: {type: String}});// 4.将文档结构发布为模型// mongoose.model方法就是用来将一个架构发布为 model// 第一个参数:传入一个大写名词单数字符串用来表示你的数据库的名称// mongoose 会自动将大写名词的字符串生成 小写复数 的集合名称// 例如 这里会变成users集合名称// 第二个参数:架构// 返回值:模型构造函数var User = mongoose.model('User', userSchema);
九、Mongoose
安装:
npm i mongoose
起步:
const mongoose = require('mongoose');//连接mongoose.connect('mongodb://localhost:27017/test', {useNewUrlParser: true, useUnifiedTopology: true});//创建一个模型,其实是在设计数据库const Cat = mongoose.model('Cat', { name: String });//实例化一个Catconst kitty = new Cat({ name: 'Zildjian' });//持久化保存kitty.save().then(() => console.log('meow'));
1.MongoDB数据库的基本概念
- 可以有多个数据库
- 一个数据库中可以有多个集合(表)
- 一个集合中可以有多个文档(表记录)
- 文档结构很灵活,没用任何限制
- MongoDB非常灵活,不需要像MySQL一样先创建数据库、表、设计结构
{qq:{(库)user:[(表){name:'张三',age:18},(表记录){name:'李四',age:18},{name:'王五',age:18},...],products:[],},taobao:{},baidu:{}}
十、blog案例
1.目录结构
app.js 项目的入口文件controllersmodels 存储使用mongoose设计的数据模型node_modules 第三方包package.json 包描述文件package-lock.json 第三方包版本锁定文件(npm5之后才有)public 公共静态资源routes 路由views 存储视图目录
2.模板页
- art-tmplate 子模板
- art-template 模板继承
3.路由设计
| 路由 | 方法 | get参数 | post参数 | 是否需要登录 | 备注 |
|---|---|---|---|---|---|
| / | get | 渲染首页 | |||
| /register | get | 渲染注册页面 | |||
| /register | post | email,nickname,password | 处理注册请求 | ||
| /login | get | 渲染登陆界面 | |||
| /login | post | email,password | 处理登录请求 | ||
| /loginout | get | 处理退出请求 |
const express = require('express')const User = require('./modules/user')const md5 = require('blueimp-md5')const router = express.Router()router.get('/', function (req, res) {res.render('index.html')})//登录router.get('/login', function (req,res) {res.render('login.html')})router.post('/login', function (req,res) {// res.render('login.html')})//注册router.get('/register', function (req,res) {res.render('register.html')})router.post('/register', async function (req,res) {//1. 获取表单提交得数据 body-parse//2. 操作数据库// 判断该用户是否已存在// 如果已存在不允许注册// 如果不存在,注册成功//3. 发送响应console.log(req.body)let body = req.bodyUser.findOne({$or:[{email:body.email},{nickname:body.nickname}]}, function (err, data) {//josn 方法替换 send方法if (err) {return res.status(500).json({err_code:500,error_info:'服务端错误'})}// console.log(data)if(data) {return res.status(200).send({err_code: 1,error_info:'邮箱或者昵称已存在'})}//保存数据body.password = md5(md5(body.password)) //对密码进行加密new User(body).save(function (err, user) {if(err) {return res.status(500).json({err_code:500,error_info:'服务端错误'})}})//这么写麻烦// res.status(200).send(JSON.stringify({// 'success':true// }))//express 提供了一个响应方法:json 该方法接收一个对象作为参数,他会自动帮你把对象转为字符串再发送给浏览器res.status(200).json({err_code:0,message:'ok'})})})module.exports = router
使用async 和 await改写上面的代码
router.post('/register', async function (req, res) {var body = req.bodytry {if (await User.findOne({ email: body.email })) {return res.status(200).json({err_code: 1,message: '邮箱已存在'})}if (await User.findOne({ nickname: body.nickname })) {return res.status(200).json({err_code: 2,message: '昵称已存在'})}// 对密码进行 md5 重复加密body.password = md5(md5(body.password))// 创建用户,执行注册await new User(body).save()res.status(200).json({err_code: 0,message: 'OK'})} catch (err) {res.status(500).json({err_code: 500,message: err.message})}})
4.注册表单提交
表单具有默认的提交的行为,默认是同步提交,同步表单提交,浏览器会锁死(转圈儿)等待服务端的响应结果。表单的同步提交之后,无论服务端响应的是什么,都会直接把响应的结果覆盖掉当前页面。
同步提交:默认表单提交
<form id="register_form" method="post" action="/register"><div class="form-group"><label for="email">邮箱</label><input type="email" class="form-control" id="email" name="email" placeholder="Email" autofocus></div><div class="form-group"><label for="nickname">昵称</label><input type="text" class="form-control" id="nickname" name="nickname" placeholder="Nickname"></div><div class="form-group"><label for="password">密码</label><input type="password" class="form-control" id="password" name="password" placeholder="Password"></div><button type="submit" class="btn btn-success btn-block">注册</button></form>
解决办法是重定向到当前注册页面,并将原来填写的数据回填到页面。
app.jsp.js
register.html
异步提交:通过ajax提交
$('#register_form').on('submit', function (e) {e.preventDefault() //阻止默认提交console.log('1234')var formData = $(this).serialize() //输出序列化表单值得结果$.ajax({url: '/register',type: 'post',data: formData,dataType: 'json',success: function (data) {console.log(data)var err_code = data.err_codeif (err_code === 0) {// window.alert('注册成功!')// 服务端重定向针对异步请求无效window.location.href = '/'} else if (err_code === 1) {window.alert('邮箱或昵称已存在!')} else if (err_code === 500) {window.alert('服务器忙,请稍后重试!')}}})})
使用 FormData 接口提交数据
FormData的主要用途有两个:
1、将form表单元素的name与value进行组合,实现表单数据的序列化,从而减少表单元素的拼接,提高工作效率。
2、异步上传文件
使用:
$('.btn').onclick = function () {let form = $('#register_form')let formdata = new FormData(form)$.ajax({url: '/register',type: 'post',data: formData,dataType: 'json',success: function (data) {console.log(data)var err_code = data.err_codeif (err_ code === 0) {// window.alert('注册成功!')// 服务端重定向针对异步请求无效window.location.href = '/'} else if (err_code === 1) {window.alert('邮箱或昵称已存在!')} else if (err_code === 500) {window.alert('服务器忙,请稍后重试!')}}})}
FormData的方法
[FormData.append()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/append)
向 FormData 中添加新的属性值,FormData 对应的属性值存在也不会覆盖原值,而是新增一个值,如果属性不存在则新增一项属性值。
[FormData.delete()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/delete)
从 FormData 对象里面删除一个键值对。
[FormData.entries()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/entries)
返回一个包含所有键值对的[iterator](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Iteration_protocols)对象。
[FormData.get()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/get)
返回在 FormData 对象中与给定键关联的第一个值。
[FormData.getAll()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/getAll)
返回一个包含 FormData 对象中与给定键关联的所有值的数组。
[FormData.has()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/has)
返回一个布尔值表明 FormData 对象是否包含某些键。
[FormData.keys()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/keys)
返回一个包含所有键的[iterator](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Iteration_protocols)对象。
[FormData.set()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/set)
给 FormData 设置属性值,如果FormData 对应的属性值存在则覆盖原值,否则新增一项属性值。
[FormData.values()](https://developer.mozilla.org/zh-CN/docs/Web/API/FormData/values)
返回一个包含所有值的[iterator](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Iteration_protocols)对象。
服务端重定向对异步请求无效
注册成功后希望跳转到首页,这个时候重定向只能是客户端自己通过window.location.href方法跳转,不能通过服务端的res.redirect('/') 重定向
5.通过Session保存登录状态
cookie和session的区别:https://www.cnblogs.com/8023-CHD/p/11067141.html
Cookie 可以用来保存一些不太敏感的数据。记住用户名、购物车
但是不能用来保存用户登陆状态。isVIP: true
在 Express 这个框架中,默认不支持 Session 和 Cookie
我们可以使用第三方中间件:express-session 来解决
npm install express-session配置 (一定要在 app.use(router) 之前)
app.use(session({// 配置加密字符串,它会在原有加密基础之上和这个字符串拼起来去加密// 目的是为了增加安全性,防止客户端恶意伪造secret: 'itcast',resave: false,saveUninitialized: false // 无论你是否使用 Session ,我都默认直接给你分配一把钥匙}))
使用
- 当把这个插件配置好之后,我们就可以通过 req.session 来发访问和设置 Session 成员了
- 添加 Session 数据:
req.session.foo = 'bar' - 访问 Session 数据:
req.session.foo
注册成功,使用Session 记录用户的登录状态req.session.user = user,并传至首页进行用户数据的渲染
router.post('/register', async function (req,res) {//1. 获取表单提交得数据 body-parse//2. 操作数据库// 判断该用户是否已存在// 如果已存在不允许注册// 如果不存在,注册成功//3. 发送响应// console.log(req.body)let body = req.bodyUser.findOne({$or:[{email:body.email},{nickname:body.nickname}]}, function (err, data) {//josn 方法替换 send方法if (err) {return res.status(500).json({err_code:500,error_info:'服务端错误'})}// console.log(data)if(data) {return res.status(200).send({err_code: 1,error_info:'邮箱或者昵称已存在'})}//保存数据body.password = md5(md5(body.password)) //对密码进行加密new User(body).save(function (err, user) {if(err) {return res.status(500).json({err_code:500,error_info:'服务端错误'})}//注册成功,使用Session 记录用户的登录状态req.session.user = user//express 提供了一个响应方法:json 该方法接收一个对象作为参数,他会自动帮你把对象转为字符串再发送给浏览器res.status(200).json({err_code:0,message:'ok'})})})})
router.get('/', function (req, res) {console.log(req.session.user)res.render('index.html',{user:req.session.user})})
<ul class="nav navbar-nav navbar-right">{{ if user }}<a class="btn btn-default navbar-btn" href="/topics/new">发起</a><li class="dropdown"><a href="#" class="dropdown-toggle" data-toggle="dropdown" role="button" aria-haspopup="true" aria-expanded="false"><img width="20" height="20" src="../public/img/avatar-max-img.png" alt=""> <span class="caret"></span></a><ul class="dropdown-menu"><li class="dropdown-current-user">当前登录用户: {{ user.nickname }}</li><li role="separator" class="divider"></li><li><a href="#">个人主页</a></li><li><a href="/settings/profile">设置</a></li><li><a href="/logout">退出</a></li></ul></li>{{ else }}<a class="btn btn-primary navbar-btn" href="/login">登录</a><a class="btn btn-success navbar-btn" href="/register">注册</a>{{ /if }}</ul>
6.登录表单提交
router.post('/login', function (req,res) {// 1.获取表单数据//2. 查询数据库看用户是否存在//3. 发送响应let body = req.bodyUser.findOne({email:body.email,password:md5(md5(body.password))}, function (err, user) {if (err) {return res.status(500).json({err_code:500,message:err.message})}//用户不存在if(!user) {return res.status(200).json({err_code:1,message: '邮箱或密码错误'})}//用户存在,登录成功,通过Seesion记录登录状态req.session.user = userres.status(200).json({err_code: 0,message:'OK'})})})
不存在给出提示信息,存在用session保存登录状态
7.退出登录
退出登录分为两步:
1.清除Session登录状态
2.重定向到登录页
<li><a href="/logout">退出</a></li>
router.get('/logout', function (req,res) {//清除登录状态req.session.user = null//重定向到登录页res.redirect('/login')})
a 链接是同步请求,所以可以通过服务端重定向到登录页
此项目未完成部分
1.topic数据库的建立和连接
2.修改密码怎么将用户标识传递给到前端
3.头像上传
十一、中间件
中间件的概念
中间件:把很复杂的事情分割成单个,然后依次有条理的执行。就是一个中间处理环节,有输入,有输出。
说的通俗易懂点儿,中间件就是一个(从请求到响应调用的方法)方法。
把数据从请求到响应分步骤来处理,每一个步骤都是一个中间处理环节。
var http = require('http');var url = require('url');var cookie = require('./expressPtoject/cookie');var query = require('./expressPtoject/query');var postBody = require('./expressPtoject/post-body');var server = http.createServer(function(){// 解析请求地址中的get参数// var obj = url.parse(req.url,true);// req.query = obj.query;query(req,res); //中间件// 解析请求地址中的post参数req.body = {foo:'bar'}});if(req.url === 'xxx'){// 处理请求...}server.listen(3000,function(){console.log('3000 runing...');});
同一个请求对象所经过的中间件都是同一个请求对象和响应对象。
var express = require('express');var app = express();app.get('/abc',function(req,res,next){// 同一个请求的req和res是一样的,// 可以前面存储下面调用console.log('/abc');// req.foo = 'bar';req.body = {name:'xiaoxiao',age:18}next();});app.get('/abc',function(req,res,next){// console.log(req.foo);console.log(req.body);console.log('/abc');});app.listen(3000, function() {console.log('app is running at port 3000.');});
中间件的分类:
应用程序级别的中间件
万能匹配(不关心任何请求路径和请求方法的中间件):
app.use(function(req,res,next){console.log('Time',Date.now());next();});
关心请求路径和请求方法的中间件:
app.use('/a',function(req,res,next){console.log('Time',Date.now());next();});
路由级别的中间件
严格匹配请求路径和请求方法的中间件
get:
app.get('/',function(req,res){res.send('get');});
post:
app.post('/a',function(req,res){res.send('post');});
put:
app.put('/user',function(req,res){res.send('put');});
delete:
app.delete('/delete',function(req,res){res.send('delete');});
总
var express = require('express');var app = express();// 中间件:处理请求,本质就是个函数// 在express中,对中间件有几种分类// 1 不关心任何请求路径和请求方法的中间件// 也就是说任何请求都会进入这个中间件// 中间件本身是一个方法,该方法接收三个参数// Request 请求对象// Response 响应对象// next 下一个中间件// // 全局匹配中间件// app.use(function(req, res, next) {// console.log('1');// // 当一个请求进入中间件后// // 如果需要请求另外一个方法则需要使用next()方法// next();// // next是一个方法,用来调用下一个中间件// // 注意:next()方法调用下一个方法的时候,也会匹配(不是调用紧挨着的哪一个)// });// app.use(function(req, res, next) {// console.log('2');// });// // 2 关心请求路径的中间件// // 以/xxx开头的中间件// app.use('/a',function(req, res, next) {// console.log(req.url);// });// 3 严格匹配请求方法和请求路径的中间件app.get('/',function(){console.log('/');});app.post('/a',function(){console.log('/a');});app.listen(3000, function() {console.log('app is running at port 3000.');});
错误处理中间件
app.use(function(err,req,res,next){console.error(err,stack);res.status(500).send('Something broke');});
配置使用404中间件:
app.use(function(req,res){res.render('404.html');});
配置全局错误处理中间件:
app.get('/a', function(req, res, next) {fs.readFile('.a/bc', funtion() {if (err) {// 当调用next()传参后,则直接进入到全局错误处理中间件方法中// 当发生全局错误的时候,我们可以调用next传递错误对象// 然后被全局错误处理中间件匹配到并进行处理next(err);}})});//全局错误处理中间件app.use(function(err,req,res,next){res.status(500).json({err_code:500,message:err.message});});
内置中间件
- express.static(提供静态文件)
第三方中间件
- body-parser
- compression
- cookie-parser
- mogran
- response-time
- server-static
- session
十二、Nodejs中的流以及管道流
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。
Node.js,Stream 有四种流类型:
- Readable - 可读操作。
- Writable - 可写操作。
- Duplex - 可读可写操作.
- Transform - 操作被写入数据,然后读出结果。
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件有:
- data - 当有数据可读时触发。
- end - 没有更多的数据可读时触发。
- error - 在接收和写入过程中发生错误时触发。
- finish - 所有数据已被写入到底层系统时触发。
1.fs.createReadStream 从文件流中读取数据
const fs = require('fs')const readStream = fs.createReadStream('./data/input.txt') //创建读取流,读取data文件夹下的input.txt,一共有2万多条数据let count = 0 // 记录读取次数let str = '' // 读取的字符串readStream.on('data',(data) => {// str += datacount++})//读取结束readStream.on('end', ()=> {console.log(str)console.log(count) // 执行了20次})// 监听错误事件,比如没有这个文件readStream.on('error', (err) => {console.log(err)})
2.fs.createWriteStream 写入文件
const fs = require('fs')//要写入的数据let data = ''//创建一个写入流,写入到output.txt文件中const writeStream = fs.createWriteStream('./data/output.txt')for(let i = 0; i < 1000; i++ ) {data +='我是要写入的数据\n'}//使用utf8编码写入writeStream.write(data,'utf8')//标记写入完成 如果没有这个,finish事件就不会被触发writeStream.end()//处理流事件 finish 所有数据已经全部被写入时触发writeStream.on('finish', ()=>{console.log('写入完成')})//监听错误事件writeStream.on('error', (err) =>{console.log(err.stack)})
3.管道流
管道提供了一个输出流到输入流的机制。通常我们用于从一个流中获取数据并将数据传递到另外一个流中。
从一个流读取出来数据写入到另一个流,主要用于读取文件
const fs = require('fs')// 创建读取流读取图片const readStream = fs.createReadStream('./aaa.jpg')//创建写入流 写入到data 下的 aaa.jpgconst writeStream = fs.createWriteStream('./data/aaa.jpg')// 读取通过管道写入readStream.pipe(writeStream)
4.链式流
链式是通过连接输出流到另外一个流并创建多个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。
创建 compress.js 文件, 代码如下:
var fs = require("fs");var zlib = require('zlib');// 压缩 input.txt 文件为 input.txt.gzfs.createReadStream('input.txt').pipe(zlib.createGzip()).pipe(fs.createWriteStream('input.txt.gz'));console.log("文件压缩完成。");
执行完以上操作后,我们可以看到当前目录下生成了 input.txt 的压缩文件 input.txt.gz。
接下来,让我们来解压该文件,创建 decompress.js 文件,代码如下:
var fs = require("fs");var zlib = require('zlib');// 解压 input.txt.gz 文件为 input.txtfs.createReadStream('input.txt.gz').pipe(zlib.createGunzip()).pipe(fs.createWriteStream('input.txt'));console.log("文件解压完成。");
十三、Nodejs事件循环
为什么是事件驱动的,因为他是单线程单进程的应用程序,只能通过异步事件处理不同的事件。
V8 引擎提供的异步执行回调接口,通过这些接口可以处理大量的并发,所以性能非常高。
Node.js 几乎每一个 API 都是支持回调函数的。
Node.js 基本上所有的事件机制都是用设计模式中观察者模式实现。
- 在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们成为Tick。
- 每个Tick的过程就是查看是否有事件待处理。如果有就取出事件及其相关的回调函数。然后进入下一个循环,如果不再有事件处理,就退出进程。
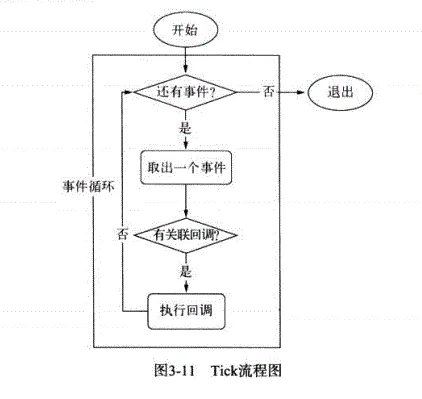
在每个tick的过程中,如何判断是否有事件需要处理呢?
- 每个事件循环中有一个或者多个观察者,而判断是否有事件需要处理的过程就是向这些观察者询问是否有要处理的事件。
- 在Node中,事件主要来源于网络请求、文件的I/O等,这些事件对应的观察者有文件I/O观察者,网络I/O的观察者。
- 事件循环是一个典型的生产者/消费者模型。异步I/O,网络请求等则是事件的生产者,源源不断为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
- 在windows下,这个循环基于IOCP创建,在*nix下则基于多线程创建
事件驱动程序
Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。
当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
这个模型非常高效可扩展性非常强,因为 webserver 一直接受请求而不等待任何读写操作。(这也称之为非阻塞式IO或者事件驱动IO)
在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。
Node.js 有多个内置的事件,我们可以通过引入 events 模块,并通过实例化 EventEmitter 类来绑定和监听事件,如下实例:
实例
let fs = require('fs')// 引入 events 模块var events = require('events');// 创建 eventEmitter 对象var eventEmitter = new events.EventEmitter();fs.readFile('hellow.txt', 'utf8', (err, data) => {if (err) {console.log(err)}else {console.log(data)eventEmitter.emit('fileSucess',data) // 触发事件}})// 绑定事件eventEmitter.on('fileSucess', function(eventMsg){console.log('1查看数据库数据')})eventEmitter.on('fileSucess', function(eventMsg){console.log('2查看数据库数据')})eventEmitter.on('fileSucess', function(eventMsg){console.log('3查看数据库数据')})
EventEmitter 提供了多个属性,如 on 和 emit。on 函数用于绑定事件函数,emit 属性用于触发一个事件。
eventEmitter底层原理
Node.js 所有的异步 I/O 操作在完成时都会发送一个事件到事件队列。
Node.js 里面的许多对象都会分发事件:一个 net.Server 对象会在每次有新连接时触发一个事件, 一个 fs.readStream 对象会在文件被打开的时候触发一个事件。 所有这些产生事件的对象都是 events.EventEmitter 的实例。
events 模块只提供了一个对象: events.EventEmitter。EventEmitter 的核心就是事件触发与事件监听器功能的封装。下面自己模拟实现eventEmitter
let fs = require('fs')fs.readFile('hellow.txt', 'utf8', (err, data) => {if (err) {console.log(err)}else {console.log(data)eventEmitter.emit('fileSucess',data)}})// 模拟eventEmitterlet eventEmitter = {//事件名称event:{// fileSucess:[fn, fn, fn], //一个事件可能对应多个事件监听器,所以要用数组的形式存入// filefailed:[fn, fn, fn] //一个事件可能对应多个事件监听器},//事件绑定on:function(eventName, eventFn) {if(this.event[eventName]) { //如果对应事件的名称存在就直接将事件监听器存入this.event[eventName].push(eventFn)}else { // 如果对应事件的名称不存在就创建一个对应的数组,然后将事件监听器存进去this.event[eventName] = []this.event[eventName].push(eventFn)}},//事件输出emit:function(eventName, eventMsg) {if(this.event[eventName]) {this.event[eventName].forEach(itemFn => {itemFn(eventMsg)});}}}eventEmitter.on('fileSucess', function(eventMsg){console.log('1查看数据库数据')})eventEmitter.on('fileSucess', function(eventMsg){console.log('2查看数据库数据')})eventEmitter.on('fileSucess', function(eventMsg){console.log('3查看数据库数据')})
EventEmitter 的每个事件由一个事件名和若干个参数组成,事件名是一个字符串,通常表达一定的语义。EventEmitter 支持 每个事件可以有若干个事件监听器。
当事件触发时,注册到这个事件的事件监听器被依次调用,事件参数作为回调函数参数传递。典型的发布订阅模式。
Node 应用程序是如何工作的?
在 Node 应用程序中,执行异步操作的函数将回调函数作为最后一个参数, 回调函数接收错误对象作为第一个参数。
var fs = require("fs");fs.readFile('input.txt', function (err, data) {if (err){console.log(err.stack);return;}console.log(data.toString());});console.log("程序执行完毕");
以上程序中 fs.readFile() 是异步函数用于读取文件。 如果在读取文件过程中发生错误,错误 err 对象就会输出错误信息。
如果没发生错误,readFile 跳过 err 对象的输出,文件内容就通过回调函数输出。
十四、同步IO与异步IO
同步IO:在一个线程中,CPU执行代码的速度极快,然而,一旦遇到IO操作,如读写文件、发送网络数据时,就需要等待IO操作完成,才能继续进行下一步操作。IO期间CPU会转去执行其他线程。
异步IO:当遇到IO操作时,CPU只是发送IO指令,不等待结果,然后继续执行其他代码。一段时间后,当IO返回结果时,再通知CPU进行处理。
异步IO模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程
同步:如果有阻塞的任务就让另一个线程去执行,主线程执行非阻塞任务。
异步:通过事件驱动,当事件发生的时候调用对应处理函数。
同步适合计算量大的任务,异步适合IO操作量大的,比如读取文件。各有所长。
事件驱动模型
1.为什么要有异步I/O?
用户体验
因为js在执行的时候UI渲染和响应是处于停滞状态的,不会响应用户的任何交互行为,用户体验极差。而采用异步的方式,在加载资源期间,js和UI都不会处于等待状态,可以继续响应用户的行为,给用户一个鲜活的页面。
资源分配
多线程的代价是创建线程和执行期线程上下文切换开销大,经常面临着死锁,状态同步等问题,所以采用单线程更好一点,但是,在计算机资源中,通常I/O和CPU计算之间是可以并行执行的。但是同步导致的问题是,I/O进行会让后续任务等待,造成资源不能被更好的利用。异步I/O可以让单线程远离阻塞,更好的利用CPU。
2.异步I/O的实现
采用线程池与阻塞I/O模拟异步I/O。node提供了libuv作为抽象封装层,使得所有平台都兼容。
十五、非I/O的异步API
1.定时器
settimeout() 或者setInterval() 分别用于单次和多次定时执行任务。
定时器的实现原理与异步I/O比较类似,只是不需要线程池I/O线程池的参与。调用settimeout() 或者setInterval() 创建的定时器会被插入到定时器观察者内部的一个红黑树中,每次Tick执行时会从该红黑树中迭代取出定时器对象,检查是否超过定时时间,如果超过就形成一个事件,它的回调函数将立即执行。定时器的问题在于它并非是精确的。时间复杂度为O(lg(n))。
2.process.nextTick()
mei次调用process.nextTick()方法,只会将回调函数放入队列中,在下一轮tick时取出执行。时间复杂度为O(1).
3.setImmediate()
setImmediate()与process.nextTick()非常相似。但是process.nextTick()的优先级高于setImmediate(),这是因为事件循环对观察者的检查是有顺序的,setImmediate()属于check观察,process.nextTick()属于idle观察,每一轮循环检查中,idle观察先于I/O观察,I/O观察先于check观察。如下图:
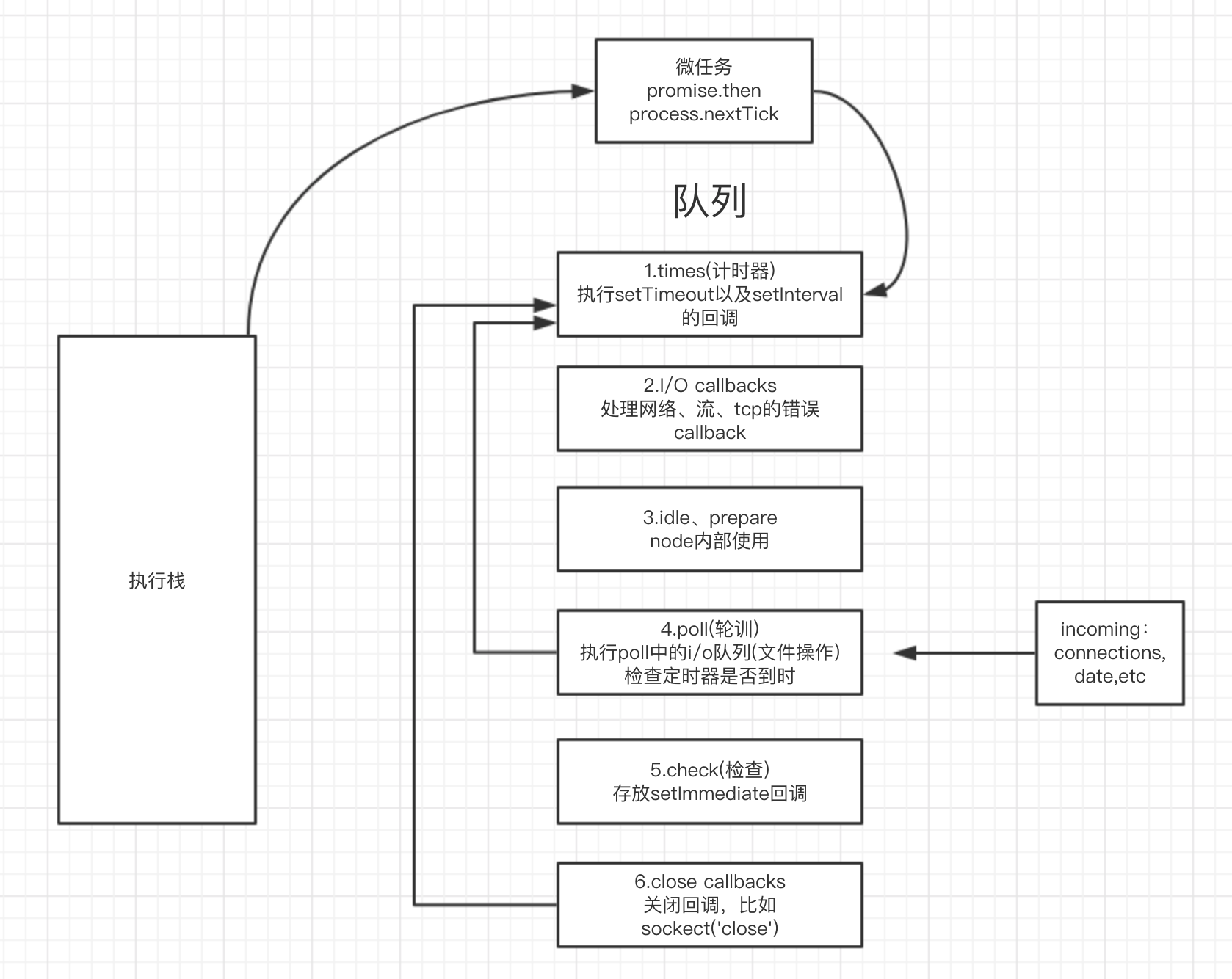
在具体实现上,process.nextTick()的回调函数保存在 一个数组中,setImmediate() 的结果则是保存在链表中。process.nextTick()在每轮循环中会将数组中的回调函数全部执行完。而setImmediate() 在每轮循环中执行链表中的一个回调函数。
在循环事件任务完成后马上运行指定代码
以前使用 setTimeout(fn, 0);
Since browsers clamp their timers to 4ms, it really doesn’t matter if you say 0, 1, 2, 3, or 4
计时器间隔至少为 4毫秒,所以事实上 setTimeout(fn, 0) 并不是立即运行的
而setImmediate() 则可以立即运行
只用 ie10 支持,Mozilla and WebKit 不感冒
如果是做动画应该使用 requestAnimationFrame() 代替 setImmediate(fn, 0),这是浏览器提供用于做动画的API,DOM-based样式改变,或者canvas,或者WebGL都可以使用
用settimeout最大的问题是屏幕显示更新的频率和settimeout定义的时间不同
十六、nodejs事件循环和浏览器事件循环
https://juejin.im/post/5ba85ce26fb9a05d2f36af01
https://www.jianshu.com/p/5f1a8f586019
1.循环机制
JavaScript中事件循环,主要就在理解宏任务和微任务这两种异步任务。
宏任务(macrotask):
setTimeOut 、 setInterval 、 setImmediate 、 I/O 、 各种callback、 UI渲染 、messageChannel等
优先级:主代码块 > setImmediate > postMessage > setTimeOut/setInterval
微任务(microtask):
process.nextTick 、Promise 、MutationObserver 、async(实质上也是promise)
优先级:process.nextTick > Promise > MutationOberser
Node.js采用V8作为js的解析引擎,而I/O处理方面使用了自己设计的libuv,libuv是一个基于事件驱动的跨平台抽象层,封装了不同操作系统一些底层特性,对外提供统一的API,事件循环机制也是它里面的实现。它靠的是多线程实现的(worker threads),它用多线程模拟了异步的机制,我们每次调用node api的时候,它里面会进入LIBUV调用多个线程执行,同步堵塞调用,模拟了异步的机制,成功以后,通过callback执行放到一个队列里,然后返回给我们的客户端。
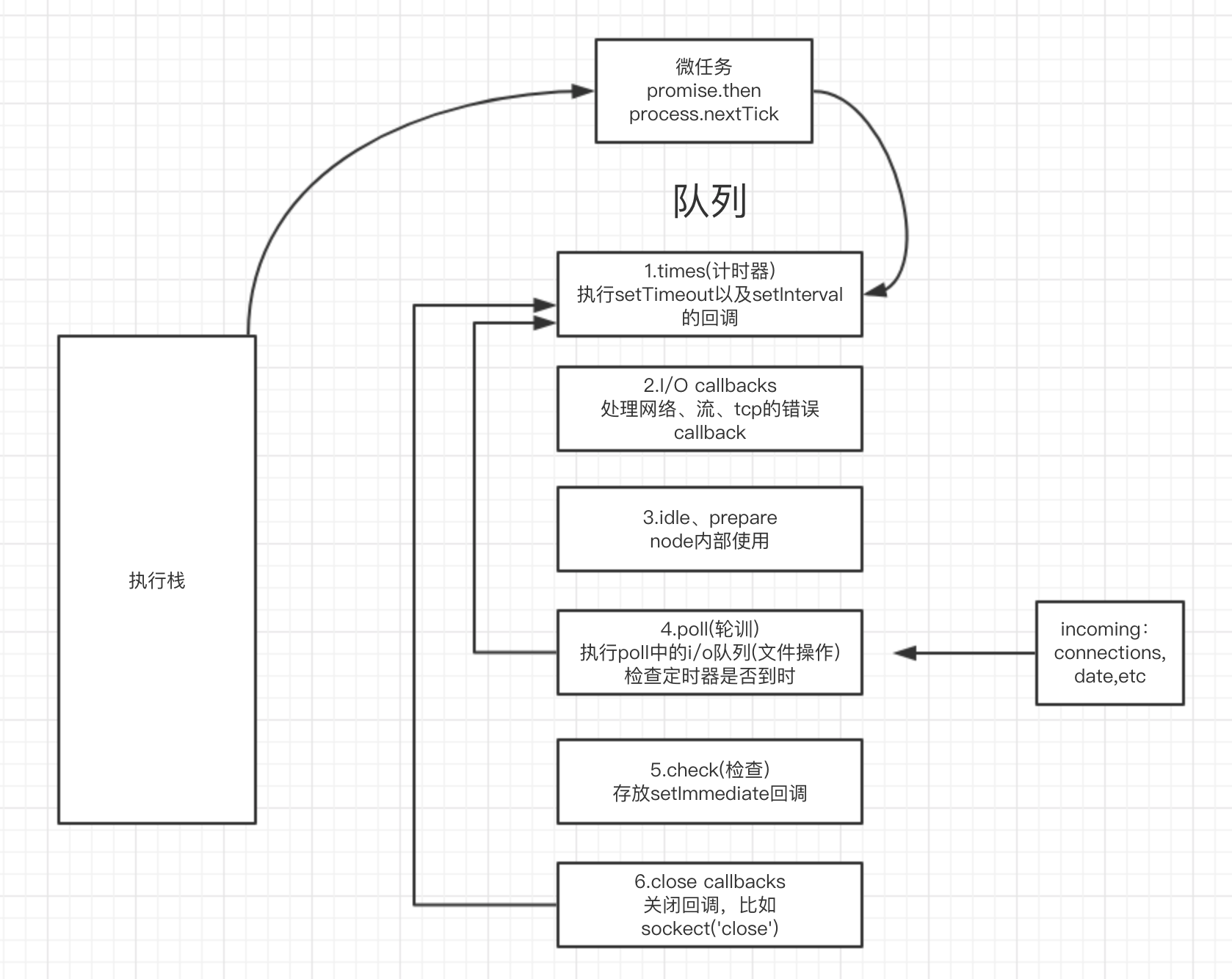
2.对于微任务的处理不同
浏览器环境下,当执行栈清空后,会执行完所有微任务的队列,然后再到宏任务队列取一个事件到执行栈执行,重点,取一个,不是取所有的,执行完后,再到微任务队列清空所有微任务,再跑去宏任务队列取一个事件到执行栈执行。
对于微任务的处理,和浏览器事件环机制不同,node中,宏任务阶段遇到微任务不会立马执行微任务,而是等待宏任务队列清空之后,再去执行微任务。
十七、Buffer
js语言只要字符串类型的数据,没有二进制类型的,但在处理像文件流时(文件读写操作),必须使用到二进制数据,因此在Nodejs中定义了一个Buffer类,该类用来创建一个专门存放二进制数据的缓冲区,它的元素为16进制的两位数,类似于一个从 0 到 255 之间的整数数组,但对应于固定大小的内存块,并且不能包含任何其他值。 一个 Buffer 的大小在创建时确定,且无法更改。
Buffer 类在全局作用域中,因此无需使用 require('buffer').Buffer。
1.创建Buffer对象
- Buffer.from(array) 根绝一个数组创建Buffer对象
- Buffer.from(String[,encoding])根据字符串创建Buffer对象,默认utf8,可以指定字符编码
- Buffer.alloc(size) 创建指定长度的Buffer对象。创建以零初始化的 Buffer 实例。
- Buffer.allocUnsafe() 创建的 Buffer 实例的底层内存是未初始化的。 新创建的 Buffer 的内容是未知的,可能包含敏感数据。
let buf1 = Buffer.from([98, 97, 96]) // <Buffer 62 61 60>let buf2 = Buffer.from('allsll') // <Buffer 61 6c 6c 73 6c 6c>let buf3 = Buffer.alloc(10) // <Buffer 00 00 00 00 00 00 00 00 00 00>console.log(buf1, buf2, buf3)
2.Buffer的内存分配机制
为了高效的使用申请来的内存,Node采用了slab分配机制。slab是一种动态的内存管理机制。 Node以8kb为界限来来区分Buffer为大对象还是小对象,如果是小于8kb就是小Buffer,大于8kb就是大Buffer。
例如第一次分配一个1024字节的Buffer,Buffer.alloc(1024),那么这次分配就会用到一个slab,接着如果继续Buffer.alloc(1024),那么上一次用的slab的空间还没有用完,因为总共是8kb,1024+1024 = 2048个字节,没有8kb,所以就继续用这个slab给Buffer分配空间。如果slab内存空间不足就会重新分配一个新的slab,原slab中剩余的空间将会造成浪费。
如果超过8kb,那么直接用C++底层地宫的SlowBuffer来给Buffer对象提供空间。
3.属性
length:返回 buf 的字节长度,若想修改 Buffer 的字节长度,应将 length 属性视为只读,并使用 buf.slice() 创建一个新的Buffer
4.Buffer 类型转换
buf.toString([encoding], [start], [end]) buffer 转字符串
newBuffer(str, [encoding]) 字符串转buffer。
一个Buffer对象可以存储不同编码类型的字符串转码值,调用write方法可以实现。
buf.write(string, [offset], [length], [encoding])
5.Buffer乱码问题
例如一个份文件test.md里的内容如下:
床前明月光,疑是地上霜,举头望明月,低头思故乡复制代码
我们这样读取就会出现乱码:
var rs = require('fs').createReadStream('test.md', {highWaterMark: 11});// 床前明???光,疑???地上霜,举头???明月,???头思故乡复制代码
一般情况下,只需要设置rs.setEncoding(‘utf8’)即可解决乱码问题
6.Buffer类方法
十八、fs模块
const fs = require('fs')//1.fs.stat 获取文件信息fs.stat('./index.html', (err, data) => {if(err) {console.log(err)return}console.log(data)console.log(`是文件: ${data.isFile()}`) //true isFile() 检测是否是文件console.log(`是目录:${data.isDirectory()}`) //false 检测是否是目录})// 2.fs.mkdir 创建目录 若目录已经存在就会返回错误信息fs.mkdir('./home', (err) => {if(err) {console.log(err)return}console.log('创建成功')})//3.fs.writeFile 创建以及写入 如果文件不存在的话会自动创建并且写入,但是不会创建目录的,如果文件存在就直接直接替换文件原来的内容fs.writeFile('./home/index.html', '我是首页','utf8', (err) =>{if(err) {console.log(err)return}console.log('创建以及写入文件成功')})//使用Bufferlet buf1 = Buffer.from('床前明月光')fs.writeFile('./home/index.html', buf1, (err) =>{if(err) {console.log(err)return}console.log('创建以及写入文件成功')})// 使用stream模式见十一。// Buffer模式就是取完数据一次性操作 stream模式是边取数据边操作,一点一点/***file <string> | <Buffer> | <URL> | <integer> 文件名或文件描述符。data <string> | <Buffer> | <TypedArray> | <DataView>options <Object> | <string>encoding <string> | <null> 默认值: 'utf8'。mode <integer> 默认值: 0o666。flag <string> 参见文件系统 flag 的支持。 默认值: 'w'。callback <Function>err <Error>当 file 是文件名时,则异步地写入数据到文件(如果文件已存在,则覆盖文件)。 data 可以是字符串或 buffer。当 file 是文件描述符时,则其行为类似于直接调用 fs.write()(建议使用)。 参见以下关于使用文件描述符的说明。如果 data 是 buffer,则 encoding 选项会被忽略。*/// 4. fs.appendfile 创建并追加文件// 如果是要追加到某个文件夹下则这个文件夹必须存在的情况下才能追加成功fs.appendFile('./css/bass.css', 'body{color:red}\n',(err) => {if(err) {console.log(err) // 若没有错误就是 nullreturn}console.log('追加成功')})// 如果文件已经存在,不会替换原文件内容,而是追加到后面fs.appendFile('./css/bass.css', 'h2{color:red}',(err) => {if(err) {console.log(err)return}console.log('追加成功')})//5.fs.readFile 读取文件fs.readFile('./home/index.html', (err, data) =>{if(err) {console.log(err)return}console.log(data) // 这个数据是buffer类型,console.log(data.toString()) // 通过toString方法转换成string类型})//6.fs.readdir 读取目录fs.readdir('./home',(err, data) =>{if(err){console.log(err)return}console.log(data) // 数组格式 [ 'index.html' ]})//7.fs。rename 重命名 移动文件// fs.rename('./css')// 8. fs.rmdir 删除目录 如果目录下有别的文件就不能直接删除,需要先删除文件再删除目录fs.rmdir('./aaaa', (err) => {if(err) {console.log(err)}console.log('删除目录成功')})//9. fs.unlink 删除文件fs.unlink('./aaaa/index.html', (err) =>{if(err) {console.log(err)return}console.log('删除文件成功')})
十九、url模块
二十、Commonjs包规范和Nodejs包实现
CommonJS 规范的包应该具备以下特征:
package.json是CommonJS规定的用来面熟包的文件,完全符合规范的文件应包含以package.json下字段。
二十一、V8的垃圾回收机制
1. 如何查看V8的内存使用情况
使用process.memoryUsage()返回如下
{rss: 4935680,heapTotal: 1826816,heapUsed: 650472,external: 49879}复制代码
heapTotal 和 heapUsed 代表V8的内存使用情况。 external代表V8管理的,绑定到Javascript的C++对象的内存使用情况。 rss, 驻留集大小, 是给这个进程分配了多少物理内存(占总分配内存的一部分) 这些物理内存中包含堆,栈,和代码段。
2. V8的内存限制是多少,为什么V8这样设计
64位系统下是1.4GB, 32位系统下是0.7GB。因为1.5GB的垃圾回收堆内存,V8需要花费50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起Javascript线程暂停执行的事件,在这样的花销下,应用的性能和影响力都会直线下降。
3. V8的内存分代和回收算法请简单讲一讲
在V8中,主要将内存分为新生代和老生代两代。新生代中的对象存活时间较短的对象,老生代中的对象存活时间较长,或常驻内存的对象。

3.1 新生代
新生代中的对象主要通过Scavenge算法进行垃圾回收。这是一种采用复制的方式实现的垃圾回收算法。它将堆内存一份为二,一个处于使用中,另一个处于闲置状态。处于使用状态的空间称为From空间,处于闲置状态的空间称为To空间。

- 当开始垃圾回收的时候,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。完成复制后,From空间和To空间发生角色对换。
- 应为新生代中对象的生命周期比较短,就比较适合这个算法。
- 当一个对象经过多次复制依然存活,它将会被认为是生命周期较长的对象。这种新生代中生命周期较长的对象随后会被移到老生代中。
3.2 老生代
老生代主要采取的是标记清除的垃圾回收算法。与Scavenge复制活着的对象不同,标记清除算法在标记阶段遍历堆中的所有对象,并标记活着的对象,只清理死亡对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是为什么采用标记清除算法的原因。
3.3 标记清楚算法的问题
主要问题是每一次进行标记清除回收后,内存空间会出现不连续的状态

- 这种内存碎片会对后续内存分配造成问题,很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
- 为了解决碎片问题,标记整理被提出来。就是在对象被标记死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。
3.4 哪些情况会造成V8无法立即回收内存
闭包和全局变量
3.5 请谈一下内存泄漏是什么,以及常见内存泄漏的原因,和排查的方法
什么是内存泄漏
- 内存泄漏(Memory Leak)指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。
- 如果内存泄漏的位置比较关键,那么随着处理的进行可能持有越来越多的无用内存,这些无用的内存变多会引起服务器响应速度变慢。
- 严重的情况下导致内存达到某个极限(可能是进程的上限,如 v8 的上限;也可能是系统可提供的内存上限)会使得应用程序崩溃。
- 内存泄漏的几种情况:
- 缓存
- 队列消费不及时
- 作用域未释放
一、全局变量
a = 10;//未声明对象。global.b = 11;//全局变量引用这种比较简单的原因,全局变量直接挂在 root 对象上,不会被清除掉。复制代码
二、闭包。
function out() {const bigData = new Buffer(100);inner = function () {}}复制代码
闭包会引用到父级函数中的变量,如果闭包未释放,就会导致内存泄漏。上面例子是 inner 直接挂在了 root 上,那么每次执行 out 函数所产生的 bigData 都不会释放,从而导致内存泄漏。
需要注意的是,这里举得例子只是简单的将引用挂在全局对象上,实际的业务情况可能是挂在某个可以从 root 追溯到的对象上导致的。
三、事件监听
Node.js 的事件监听也可能出现的内存泄漏。例如对同一个事件重复监听,忘记移除(removeListener),将造成内存泄漏。这种情况很容易在复用对象上添加事件时出现,所以事件重复监听可能收到如下警告:
emitter.setMaxListeners() to increase limit复制代码
例如,Node.js 中 Agent 的 keepAlive 为 true 时,可能造成的内存泄漏。当 Agent keepAlive 为 true 的时候,将会复用之前使用过的 socket,如果在 socket 上添加事件监听,忘记清除的话,因为 socket 的复用,将导致事件重复监听从而产生内存泄漏。
原理上与前一个添加事件监听的时候忘了清除是一样的。在使用 Node.js 的 http 模块时,不通过 keepAlive 复用是没有问题的,复用了以后就会可能产生内存泄漏。所以,你需要了解添加事件监听的对象的生命周期,并注意自行移除。
排查方法
想要定位内存泄漏,通常会有两种情况:
- 对于只要正常使用就可以重现的内存泄漏,这是很简单的情况只要在测试环境模拟就可以排查了。
- 对于偶然的内存泄漏,一般会与特殊的输入有关系。想稳定重现这种输入是很耗时的过程。如果不能通过代码的日志定位到这个特殊的输入,那么推荐去生产环境打印内存快照了。
- 需要注意的是,打印内存快照是很耗 CPU 的操作,可能会对线上业务造成影响。 快照工具推荐使用 heapdump 用来保存内存快照,使用 devtool 来查看内存快照。
- 使用 heapdump 保存内存快照时,只会有 Node.js 环境中的对象,不会受到干扰(如果使用 node-inspector 的话,快照中会有前端的变量干扰)。
- PS:安装 heapdump 在某些 Node.js 版本上可能出错,建议使用 npm install heapdump -target=Node.js 版本来安装。

若有收获,就点个赞吧
0 人点赞
