文中观点仅代表个人学习与观点沉淀,用于学习交流。文中涉及到任何内容,与本人呆过的所有公司无关,思路仅供参考。
感谢您花时间阅读本篇文章,本篇文章主要介绍编译原理思想在前端的应用,通过阅读本篇文章您能了解到:编译原理概述, 编译思想在前端工程中应用,编译思想在低代码平台的应用,通过本篇文章阅读希望可以给您在后续的工作中提供一些思路。对于编译原理涉及到技术细节和算法,本篇文章中不再讲述,感兴趣的话可查阅相关资料。
一、前言
从互联网时代初至今, 从Web1.0静态展示型到 Web2.0 重交互型发展,软件应用的复杂度越来越高。前端领域需进一步提高研发效率,在此过程中针对细分领域诞生了各种语言及配套工具。而在这些工具中编译原理及其思想被反复在前端中使用。有必要了解、学习基本原理和应用场景,来更好的解决业务问题。
二、编译原理概述
2.1 什么是编译原理
- 编译原理:我们当前使用的程序设计语言(如 C, Java等)有别于早期的机器语言,在一个程序可运行之前首先被翻译成一种能够被计算机理解的机器码, 这部分工作通常由编译器(compiler)或解释器(interpreter)。而编译原理是计算机专业的一门重要专业课,旨在介绍编译构造的一般原理和基本方法。内容包括语言和文法、词法分析、语法分析、语法制导翻译、中间代码生成、存储管理、代码优化和目标代码生成。
编译器和解释器
本职工作:JavaScript本身也属于程序设计语言,通过了解 JS 执行时解释器工作原理,可以帮助更好的理解代码运行,优化代码,基于JavaScript 本身做些扩展(如Flow 静态类型检查器,JSDoc 文档生成等等)。
- 工程实践:前端发展过程中,工程实践工具越来越多,如 CSS预处理工具 less, JavaScript编译器 Babel等 而大多以前端设计语言(HTML/CSS/JS)为源程序进行编译处理,了解工具的编译处理过程,可以更好的追踪和处理问题。
- 应用领域:把编译思想升维,源程序为领域特定语言(DSL),编译处理成目标程序,如低代码平台生成多端复用应用,生成多技术栈代码等。把编译思想的空间维度转移到业务场景中可能会有更大的解决思路。
三、在前端中的应用
编译原理在前端中有很多应用,这里列举几个常见的应用例子,便于理解。3.1 JS 执行机制
JS执行机制整理流程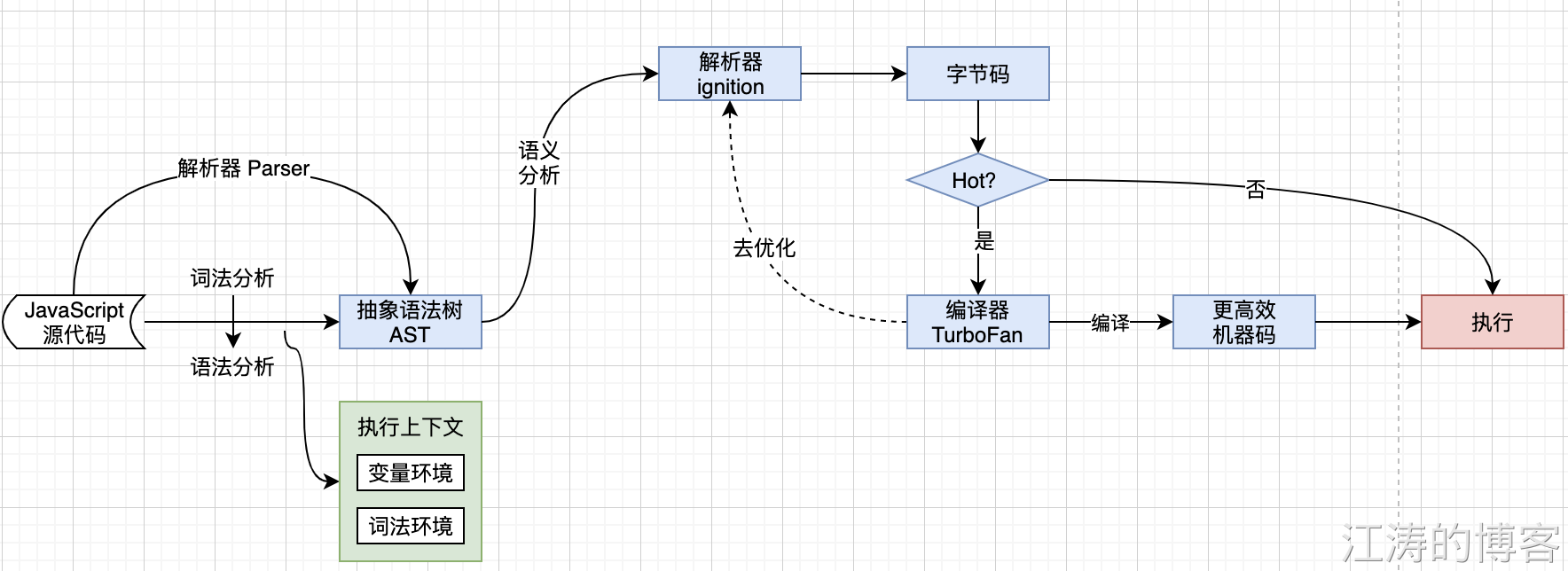
3.1.1 生成抽象语法树(AST)和执行上下文
3.1.1.1 生成抽象语法树
对于我们开发者而言,JavaScript 源代码是对我们较为友好的理解,但对于编译器来说生成抽象语法树 AST 更好理解,好比 HTML 生成 DOM 树浏览器更好理解。
生成抽象语法树经过两个阶段
词法分析
词法解析,将一行行源代码解析成 token 单元,所谓 token 单元是语法上不能再分的最小单元。可以通过下图理解: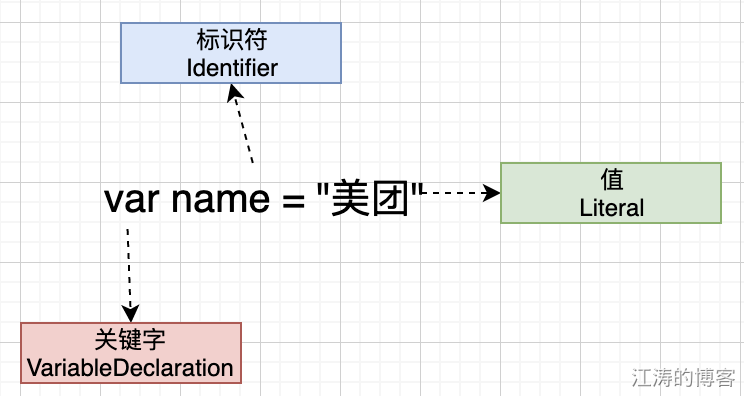


上面的代码,由关键字var, 标识符 name,值literal 组成。更多的 token 组成,可以通过ast工具查看生成的 token 单元描述。
语法分析
根据上述生成的词法 token 单元,根据 JS 语法规则,生成 ast。如果源码符合语法规则,顺利生成 ast。但若存在语法错误,这一步就会终止,并抛出一个“语法错误”。生成 ast 后,生成执行上下文。
var name = "美团"function foo(a){return '我是' + a + '员工';}name = "meituan"foo(name)
{"type": "Program","start": 0,"end": 87,"body": [{"type": "VariableDeclaration","start": 0,"end": 15,"declarations": [{"type": "VariableDeclarator","start": 4,"end": 15,"id": {"type": "Identifier","start": 4,"end": 8,"name": "name"},"init": {"type": "Literal","start": 11,"end": 15,"value": "美团","raw": "\"美团\""}}],"kind": "var"},{"type": "FunctionDeclaration","start": 16,"end": 60,"id": {"type": "Identifier","start": 25,"end": 28,"name": "foo"},"expression": false,"generator": false,"async": false,"params": [{"type": "Identifier","start": 29,"end": 30,"name": "a"}],"body": {"type": "BlockStatement","start": 31,"end": 60,"body": [{"type": "ReturnStatement","start": 35,"end": 58,"argument": {"type": "BinaryExpression","start": 42,"end": 57,"left": {"type": "BinaryExpression","start": 42,"end": 50,"left": {"type": "Literal","start": 42,"end": 46,"value": "我是","raw": "'我是'"},"operator": "+","right": {"type": "Identifier","start": 49,"end": 50,"name": "a"}},"operator": "+","right": {"type": "Literal","start": 53,"end": 57,"value": "员工","raw": "'员工'"}}}]}},{"type": "ExpressionStatement","start": 61,"end": 77,"expression": {"type": "AssignmentExpression","start": 61,"end": 77,"operator": "=","left": {"type": "Identifier","start": 61,"end": 65,"name": "name"},"right": {"type": "Literal","start": 68,"end": 77,"value": "meituan","raw": "\"meituan\""}}},{"type": "ExpressionStatement","start": 78,"end": 87,"expression": {"type": "CallExpression","start": 78,"end": 87,"callee": {"type": "Identifier","start": 78,"end": 81,"name": "foo"},"arguments": [{"type": "Identifier","start": 82,"end": 86,"name": "name"}],"optional": false}}],"sourceType": "module"}
3.1.1.2 生成执行上下文
本篇文章主要围绕编译相关介绍进行,执行上下文这里做简单的介绍。
当 AST 生成后,会生成执行上下文,执行上下文是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行。
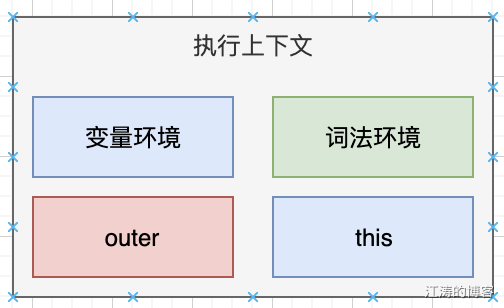
执行上下文生命周期为: 创建阶段,执行阶段,回收阶段。执行上下文创建后,会生成以下几个指针和环境:
- 变量环境:记录变量、函数。在进行编译之前会将相关变量、函数,预先存储到变量环境中,当代码执行时从变量环境中取出。
- 词法环境:有let或者const声明的变量,编译后存放到该函数的词法环境
- outer: 指向外部作用链,用于维护作用域链关系
- this指向: this 和执行上下文有关,1 个执行上下文有一个this
3.1.1.3 js 执行
有了ast 和执行上下文之后, 遇到 ignition 解析器 解析成字节码。如果一段代码多次触发,会标记为 hot,触发turboFan 编译器,将字节码编译成更高效的机器码存储,当下次再次执行,使用优化后的机器码执行,以此来提高 js 执行效率。
turboFan 编译器去优化,举个例子,当执行函数100 次 时,假设前 90次 参数为 init,第 91 次是其他类型,此时turboFan 编译器进行去优化操作,重新回到 ignition 解析器 解析成字节码并执行阶段,去优化代价比较昂贵,在实际编码中注意去优化操作。
3.2 前端工程中的应用
3.2.1 doc生成
doc生成的例子有很多经典的 JS Doc, Swagger API, VuePress等。找了一个相对来说解析、处理过程较单一的场景来说明编译思想的应用。
3.2.1.1 背景
在之前工作中基于 Koa 的 Node.js 框架,有大量的 API 需要书写,API 文档书写成本较高,而 Restful API 生成文档较单一,因此需要提供一套可根据源代码范式生成API 文档的工具。
3.2.1.2 思路
我们把 源代码作为输入, 最终的markdown 结果,视图流程如下:
export default class ListController {// 获取当前用的订单信息@RequestUrl('/list', RequestUrl.GET)@RequestParam('text', 'required', '名称')@RequestParam('nickname', '*', '昵称')@RequestMock(getMockName(conf.mock.dir), conf.mock.enabled)async action(ctx, next) {ctx.body = `hello ${ctx.getParameter('text')}`}}

3.2.1.3 实现流程
上面源代码的范式基于 JS class Decorator 实现,集中式管理Node API地址,请求参数,请求规则,Mock 数据等。感兴趣这里可以查看代码 主要介绍 doc 生成的工作流程:
- 源码解析:可以用任意JS解析器,选择对 ESModule 较为友好的babylon解析,实例中的代码通过 decorators定义信息,生成后的 AST decorator 中存储着关键信息

语义分析: 通过提取 ast的 每个decorator信息, 这里只对 RequestUrl, RequestParam信息提取,代码实现逻辑可点击查看
[{"params": [["text","required","名称"],["nickname","*","昵称"]],"comment": " 获取当前用的订单信息","url": "/list","method": "GET"}]
编译生成markdown: 关键数据生成markdown 的过程,可以看作一次编译过程,实现过程把相关的数据拼装成 markdown 语法
- 写入文件: 最后将文本写入对应文件即可。
四、低代码平台中应用
4.1 什么是低代码平台
看到这里可能会有疑问, 为什么编译思想在低代码领域有所应用。先了解下什么是低代码平台,低代码平台是通过少量代码就可以快速生成应用程序的开发平台,可以通过图形化的用户界面,使用拖拽组件或模型驱动的逻辑来创建应用的平台。
低代码平台因面向用户和面向领域,实现方式等不同,有不同的称谓,如搭建平台,无代码平台等。具体可查看开源的 awsome-lowcode一些介绍。4.2 页面编辑器工作流程
不同的低代码平台对于 实体的抽象不同,但最核心页面编辑器(视图、交互、数据),页面编辑器输出 (页面视图、交互、数据)的表示DSL(领域特定语言),DSL 回显到页面编辑器,展示再编辑等。为了让存储的 DSL,创建应用,需要将 DSL 转换为浏览器可识别的语言,将 DSL 转换到小程序、手机端等不同平台展示。具体的流程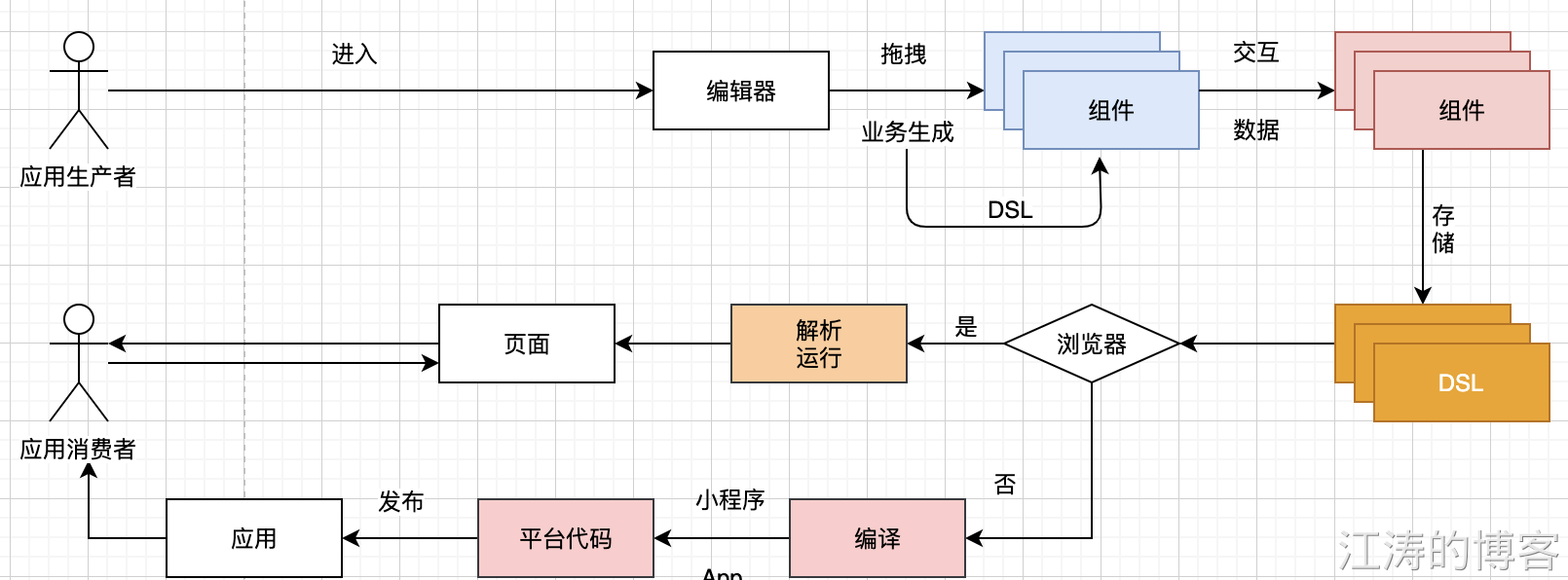
从核心的DSL来看,DSL 是组件的表示,若想在浏览器中运行, 需要通过对 DSL 进行解析和转换在浏览器动态运行(和业务强相关的 DSL 会通过编译来处理,进行数据脱敏,数据组装、加工、鉴权等),若存在不同平台需要对 DSL 进行编译处理成不同平台可运行的代码,发布后运行。整个过程和编译思想相似,每个阶段面向对象有所区别。
在整个低代码平台中 页面编辑器 是低代码平台的核心承载,应用生产者的输入和调整都是通过编辑器来制作,就好比开发者通过 IDE 进行代码研发一样。
4.3 页面编辑器
4.3.1 编辑器界面
以之前公司的无代码平台编辑器设计为例。把页面拆成三部分: 视图、交互、数据。
- 视图:视图主要由组件组成,组件分为基础组件,布局组件,业务组件,容器组件等。组件需要排版展示,样式修改
- 交互:交互行为分为前端行为(事件行为、页面行为),后端行为(流程关联、逻辑处理)
- 数据:数据主要是数据查询,接口调用等。
视图与数据之间 通过 交互连接, 体现在前端 通过组件 method, event来做处理。而交互有很高的复杂性,每个交互可以看成一步步的流程。整个页面编辑器分为两部分:设计和流程
组件通过事件来调用流程好的流程,流程通过逻辑操作可对组件属性进行设置,暴露方法调用。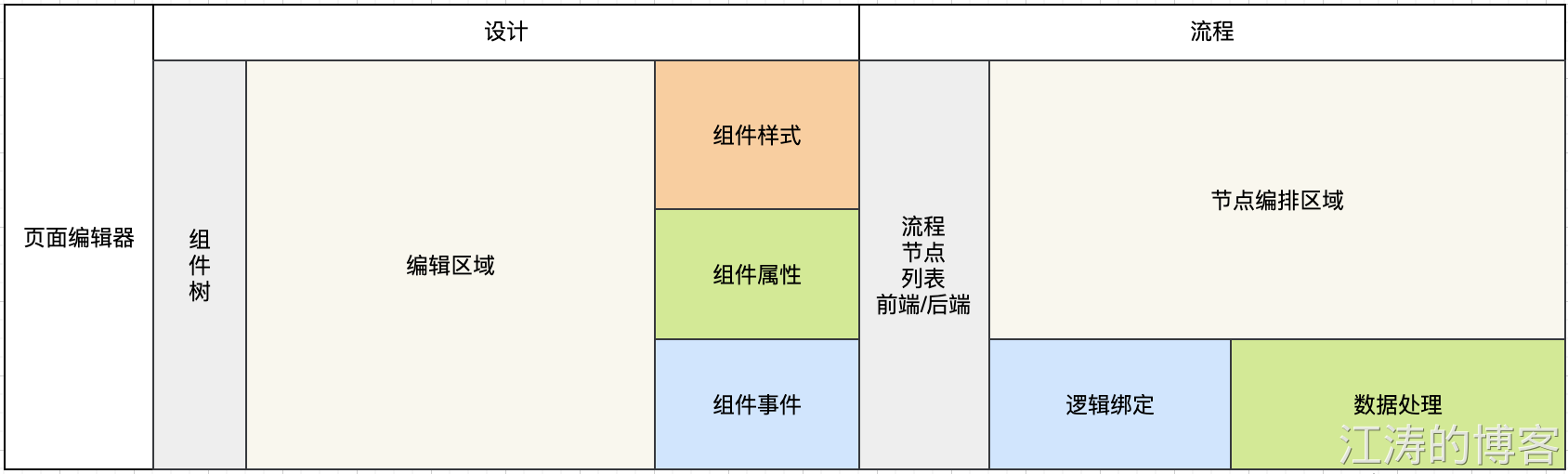
整体的设计编辑区域 和 流程节点编排区域,社区里面有不少优秀的案例,如设计编辑区域 vvweb editor, 流程节点编排G6 Editor,GGeditor。本篇文章重心还是放在编译思维的应用上,涉及到具体的领域技术细节这里不作展开。
4.3.2 存储设计
由于系统的复杂性和早期的实验和快速迭代。之前工作的无代码平台采用了 MongoDB 数据库。编辑器界面的核心是组件、流程。这里面介绍下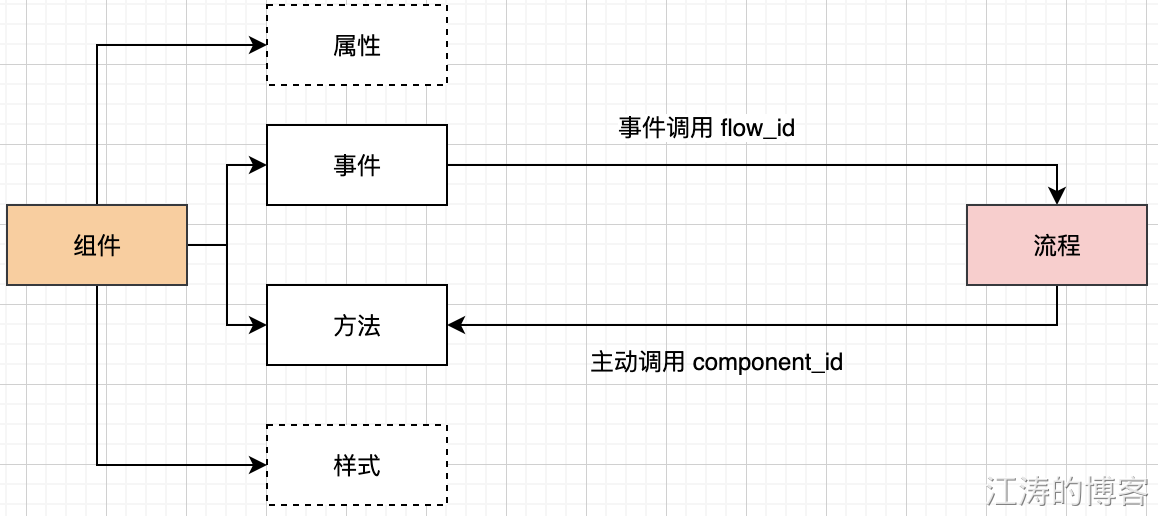
- 组件通过事件调用流程设计好的流程,组件表中记录对应事件调用的流程 flow_id
- 流程通过主动调用,组件暴露的方法,流程表中记录主动调用方法,记录在流程节点options字段每个 option 字段代表一个节点,每个param代码节点下处理行为
组件表设计
{"_id" : ObjectId("5f848ac45ba062e4e77c79ec"),"removed" : 0, // 组件状态,假删"parentId" : "nxdgb7zzhg9a4vc00", // 组件的父组件 id"childrenIds" : [], // 当前组件的子组件 id,前端渲染使用,避免重复查询计算"style" : { // 组件样式"width" : 154,"height" : 40},"type" : "text", // 组件类型"name" : "text1", // 组件类型"componentId" : "", // Vue2.0组件"props" : { // 组件暴露的属性},"eventsCall": { // 事件调用流程"complexEvents" : [{"type" : "click","bind" : "5f8509445ba062e4e77c7bfd","repetitive" : false,"rate" : 500,"tip" : ""}]},"events" : {"click" : {"type" : 4}},"id" : "geatgutd56lj5s000","controlId" : "geatgutd56lj5s000","appId" : ObjectId("5f848ab85ba062e4e77c79df"),"pageId" : "26a92dae656266bf6b9a18a2fd889823","userId" : ObjectId("5f84881b5ba062e4e77c79d9"),}
流程表设计
{"_id" : ObjectId("5f8509445ba062e4e77c7bfd"),"removed" : 0,"tags" : [],"options" : [ // 流程图节点描述{"id" : 1,"type" : "compute","desc" : "计算赋值","next" : 0,"style" : {"width" : 110,"height" : 42,"left" : 20,"top" : 30},"params" : [{"target_type" : "control", // 来源组件"target_value" : {"prop" : "","controlId" : ""},"source_type" : "inner", // 内部方法"source_value" : "console.log(123)" // 内部方法值},{"target_type" : "control", // 来源组件"target_value" : {"prop" : "","controlId" : ""},"source_type" : "method", // 组件主动调用方法"source_value" : "print(#a#, #b#)", // 调用方法形式,"source_opts": [{}, {}] // 调用方法的参数}],"start" : true}],"initial" : false, // 是否页面初始化执行"app_id" : ObjectId("5f848ab85ba062e4e77c79df"), // 对应的应用 id"page_id" : "26a92dae656266bf6b9a18a2fd889823", // 对应的页面 id"name" : "流程图-前台-1", // 页面名称"type" : "front", // 流程图节点"flow_id" : "5f8509445ba062e4e77c7bfd", // 流程图节点,自己生成,节点存在复用时可重复}
4.4 组件渐进升级思路
4.4.1 场景
- 之前工作的无代码平台由于历史原因,基于较老的 Vue1.0 技术体系打通全流程。新入职员工对于 Vue1.0 技术体系不熟,且 Vue1.0 体系不少技术文档陈旧更新不足,影响了团队对组件的研发效率
平台已经进入一直长久的稳定期,且代码量巨大(100w 行前端代码,编译代码),升级技术栈投入回报严重不成正比。希望可以引入 Vue2.0 的语法,提高团队组件产能,且在 1.0 技术体系在共存。
4.4.2 实现流程
上面介绍到低代码平台整体的核心是 DSL,可以通过把编写的 Vue 2.0 组件 以 DSL 的存入数据库中,以 Vue2.0 的模板编译器和 JS 编译器转换成 Vue1.0可识别的语法,以达成使用 Vue2.0 组件开发,在 Vue1.0 的编译环境下运行。
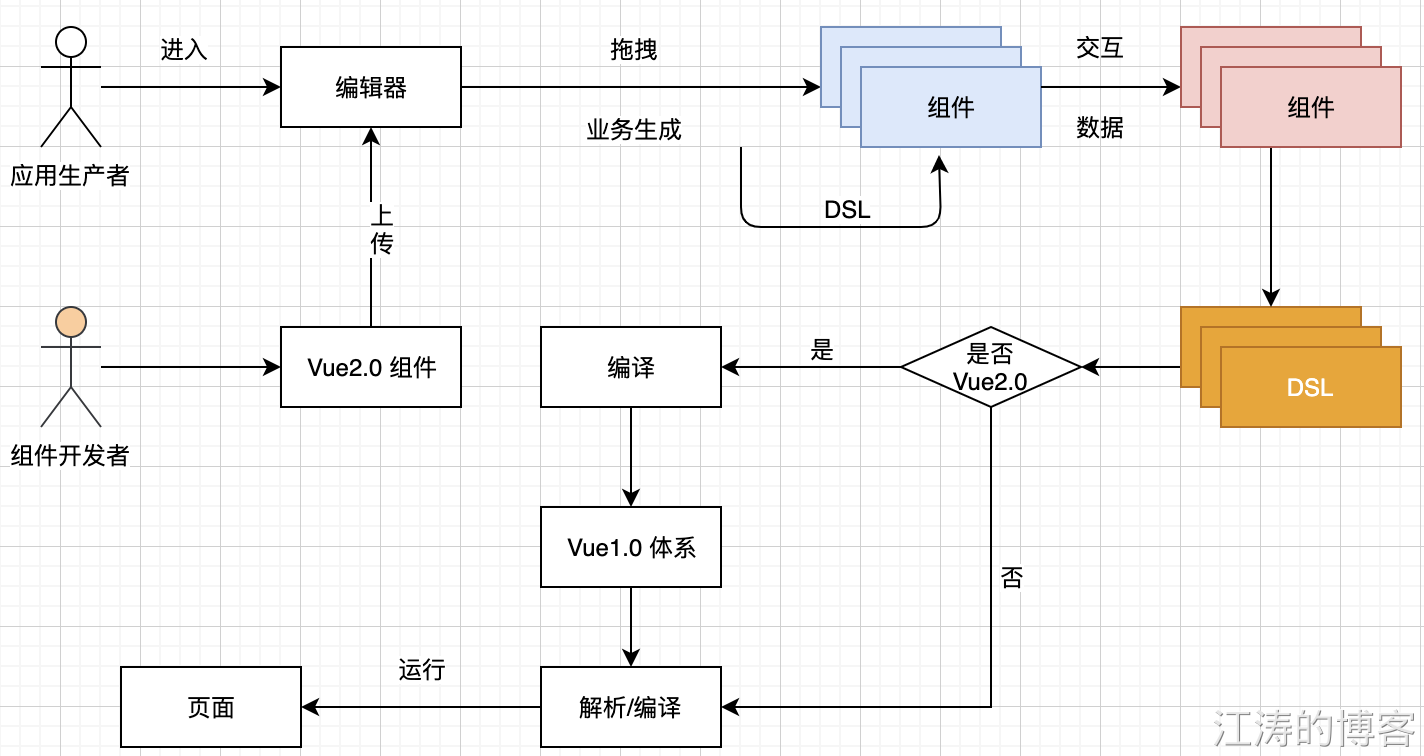
编译实现通过Vue 模板核心基于不同版本的 vue-template-compiler, 通过Vue2.0的 template-compiler 编译成 模板 ast,在对 ast 进行 转换成 Vue1.0 的代码。Vue1.0模板转ast转模板, Vue2.0模板转 ast 转模板。JS 通过手动转换生命周期即可。Css 无需要转换。五、总结
本文讲述了编译原理概述,前端学习编译思想的一些好处,以及从 JS 执行机制解析编译在前端中的流程,JSDoc 在前端中的基本流程,低代码平台中编译思维的运用,低代码平台通过 DSL 不同编译环境下实现前端开发技术栈升级。理解编译原理思维,对不同的实体(可以是 源代码、DSL 信息)进行抽象,解析或编译处理成目标对象,来实现场景。再次感谢您的阅读,您在工作中把编译思想用到哪些有意思的场景,欢迎留言或联系我交流。
六、参考资料
- V8 的 JavaScript 执行管道
- V8 的相关演讲
- 深入理解 JavaScript 执行上下文和执行栈
- 低代码,要怎么低?和低代码有关的 10 个问题
- 可视化搭建系统探索前端领域技术和业务价值

若有收获,就点个赞吧
0 人点赞
