一、Sql介绍
SQL, 全称为Structured Query Language(结构化查询语言)。 要讲SQL就绕不开database(数据库), 平时所说的数据库,一般就是指的 Relational database(关系型数据库).
大家知道数据库是用来存储大量数据的一种软件,那么SQL呢是用来操作数据里的数据,具体来说SQL可以做数据查询,数据更新,写入数据等等。
数据库由若干张表(Table)组成,这里说的数据Table很像Excel里的表; 正如Excel里的表格,Table也是由 行(rows)和列(columns)组成。
一个Table存储一个类别的数据,每一行是一条数据,每一列是这种数据的一个属性; Table就像一个二维的表格,列(columns)是有限固定的,行(rows)是无限不固定的
举个例子, 比如我们数据库里有一张表(Table). 是用来存储世界上所有的狗,每一行(rows)是一条狗的信息。那么你会在这个狗Table里存储 哪些狗的属性列(columns)呢?比如 编号,名字,体重,身高,品种,年龄,毛发颜色?。让我们来看一下这张表,暂且就叫表 Dog吧!
Table(表): Dog
| Id | # Name(名字) | # Weight(体重) | # Height (身高) | # Type (品种) | # Age (月龄) | # Color (肤色) |
|---|---|---|---|---|---|---|
| 1 | Mike | 3 | 28 | 吉娃娃 | 10 | 白 |
| 2 | Sala | 6.5 | 40 | 柴犬 | 15 | 黄 |
| 3 | 黑狮 | 21.5 | 45 | 藏獒 | 26 | 黑 |
| 4 | 大圣 | 15 | 42 | 牧羊犬 | 20 | 黄 |
| 5 | Boy | 5.5 | 24 | 蝴蝶犬 | 6 | 白 |
| … | … | … | … | … | … | … |
上面就是一个Dog表的简单展示,像这样一个狗数据库里,除了这张狗(Dog)表,还可能存在其他的表,比如有一张表是存狗品种信息, 另外有一张表是存狗主人信息的 …
SQL操作
存储引擎
MySQL支持插件式的存储引擎。
常见的存储引擎:MySAM和InnoDB
MyLSAM
- 查询速度快
- 只支持表锁
-
InnoDB
- 整体速度快
支持表锁和行锁
-
事物
把多个SQL操作当成一个整体
事物的特点:
ACID: 原子性:事物要么成功要么失败,没有中间状态。
- 一致性:数据库的完整性没有被破坏。
隔离性:事物之间是相互隔离的,不会有冲突。
数据库允许多个并发事物同时对其数据进行读写和修改的能力。隔离性可以防止多个事物并发执行时由于交叉执行而导致的数据不一致问题。事物隔离分为不同的级别。包括读未提交(读了没有提交的数据)、读提交、可重复读和串行化。
持久性:事物处理结束后,对数据的修改是永久的,即使是系统故障也不会丢失。事物操作的结果是
索引
索引的原理:B树和B+树 (按目录查找)
索引的类型
索引的命中
分库分表
SQL注入
SQL慢查询优化
MySQL主从:
二、SELECT 查询
SELECT 语句, 通常又称为 查询 (queries), 正如其名, SELECT 可以用来从数据库中取出数据. 一条 SELECT 语句或者叫一个查询, 可以描述我们要从什么表取数据, 要取哪些数据,在返回之前怎么对结果做一些转化计算等等. 我们接下来会说明 SELECT 的语法,看 SELECT 是怎么来实现上述的取数据任务的。
可以把一个表(Table)想象成一个类别的事物,比如 狗 (Dogs), 表里的每一行就是 一条狗,每一列代表了狗的一种属性,比如: 颜色,长度等等)
现在有了这么一张表,最常见的一种查询就是取出表中的 一个或某几个属性列(注意:是所有数据的某几个属性列)
1.Select 查询某些属性列(specific columns)的语法
SELECT column(列名), another_column, …
FROM mytable(表名);
查询的结果是一个二维的表格,由行(rows)和列(columns)组成, 看起来像是复制了一遍原有的表(Table),只不过列是我们选定的,而不是所有的列.
如果我们想取出所有列的数据, 当然可以把所有列名写上,不过更简单的方式用星号 (*) 来代表所有列.如下:
2.Select 查询所有列
SELECT
FROM mytable(表名);
SELECT FROM table. 这条语句经常用来在不清楚table(表)中有什么数据时,能取出所有的数据瞜一眼。
如:
三、条件查询
1.WHERE 子句(数字类型)
真实情况下,我们很少直接查所有行,即使查询出来也看不完。为了更精确的查询出特定数据,我们需要学习一个新的SQL语法:SELECT查询的 WHERE 子句. 一个查询的 WHERE子句用来描述哪些行应该进入结果,具体就是通过 condition条件 限定这些行的属性满足某些具体条件。比如:WHERE 体重大于 10KG的狗。你可以把 WHERE想象成一个 筛子,每一个特定的筛子都可以筛下某些豆子。
条件查询语法
SELECT column, another_column, …FROM mytableWHERE conditionAND/OR another_conditionAND/OR …;
注:这里的 condition 都是描述属性列的,具体会在下面的表格体现。
可以用 AND or OR 这两个关键字来组装多个条件(表示并且,或者) (ie. num_wheels >= 4 AND doors <= 2 这个组合表示 num_wheels属性 大于等于 4 并且 doors 属性小于等于 2). 下面的具体语法规则,可以用来筛选数字属性列(包括 整数,浮点数) :
| Operator(关键字) | Condition(意思) | SQL Example(例子) |
|---|---|---|
| =, !=, < <=, >, >= | Standard numerical operators 基础的 大于,等于等比较 | col_name != 4 |
| BETWEEN … AND … | Number is within range of two values (inclusive) 在两个数之间 | col_name BETWEEN 1.5 AND 10.5 |
| NOT BETWEEN … AND … | Number is not within range of two values (inclusive) 不在两个数之间 | col_name NOT BETWEEN 1 AND 10 |
| IN (…) | Number exists in a list 在一个列表 | col_name IN (2, 4, 6) |
| NOT IN (…) | Number does not exist in a list 不在一个列表 | col_name NOT IN (1, 3, 5) |
练习:
1.找到2010(含)年之后的电影里片长小于105分钟的片子
SELECT * FROM movies WHERE year >= 2010 AND Length_minutes <=105
2.找到在2000-2010年间year上映的电影
SELECT * FROM movies WHERE year BETWEEN 2000 AND 2010
2.LIKE 和 % (字符串类型操作)
WHERE 语句来筛选数字类型的属性,如果属性是字符串, 我们会用到字符串相关的一些操作符号,其中 LIKE(模糊查询) 和 %(通配符) 是新增的两个. 下面这个表格对字符串操作符有详细的描述:
| Operator(操作符) | Condition(解释) | Example(例子) |
|---|---|---|
| = | Case sensitive exact string comparison (notice the single equals)完全等于 | col_name = “abc” |
| != or <> | Case sensitive exact string inequality comparison 不等于 | col_name != “abcd” |
| LIKE | Case insensitive exact string comparison 没有用通配符等价于 = | col_name LIKE “ABC” |
| NOT LIKE | Case insensitive exact string inequality comparison 没有用通配符等价于 != | col_name NOT LIKE “ABCD” |
| % | Used anywhere in a string to match a sequence of zero or more characters (only with LIKE or NOT LIKE) 通配符,代表匹配0个以上的字符 | col_name LIKE “%AT%” (matches “AT”, “ATTIC”, “CAT” or even “BATS”) “%AT%” 代表AT 前后可以有任意字符 |
| _ | Used anywhere in a string to match a single character (only with LIKE or NOT LIKE) 和% 相似,代表1个字符 | colname LIKE “AN“ (matches “AND”, but not “AN”) |
| IN (…) | String exists in a list 在列表 | col_name IN (“A”, “B”, “C”) |
| NOT IN (…) | String does not exist in a list 不在列表 | col_name NOT IN (“D”, “E”, “F”) |
练习:
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
1.找到所有是John Lasseter导演的电影
SELECT * FROM movies WHERE Director = 'John Lasseter'SELECT * FROM movies WHERE Director LIKE 'John Lasseter'
2.找到所有不是John Lasseter导演的电影
SELECT * FROM movies WHERE Director != 'John Lasseter'SELECT * FROM movies WHERE Director NOT LIKE 'John Lasseter'
3.找到所有电影名为 “WALL-“ 开头的电影
SELECT * FROM movies WHERE Title LIKE "%WALL_%"
4.有一部98年电影中文名《虫虫危机》请给我找出来
SELECT * FROM movies WHERE Year=1998 AND Title LIKE "虫虫危机"
3. 查询结果Filtering过滤 和 sorting排序
3.1 去重
DISTINCT 关键字来指定某个或某些属性列唯一返回。
对于上面的结果,如果你想要按年份去重,一年只能出现一部电影到结果中,就可以这样写:
DISTINCT Year
选取出唯一的结果的语法:
SELECT DISTINCT column, another_column, …FROM mytableWHERE condition(s);
3.2 结果排序
在实际的数据库表中数据添加完并不是顺序的,如果不对结果排序,那么成千上万的数据就会很乱。
我们可以用 ORDER BY col_name 语法让结果按一个或者多个属性做排序。
对结果排序语法:
SELECT column, another_column, …FROM mytableWHERE condition(s)ORDER BY column ASC/DESC;
ORDER BY column ASC/DESC 意思是让结果按某个属性列 升序或降序排列。
3.3 选取部分结果
通过LIMIT和OFFSET子句选取结果集中的一部分。
LIMIT表示选取多少条数据,OFFSET表示从哪里开始选取。
LIMIT查询语法:
SELECT column, another_column, …FROM mytableWHERE condition(s)ORDER BY column ASC/DESCLIMIT num_limit OFFSET num_offset;
练习:
依旧是对上面那张表进行操作。
1.按导演名排重列出所有电影(只显示导演),并按导演名正序排列
SELECT DISTINCT Director FROM movies ORDER BY Director ASC;
2.列出按上映年份最新上线的4部电影
SELECT * FROM movies ORDER BY Year DESC LIMIT 4;
3.按电影名字母序升序排列,列出前5部电影
SELECT * FROM movies ORDER BY Title ASC LIMIT 5;
4.按电影名字母序升序排列,列出上一题之后的5部电影
5.如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可
四、用JOINs进行多表联合查询
1.INNER JOIN
一般关系数据表中,都会有一个属性列设置为 主键(primary key)。主键是唯一标识一条数据的,不会重复复(想象你的身份证号码)。一个最常见的主键就是auto-incrementing integer(自增ID,每写入一行数据ID+1, 当然字符串,hash值等只要是每条数据是唯一的也可以设为主键.
借助主键(primary key)(当然其他唯一性的属性也可以),我们可以把两个表中具有相同 主键ID的数据连接起来。用INNER JOIN 连接表的语法:
SELECT column, another_table_column, …FROM mytable (主表)INNER JOIN another_table (要连接的表)ON mytable.id = another_table.id (主键连接)WHERE condition(s)ORDER BY column, … ASC/DESCLIMIT num_limit OFFSET num_offset;
ON描述了关联关系,也就是主键。INNER JOIN 先将两个表数据连接到一起. 两个表中如果通过ID互相找不到的数据将会舍弃。相当于两个集合的交集。
练习:
Table: Movies
| Id | Title | Director | Year | Length_minutes |
|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 |
| 7 | Cars | John Lasseter | 2006 | 117 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 |
| 10 | Up | Pete Docter | 2009 | 101 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 |
| 13 | Brave | Brenda Chapman | 2012 | 102 |
| 14 | Monsters University | Dan Scanlon | 2013 | 110 |
Table: Boxoffice
| Movie_id | Rating | Domestic_sales | International_sales |
|---|---|---|---|
| 5 | 8.2 | 380843261 | 555900000 |
| 14 | 7.4 | 268492764 | 475066843 |
| 8 | 8 | 206445654 | 417277164 |
| 12 | 6.4 | 191452396 | 368400000 |
| 3 | 7.9 | 245852179 | 239163000 |
| 6 | 8 | 261441092 | 370001000 |
| 9 | 8.5 | 223808164 | 297503696 |
| 11 | 8.4 | 415004880 | 648167031 |
| 1 | 8.3 | 191796233 | 170162503 |
| 7 | 7.2 | 244082982 | 217900167 |
| 10 | 8.3 | 293004164 | 438338580 |
| 4 | 8.1 | 289916256 | 272900000 |
| 2 | 7.2 | 162798565 | 200600000 |
| 13 | 7.2 | 237283207 | 301700000 |
1.找到所有电影的国内Domestic_sales和国际销售额
SELECT * FROM Movies INNER JOIN Boxoffice ON BoxOffice.Movie_id = Movies.id
| Id | Title | Director | Year | Length_minutes | Movie_id | Rating | Domestic_sales | International_sales |
|---|---|---|---|---|---|---|---|---|
| 1 | Toy Story | John Lasseter | 1995 | 81 | 1 | 8.3 | 191796233 | 170162503 |
| 2 | A Bug’s Life | John Lasseter | 1998 | 95 | 2 | 7.2 | 162798565 | 200600000 |
| 3 | Toy Story 2 | John Lasseter | 1999 | 93 | 3 | 7.9 | 245852179 | 239163000 |
| 4 | Monsters, Inc. | Pete Docter | 2001 | 92 | 4 | 8.1 | 289916256 | 272900000 |
| 5 | Finding Nemo | Finding Nemo | 2003 | 107 | 5 | 8.2 | 380843261 | 555900000 |
| 6 | The Incredibles | Brad Bird | 2004 | 116 | 6 | 8 | 261441092 | 370001000 |
| 7 | Cars | John Lasseter | 2006 | 117 | 7 | 7.2 | 244082982 | 217900167 |
| 8 | Ratatouille | Brad Bird | 2007 | 115 | 8 | 8 | 206445654 | 417277164 |
| 9 | WALL-E | Andrew Stanton | 2008 | 104 | 9 | 8.5 | 223808164 | 297503696 |
| 10 | Up | Pete Docter | 2009 | 101 | 10 | 8.3 | 293004164 | 438338580 |
| 11 | Toy Story 3 | Lee Unkrich | 2010 | 103 | 11 | 8.4 | 415004880 | 648167031 |
| 12 | Cars 2 | John Lasseter | 2011 | 120 | 12 | 6.4 | 191452396 | 368400000 |
| 13 | Brave | Brenda Chapman | 2012 | 102 | 13 | 7.2 | 237283207 | 301700000 |
| 14 | Monsters University | Dan Scanlon |
2.找到所有国际销售额比国内销售大的电影
SELECT * FROM Movies INNER JOIN Boxoffice ON BoxOffice.Movie_id = Movies.id WHERE Domestic_sales < International_sales
3.找出所有电影按市场占有率 rating 倒序排列。
SELECT * FROM MoviesINNER JOIN Boxoffice ON BoxOffice.Movie_id = Movies.idORDER BY Rating DESC
市场占有率 Rating 在 BoxOffice 表,所以需要联表查询,倒序排列,ORDER BY column ASC/DESC;
4.每部电影按国际销售额比较,排名最靠前的导演是谁,国际销量多少
SELECT Director FROM MoviesINNER JOIN Boxoffice ON Movies.id = Boxoffice.Movie_idORDER BY International_sales ASC LIMIT 1
找导演:SELECT Director FROM Movie
按国际销售额:联表 INNER JOIN Boxoffice ON Movies.id = Boxoffice.Movie_id
排名第一:ORDER BY International_sales ASC LIMIT 1
2.LEFT JOIN 和 RIGHT JOIN
INNER JOIN 只会保留两个表都存在的数据(还记得之前的交集吗),这看起来意味着一些数据的丢失,在某些场景下会有问题.
真实世界中两个表存在差异很正常,所以我们需要更多的连表方式,也就是本节要介绍的左连接LEFT JOIN,右连接RIGHT JOIN 和 全连接FULL JOIN. 这几个 连接方式都会保留不能匹配的行。
用LEFT/RIGHT/FULL JOINs 做多表查询
SELECT column, another_column, …FROM mytableINNER/LEFT/RIGHT/FULL JOIN another_tableON mytable.id = another_table.matching_idWHERE condition(s)ORDER BY column, … ASC/DESCLIMIT num_limit OFFSET num_offset;
我们可以用集合的关系来表示:
LEFT JOIN: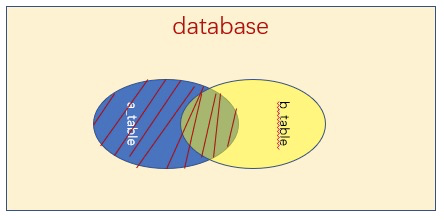
RIGHT JOIN:
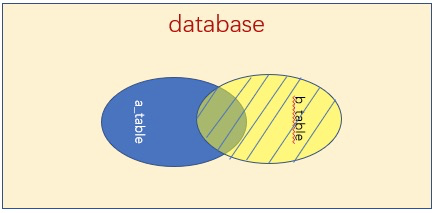
FULL JOIN:
将两个表数据1-1连接,保留A或B的原有行,如果某一行在另一个表不存在,会用 NULL来填充结果数据。所有在用这三个JOIN时,需要单独处理 NULL。
3.特殊关键字NULLs
NULL表达的是 “无”的概念,或者说没有东西。因为 NULL的存在,我们需要在编写SQL时考虑到某个属性列可能是 NULL的情况, 这种特殊性会造成编写SQL的复杂性,所以没有必要的情况下,我们应该尽量减少 NULL的使用,让数据中尽可能少出现 NULL的情况。
如果某个字段你没有填写到数据库,很可能就会出现NULL 。所有一个常见的方式就是为字段设置默认值,比如 数字的默认值设置为0,字符串设置为 “”字符串. 但是在一些NULL 表示它本来含义的场景,需要注意是否设置默认值还是保持NULL。 (f比如, 当你计算一些行的平均值的时候,如果是0会参与计算导致平均值差错,是NULL则不会参与计算).
还有一些情况很难避免 NULL 的出现, 比如之前说的 outer-joining 多表连接,A和B有数据差异时,必须用 NULL 来填充。这种情况,可以用IS NULL和 IS NOT NULL 来选在某个字段是否等于 NULL。
SELECT column, another_column, …FROM mytableWHERE column IS/IS NOT NULLAND/OR another_conditionAND/OR …;
五、设计数据库的常见范式
作者:知乎用户
链接:https://www.zhihu.com/question/24696366/answer/29189700
来源:知乎
国内绝大多数院校用的王珊的《数据库系统概论》这本教材,某些方面并没有给出很详细很明确的解释,与实际应用联系不那么紧密,你有这样的疑问也是挺正常的。我教《数据库原理》这门课有几年了,有很多学生提出了和你一样的问题,试着给你解释一下吧。(基本来自于我上课的内容,某些地方为了不过于啰嗦,放弃了一定的严谨,主要是在“关系”和“表”上)首先要明白”范式(NF)”是什么意思。按照教材中的定义,范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”。很晦涩吧?实际上你可以把它粗略地理解为一张数据表的表结构所符合的某种设计标准的级别。就像家里装修买建材,最环保的是E0级,其次是E1级,还有E2级等等。数据库范式也分为1NF,2NF,3NF,BCNF,4NF,5NF。一般在我们设计关系型数据库的时候,最多考虑到BCNF就够。符合高一级范式的设计,必定符合低一级范式,例如符合2NF的关系模式,必定符合1NF。接下来就对每一级范式进行一下解释,首先是第一范式(1NF)。符合1NF的关系(你可以理解为数据表。“关系模式”和“关系”的区别,类似于面向对象程序设计中”类“与”对象“的区别。”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构。1NF的定义为:符合1NF的关系中的每个属性都不可再分。表1所示的情况,就不符合1NF的要求。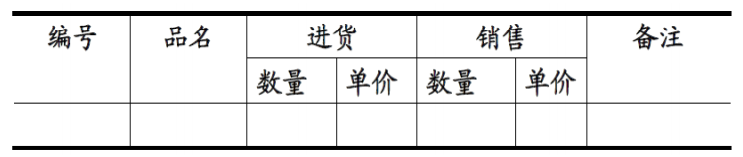 表1实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。如果我们要在RDBMS中表现表中的数据,就得设计为表2的形式:
表1实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。如果我们要在RDBMS中表现表中的数据,就得设计为表2的形式: 表2但是仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如对于表3中的设计:
表2但是仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如对于表3中的设计: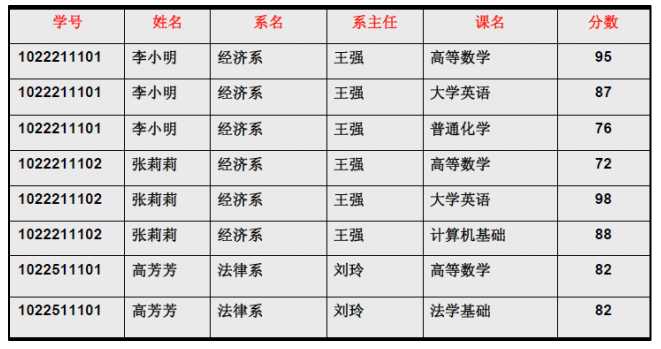
表3每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大 假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的 (注1)——插入异常注1:根据三种关系完整性约束中实体完整性的要求,关系中的码(注2)所包含的任意一个属性都不能为空,所有属性的组合也不能重复。为了满足此要求,图中的表,只能将学号与课名的组合作为码,否则就无法唯一地区分每一条记录。注2:码:关系中的某个属性或者某几个属性的组合,用于区分每个元组(可以把“元组”理解为一张表中的每条记录,也就是每一行)。假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。——删除异常假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。——修改异常。正因为仅符合1NF的数据库设计存在着这样那样的问题,我们需要提高设计标准,去掉导致上述四种问题的因素,使其符合更高一级的范式(2NF),这就是所谓的“规范化”。第二范式(2NF)在关系理论中的严格定义我这里就不多介绍了(因为涉及到的铺垫比较多),只需要了解2NF对1NF进行了哪些改进即可。其改进是,2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。接下来对这句话中涉及到的四个概念——“函数依赖”、“码”、“非主属性”、与“部分函数依赖”进行一下解释。函数依赖我们可以这么理解(但并不是特别严格的定义):若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作 学号 → 姓名。但是反过来,因为可能出现同名的学生,所以有可能不同的两条学生记录,它们在姓名上的值相同,但对应的学号不同,所以我们不能说学号函数依赖于姓名。表中其他的函数依赖关系还有如:系名 → 系主任学号 → 系主任(学号,课名) → 分数但以下函数依赖关系则不成立:学号 → 课名学号 → 分数课名 → 系主任(学号,课名) → 姓名从“函数依赖”这个概念展开,还会有三个概念:完全函数依赖在一张表中,若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X ‘ → Y 不成立,那么我们称 Y 对于 X 完全函数依赖,记作 X F→ Y。(那个F应该写在箭头的正上方,没办法打出来……,正确的写法如图1)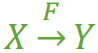 图1例如: 学号 F→ 姓名 (学号,课名) F→ 分数 (注:因为同一个的学号对应的分数不确定,同一个课名对应的分数也不确定)部分函数依赖假如 Y 函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X,记作 X P→ Y,如图2。
图1例如: 学号 F→ 姓名 (学号,课名) F→ 分数 (注:因为同一个的学号对应的分数不确定,同一个课名对应的分数也不确定)部分函数依赖假如 Y 函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X,记作 X P→ Y,如图2。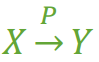 图2例如:(学号,课名) P→ 姓名 传递函数依赖假如 Z 函数依赖于 Y,且 Y 函数依赖于 X (感谢 @百达 指出的错误,这里改为:『Y 不包含于 X,且 X 不函数依赖于 Y』这个前提),那么我们就称 Z 传递函数依赖于 X ,记作 X T→ Z,如图3。
图2例如:(学号,课名) P→ 姓名 传递函数依赖假如 Z 函数依赖于 Y,且 Y 函数依赖于 X (感谢 @百达 指出的错误,这里改为:『Y 不包含于 X,且 X 不函数依赖于 Y』这个前提),那么我们就称 Z 传递函数依赖于 X ,记作 X T→ Z,如图3。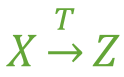 图3码设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为候选码,简称为码。在实际中我们通常可以理解为:假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为主码) 例如:对于表3,(学号、课名)这个属性组就是码。该表中有且仅有这一个码。(假设所有课没有重名的情况)非主属性包含在任何一个码中的属性成为主属性。例如:对于表3,主属性就有两个,学号 与 课名。终于可以回过来看2NF了。首先,我们需要判断,表3是否符合2NF的要求?根据2NF的定义,判断的依据实际上就是看数据表中是否存在非主属性对于码的部分函数依赖。若存在,则数据表最高只符合1NF的要求,若不存在,则符合2NF的要求。判断的方法是:第一步:找出数据表中所有的码。第二步:根据第一步所得到的码,找出所有的主属性。第三步:数据表中,除去所有的主属性,剩下的就都是非主属性了。第四步:查看是否存在非主属性对码的部分函数依赖。对于表3,根据前面所说的四步,我们可以这么做:第一步:查看所有每一单个属性,当它的值确定了,是否剩下的所有属性值都能确定。查看所有包含有两个属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。……查看所有包含了六个属性,也就是所有属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。看起来很麻烦是吧,但是这里有一个诀窍,就是假如A是码,那么所有包含了A的属性组,如(A,B)、(A,C)、(A,B,C)等等,都不是码了(因为作为码的要求里有一个“完全函数依赖”)。图4表示了表中所有的函数依赖关系:
图3码设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为候选码,简称为码。在实际中我们通常可以理解为:假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为主码) 例如:对于表3,(学号、课名)这个属性组就是码。该表中有且仅有这一个码。(假设所有课没有重名的情况)非主属性包含在任何一个码中的属性成为主属性。例如:对于表3,主属性就有两个,学号 与 课名。终于可以回过来看2NF了。首先,我们需要判断,表3是否符合2NF的要求?根据2NF的定义,判断的依据实际上就是看数据表中是否存在非主属性对于码的部分函数依赖。若存在,则数据表最高只符合1NF的要求,若不存在,则符合2NF的要求。判断的方法是:第一步:找出数据表中所有的码。第二步:根据第一步所得到的码,找出所有的主属性。第三步:数据表中,除去所有的主属性,剩下的就都是非主属性了。第四步:查看是否存在非主属性对码的部分函数依赖。对于表3,根据前面所说的四步,我们可以这么做:第一步:查看所有每一单个属性,当它的值确定了,是否剩下的所有属性值都能确定。查看所有包含有两个属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。……查看所有包含了六个属性,也就是所有属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。看起来很麻烦是吧,但是这里有一个诀窍,就是假如A是码,那么所有包含了A的属性组,如(A,B)、(A,C)、(A,B,C)等等,都不是码了(因为作为码的要求里有一个“完全函数依赖”)。图4表示了表中所有的函数依赖关系: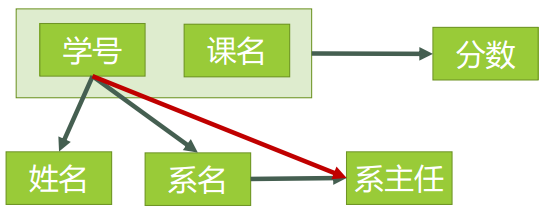 图4这一步完成以后,可以得到,表3的码只有一个,就是(学号、课名)。第二步:主属性有两个:学号 与 课名第三步:非主属性有四个:姓名、系名、系主任、分数第四步:对于(学号,课名) → 姓名,有 学号 → 姓名,存在非主属性 姓名 对码(学号,课名)的部分函数依赖。对于(学号,课名) → 系名,有 学号 → 系名,存在非主属性 系名 对码(学号,课名)的部分函数依赖。对于(学号,课名) → 系主任,有 学号 → 系主任,存在非主属性 对码(学号,课名)的部分函数依赖。所以表3存在非主属性对于码的部分函数依赖,最高只符合1NF的要求,不符合2NF的要求。为了让表3符合2NF的要求,我们必须消除这些部分函数依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表,在拆分的过程中,要达到更高一级范式的要求,这个过程叫做”模式分解“。模式分解的方法不是唯一的,以下是其中一种方法:选课(学号,课名,分数)学生(学号,姓名,系名,系主任)我们先来判断以下,选课表与学生表,是否符合了2NF的要求?对于选课表,其码是(学号,课名),主属性是学号和课名,非主属性是分数,学号确定,并不能唯一确定分数,课名确定,也不能唯一确定分数,所以不存在非主属性分数对于码 (学号,课名)的部分函数依赖,所以此表符合2NF的要求。对于学生表,其码是学号,主属性是学号,非主属性是姓名、系名和系主任,因为码只有一个属性,所以不可能存在非主属性对于码 的部分函数依赖,所以此表符合2NF的要求。图5表示了模式分解以后的新的函数依赖关系
图4这一步完成以后,可以得到,表3的码只有一个,就是(学号、课名)。第二步:主属性有两个:学号 与 课名第三步:非主属性有四个:姓名、系名、系主任、分数第四步:对于(学号,课名) → 姓名,有 学号 → 姓名,存在非主属性 姓名 对码(学号,课名)的部分函数依赖。对于(学号,课名) → 系名,有 学号 → 系名,存在非主属性 系名 对码(学号,课名)的部分函数依赖。对于(学号,课名) → 系主任,有 学号 → 系主任,存在非主属性 对码(学号,课名)的部分函数依赖。所以表3存在非主属性对于码的部分函数依赖,最高只符合1NF的要求,不符合2NF的要求。为了让表3符合2NF的要求,我们必须消除这些部分函数依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表,在拆分的过程中,要达到更高一级范式的要求,这个过程叫做”模式分解“。模式分解的方法不是唯一的,以下是其中一种方法:选课(学号,课名,分数)学生(学号,姓名,系名,系主任)我们先来判断以下,选课表与学生表,是否符合了2NF的要求?对于选课表,其码是(学号,课名),主属性是学号和课名,非主属性是分数,学号确定,并不能唯一确定分数,课名确定,也不能唯一确定分数,所以不存在非主属性分数对于码 (学号,课名)的部分函数依赖,所以此表符合2NF的要求。对于学生表,其码是学号,主属性是学号,非主属性是姓名、系名和系主任,因为码只有一个属性,所以不可能存在非主属性对于码 的部分函数依赖,所以此表符合2NF的要求。图5表示了模式分解以后的新的函数依赖关系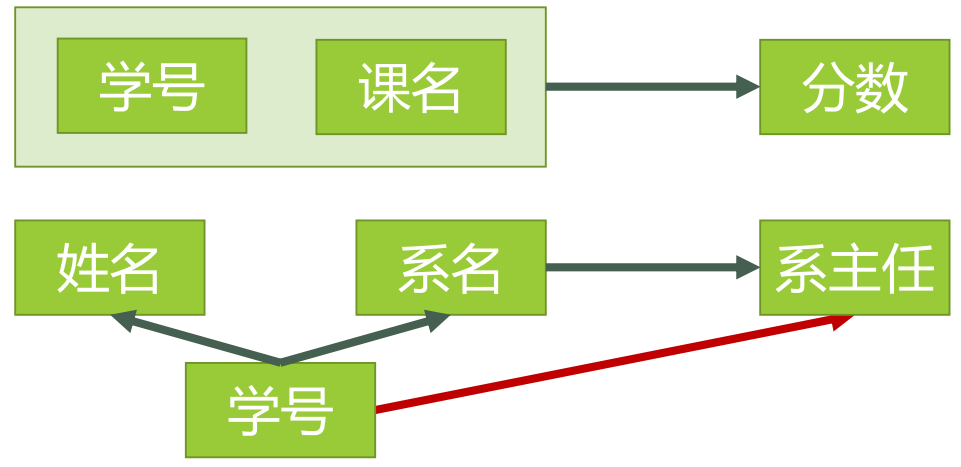 图5表4表示了模式分解以后新的数据
图5表4表示了模式分解以后新的数据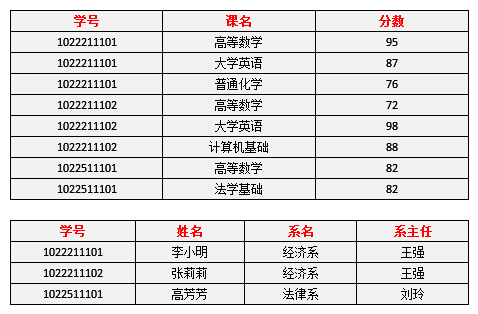 表4(这里还涉及到一个如何进行模式分解才是正确的知识点,先不介绍了)现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?李小明转系到法律系只需要修改一次李小明对应的系的值即可。——有改进数据冗余是否减少了?学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进删除某个系中所有的学生记录该系的信息仍然全部丢失。——无改进插入一个尚无学生的新系的信息。因为学生表的码是学号,不能为空,所以此操作不被允许。——无改进所以说,仅仅符合2NF的要求,很多情况下还是不够的,而出现问题的原因,在于仍然存在非主属性系主任对于码学号的传递函数依赖。为了能进一步解决这些问题,我们还需要将符合2NF要求的数据表改进为符合3NF的要求。第三范式(3NF) 3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。接下来我们看看表4中的设计,是否符合3NF的要求。对于选课表,主码为(学号,课名),主属性为学号和课名,非主属性只有一个,为分数,不可能存在传递函数依赖,所以选课表的设计,符合3NF的要求。对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。。为了让数据表设计达到3NF,我们必须进一步进行模式分解为以下形式:选课(学号,课名,分数)学生(学号,姓名,系名)系(系名,系主任)对于选课表,符合3NF的要求,之前已经分析过了。对于学生表,码为学号,主属性为学号,非主属性为系名,不可能存在非主属性对于码的传递函数依赖,所以符合3NF的要求。对于系表,码为系名,主属性为系名,非主属性为系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),所以符合3NF的要求。。新的函数依赖关系如图6
表4(这里还涉及到一个如何进行模式分解才是正确的知识点,先不介绍了)现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?李小明转系到法律系只需要修改一次李小明对应的系的值即可。——有改进数据冗余是否减少了?学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进删除某个系中所有的学生记录该系的信息仍然全部丢失。——无改进插入一个尚无学生的新系的信息。因为学生表的码是学号,不能为空,所以此操作不被允许。——无改进所以说,仅仅符合2NF的要求,很多情况下还是不够的,而出现问题的原因,在于仍然存在非主属性系主任对于码学号的传递函数依赖。为了能进一步解决这些问题,我们还需要将符合2NF要求的数据表改进为符合3NF的要求。第三范式(3NF) 3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。接下来我们看看表4中的设计,是否符合3NF的要求。对于选课表,主码为(学号,课名),主属性为学号和课名,非主属性只有一个,为分数,不可能存在传递函数依赖,所以选课表的设计,符合3NF的要求。对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。。为了让数据表设计达到3NF,我们必须进一步进行模式分解为以下形式:选课(学号,课名,分数)学生(学号,姓名,系名)系(系名,系主任)对于选课表,符合3NF的要求,之前已经分析过了。对于学生表,码为学号,主属性为学号,非主属性为系名,不可能存在非主属性对于码的传递函数依赖,所以符合3NF的要求。对于系表,码为系名,主属性为系名,非主属性为系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),所以符合3NF的要求。。新的函数依赖关系如图6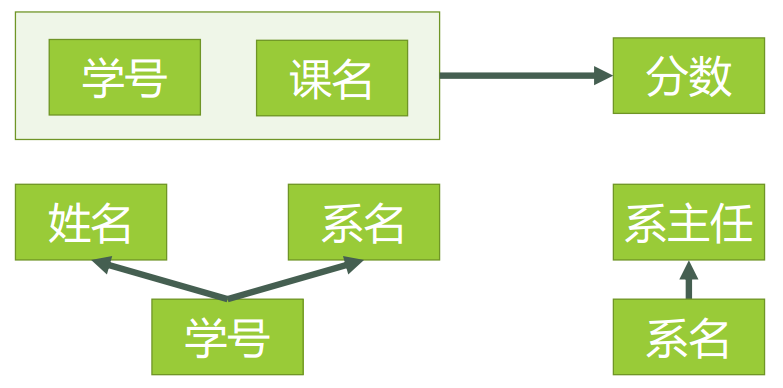 图6新的数据表如表5
图6新的数据表如表5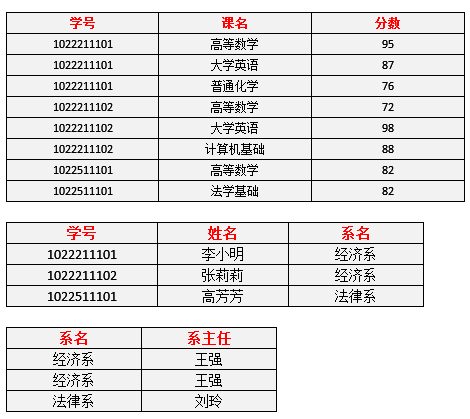 表5现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?删除某个系中所有的学生记录该系的信息不会丢失。——有改进插入一个尚无学生的新系的信息。因为系表与学生表目前是独立的两张表,所以不影响。——有改进数据冗余更加少了。——有改进结论由此可见,符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到2NF或者1NF,但是作为数据库设计人员,至少应该知道,3NF的要求是怎样的。==============时隔半年,终于决定把这个坑填上,来晚了 ===========BCNF范式要了解 BCNF 范式,那么先看这样一个问题:若:某公司有若干个仓库;每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。那么关系模式 仓库(仓库名,管理员,物品名,数量) 属于哪一级范式?答:已知函数依赖集:仓库名 → 管理员,管理员 → 仓库名,(仓库名,物品名)→ 数量码:(管理员,物品名),(仓库名,物品名)主属性:仓库名、管理员、物品名非主属性:数量∵ 不存在非主属性对码的部分函数依赖和传递函数依赖。∴ 此关系模式属于3NF。基于此关系模式的关系(具体的数据)可能如图所示:
表5现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?删除某个系中所有的学生记录该系的信息不会丢失。——有改进插入一个尚无学生的新系的信息。因为系表与学生表目前是独立的两张表,所以不影响。——有改进数据冗余更加少了。——有改进结论由此可见,符合3NF要求的数据库设计,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到2NF或者1NF,但是作为数据库设计人员,至少应该知道,3NF的要求是怎样的。==============时隔半年,终于决定把这个坑填上,来晚了 ===========BCNF范式要了解 BCNF 范式,那么先看这样一个问题:若:某公司有若干个仓库;每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。那么关系模式 仓库(仓库名,管理员,物品名,数量) 属于哪一级范式?答:已知函数依赖集:仓库名 → 管理员,管理员 → 仓库名,(仓库名,物品名)→ 数量码:(管理员,物品名),(仓库名,物品名)主属性:仓库名、管理员、物品名非主属性:数量∵ 不存在非主属性对码的部分函数依赖和传递函数依赖。∴ 此关系模式属于3NF。基于此关系模式的关系(具体的数据)可能如图所示: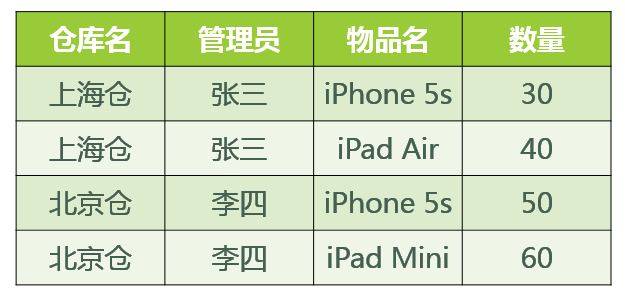 好,既然此关系模式已经属于了 3NF,那么这个关系模式是否存在问题呢?我们来看以下几种操作:先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。从这里我们可以得出结论,在某些特殊情况下,即使关系模式符合 3NF 的要求,仍然存在着插入异常,修改异常与删除异常的问题,仍然不是 ”好“ 的设计。造成此问题的原因:存在着主属性对于码的部分函数依赖与传递函数依赖。(在此例中就是存在主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。解决办法就是要在 3NF 的基础上消除主属性对于码的部分与传递函数依赖。仓库(仓库名,管理员)库存(仓库名,物品名,数量)这样,之前的插入异常,修改异常与删除异常的问题就被解决了。以上就是关于 BCNF 的解释。最近身体不太舒服,写不动了。有空再放几个典型习题及其解答吧。
好,既然此关系模式已经属于了 3NF,那么这个关系模式是否存在问题呢?我们来看以下几种操作:先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。从这里我们可以得出结论,在某些特殊情况下,即使关系模式符合 3NF 的要求,仍然存在着插入异常,修改异常与删除异常的问题,仍然不是 ”好“ 的设计。造成此问题的原因:存在着主属性对于码的部分函数依赖与传递函数依赖。(在此例中就是存在主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。解决办法就是要在 3NF 的基础上消除主属性对于码的部分与传递函数依赖。仓库(仓库名,管理员)库存(仓库名,物品名,数量)这样,之前的插入异常,修改异常与删除异常的问题就被解决了。以上就是关于 BCNF 的解释。最近身体不太舒服,写不动了。有空再放几个典型习题及其解答吧。
===============================
问题1:李德竹 :老师您好,我看了您关于数据库范式的回答,有一点不太理解,就是关于码的定义,如果除K之外的所有属性都完全函数依赖于K时才能称K为码,那么在判断2NF时又怎么会存在非主属性对码的部分函数依赖这种情况?希望老师有时间能指点一下,谢谢我 :在“码”的定义中,除 K 之外的所有属性应该看成是一个集合 U(也就是一个整体),也就是说,只有 K 能够完全函数决定 U 中的每一个属性,那么 K 才是码。如果 K 只是能够完全函数决定 U 中的一部分属性,而不能完全函数决定另外一部分属性,那么 K 不是码。比如有关系模式 R (Sno, Sname, Cno, Cname, Sdept, Sloc, Grade),其中函数依赖集为 F= {Sno → Sname, Sno → Sdept, Sdept → Sloc,Sno → Sloc, Cno → Cname, (Sno, Cno) → Grade }那么 R 中的码只能是 (Sno, Cno),Sno 或 Cno 并不能完全函数决定除 Sno / Cno 之外的所有其他属性(其实就是不能决定 Grade ),所以单独的 Sno 与 Cno 并不能作为码。所以可得到主属性:Sno, Cno非主属性:Sname, Cname, Sdept, Sloc, GradeR 中存在非主属性 Cname 对于码 (Sno, Cno) 的部分函数依赖 (Cno → Cname) 。(还有很多别的例子就不一一列举了)。所以 R 不符合 2NF 的要求。========================================花了好几天断断续续写了这个答案,累死我了。看有不少人对此有疑问,干脆写一个详细点的,希望成为这个知识点的权威回答……如果有一些细节方面的问题,比如表达上,还会进行修改,大的方面,肯定是没错的。编辑于 2017-10-26赞同 8493505 条评论分享收藏喜欢收起继续浏览内容知乎发现更大的世界打开Chrome继续更多回答王红波智能数据技术服务创业者512 人赞同了该回答谢邀。这个问题不太好解释,我尽力吧!一范式就是属性不可分割。属性是什么?就是表中的字段。不可分割的意思就按字面理解就是最小单位,不能再分成更小单位了。这个字段只能是一个值,不能被拆分成多个字段,否则的话,它就是可分割的,就不符合一范式。不过能不能分割并没有绝对的答案,看需求,也就是看你的设计目标而定。举例:学生信息组成学生信息表,有姓名、年龄、性别、学号等信息组成。姓名不可拆分吧?所以可以作为该表的一个字段。但我要说这个表要在国外使用呢?人家姓和名要分开,都有特别的意义,所以姓名字段是可拆分的,分为姓字段和名字段。简单来说,一范式是关系数据库的基础,但字段是否真的不可拆分,根据你的设计目标而定。二范式就是要有主键,要求其他字段都依赖于主键。为什么要有主键?没有主键就没有唯一性,没有唯一性在集合中就定位不到这行记录,所以要主键。其他字段为什么要依赖于主键?因为不依赖于主键,就找不到他们。更重要的是,其他字段组成的这行记录和主键表示的是同一个东西,而主键是唯一的,它们只需要依赖于主键,也就成了唯一的。如果有同学不理解依赖这个词,可以勉强用“相关”这个词代替,也就是说其他字段必须和它们的主键相关。因为不相关的东西不应该放在一行记录里。举例:学生信息组成学生表,姓名可以做主键么?不能!因为同名的话,就不唯一了,所以需要学号这样的唯一编码才行。那么其他字段依赖于主键是什么意思?就是“张三”同学的年龄和性别等字段,不能存储别人的年龄性别,必须是他自己的,因为张三的学号信息就决定了,这行记录归张三所有,不能给无关人员使用。三范式就是要消除传递依赖,方便理解,可以看做是“消除冗余”。消除冗余应该比较好理解一些,就是各种信息只在一个地方存储,不出现在多张表中。比如说大学分了很多系(中文系、英语系、计算机系……),这个系别管理表信息有以下字段组成:系编号,系主任,系简介,系架构。那么再回到学生信息表,张三同学的年龄、性别、学号都有了,我能不能把他的系编号,系主任、系简介也一起存着?如果你问三范式,当然不行,因为三范式不同意。因为系编号,系主任、系简介已经存在系别管理表中,你再存入学生信息表,就是冗余了。三范式中说的传递依赖,就出现了。这个时候学生信息表中,系主任信息是不是依赖于系编号了?而这个表的主键可是学号啊!所以按照三范式,处理这个问题的时候,学生表就只能增加一个系编号字段。这样既能根据系编号找到系别信息,又避免了冗余存储的问题。所谓的范式,是用来学习参考的,设计的时候根据情况,未必一定要遵守,切记。三范式都能码这么多字,我果然越来越水了:)
六、GO操作MySQL
1.下载驱动
go get github.com/go-sql-driver/mysql
database/sql
原生支持连接池,并发是安全的。
这个标准库没有具体的实现,只是列出了一些需要第三方库实现的具体内容。

若有收获,就点个赞吧
0 人点赞
