正则表达式可以通过字面量或RegExp构造函数定义。
var pattern2 = /\[bc\]at/i;var pattern2 = new EegExp("[bc]at", "i");
匹配示例:
一个正则表达式是一个模式与标志的组合体。
- 模式部分可以是任何简单或复杂的正则表达式。
- 模式中使用的所有元字符都必须转义
- 标志:
- g:全局模式,模式将被应用于所有字符串。
- i:不区分大小写模式。
- m:多行模式。
- y:粘附模式,表示只查找从lastIndex开始及之后的字符串。
- u: Unicode模式,启用Unicode匹配。
- s:dotAll模式,表示元字符.匹配任何字符(包括\n或\r)
RegExp实例方法
1、exec()专门为捕获组而设计
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec
参数:要应用模式的字符串// Match "quick brown" followed by "jumps", ignoring characters in between// Remember "brown" and "jumps"// Ignore caselet re = /quick\s(brown).+?(jumps)/igd;let result = re.exec('The Quick Brown Fox Jumps Over The Lazy Dog');
返回值
| Property/Index | Description | Example |
|---|---|---|
| [0] | The full string of characters matched | “Quick Brown Fox Jumps” |
| [1], …[n] | 圆弧内匹配的文字,数量不限 | result[1] === “Brown” result[2] === “Jumps” |
| index | The 0-based index of the match in the string. | 4 |
| indices | ? | indices[0] === Array [ 4, 25 ] indices[1] === Array [ 10, 15 ] indices[2] === Array [ 20, 25 ] indices.groups === undefined indices.length === 3 |
| input | 原字符串 | The Quick Brown Fox Jumps Over The Lazy Dog |
捕获组与非捕获组
https://shimo.im/docs/GdKhP9QgxXHpqPpP/read
- 捕获组
- 目的:为了将分组中匹配到的内容保存到内存中,以供后续使用
- 形式:
- 捕获组:使用()包起来的正则表达式
- 命名捕获组
- ES6新增
- 写法:(?
pattern) 或 (?’name’pattern) 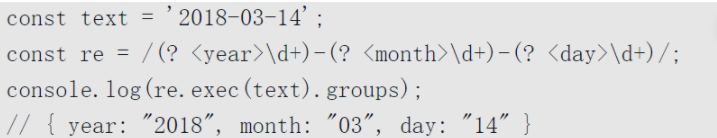
- 应用:详见【实战演练:捕获组反向引用】
- 非捕获组
- 存在的意义是只匹配字符信息,不捕获文本,从而节省内存
- 除命名捕获组外,凡是以 (?) 开头的捕获组就是非捕获组
- 非捕获组具有以下特点:
- 不捕获文本,不占用内存无分组编号
- 不可被反向引用
元字符
所有元字符见:https://www.runoob.com/regexp/regexp-metachar.html基础元字符
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。
例如,’n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\\‘ 匹配 “\“ 而 “\(“ 则匹配 “(“。 | | —- | —- | | ^ | 匹配输入字符串的开始位置。
如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 | | $ | 匹配输入字符串的结束位置。
如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 | | | 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 | | + | 匹配前面的子表达式一次或多次。
例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 | | . | 匹配除换行符(\n、\r)之外的任何单个字符。
要匹配包括 ‘\n’ 在内的任何字符,请使用像”(.|\n)“的模式。 | | ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 | | ? | 当该字符紧跟在任何一个其他限制符 【, +, ?, {n}, {n,}, {n,m}】后面时,匹配模式是非贪婪的。
非贪婪模式尽可能少的匹配所搜索的字符串。
例如,对于字符串 “oooo”,’o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
集合元字符
| x|y | 匹配 x 或 y。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
|---|---|
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、’l’、’i’、’n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
字符系列
| \d | 匹配一个数字字符。等价于 [0-9]。 |
|---|---|
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
捕获组、非捕获组
| (pattern) | 【获取匹配结果】 匹配 pattern 并获取这一匹配。 |
|---|---|
| (? (?’name’pattern) |
【获取匹配结果】 命名匹配 pattern 并获取这一匹配。 |
| (?:pattern) | 【仅匹配,不保存】 匹配 pattern 但不获取匹配结果,不进行存储供以后使用。 例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
| (?=pattern) | 【仅匹配,不保存】 followed by 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。 例如,”Windows(?=95|98|NT|2000)”能匹配”Windows2000”中的”Windows”,但不能匹配”Windows3.1”中的”Windows”。 |
| (?!pattern) | 【仅匹配,不保存】 not followed by 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。 例如”Windows(?!95|98|NT|2000)”能匹配”Windows3.1”中的”Windows”,但不能匹配”Windows2000”中的”Windows”。 |
| (?<=pattern) | 【仅匹配,不保存】 反向肯定预查,与正向肯定预查类似,只是方向相反。 例如,”(?<=95|98|NT|2000)Windows”能匹配”2000Windows”中的”Windows”,但不能匹配”3.1Windows”中的”Windows”。 |
| (?<!pattern) | 【仅匹配,不保存】 反向否定预查,与正向否定预查类似,只是方向相反。 例如”(?<!95|98|NT|2000)Windows”能匹配”3.1Windows”中的”Windows”,但不能匹配”2000Windows”中的”Windows”。 |
{}系列
匹配多少次
| {n} | 匹配确定的 n 次。 例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
|---|---|
| {n,} | 至少匹配n 次。 |
| {n,m} | 最少匹配 n 次且最多匹配 m 次。 |
其他补充
String.prototype.replace
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/String/replace
第二个参数是Function时,该函数的变量信息:
| 变量名 | 代表的值 |
|---|---|
| match | 匹配的子串。(对应于上述的$&。) |
| p1,p2, … | 假如 replace() 方法的第一个参数是一个RegExp 对象,则代表第 n 个括号匹配的字符串。(对应于上述的$1,$2等。)例如,如果是用 /(\a+)(\b+)/ 这个来匹配,p1 就是匹配的 \a+,p2 就是匹配的 \b+。 |
| offset | 匹配到的子字符串在原字符串中的偏移量。(比如,如果原字符串是 ‘abcd’,匹配到的子字符串是 ‘bc’,那么这个参数将会是 1) |
| string | 被匹配的原字符串。 |
| NamedCaptureGroup | 命名捕获组匹配的对象 |
主要用到前2个,比如:
- match:【字符串首字母大写】
- p1,p2:【将字符串驼峰化】
全局标志会改变正则的lastindex

实战演练
例题:https://juejin.cn/post/7070284710131269669
测试工具:https://c.runoob.com/front-end/854/
可视化工具:https://regexper.com/#%2F%5C%2F%5C%2F%28.%29%2B%2Fg捕获组反向引用
```javascript const date = ‘2021-02-10’; // 捕获组 date.replace(/(\d{4})-(\d{2})-(\d{2})/, ‘$1-$3-$2’); // ‘2021-10-02’
// 命名捕获组
date.replace(/(?
<a name="fz2JW"></a>## 实现一个 trim 方法[https://www.cnblogs.com/rubylouvre/archive/2009/09/18/1568794.html](https://www.cnblogs.com/rubylouvre/archive/2009/09/18/1568794.html)(介绍了12种实现)<br />str.replace(/^\s\s*/, '').replace(/\s\s*$/, '');<br />str.replace(/^\s+|\s+$/g, '');<a name="rZKlJ"></a>## 解析url```javascriptfunction urlParse(url) {const paramStr = /.+\?(.+)$/.exec(url)[1]; // 将 ? 后面的字符串取出来const paramAtr = paramStr.split('&');const obj = {};paramArr.forEach((param) => {if(param.includes('=')) { // 处理有=的参数/=/.test(param)let [key, val] = param.split('=');val = decodeURIComponent(val); // 解码val = /^\d+$/.test(val) ? parseFloat(val) : val; // 判断是否转为数字// 添加对象if(obj[key]) {obj[key] = [].concat(obj[key], val)} else {obj[key] = val;}} else {obj[param] = true;}});return obj;}
模板字符串(非react)
模板字符串形态’我是{{name}},年龄{{age}},性别{{sex}}’
模板字符串正则:/{{(\w+)}}/
function render(template, data) {const reg = /\{\{(\w+)\}\}/if(reg.test(template)) {const name = reg.exec(template)[1];template = template.replace(reg, data[name]);return render(template, data);} else {return template;}}

数字价格千分位分割
知识点:
- (?!pattern) not followed by
- (?=pattern) follewed by
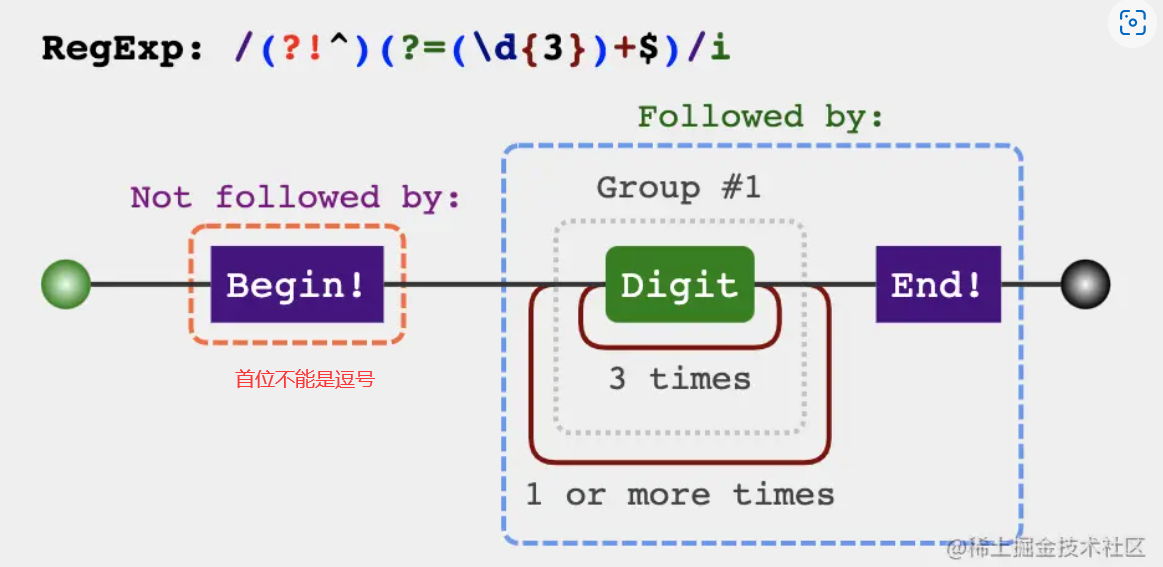
'123456789'.replace(/(?!^)(?=(\d{3})+$)/g, ',') // 123,456,789
手机号344分割:每四个数字前的位置,并把这个位置替换为-
'18379836654'.replace(/(?=(\d{4})+$)/g, '-') // 183-7983-6654
将字符串驼峰化

function camelCase(str) {const reg = /[-_\s]+(.)?/gstr.replace(reg, (match, char) => {// char匹配的是第一个()内的内容return char ? char.toUpperCase() : ''});return str;}console.log(camelCase('foo Bar')) // fooBarconsole.log(camelCase('foo-bar--')) // fooBarconsole.log(camelCase('foo_bar__')) // fooBar
字符串首字母大写
找到字符串的开头字符+所有以空格开头的首字符
\s+可以匹配多空格情况
function capitalize(str) {const reg = /(?:^|\s+)\w/g;return str.toLowerCase().replace(reg, (match) => match.toUpperCase());}console.log(capitalize('hello world')) // Hello Worldconsole.log(capitalize('hello WORLD')) // Hello World
提取连续重复的字符
反向引用的应用
function collectRepeatStr(str) {const reg = /(.+)\1+/gconst result = [];return str.replace(reg, ($0, $1) => {$1 && result.push($1)});return result;}console.log(collectRepeatStr('11')) // ["1"]console.log(collectRepeatStr('12323')) // ["23"]console.log(collectRepeatStr('12323454545666')) // ["23", "45", "6"]
实用VSCode正则
查找带有extra属性的TreeNode组件引用:
(?<=<TreeNode)(.*\n)*\s{1,}extra=
不可输入—

先排除-是为了防止永远进入到第一个判断。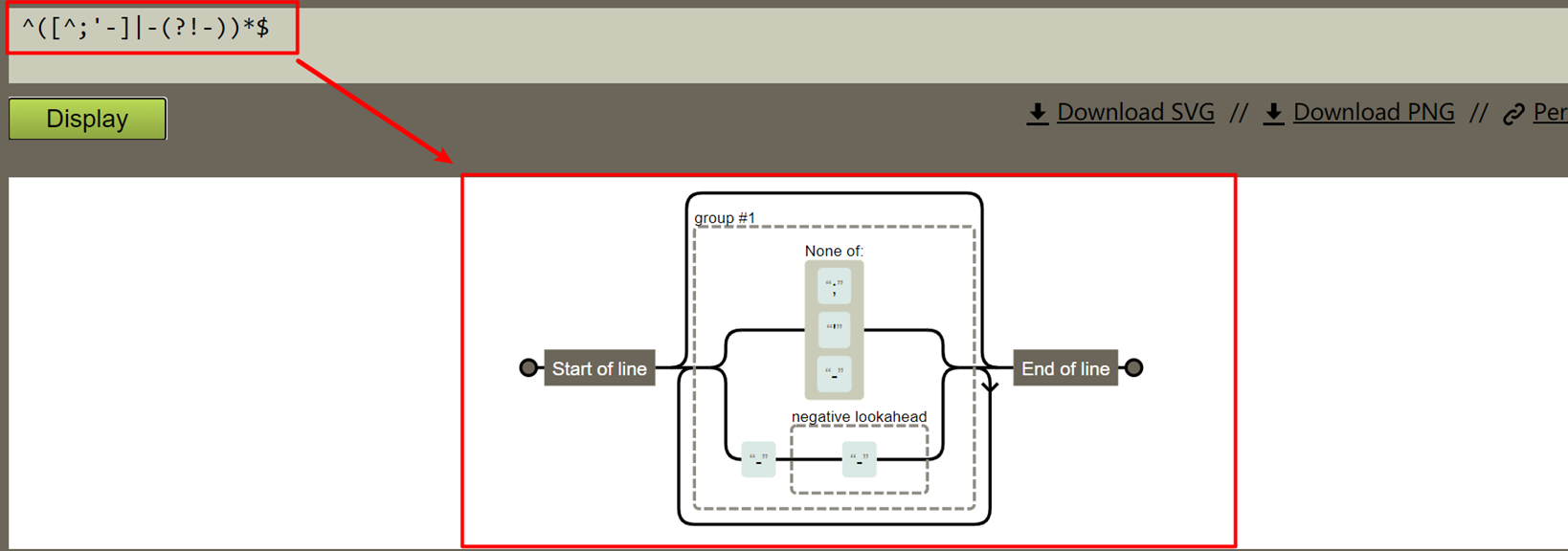

若有收获,就点个赞吧
0 人点赞
