- 行内样式替换;计算样式读取;
- 元素偏移;元素大小;
-
书摘&心得
1 概览
DOM1级主要定义HTML和XML文档的底层结构,
- DOM2和DOM3级则在这个结构的基础上引入了更多的交互能力,也支持更高级的XML特性。
-
2 样式
2.1 行内样式
DOM2级样式规范为style对象定义了一些属性和方法,在提供元素的style特性值的同时,也可以修改样式。
style对象处理的是行内样式,不包含从其他样式表层叠而来影响到当前元素的样式信息。
- 提供了getComputedStyle()方法,该方法接受2个参数
- 要取得计算样式的元素、一个伪元素字符串(:after | null)
- 返回一个CSSStyleDeclaration对象(与style属性的类型相同),其中包含当前元素的所有计算的样式。
- 以下代码可以取得这个元素计算后的样式:
-
2.3 元素大小
偏移量offsetTop/Left/Width/Height

偏移量属性是只读的,每次访问它们需要重新计算,应该尽量避免重复访问这些属性。
如果需要重复使用某些属性的值,可以将它们保存在局部变量中以提高性能。
客户区大小ClientHegiht/Width
包含滚动内容的元素的大小。
- 有的元素(如html),没有执行任何代码也能自动添加滚动条,另外一些元素要通过设置CSS的overflow属性才能滚动。

scrollWidth和scrollHeight主要用于确定元素内容的实际大小

确定元素大小getBoundingClientRect
getBoundingClientRect()返回一个矩形对象,包含4个方位属性
-
3遍历
DOM2定义了两个用于辅助完成顺序遍历DOM结构的类型:NodeIterator和TreeWalker
3.1 NodeIterator
使用document.createNodeIterator()方法创建它的新实例,接受下列4个参数

3.1.1 参数详解
1、whatToShow参数
2、filter参数
NodeFilter对象指定一个功能类似节点过滤器的函数
- NodeFilter对象只有一个方法acceptNode()
- 如果应该访问给定的节点,该方法返回NodeFilter.FILTER_ACCEPT,反之返回NodeFilter.FILTER_SKIP
- 下列代码展示了如何创建一个只显示
元素的节点迭代器:
- 也可以是一个与acceptNode()方法类似的函数:
-
3.1.2 遍历器的使用
两个主要方法:nextNode()和previousNode()
nextNode()方法
- nextNode()方法用于向前前进一步
- 第一次调用nextNode()会返回根节点
- 遍历到DOM子树的最后一个节点会返回null
- 示例
previousNode()方法
TreeWalker是NodeIterator的一个更高级的版本
- 除了包括相同的功能外,还提供了下列在不同方向上遍历DOM结构的方法
- 使用document.createTreeWalker()方法
- 接收参数和NodeIterator一样,很容易用TreeWalker代替NodeIterator
- filter可以返回的值有所不同
- 新增返回值NodeFilter.FILTER_REJECT
- NodeFilter_SKIP会跳过相应节点继续进到子树中的下一个节点,NodeFilter.FILTER_REJECT会跳过相应节点及该节点的整个子树。
- TreeWalker强大的地方在于能够在DOM结构中沿任何方向移动:
- TreeWalker类型还有一个属性currentNode,表示任何遍历方法在上一次遍历中返回的节点。
- 设置这个属性可以修改遍历继续进行的起点:

- IE不支持

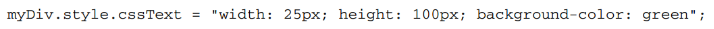










若有收获,就点个赞吧
0 人点赞
