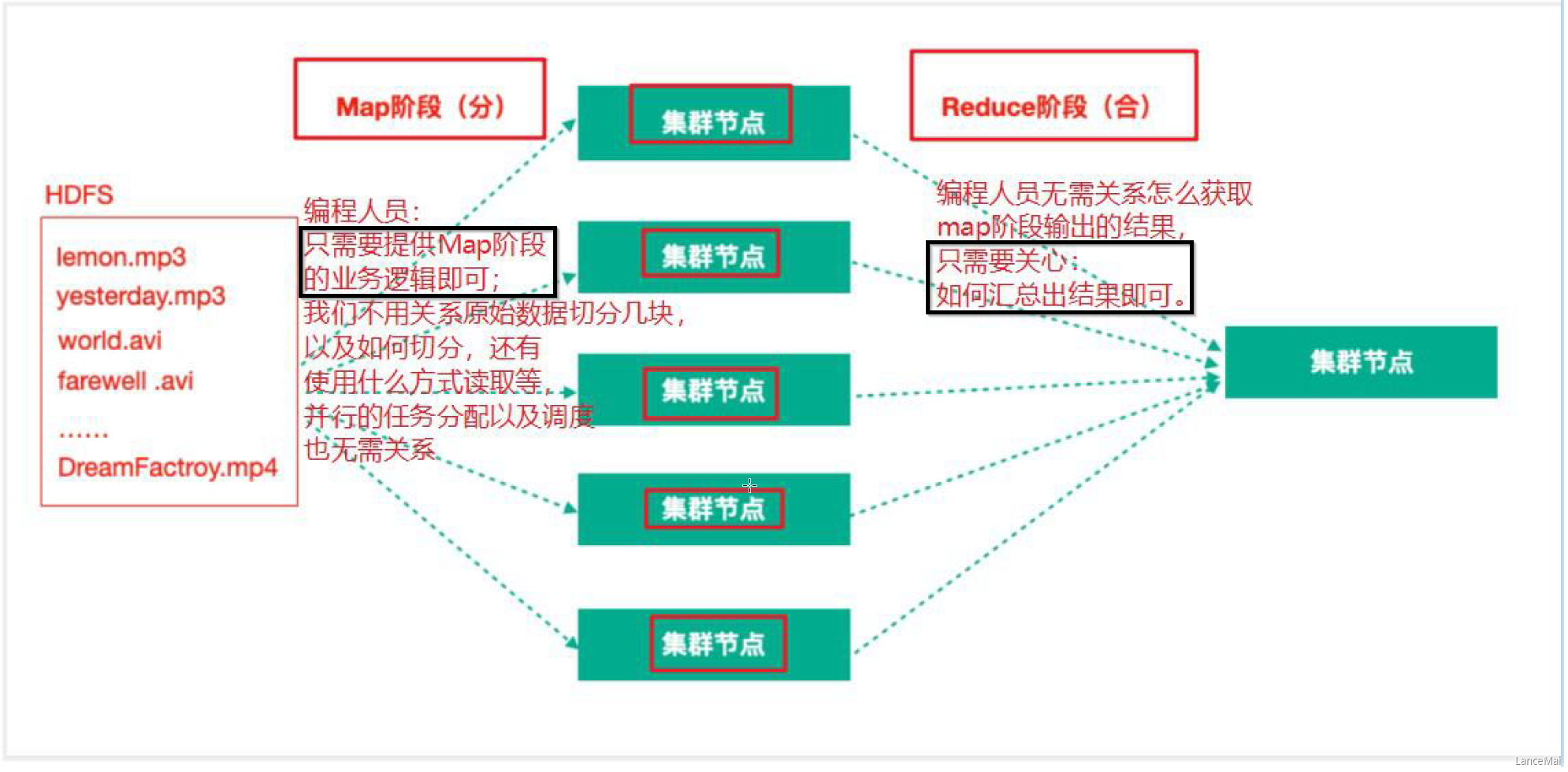
MapReduce 思想
- MapReduce 任务过程是分为两个处理阶段
- Map 阶段
- Map 阶段的主要作用是“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。Map 阶段的这些任务可以并行计算,彼此间没有依赖关系
- Reduce 阶段
- Reduce 阶段的主要作用是“合”,即对 map 阶段的结果进行全局汇总
- Map 阶段
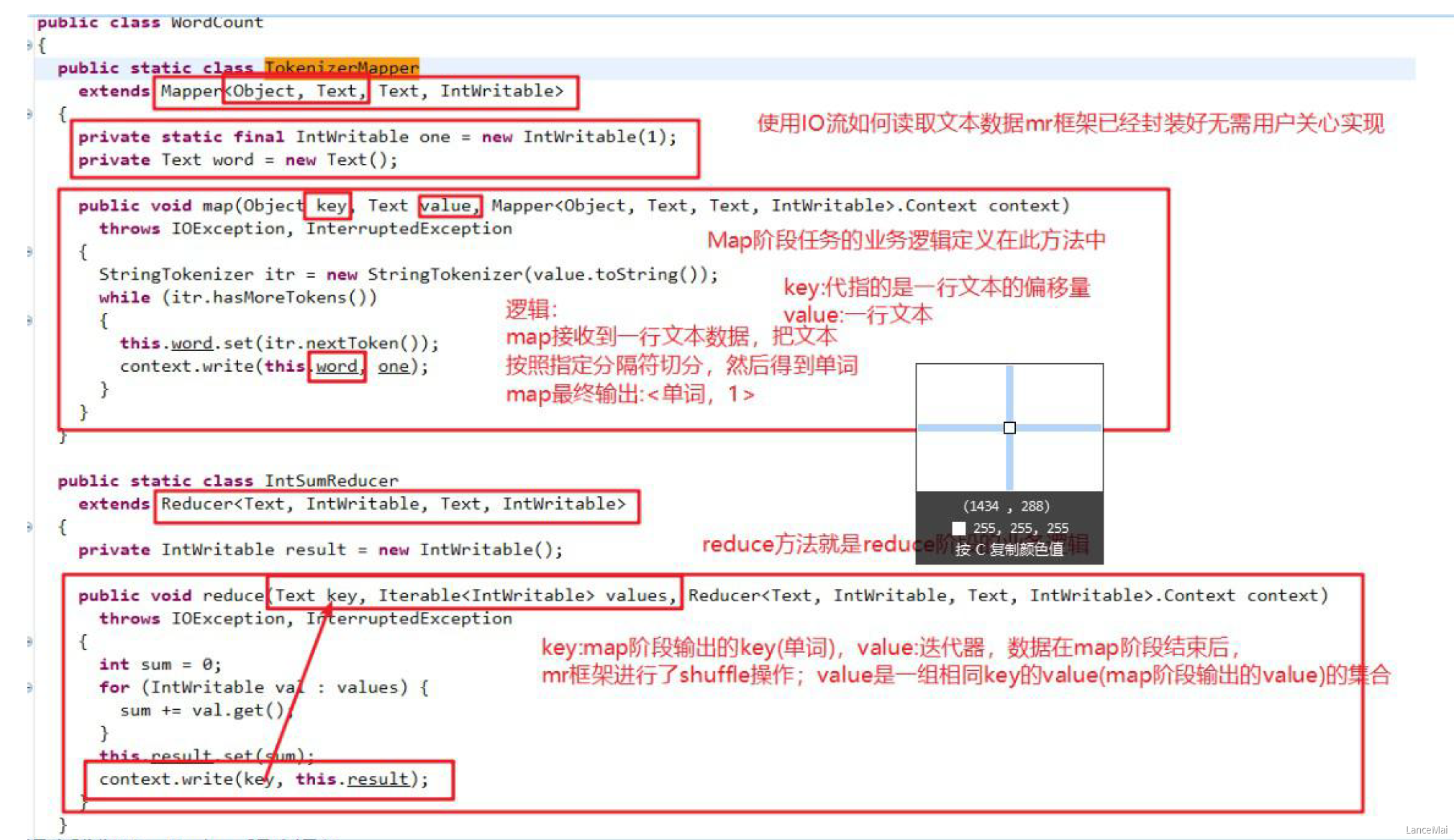
一、WordCount 官方源码解析
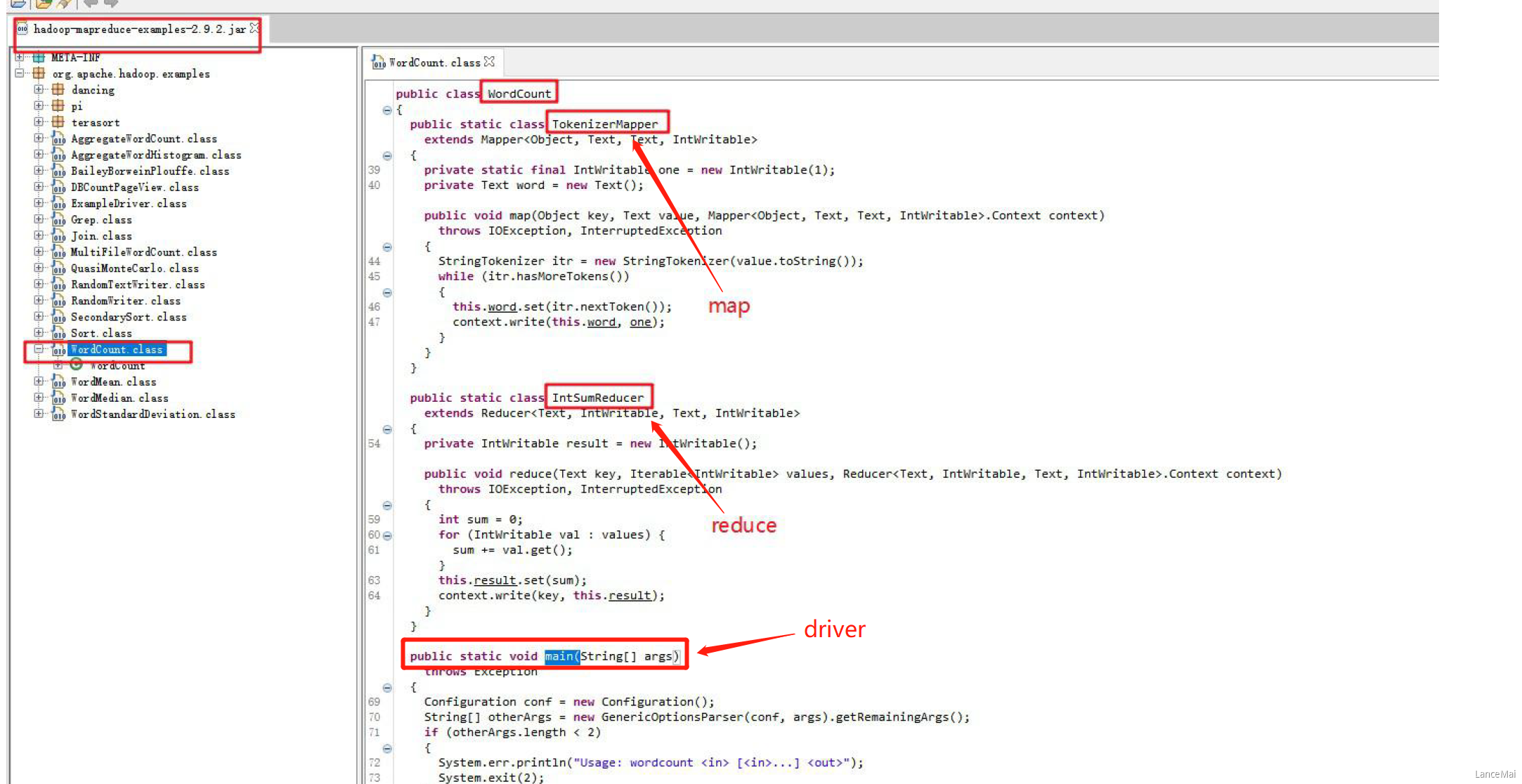
- 由源码可知,一个统计单词数量的 MapReduce 程序的代码由三个部分组成
- Mapper 类
- Mapper类继承了 org.apache.hadoop.mapreduce.Mapper类,重写了其中的 map 方法
- 重写的 Map 方法作用
- map 方法其中的逻辑就是用户希望 mr 程序 map 阶段如何处理的逻辑
- Reducer 类
- Reducer类继承了 org.apache.hadoop.mapreduce.Reducer类,重写了其中的 reduce 方法
- 重写的 Reduce 方法作用
- reduce 方法其中的逻辑是用户希望 mr程序 reduce 阶段如何处理的逻辑
- 运行作业的代码(Driver)
- Mapper 类
二、MapReduce 编程规范
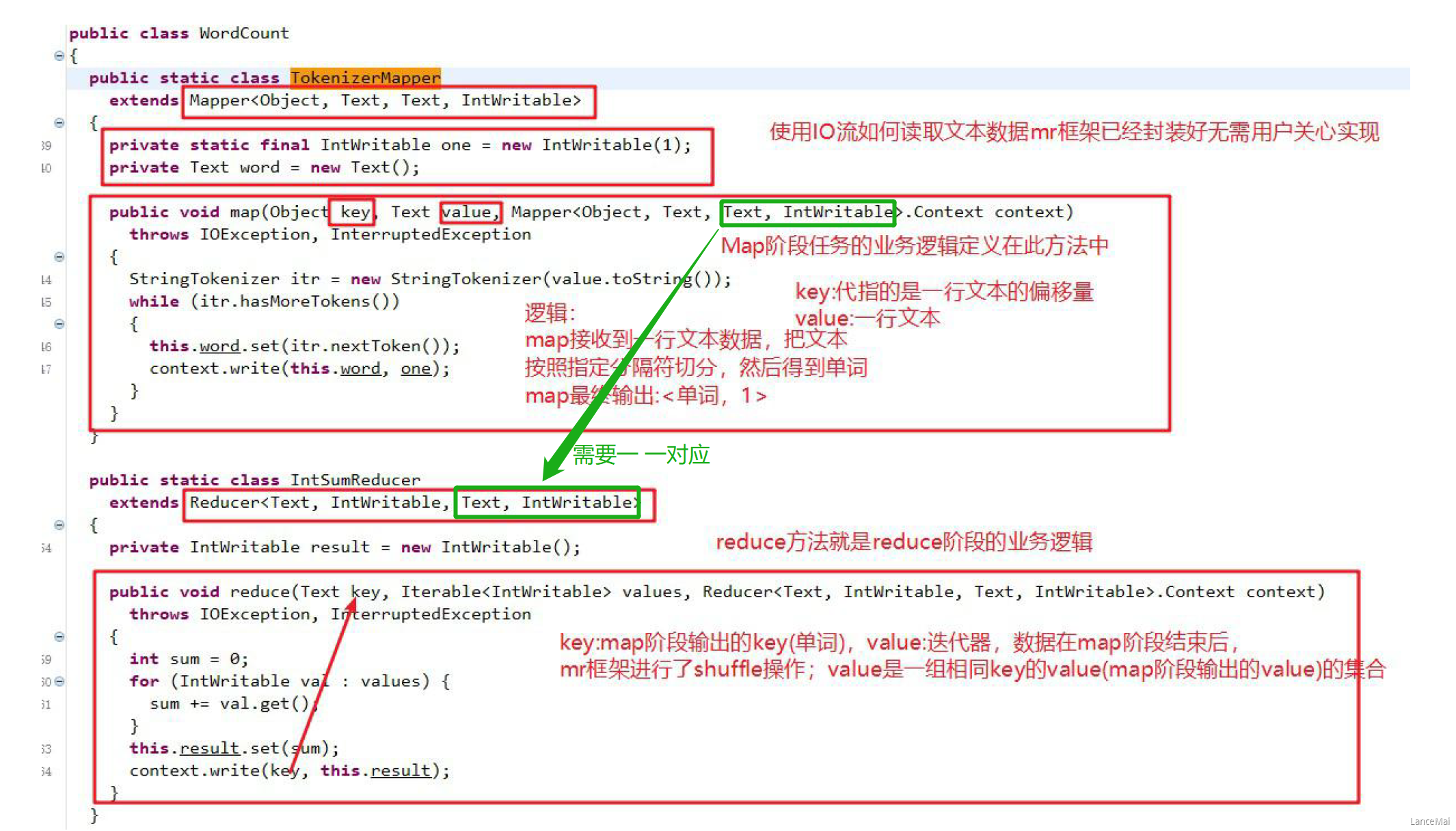
Mapper 类
- 用户自定义一个 Mapper 类继承 Hadoop 的 Mapper 类
- Mapper 的 输入数据 是 key-value对 的形式(类型可以自定义)
- Map 阶段的业务逻辑定义在 map() 方法中
- Mapper 的 输出数据 是 key-value对 的形式(类型可以自定义)
-
Reducer 类
用户自定义 Reducer 类要继承 Hadoop 的 Reducer 类
- Reducer 的 输入数据类型对应 Mapper 的 输出数据类型(key-value对)
- Reduce 的业务逻辑写 在reduce() 方法中
Reduce() 方法是对相同key的⼀组KV对调用执行⼀次
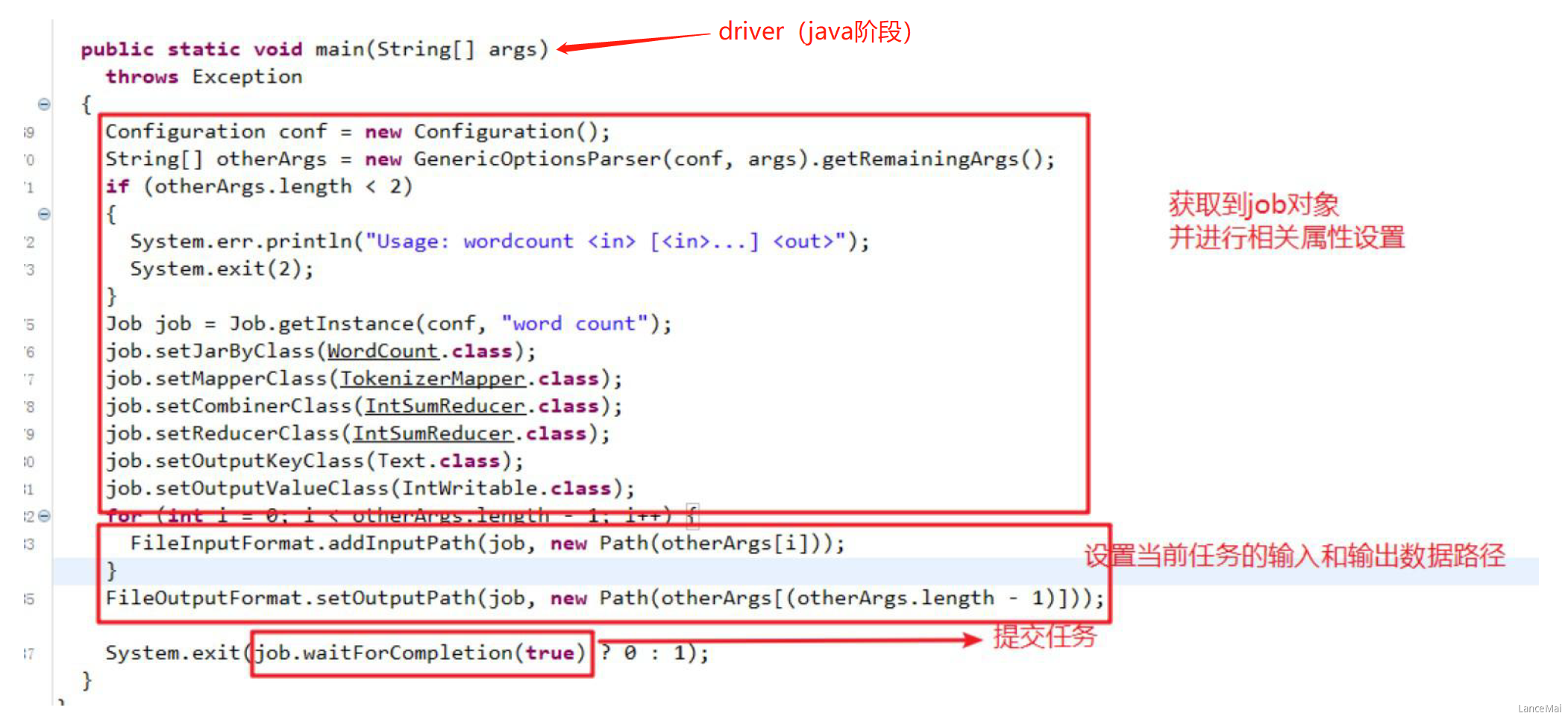
Driver 阶段
创建提交 YARN 集群运行的 Job 对象,其中封装了 MapReduce 程序运行所需要的相关参数、输入数据路径、输出数据路径等
- 相当于是一个YARN集群的客户端,主要作用就是提交 MapReduce 程序运行
- 思路整理
- Map 阶段
- map() 方法中把传入数据转为 String
- 根据空格切分单词
- 输出 元组 <单词,1>
- Reduce 阶段
- 汇总各个key(单词)的个数,遍历 value 数据进行累加
- 输出 key 的总数
- Driver
- 获取配置文件对象,获取 job 对象实例
- 指定程序 jar 的本地路径
- 指定 Mapper/Reducer 类
- 指定 Mapper 输出的 kv 数据类型
- 指定 Reducer 最终输出的 kv 数据类型
- 指定 job 处理的原始数据路径
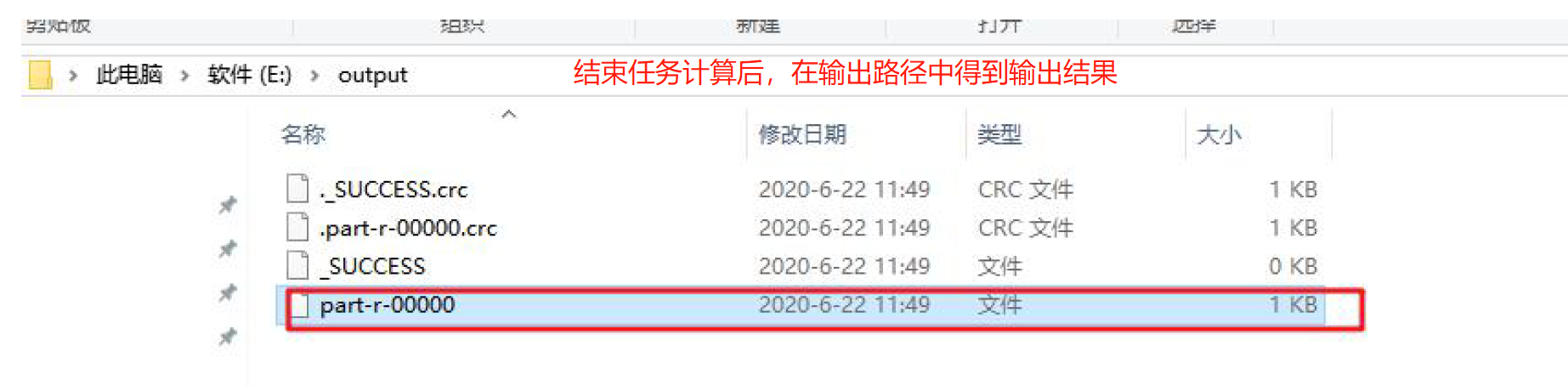
- 指定 job 输出结果路径
- 提交 job
- Map 阶段
三、WordCount 案例实现
Mapper 类
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1 获取⼀⾏String line = value.toString();// 2 切割String[] words = line.split(" ");// 3 输出for (String word : words) {k.set(word);context.write(k, v);}}}

Reducer 类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values){
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}

Driver 驱动类
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路路径
job.setJarByClass(WordcountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输⼊入和输出路路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
// jvm退出: 正常退出0,非正常退出不为0
System.exit(result ? 0 : 1);
}
}
运行任务
本地模式
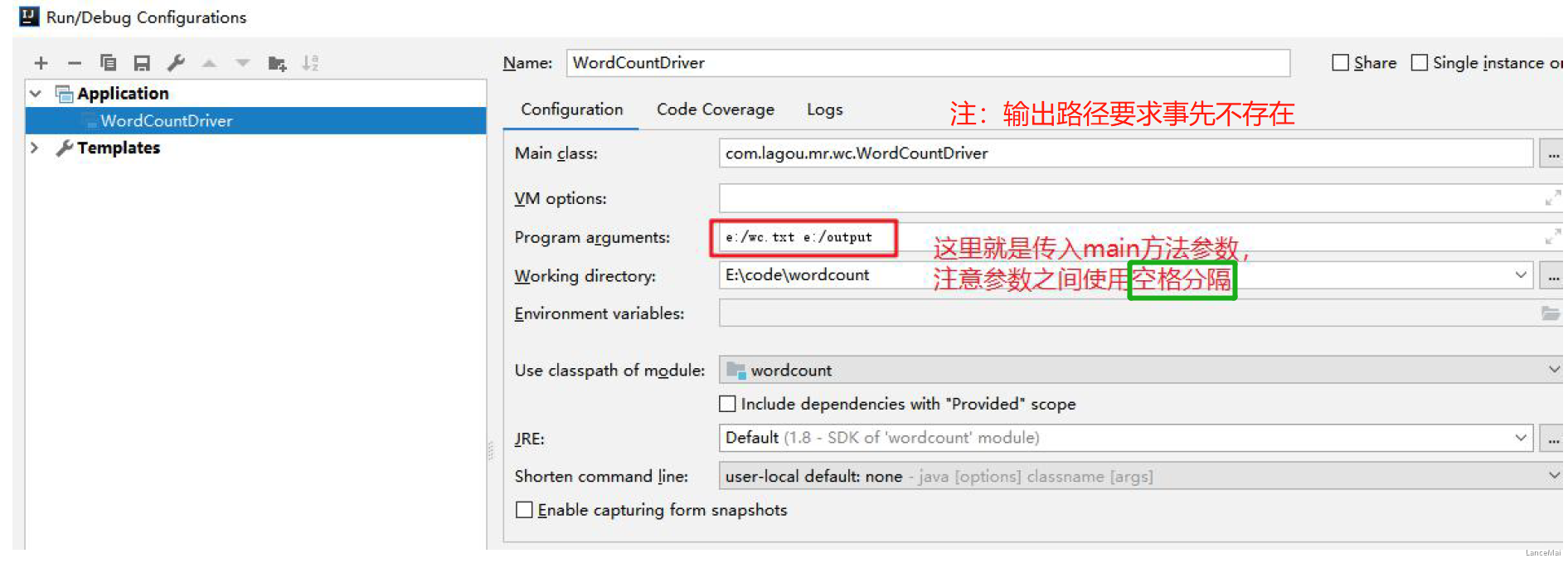
- 直接 Idea 中运行 驱动类 即可
- Idea 运行需要 传入参数(
String[] args) 注:本地 idea 运行 mr 任务与集群没有任何关系,没有提交任务到 yarn 集群,是在本地使用多线程方式模拟的 mr 的运行
- 把程序打成 jar 包,改名为 wc.jar,然后上传到 Hadoop 集群
- 注:jar 包 在集群中的任意一台有 Hadoop环境的机器上 都可以运行计算
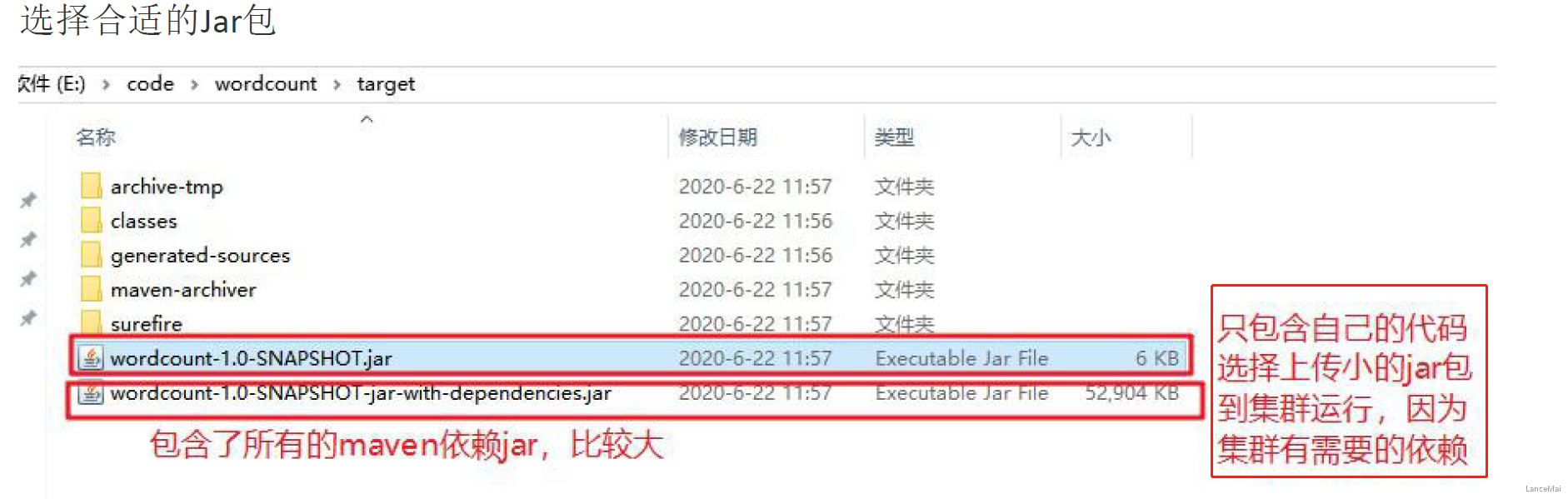
- 把程序打成 jar 包,改名为 wc.jar,然后上传到 Hadoop 集群
- 2. 准备原始数据文件,**上传到 HDFS 的路径,不能是本地路径**,因为跨节点运行行无法获取数据 !!!
- 启动 Hadoop 集群(Hdfs、Yarn、JobHistoryServer)
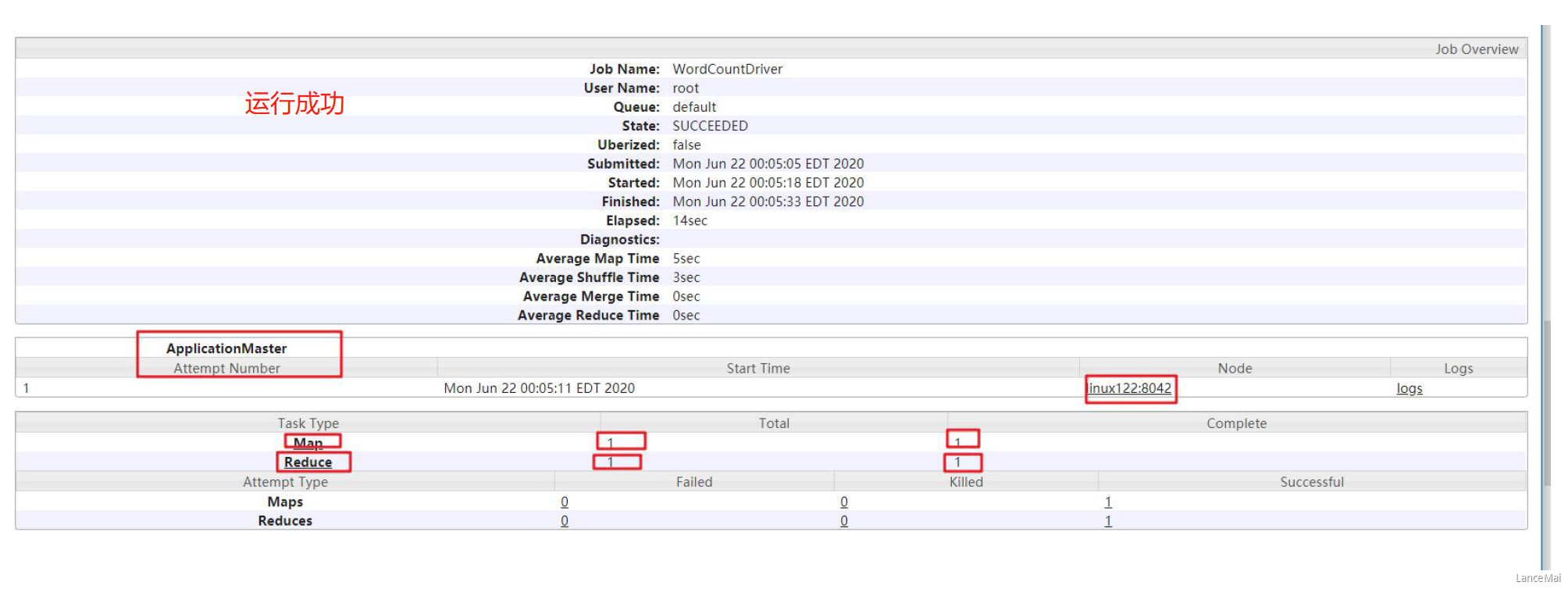
- 使用 Hadoop 命令提交任务运行
- 其中的 com.lagou.wordcount.WordcountDriver 是jar包中主程序的全路径
hadoop jar wc.jar com.lagou.wordcount.WordcountDriver /wcinput/input /wcoutput/output
- 使用 Hadoop 命令提交任务运行

若有收获,就点个赞吧
0 人点赞
