三、HBase API应用和优化
1、HBase API客户端操作
- 包括 增、删、改、查
先添加依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.3.1</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>org.testng</groupId><artifactId>testng</artifactId><version>6.14.3</version><scope>test</scope></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version><scope>compile</scope></dependency>
代码实现
package com.lagou.hbase.client;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class HbaseClientDemo {
Configuration conf = null;
Connection connection = null;
Table student = null;
@Before
public void init() throws IOException {
//获取一个配置文件对象
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","linux121,linux122");
conf.set("hbase.zookeeper.property.clientPort","2181");
//通过conf获取到hbase集群的连接
connection = ConnectionFactory.createConnection(conf);
}
//创建一张hbase表
@Test
public void createTable() throws IOException {
//获取HbaseAdmin对象,用于创建表
HBaseAdmin admin = (HBaseAdmin)connection.getAdmin();
//创建HTabledesc描述器,表描述器
HTableDescriptor student = new HTableDescriptor(TableName.valueOf("student"));
//指定列族
HTableDescriptor info = student.addFamily(new HColumnDescriptor("info"));
admin.createTable(student);
System.out.println("student 创建成功。");
}
//插入一条数据
@Test
public void putData() throws IOException {
//获取一个table对象
student = connection.getTable(TableName.valueOf("student"));
//准备一个put对象
Put put = new Put(Bytes.toBytes("110")); //指定rowKey
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("addr"), Bytes.toBytes("Hainan"));
//插入数据
student.put(put);
//关闭table对象
student.close();
System.out.println("插入数据到student表成功!");
}
//删除数据
@Test
public void deleteData() throws IOException {
//获取一个table对象
student = connection.getTable(TableName.valueOf("student"));
//准备一个delete对象
Delete delete = new Delete(Bytes.toBytes("110"));
//执行删除
student.delete(delete);
//关闭table对象
student.close();
System.out.println("删除成功!");
}
//查询数据
@Test
public void getData() throws IOException {
//获取一个table对象
student = connection.getTable(TableName.valueOf("student"));
//准备一个get对象
Get get = new Get(Bytes.toBytes("110"));
//指定查询某个列族或者列
get.addFamily(Bytes.toBytes("info"));
//执行查询
Result result = student.get(get);
//获取到result中所有cell对象
Cell[] cells = result.rawCells();
//遍历打印
for (Cell cell : cells) {
String rowKey = Bytes.toString(CellUtil.cloneRow(cell));
String f = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowKey + "----" + f + "---" + column + "---" + value);
}
student.close();
}
//全表扫描 scan
@Test
public void scanData() throws IOException {
//获取一个table对象
student = connection.getTable(TableName.valueOf("student"));
//准备一个get对象
Scan scan = new Scan();
//执行扫描
ResultScanner scannerResult = student.getScanner(scan);
for (Result result : scannerResult) {
Cell[] cells = result.rawCells();
//遍历打印
for (Cell cell : cells) {
String rowKey = Bytes.toString(CellUtil.cloneRow(cell));
String f = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowKey + "----" + f + "---" + column + "---" + value);
}
}
student.close();
}
//通过 startRowKey 和 endRowKey 进行扫描查询
@Test
public void scanStartEndData() throws IOException {
//获取一个table对象
student = connection.getTable(TableName.valueOf("student"));
//准备一个scan对象
Scan scan = new Scan();
//指定查询rowKey的区间
scan.setStartRow(Bytes.toBytes("001"));
scan.setStopRow(Bytes.toBytes("2"));
//执行扫描
ResultScanner scannerResult = student.getScanner(scan);
for (Result result : scannerResult) {
Cell[] cells = result.rawCells();
//遍历打印
for (Cell cell : cells) {
String rowKey = Bytes.toString(CellUtil.cloneRow(cell));
String f = Bytes.toString(CellUtil.cloneFamily(cell));
String column = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowKey + "----" + f + "---" + column + "---" + value);
}
}
student.close();
}
//释放连接
@After
public void release() {
if (null != connection) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2、Hbase 协处理器
① 协处理器 概述
官方文档:http://hbase.apache.org/book.html#cp
- 访问HBase的方式是使用scan或get获取数据,在获取到的数据上进行业务运算。但是在数据量非常大的时候,比如一个有上亿行及十万个列的数据集,再按常用的方式移动获取数据就会遇到性能问题。客户端也需要有强大的计算能力以及足够的内存来处理这么多的数据。
- 此时就可以考虑使用Coprocessor(协处理器)。将业务运算代码封装到Coprocessor中并在RegionServer上运行,即在数据实际存储位置执行,最后将运算结果返回到客户端。利用协处理器,用户可以编写运行在 HBase Server 端的代码。
Hbase Coprocessor类似以下概念:
- 触发器和存储过程:一个Observer Coprocessor有些类似于关系型数据库中的触发器,通过它我们可以在一些事件(如Get或是Scan)发生前后执行特定的代码。Endpoint Coprocessor则类似于关系型数据库中的存储过程,因为它允许我们在RegionServer上直接对它存储的数据进行运算,而非是在客户端完成运算。
- MapReduce:MapReduce的原则就是将运算移动到数据所处的节点。Coprocessor也是按照相同的原则去工作的。
AOP:如果熟悉AOP的概念的话,可以将Coprocessor的执行过程视为在传递请求的过程中对请求进行了拦截,并执行了一些自定义代码
② 协处理器 类型
Observer
协处理器与触发器(trigger)类似:在一些特定事件发生时回调函数(也被称作钩子函数,hook)被执行。这些事件包括一些用户产生的事件,也包括服务器端内部自动产生的事件。
协处理器框架提供的接口如下
这类协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器在Regionserver中执行一段代码,并将 RegionServer 端执行结果返回给客户端进一步处理【即移动计算,而非移动数据】
- Endpoint常见用途
- 聚合操作
- 假设需要找出一张表中的最大数据,即 max 聚合操作,普通做法就是必须进行全表扫描,然后Client代码内遍历扫描结果,并执行求最大值的操作。这种方式存在的弊端是无法利用底层集群的并发运算能力,把所有计算都集中到 Client 端执行,效率低下
- 使用Endpoint Coprocessor,用户可以将求最大值的代码部署到 HBase RegionServer 端,HBase 会利用集群中多个节点的优势来并发执行求最大值的操作。也就是在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给Client。在Client进一步将多个 Region 的最大值汇总进一步找到全局的最大值
- Endpoint Coprocessor 的应用我们后续可以借助于 Phoenix 非常容易就能实现。针对Hbase数据集进行聚合运算直接使用SQL语句就能搞定
- 聚合操作
③ Observer 案例
- 需求
- 通过协处理器Observer实现Hbase当中t1表插入数据,指定的另一张表t2也需要插入相对应的数据
create 't1','info'create 't2','info'
- 通过协处理器Observer实现Hbase当中t1表插入数据,指定的另一张表t2也需要插入相对应的数据
- 实现思路
- 通过Observer协处理器捕捉到t1插入数据时,将数据复制一份并保存到t2表中
开发步骤
(1)编写 Observer 协处理器
- 添加依赖
```java package com.lagou.hbase.processor;<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server --> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>1.3.1</version> </dependency>
import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Durability; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver; import org.apache.hadoop.hbase.coprocessor.ObserverContext; import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment; import org.apache.hadoop.hbase.regionserver.wal.WALEdit; import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class MyProcessor extends BaseRegionObserver {
//重写prePut方法,监听向t1表插入数据时,执行向t2表插入数据的代码
@Override
public void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
//把自己需要执行的逻辑定义在此处,向t2表插入数据,数据具体是什么内容与Put一样
//获取t2表的table对象
HTable t2 = (HTable)e.getEnvironment().getTable(TableName.valueOf("t2"));
//解析t1表的插入对象put,其中 get(0) 表示最新版本
Cell cell = put.get(Bytes.toBytes("info"), Bytes.toBytes("name")).get(0);
//table对象.put
Put put1 = new Put(put.getRow());
put1.add(cell);
//执行向t2表插入数据
t2.put(put1);
t2.close();
}
}
**(2)打成Jar包,上传HDFS**
```shell
cd /opt/lagou/softwares
mv original-hbaseStudy-1.0-SNAPSHOT.jar processor.jar
hdfs dfs -mkdir -p /processor
hdfs dfs -put processor.jar /processor
(3)挂载协处理器
- 进入 hbase shell
- 创建 t1 、t2 表
create 't1', 'info'create 't2', 'info'```shell describe ‘t1’ alter ‘t1’,METHOD =>’table_att’,’Coprocessor’=>’hdfs://linux121:9000/processor/processor.jar|com.lagou.hbase.processor.MyProcessor|1001|’
再次查看’t1’表,
describe ‘t1’
**(4)验证协处理器**
- 向t1表中插入数据(shell方式验证)
- `put 't1','rk1','info:name','lisi'`
- 发现 向t1插入数据后,同时在t2中发现了同样的数据,表示成功!
**(5)卸载协处理器**
- `disable 't1'`
- `alter 't1',METHOD=>'table_att_unset',NAME=>'coprocessor$1'`
- `enable 't2'`
---
<a name="aqo7C"></a>
## 4、HBase表的RowKey设计
**RowKey的基本介绍**<br />**ASCII码字典顺序:**<br />012,0,123,234,3.<br />0,3,012,123,234<br />0,012,123,234,3
**字典序的排序规则:**
- 先比较第一个字节,如果相同,然后比对第二个字节,以此类推,如果到第X个字节,其中一个已经超出了rowkey的长度,短rowkey排在前面
**RowKey长度原则**
- rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
- 建议越短越好,不要超过16个字节
- 设计过长会降低memstore内存的利用率和HFile存储数据的效率。
**RowKey散列原则**
- 建议将rowkey的高位作为散列字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。
**RowKey唯一原则**
- 必须在设计上保证其唯一性,访问hbase table中的行:有3种方式:
- 单个rowkey
- rowkey 的range
- 全表扫描(一定要避免全表扫描)
- **实现方式**:
1)org.apache.hadoop.hbase.client.Get<br />2)scan方法: org.apache.hadoop.hbase.client.Scan
- scan使用的时候注意:
- setStartRow,setEndRow 限定范围, 范围越小,性能越高。
**RowKey排序原则**
- HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点
<a name="0u3Kw"></a>
## 5、HBase表的热点
- 热点:检索habse的记录首先要通过row key来定位数据行。当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象【**即负载不均衡**】
- 热点的解决方案
- 预分区
- 预分区的目的让表的数据可以均衡的分散在集群中,而不是默认只有一个region分布在集群的一个节点上
- 加盐
- 这里所说的加盐不是密码学的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同
- 哈希
- 哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
- 反转
- 反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。如:15X,13X
<a name="RW2s9"></a>
## 6、HBase的二级索引
- HBase表按照rowkey查询性能是最高的。**rowkey就相当于hbase表的一级索引!!**
- 为了HBase的数据查询更高效、适应更多的场景,诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
- **hbase的二级索引其本质就是建立 hbase 表中****列****与****行键****(****rowkey)之间的映射关系**
- 常见的二级索引我们一般可以借助各种其他的方式来实现,例如 _Phoenix _或者 _solr _或者 _ES__ _等
<a name="07vy9"></a>
## 7、布隆过滤器在hbase的应用
**布隆过滤器应用**
- 之前在讲hbase的数据存储原理的时候,我们知道hbase的读操作需要访问大量的文件,**大部分的实现通过布隆过滤器来避免大量的读文件操作**
**<br />**布隆过滤器的原理**
- 通常判断某个元素是否存在用的可以选择 _hashmap_。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
- **Bloom Filter是一种空间效率很高的随机数据结构**,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合
- hbase 中布隆过滤器来过滤指定的rowkey是否在目标文件,避免扫描多个文件。使用布隆过滤器来判断
**注:布隆过滤器返回 true,在结果不一定正确,如果返回false,则说明确实不存在**<br />**
**原理示意图**<br />**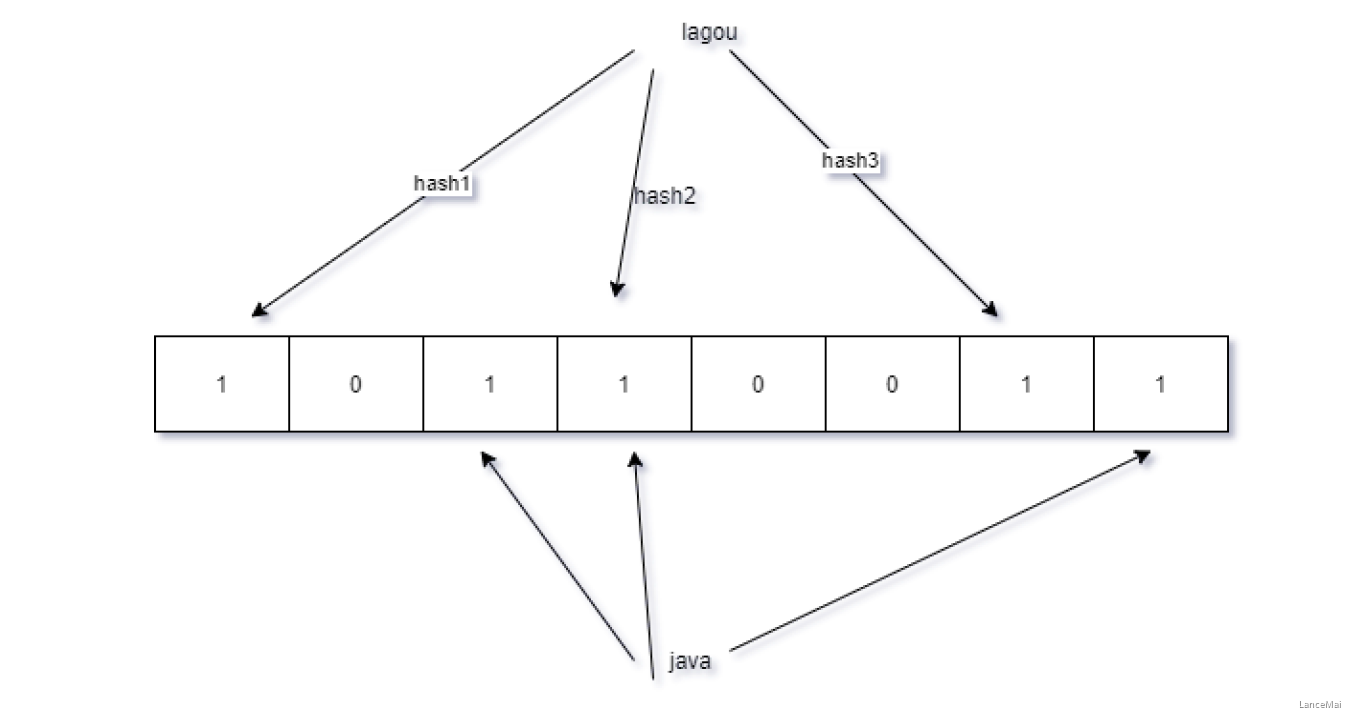**
**Bloom Filter案例**
- 布隆过滤器,已经不需要自己实现,_Google已经提供了非常成熟的实现_
- 添加依赖
```xml
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
使用guava 的布隆过滤器,封装的非常好,使用起来非常简洁方便。
如下例子: 预估数据量1w,错误率需要减小到万分之一。使用如下代码进行创建
public static void main(String[] args) { // 1.创建符合条件的布隆过滤器,预期数据量10000,错误率0.0001 BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel( Charset.forName("utf-8")),10000, 0.0001); // 2.将一部分数据添加进去 for (int i = 0; i < 5000; i++) { bloomFilter.put("" + i); } System.out.println("数据写入完毕"); // 3.测试结果 for (int i = 0; i < 10000; i++) { if (bloomFilter.mightContain("" + i)) { System.out.println(i + "存在"); } else { System.out.println(i + "不存在"); } } }

若有收获,就点个赞吧
0 人点赞
