一、Hive 概述
1. Hive 产生背景
- 直接使用 MapReduce 处理大数据,将面临以下问题:
- MapReduce 开发难度大,学习成本高 (学习wordCount程序 相当于学习java的 Hello World程序,而前者比后者复杂多了)
- Hdfs 文件没有字段名、没有数据类型,不方便进行数据的有效管理
- 使用 MapReduce 框架开发,项目周期长,成本高
- Hive 是基于 Hadoop 的一个数据仓库工具,可以将 结构化的数据文件 映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能;Hive是由 Facebook 开源,用于解决海量结构化日志的数据统计。
- Hive本质是:将 SQL 转换为 MapReduce 的任务进行运算
- 底层由 HDFS 来提供数据存储
- 可以将 Hive 理解为一个:将 SQL 转换为 MapReduce 任务的工具
数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,主要用于管理决策。(数据仓库之父比尔·恩门,1991年提出)。
RDBMS —> Relative Database Management System,关系型数据库,如Mysql,Oracle,SQL Server等。
- 由于 Hive 采用了类似SQL(Structured Query Language) 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和传统的关系数据库除了拥有类似的查询语言,再无类似之处,即 Hive 与 RDBMS 差别很大!!!
下面是 Hive 与 RDBMS 之间的异同之处
- 查询语言相似
- HQL <=> SQL 高度相似
- 由于 SQL 被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发
- 数据规模
- Hive 存储海量数据;RDBMS 只能处理有限的数据集
- 由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;而RDBMS可以支持的数据规模较小
- 执行引擎
- Hive的引擎是MR/Tez/Spark/Flink;RDBMS使用自己的执行引擎
- Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而RDBMS通常有自己的执行引擎(每种关系型数据库都有自己的引擎)
- 数据存储
- Hive保存在HDFS上;RDBMS保存在本地文件系统 或 裸设备
- 裸设备:也叫裸分区(原始分区),是一种没有经过格式化,不被Unix通过文件系统来读取的特殊字符设备。它由应用程序负责对它进行读写操作。不经过文件系统的缓冲。
- 裸设备的好处:因为使用裸设备避免了再经过Unix操作系统这一层,数据直接从Disk到Oracle进行传输,所以使用裸设备对于读写频繁的数据库应用来说,可以极大地提高数据库系统的性能。当然,这是以磁盘的 I/O 非常大,磁盘I/O已经称为系统瓶颈的情况下才成立。如果磁盘读写确实非常频繁,以至于磁盘读写成为系统瓶颈的情况成立,那么采用裸设备确实可以大大提高性能,最大甚至可以提高至40%,非常明显。 而且,由于使用的是原始分区,没有采用文件系统的管理方式,对于Unix维护文件系统的开销也都没有了,比如不用再维护I-node,空闲块等,这也能够导致性能的提高。
- Hive保存在HDFS上;RDBMS保存在本地文件系统 或 裸设备
- 执行速度
- Hive相对慢(与MR和数据量有关);RDBMS相对快(因为处理的数据量相对较小);
- Hive存储的数据量大,在查询数据的时候,通常没有索引,需要扫描整个表;加之Hive使用MapReduce作为执行引擎,这些因素都会导致较高的延迟。而RDBMS对数据的访问通常是基于索引的,执行延迟较低。当然这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出并行的优势。
- 可扩展性
- Hive支持水平扩展;通常RDBMS支持垂直扩展,对水平扩展不友好
- 关于水平扩展和垂直扩展:https://www.cnblogs.com/blfshiye/p/5059748.html
- Hive建立在Hadoop之上,其可扩展性与Hadoop的可扩展性是一致的(Hadoop集群规模可以轻松超过1000个节点)。而RDBMS由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右
- Hive支持水平扩展;通常RDBMS支持垂直扩展,对水平扩展不友好
- 数据更新
- 查询语言相似
优点
- 学习成本低
- Hive提供了类似SQL的查询语言,开发人员能快速上手;
- 处理海量数据
- 底层执行的是MapReduce 任务;
- 系统可以水平扩展
- 底层基于Hadoop;
- 功能可以扩展
- Hive允许用户自定义函数;
- 良好的容错性
- 某个节点发生故障,HQL仍然可以正常完成;
- 统一的元数据管理
- 元数据包括:有哪些表、表有什么字段、字段是什么类型
- 学习成本低
缺点
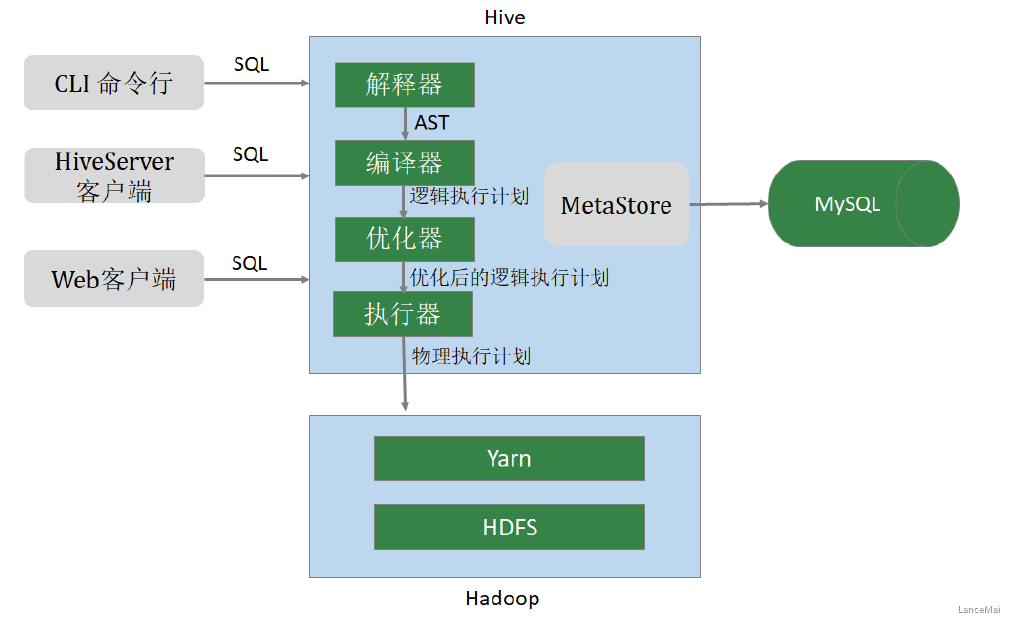
用户接口(CLI,Common Line Interface)
- Hive的命令行,用于接收HQL,并返回结果; JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似; WebUI:是指可通过浏览器访问Hive
- Thrift Server
- Hive可选组件,是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过 编程的方式远程访问Hive
- 元数据管理(MetaStore)
- Hive将元数据存储在关系数据库中(如mysql、derby)。Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数据所在位置等
- 驱动程序(Driver)
- 解析器 (SQLParser) :使用第三方工具(antlr,Another Tool for Language Recognition)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在;
- 编译器 (Compiler) :将抽象语法树编译生成逻辑执行计划;
- 优化器 (Optimizer) :对逻辑执行计划进行优化,减少不必要的列、使用分区等;
- 执行器 (Executer) :把逻辑执行计划转换成可以运行的物理计划;
二、Hive 安装与配置
1. Hive 安装配置
- Hive官网:http://hive.apache.org
- 下载网址:http://archive.apache.org/dist/hive/
- 文档网址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual
- 安装前提:3台虚拟机,安装了Hadoop
- 待安装软件:Hive(2.3.7) + MySQL (5.7.26)
- 注:Hive 的元数据默认存储在自带的 derby 数据库中,生产中多采用MySQL
- derby:java语言开发占用资源少,单进程,单用户。仅仅适用于个人的测试
安装计划(视个人而定)

安装步骤 ```
hive安装包
apache-hive-2.3.7-bin.tar.gz
MySQL安装包
mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar
MySQL的JDBC驱动程序
mysql-connector-java-5.1.46.jar
整体的安装步骤:
1、安装MySQL 2、安装配置Hive 3、Hive添加常用配置
<a name="U8sfB"></a>### 1.1 安装Mysql- Hive中使用MySQL存储元数据,MySQL的版本 5.7.26。安装步骤:- 1、环境准备(删除有冲突的依赖包、安装必须的依赖包)- 2、安装MySQL- 3、修改root密码(找到系统给定的随机密码、修改密码)- 4、在数据库中创建hive用户<a name="qZsKF"></a>#### ① 删除MariaDB及mysql旧版本- centos7.6自带的 MariaDB(MariaDB是MySQL的一个分支),与要安装的MySQL有冲突,需要删除。- 注:不一定有,但是有的话要删除
查询是否安装了mariadb
rpm -aq | grep mariadb
删除mariadb。其中-e:删除指定的套件,—nodeps:不验证套件的相互关联性
rpm -e —nodeps mariadb-libs
- 彻底删除 mysql 旧版本
- 具体参考:[https://www.jianshu.com/p/ef58fb333cd6](https://www.jianshu.com/p/ef58fb333cd6)
<a name="zFpXw"></a>
#### ② 安装依赖
- `yum install -y perl `
- `yum install -y net-tools`
<a name="eBKn8"></a>
#### ③ 安装mysql
- 解压缩
- `tar -xvf mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar`
- 依次运行以下安装命令
- `rpm -ivh mysql-community-common-5.7.26-1.el7.x86_64.rpm`
- `rpm -ivh mysql-community-libs-5.7.26-1.el7.x86_64.rpm`
- `rpm -ivh mysql-community-client-5.7.26-1.el7.x86_64.rpm`
- `rpm -ivh mysql-community-server-5.7.26-1.el7.x86_64.rpm`
<a name="A5ERu"></a>
#### ④ 启动数据库
- 启动
- `systemctl start mysqld`
- 查看启动状态
- `systemctl status mysqld`
<a name="80BbJ"></a>
#### ⑤ 查找root初始密码
- `grep password /var/log/mysqld.log`
- root 初始口令保存在 mysqld.log 文件中
<a name="x8NJo"></a>
#### ⑥ 修改root 密码
```sql
# 进入MySQL,使用前面查询到的口令
mysql -u root -p
(然后粘贴口令)
# 设置口令强度;
set global validate_password_policy=0;
# 将root口令设置为12345678;
set password for 'root'@'localhost' =password('12345678');
# 刷新
flush privileges;
- 备注:个人开发环境,出于方便的目的设比较简单的密码;生产环境一定要设复杂密码!
- validate_password_policy 指的是 密码策略(默认是1),可配置的值有以下:
授权(所有权限) GRANT ALL ON . TO ‘hive’@’%’;
刷新 FLUSH PRIVILEGES;
<a name="3EuZr"></a>
### 1.2 安装Hive
安装步骤:<br />1、下载、上传、解压缩<br />2、修改环境变量<br />3、修改hive配置<br />4、拷贝JDBC的驱动程序<br />5、初始化元数据库
<a name="z92tP"></a>
#### ① 下载Hive软件,并解压缩
```shell
# 解压
cd /opt/lagou/software
tar zxvf apache-hive-2.3.7-bin.tar.gz -C ../servers/
# 给目录改名,方便操作
cd ../servers
mv apache-hive-2.3.7-bin hive-2.3.7
② 修改环境变量
# 在 /etc/profile 文件中增加环境变量(目录为hive的安装目录)
export HIVE_HOME=/opt/lagou/servers/hive-2.3.7
export PATH=$PATH:$HIVE_HOME/bin
# 执行并生效
source /etc/profile
③ 修改 Hive 配置
在$HIVE_HOME/conf 目录中的hive-site.xml 配置文件中添加内容
cd $HIVE_HOME/conf vi hive-site.xml注:这个文件刚开始没有,上述命令会创建文件 ```xml <?xml version=”1.0” encoding=”UTF-8” standalone=”no”?> <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
javax.jdo.option.ConnectionURL jdbc:mysql://linux123:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName hive username to use against metastore database javax.jdo.option.ConnectionPassword 12345678 password to use against metastore database
- **注**:
- 注意 jdbc 的连接串,如果没有 useSSL=false 会有大量警告(useSSL=true 表示使用加密方式)
- 在 xml 文件中 **`&`** 表示 &
<a name="MZ7lF"></a>
#### ④ 拷贝 MySQL JDBC 驱动程序
- 将 `mysql-connector-java-5.1.46.jar` 拷贝到 `$HIVE_HOME/lib` 下
<a name="NtjS5"></a>
#### ⑤ 初始化元数据库
- [root@linux123 ~]$ `schematool -dbType mysql -initSchema`
- `schematool` 命令存在于 `$HIVE_HOME/bin` 中
<a name="NU8ee"></a>
#### ⑥ 启动Hive,执行命令
- **启动hive服务之前,请先启动 hdfs、yarn 的服务**(启动hdfs和yarn之后等安全模式时间过后再启动hive)
- [root@linux123 ~]$ hive
- hive> show databases;
- 注:**Hadoop 2.x 中 NameNode RPC(远程过程调用)缺省的端口号:****8020****,经常使用的端口号也有**** 9000**
- **对端口号要敏感**
<a name="c5Y7q"></a>
### 1.3 Hive 属性配置
- 可在 **`hive-site.xml`** 中增加以下常用配置,**方便使用**
**
<a name="EmkQw"></a>
#### 数据存储位置
```xml
<property>
<!-- 数据默认的存储位置(HDFS) -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
显示当前库
<property>
<!-- 在命令行中,显示当前操作的数据库 -->
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.
</description>
</property>
显示表头属性
<property>
<!-- 在命令行中,显示数据的表头 -->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
本地模式
<property>
<!-- 操作小规模数据时,使用本地模式,提高效率 -->
<name>hive.exec.mode.local.auto</name>
<value>true</value>
<description>Let Hive determine whether to run in local mode automatically</description>
</property>
注:当 Hive 的输入数据量非常小时,Hive 通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间会明显被缩短。当一个job满足如下条件才能真正使用本地模式,机器性能好的话以下参数可以适当提高
Hive 的 log文件 默认存放在
/tmp/root目录下(root为当前用户名),这个位置可以修改vi $HIVE_HOME/conf/hive-log4j2.properties- (此上文件原本不存在,但是 hive-log4j2.properties.template 模板文件存在,可以复制一份,并将其名字修改为 hive-log4j2.properties)
- 添加以下内容,指定log的存放位置:
property.hive.log.dir = /opt/lagou/servers/hive-2.3.7/logs
注:可以不修改 log文件的存放位置,但是要知道位置所在,因为以后查找错误经常需要用到
添加第三方用户(Hadoop)
- 建议:现阶段学习时 使用 root 用户,以免有些权限之类的错误发生
```sql
groupadd hadoop
-m:自动建立用户的home目录(登入目录)
-g:指定用户所属的起始群组
-G<群组>:指定用户所属的附加群组
-s:指定用户登入后所使用的shell
useradd -m hadoop -g hadoop -s /bin/bash
设置目录
passwd hadoop
<a name="Sxwny"></a>
### 1.4 参数配置方式
- 查看参数配置信息
- 查看全部参数
- hive> `set;`
- 查看某个参数
- hive> `set hive.exec.mode.local.auto;`
- 查询结果为:`hive.exec.mode.local.auto=false`
参数配置的三种方式:<br />1、用户自定义配置文件(`hive-site.xml`)<br />2、启动hive时指定参数(`-hiveconf`)<br />3、hive命令行指定参数(`set`)
<a name="lrZtb"></a>
#### 配置信息的优先级
- set > -hiveconf > hive-site.xml > **hive-default.xml(官方默认)**
<a name="UKJ0F"></a>
#### ① 配置文件方式
- 默认配置文件:`hive-default.xml`
- 用户自定义配置文件:`hive-site.xml`
- 配置优先级:`hive-site.xml > hive-default.xml`
- 配置文件的设定对**本机启动的所有 Hive 进程有效**
<a name="4ucrE"></a>
#### ② 启动时指定参数
- 启动Hive时,可以在命令行添加 -hiveconf param=value 来设定参数,这些设定**仅对本次启动有效**
- 启动时指定参数
- **`hive -hiveconf hive.exec.mode.local.auto=true`**
- 在命令行检查参数是否生效
- hive> `set hive.exec.mode.local.auto;`
- 查询结果:`hive.exec.mode.local.auto=true`
<a name="qe5OG"></a>
#### ③ 命令行修改参数
- 可在 Hive 命令行中使用 SET 关键字设定参数,同样**仅对本次启动有效**
- hive> `set hive.exec.mode.local.auto=false;`
- hive> `set hive.exec.mode.local.auto;`
- 查询结果:`hive.exec.mode.local.auto=false`
<a name="HnX7x"></a>
## 2. Hive 命令
<a name="McSYS"></a>
### ① hive
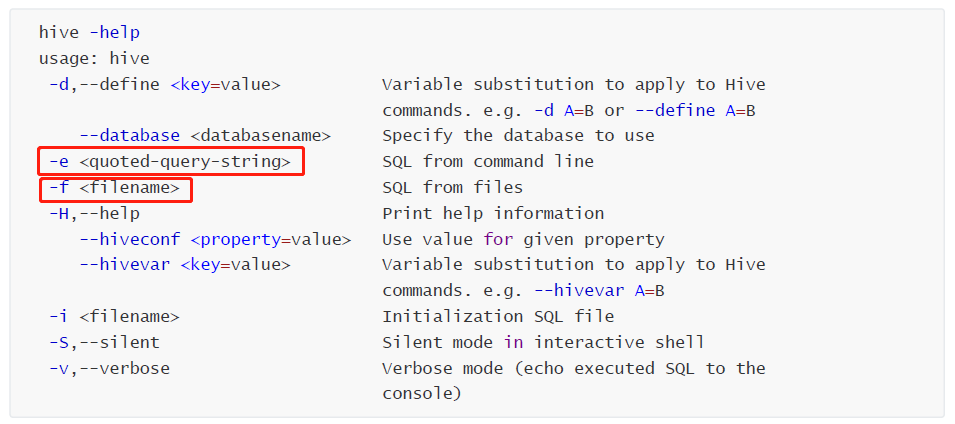
- **`-e`**:不进入hive交互窗口,直接在 操作系统命令行交互界面 执行 sql 语句
- `hive -e "select * from users"`
- **`-f`**:执行脚本中sql语句
- 创建文件 `hqlfile1.sql`,内容:`select * from users`
- 执行文件中的SQL语句
- `hive -f hqlfile1.sql`
- 执行文件中的SQL语句,将结果写入文件
- `hive -f hqlfile1.sql >> result1.log`
<a name="u2CRB"></a>
### ② 退出 Hive 命令行
- **`exit;`** 或者 **`quit;`**
<a name="hjF4u"></a>
### ③ 在hive命令行执行 shell 命令 / dfs 命令
- 目的是为了不用频繁地在 hive、shell、dfs 中切换
- 执行 shell 命令
- hive> `! ls;`
- hive> `! clear;`
- 执行 dfs 命令
- hive> `dfs -ls /;`
---
<a name="7uD6T"></a>
# 三、数据类型与文件格式
- Hive 支持关系型数据库的绝大多数** 基本数据类型**,同时也支持 **4种集合数据类型**
<a name="nYf4M"></a>
## 1. 基本数据类型及转换
- Hive类似和java语言中一样,会支持多种不同长度的整型和浮点类型数据,同时也支持布尔类型、字符串类型,时间戳数据类型以及二进制数组数据类型等。
- 详细信息见下表
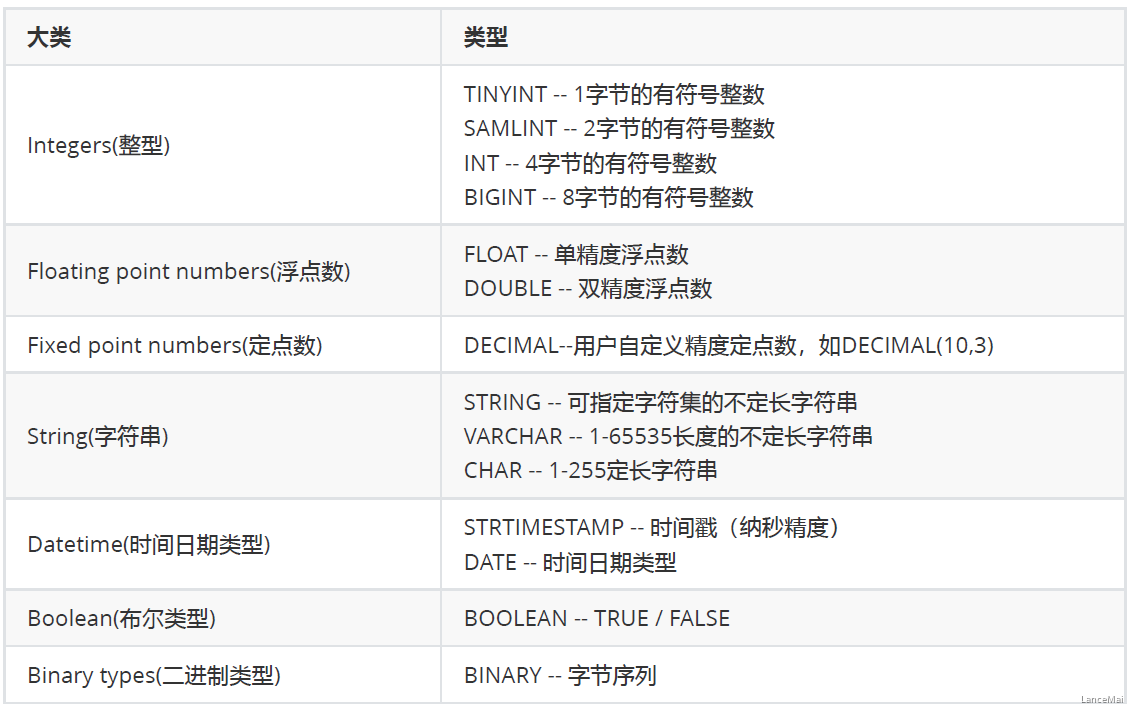
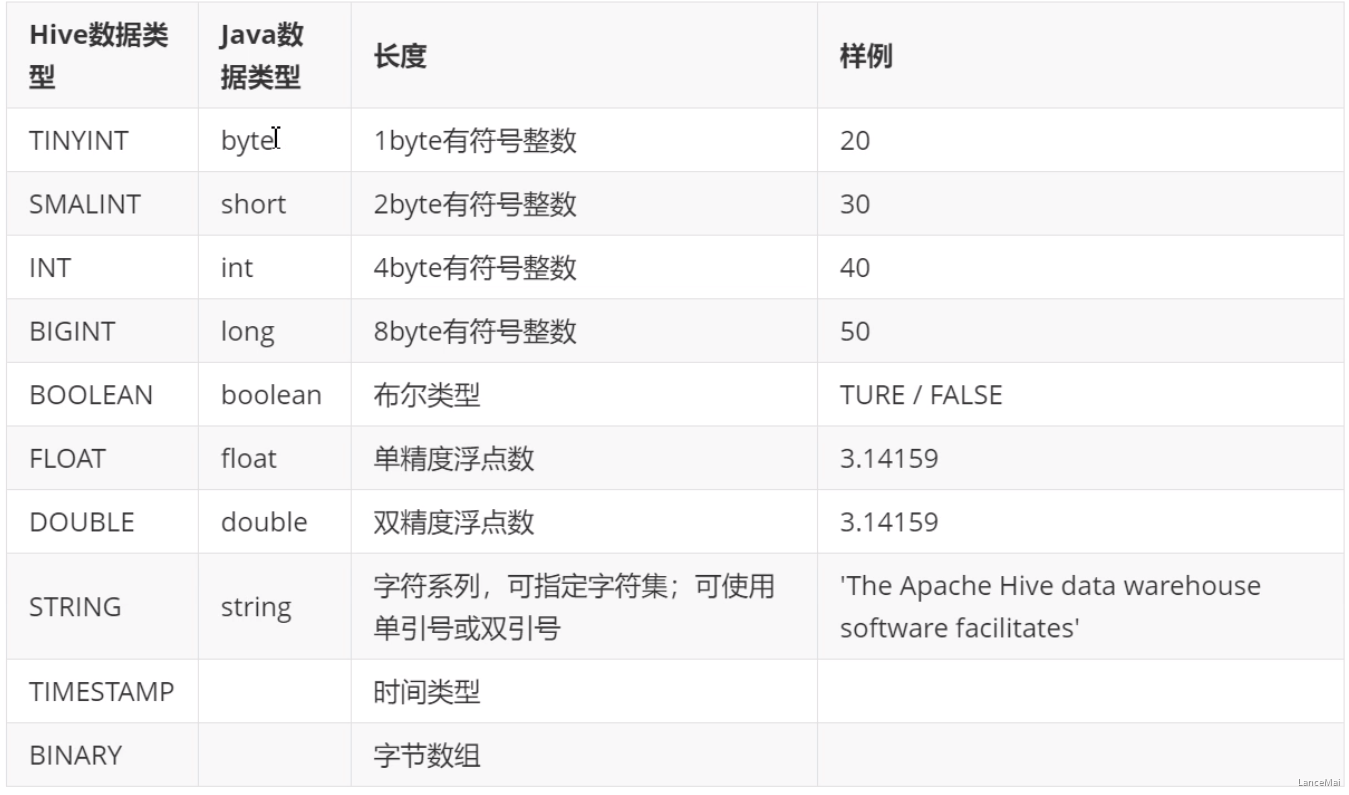
- 这些类型名称都是 Hive 中保留字。这些基本的数据类型都是 java 中的接口进行实现的,因此与 java 中数据类型是基本一致的:
<a name="fo5Nr"></a>
### 数据类型的隐式转换
- Hive 的数据类型是可以进行隐式转换的,类似于Java的类型转换。如用户在查询中将一种浮点类型和另一种浮点类型的值做对比,Hive会将类型转换成两个浮点类型中值较大的那个类型,即:将FLOAT类型转换成DOUBLE类型;当然如果需要的话,任意整型会转化成DOUBLE类型。
- Hive 中基本数据类型遵循以下层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换
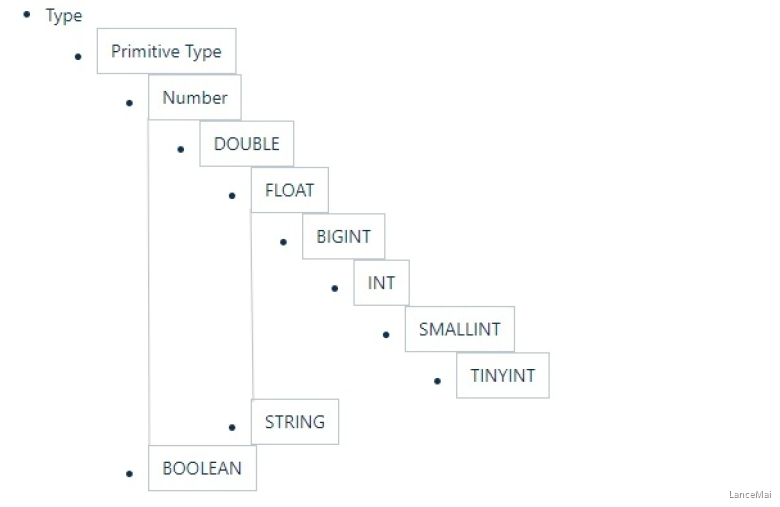
- 总的来说数据转换遵循以下 **规律**:
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成 INT, INT 可以转换成BIGINT;
- 所有整数类型、 FLOAT 和 STRING 类型(仅当STRING都是数字时)可以隐式转换为 DOUBLE;
- TINYINT、 SMALLINT、 INT 都可以转换为 FLOAT;
- BOOLEAN 类型不可以转换为任何其它的类型;
```sql
hive> select '1.0'+2;
OK
3.0
hive> select '1111' > 10;
hive> select 1 > 0.8;
数据类型的显示转换
- 使用 cast 函数进行强制类型转换;
如果强制类型转换失败,返回NULL
hive> select cast('1111s' as int); OK NULL hive> select cast('1111' as int); OK 11112. 集合数据类型
Hive支持集合数据类型,包括 array、map、struct、union
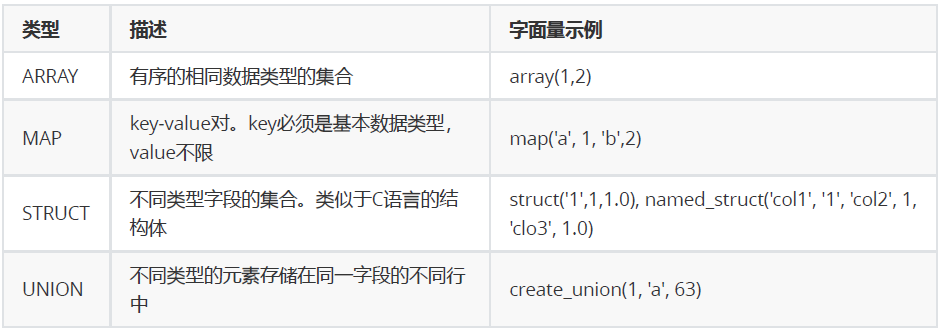
和基本数据类型一样,这些类型的名称同样是保留字
- ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似
- STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套 ```sql hive> select array(1,2,3); OK [1,2,3]
— 使用 [] 访问数组元素 hive> select arr[0] from (select array(1,2,3) arr) tmp; hive> select map(‘a’, 1, ‘b’, 2, ‘c’, 3); OK {“a”:1,”b”:2,”c”:3}
— 使用 [] 访问map元素 hive> select mymap[“a”] from (select map(‘a’, 1, ‘b’, 2, ‘c’, 3) as mymap) tmp;
— 使用 [] 访问map元素。 key不存在返回NULL hive> select mymap[“x”] from (select map(‘a’, 1, ‘b’, 2, ‘c’, 3) as mymap) tmp; NULL
— struct集合 hive> select struct(‘username1’, 7, 1288.68); OK {“col1”:”username1”,”col2”:7,”col3”:1288.68}
— 给 struct 中的字段命名 hive> select named_struct(“name”, “username1”, “id”, 7, “salary”, 12880.68); OK {“name”:”username1”,”id”:7,”salary”:12880.68}
— 使用 列名.字段名 访问具体信息 hive> select userinfo.id
> from (select named_struct("name", "username1", "id", 7, "salary", 12880.68) userinfo) tmp;
— union 数据类型 hive> select create_union(0, “zhansan”, 19, 8000.88) uinfo;
<a name="r4aHe"></a>
## 3. 文本文件数据编码
- Hive 表中的数据存储在文件系统上,Hive定义了默认的存储格式,也支持用户自定义文件存储格式
- Hive 默认使用几个**很少出现在字段值中的控制字符**,来表示替换默认分隔符的字符
<a name="sWAs6"></a>
### Hive 默认分隔符
```sql
id name age hobby(array) score(map)
字段之间:^A
元素之间: ^B
key-value之间:^C
666^Alisi^A18^Aread^Bgame^Ajava^C97^Bhadoop^C87
create table s1(
id int,
name string,
age int,
hobby array<string>,
score map<string, int>
);
load data local inpath '/home/hadoop/data/s1.dat' into table s1;
select * from s1;

- Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:
- 列分隔符(通常为空格、”\t”、”\x001”)
- 行分隔符(”\n”)
- 读取文件数据的方法
- 在加载数据的过程中,Hive 不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中
- 将 Hive 数据导出到本地时,系统默认的分隔符是^A、^B、^C 这些特殊字符,使用 cat 或者 vim 是看不到的;
- 在 vi 中输入特殊字符:
- (Ctrl + v) + (Ctrl + a) => ^A
- (Ctrl + v) + (Ctrl + b) => ^B
- (Ctrl + v) + (Ctrl + c) => ^C
^A/^B/^C都是特殊的控制字符,使用 more 、 cat 命令是看不见的;可以使用cat -A file.dat4. 读时模式
在传统数据库中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入数据库时对照表模式进行检查,这种模式称为“写时模式”(schema on write)
- 写时模式 -> 写数据检查 -> RDBMS
- Hive中数据加载过程采用“读时模式” (schema on read),加载数据时不进行数据格式的校验,读取数据时如果不合法则显示NULL。
- 读时模式 -> 读时检查数据 -> Hive
- 好处:加载数据速度快
- 缺点:有些数据会显示为NULL

若有收获,就点个赞吧
0 人点赞
