第五部分 继承
第 1 节 继承的概念
Scala中继承类的方式和Java一样,也是使用extends关键字:
class Employee extends Person{var salary=1000}
和Java一样,可在定义中给出子类需要而父类没有的字段和方法,或者重写父类的方法。 ```scala //Person类 class Person(name:String,age:Int) //Student继承Person类 class Student(name:String,age:Int,var studentNo:String) extends Person(name,age)
object Demo{ def main(args: Array[String]): Unit = { val student=new Student(“john”,18,”1024”) } }
- 上面继承部分的代码等效于下面的Java代码
```scala
//Person类
class Person{
private String name;
private int age;
public Person(String name,int age){
this.name=name; this.age=age;
}
}
//Student继承Person类
class Student extends Person{
private String studentNo;
public Student(string name,int age,String studentNo){
super(name,age);
this.sutdentNo=studentNo;
}
}
第 2 节 构造器执行顺序
- Scala在继承的时候构造器的执行顺序:首先执行父类的主构造器,其次执行子类自身的主构造器。
- 类有一个主构造器和任意数量的辅助构造器,而每个辅助构造器都必须以对先前定义的辅助构造器或主构造器的调用开始。
子类的辅助构造器最终都会调用主构造器。只有主构造器可以调用父类的构造器。
//Person类 class Person(name:String,age:Int){ println("这是父类Person") } //Student继承Person类 class Student(name:String,age:Int,studentNo:String) extends Person(name,age){ println("这是子类Student") } object Demo{ def main(args: Array[String]): Unit = { //下面的语句执行时会打印下列内容: //这是父类Person //这是子类Student //也就是说,构造Student对象之前,首先会调用Person的主构造器 val student=new Student("john",18,"1024") } }第 3 节 override方法重写
方法重写指的是当子类继承父类的时候,从父类继承过来的方法不能满足子类的需要,子类希望有自己的实现,这时需要对父类的方法进行重写,方法重写是实现多态的关键。
Scala中的方法重写同Java一样,也是利用override关键字标识重写父类的方法。
class Programmer(name:String,age:Int){ def coding():Unit=println("我在写代码...") } //ScalaProgrammer继承Programmer类 class ScalaProgrammer(name:String,age:Int,workNo:String) extends Programmer(name,age){ override def coding():Unit={ //调用父类的方法 super.coding() //增加了自己的实现 println("我在写Scala代码...") } } object ExtendsDemo { def main(args: Array[String]): Unit = { val scalaProgrammer=new ScalaProgrammer("张三",30,"1001") scalaProgrammer.coding() } } //代码运行输出内容: 我在写代码... 我在写Scala代码...需要强调一点:如果父类是抽象类,则override关键字可以不加。如果继承的父类是抽象类(假设抽象类为AbstractClass,子类为SubClass),在SubClass类中,AbstractClass对应的抽象方法如果没有实现的话,那SubClass也必须定义为抽象类,否则的话必须要有方法的实现。
第 4 节 类型检查与转换
要测试某个对象是否属于某个给定的类,可以用isInstanceOf方法。如果测试成功,可以用asInstanceOf方法进行类型转换。
if(p.isInstanceOf[Employee]){ //s的类型转换为Employee val s = p.asInstanceOf[Employee] }如果p指向的是Employee类及其子类的对象,则p.isInstanceOf[Employee]将会成功。
- 如果p是null,则p.isInstanceOf[Employee]将返回false,且p.asInstanceOf[Employee]将返回null。
- 如果p不是一个Employee,则p.asInstanceOf[Employee]将抛出异常。
- 如果想要测试p指向的是一个Employee对象但又不是其子类,可以用:
if(p.getClass == classOf[Employee])
- classOf方法定义在scala.Preder对象中,因此会被自动引入。
不过,与类型检查和转换相比,模式匹配通常是更好的选择。
p match{ //将s作为Employee处理 case s: Employee => ... //p不是Employee的情况 case _ => .... }第六部分 特质
第 1 节 作为接口使用的特质
Scala中的trait特质是一种特殊的概念。
- 首先可以将trait作为接口来使用,此时的trait就与Java中的接口非常类似。
- 在trait中可以定义抽象方法,与抽象类中的抽象方法一样,只要不给出方法的具体实现即可。
- 类可以使用extends关键字继承trait。
- 注意:在Scala中没有implement的概念,无论继承类还是trait特质,统一都是extends。
- 类继承trait特质后,必须实现其中的抽象方法,实现时 可以省略override关键字 。
Scala不支持对类进行多继承,但是 支持多重继承trait特质,使用with关键字即可 。
//定义一个trai特质 trait HelloTrait { def sayHello } //定义一个trai特质 trait MakeFriendTrait { def makeFriend } //继承多个trait,第一个trait使用extends关键字,其它trait使用with关键字 class Person(name: String) extends HelloTrait with MakeFriendsTrait with Serializable { override def sayHello() = println("Hello, My name is " + name) //override关键字也可以省略 def makeFriend() = println("Hello," + name) }第 2 节 带有具体实现的特质
具体方法
- Scala中的trait特质不仅仅可以定义抽象方法,还可以定义具体实现的方法,这时的trait更像是包含了通用工具方法的类。比如,trait中可以包含一些很多类都通用的功能方法,比如打印日志等等,Spark中就使用了trait来定义通用的日志打印方法。
具体字段
- Scala trait特质中的字段可以是抽象的,也可以是具体的。 ```scala trait People { //定义抽象字段 val name: String //定义了age字段 val age = 30
def eat(message: String): Unit = { println(message) } } trait Worker { //这个trait也定义了age字段 val age = 25
def work: Unit = { println(“Working……”) } } // Student类继承了Worker、Person这两个特质,需要使用extends、with这两个关键字 class Student extends Worker with People{ //重写抽象字段,override可以省略 override val name: String = “张三” //继承的两个trait中都有age字段,此时需要重写age字段,override不能省略 override val age = 20 } object TraitDemoTwo { def main(args: Array[String]): Unit = { val stu = new Student stu.eat(“吃饭”) stu.work println(s”Name is ${stu.name}, Age is ${stu.age}”) } } ```
注意: 特质Person和Worker中都有age字段,当Student继承这两个特质时,需要重写age字段,并且要用override关键字,否则就会报错。
第 3 节 特质构造顺序
在Scala中,trait特质也是有构造器的,也就是trait中的不包含在任何方法中的代码。
- 构造器以如下顺序执行:
- 执行父类的构造器;
- 执行trait的构造器,多个trait从左到右依次执行;
- 构造trait时会先构造父trait,如果多个trait继承同一个父trait,则父trait只会构造一次;
- 所有trait构造完毕之后,子类的构造器才执行 ```scala class Person2 { println(“Person’s constructor!”) }
trait Logger { println(“Logger’s constructor!”) }
trait MyLogger extends Logger { println(“MyLogger’s constructor!”) }
trait TimeLogger extends Logger { println(“TimeLogger’s constructor!”) }
//类既继承了类又继承了特质,要先写父类 class Student2 extends Person2 with MyLogger with TimeLogger { println(“Student’s constructor!”) }
- 上面代码的输出结果:
```scala
Person's constructor!
Logger's constructor!
MyLogger's constructor!
TimeLogger's constructor!
Student's constructor!
第 4 节 特质继承类
在Scala中,trait特质也可以继承class类,此时这个class类就会成为所有继承此trait的类的父类。
class MyUtil { def printMessage(msg: String) = println(msg) } // 特质Log继承MyUtil类 trait Log extends MyUtil { def log(msg: String) = printMessage(msg) } // Person3类继承Log特质,Log特质继承MyUtil类,所以MyUtil类成为Person3的父类 class Person3(name: String) extends Log { def sayHello { log("Hello, " + name) printMessage("Hi, " + name) } }第 5 节 Ordered和Ordering
在Java中对象的比较有两个接口,分别是Comparable和Comparator。它们之间的区别在于:
- 实现Comparable接口的类,重写compareTo()方法后,其对象自身就具有了可比较性;
- 实现Comparator接口的类,重写了compare()方法后,则提供一个第三方比较器,用于比较两个对象。
- 在Scala中也引入了以上两种比较方法(Scala.math包下):
- Ordered特质混入Java的Comparable接口,它定义了相同类型间的比较方式,但这种内部比较方式是单一的;
trait Ordered[A] extends Any with java.lang.Comparable[A]{......}- Ordering特质混入Comparator接口,它是提供第三方比较器,可以自定义多种比较方式,在实际开发中也是使用比较多的,灵活解耦合。
trait Ordering[T] extends Comparator[T] with PartialOrdering[T] with Serializable {......}
使用Ordered特质进行排序操作
case class Project(tag:String, score:Int) extends Ordered[Project] { def compare(pro:Project ) = tag.compareTo(pro.tag) } object OrderedDemo { def main(args: Array[String]): Unit = { val list=List(Project("hadoop",60),Project("flink",90),Project("hive",70),Project("spark",80)) println(list.sorted) } }使用Ordering特质进行排序操作
object OrderingDemo { def main(args: Array[String]): Unit = { val pairs = Array(("a", 7, 2), ("c", 9, 1), ("b", 8, 3)) // Ordering.by[(Int,Int,Double),Int](_._2)表示从Tuple3转到Int型 // 并按此Tuple3中第二个元素进行排序 Sorting.quickSort(pairs)(Ordering.by[(String, Int, Int), Int](_._2)) println(pairs.toBuffer) } }第七部分 模式匹配和样例类
第 1 节 模式匹配
Scala没有Java中的switch case,它有一个更加强大的模式匹配机制,可以应用到很多场合。
- Scala的模式匹配可以匹配各种情况,比如变量的类型、集合的元素、有值或无值。
- 模式匹配的基本语法结构: 变量 match { case 值 => 代码 }
- 模式匹配match case中,只要有一个case分支满足并处理了,就不会继续判断下一个case分支了,不需要使用break语句。这点与Java不同,Java的switch case需要用break阻止。如果值为下划线,则代表不满足以上所有情况的时候如何处理。
- 模式匹配match case最基本的应用,就是对变量的值进行模式匹配。match是表达式,与if表达式一样,是有返回值的。
除此之外,Scala还提供了样例类,对模式匹配进行了优化,可以快速进行匹配。
第 2 节 字符和字符串匹配
def main(args: Array[String]): Unit = { val charStr = '6' charStr match { case '+' => println("匹配上了加号") case '-' => println("匹配上了减号") case '*' => println("匹配上了乘号") case '/' => println("匹配上了除号") //注意:不满足以上所有情况,就执行下面的代码 case _ => println("都没有匹配上,我是默认值") } } def main(args: Array[String]): Unit = { val arr = Array("hadoop", "zookeeper", "spark") val name = arr(Random.nextInt(arr.length)) name match { case "hadoop" => println("大数据分布式存储和计算框架...") case "zookeeper" => println("大数据分布式协调服务框架...") case "spark" => println("大数据分布式内存计算框架...") case _ => println("我不认识你...") } }第 3 节 守卫式匹配
// 所谓守卫就是添加if语句 object MatchDemo { def main(args: Array[String]): Unit = { //守卫式 val character = '*' val num = character match { case '+' => 1 case '-' => 2 case _ if character.equals('*') => 3 case _ => 4 } println(character + " " + num) } }第 4 节 匹配类型
Scala的模式匹配还有一个强大的功能,它可以直接匹配类型,而不是值。这一点是Java的switch case做不到的。
匹配类型的语法: case 变量 : 类型 => 代码 ,而不是匹配值的“case 值 => 代码”这种语法。
def main(args: Array[String]): Unit = { val a = 3 val obj = if(a == 1) 1 else if(a == 2) "2" else if(a == 3) BigInt(3) else if(a == 4) Map("aa" -> 1) else if(a == 5) Map(1 -> "aa") else if(a == 6) Array(1, 2, 3) else if(a == 7) Array("aa", 1) else if(a == 8) Array("aa") val r1 = obj match { case x: Int => x case s: String => s.toInt // case BigInt => -1 //不能这么匹配 case _: BigInt => Int.MaxValue case m: Map[String, Int] => "Map[String, Int]类型的Map集合" case m: Map[_, _] => "Map集合" case a: Array[Int] => "It's an Array[Int]" case a: Array[String] => "It's an Array[String]" case a: Array[_] => "It's an array of something other than Int" case _ => 0 } println(r1 + ", " + r1.getClass.getName) }第 5 节 匹配数组、元组、集合
def main(args: Array[String]): Unit = { val arr = Array(0, 3, 5) //对Array数组进行模式匹配,分别匹配: //带有指定个数元素的数组、带有指定元素的数组、以某元素开头的数组 arr match { case Array(0, x, y) => println(x + " " + y) case Array(0) => println("only 0") //匹配数组以1开始作为第一个元素 case Array(1, _*) => println("1 ...") case _ => println("something else") } val list = List(3, -1) //对List列表进行模式匹配,与Array类似,但是需要使用List特有的::操作符 //构造List列表的两个基本单位是Nil和::,Nil表示为一个空列表 //tail返回一个除了第一元素之外的其他元素的列表 //分别匹配:带有指定个数元素的列表、带有指定元素的列表、以某元素开头的列表 list match { case x :: y :: Nil => println(s"x: $x y: $y") case 0 :: Nil => println("only 0") case 1 :: tail => println("1 ...") case _ => println("something else") } val tuple = (1, 3, 7) tuple match { case (1, x, y) => println(s"1, $x , $y") case (_, z, 5) => println(z) case _ => println("else") } }第 6 节 样例类
case class样例类是Scala中特殊的类。当声明样例类时,以下事情会自动发生:
- 主构造函数接收的参数通常不需要显式使用var或val修饰,Scala会自动使用val修饰
- 自动为样例类定义了伴生对象,并提供apply方法,不用new关键字就能够构造出相应的对象
- 将生成toString、equals、hashCode和copy方法,除非显示的给出这些方法的定义
- 继承了Product和Serializable这两个特质,也就是说样例类可序列化和可应用Product的方法
- case class是多例的,后面要跟构造参数,case object是单例的。
- 此外,case class样例类中可以添加方法和字段,并且可用于模式匹配。 ```scala class Amount
//定义样例类Dollar,继承Amount父类 case class Dollar(value: Double) extends Amount
//定义样例类Currency,继承Amount父类 case class Currency(value: Double, unit: String) extends Amount
//定义样例对象Nothing,继承Amount父类 case object Nothing extends Amount
object CaseClassDemo { def main(args: Array[String]): Unit = { judgeIdentity(Dollar(10.0)) judgeIdentity(Currency(20.2,”100”)) judgeIdentity(Nothing) } //自定义方法,模式匹配判断amt类型 def judgeIdentity(amt: Amount): Unit = { amt match { case Dollar(value) => println(s”$value”) case Currency(value, unit) => println(s”Oh noes,I got $unit”) case Nothing => println(“Oh,GOD!”) } } }
<a name="f9c77973"></a>
## 第 7 节 Option与模式匹配
- Scala Option选项类型用来表示一个值是可选的,有值或无值。
- Option[T] 是一个类型为 T 的可选值的容器,可以通过get()函数获取Option的值。如果值存在,Option[T] 就是一个 Some。如果不存在,Option[T] 就是对象 None 。
- Option通常与模式匹配结合使用,用于判断某个变量是有值还是无值。
```scala
object OptionMatch {
val grades = Map("jacky" -> 90, "tom" -> 80, "jarry" -> 95)
def getGrade(name: String): Unit = {
val grade = grades.get(name)
grade match {
case Some(grade) => println("成绩:" + grade)
case None => println("没有此人成绩!")
}
}
def main(args: Array[String]): Unit = {
getGrade("jacky")
getGrade("张三")
}
}
第八部分 函数及抽象化
第 1 节 函数字面量及函数的定义
- Scala中函数为头等公民,不仅可以定义一个函数然后调用它,还可以写一个未命名的函数字面量,然后可以把它当成一个值传递到其它函数或是赋值给其它变量。
- 函数字面量体现了函数式编程的核心理念。字面量包括整数字面量、浮点数字面量、布尔型字面量、字符字面量、字符串字面量、符号字面量、函数字面量等。什么是函数字面量呢?
- 在函数式编程中,函数是“头等公民”,可以像任何其他数据类型一样被传递和操作。函数的使用方式和其他数据类型的使用方式完全一致,可以像定义变量那样去定义一个函数,函数也会和其他变量一样,有类型有值;
- 就像变量的“类型”和“值”是分开的两个概念一样,函数的“类型”和“值”也成为两个分开的概念;
- 函数的“值”,就是“函数字面量”。 ```scala scala> def add1(x: Int): Int = { x + 1 } add1: (x: Int)Int // 函数的类型为: (Int) => Int // 输入参数列表只有一个括号,可以简写为: Int => Int
scala> def add2(x: Int, y: Int): Int = { x + y } add2: (x: Int, y: Int)Int // 函数的类型为: (Int, Int) => Int
scala> def add3(x: Int, y: Int, z: Int): Int = { x + y + z } add3: (x: Int, y: Int, z: Int)Int // 函数的类型为: (Int, Int, Int) => Int
scala> def add4(x: Int, y: Int, z: Int): (Int, Int) = { (x + y, y + z) } add4: (x: Int, y: Int, z: Int)(Int, Int) // 函数的类型为: (Int, Int, Int) => (Int, Int)
- 函数类型:(输入参数类型列表) => (输出参数类型列表)
- 只有一个参数时,小括号可省略;函数体中只有 1 行语句时,大括号可以省略;
- 把函数定义中的类型声明部分去除,剩下的就是函数的“值”,即函数字面量:
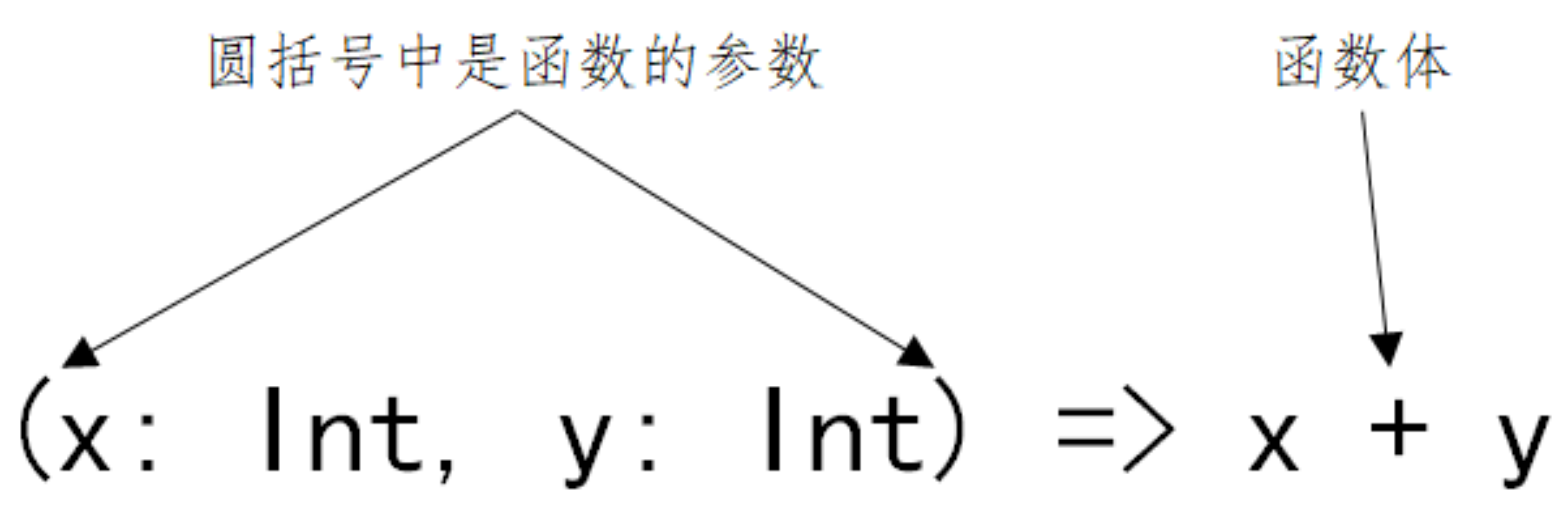
- 对 add1 而言函数的值为:(x) => x+1
- 对 add2 而言函数的值为:(x, y) => x+y
- 对 add3 而言函数的值为:(x, y, z) => x+y+z
- 对 add4 而言函数的值为:(x, y, z) => (x+y, y+z)
- 在Scala中我们这样定义变量:`val 变量名: 类型 = 值;`
- 我们可以用完全相同的方式定义函数:`val 函数名: 函数类型 = 函数字面量`
```scala
val add1: Int => Int = (x) => x+1
val add2: (Int, Int) => Int = (x, y) => x + y
val add3: (Int, Int, Int) => Int = (x, y, z) => x + y + z
val add4: (Int, Int, Int) => (Int, Int) = (x, y, z) => (x + y, y + z)
- 在Scala中有自动类型推断,所以可以省略变量的类型
val 变量名 = 值。 同样函数也可以这样:
val 函数名 = 函数字面量val add1 = (x: Int) => x + 1 val add2 = (x: Int, y: Int) => x + y val add3 = (x: Int, y: Int, z: Int) => x + y + z val add4 = (x: Int, y: Int, z: Int) => (x + y, y + z)备注:要让编译器进行自动类型推断,要告诉编译器足够的信息,所以添加了 x 的类型信息。
第 2 节 函数与方法的区别
scala> def addm(x: Int, y: Int): Int = x + y addm: (x: Int, y: Int)Int scala> val addf = (x: Int, y: Int) => x + y addf: (Int, Int) => Int = <function2>严格的说:使用 val 定义的是函数(function),使用 def 定义的是方法(method)。二者在语义上的区别很小,在绝大多数情况下都可以不去理会它们之间的区别,但是有时候有必要了解它们之间的不同。
- Scala中的方法与函数有以下区别:
- Scala 中的方法与 Java 的类似,方法是组成类的一部分
- Scala 中的函数则是一个完整的对象。Scala 中用 22 个特质(从 Function1 到 Function22)抽象出了函数的概念
- Scala 中用 val 语句定义函数,def 语句定义方法
- 方法不能作为单独的表达式而存在,而函数可以;
- 函数必须要有参数列表,而方法可以没有参数列表;
- 方法名是方法调用,而函数名只是代表函数对象本身;
- 在需要函数的地方,如果传递一个方法,会自动把方法转换为函数
```scala
// 方法不能作为单独的表达式而存在,而函数可以
scala> def addm(x: Int, y: Int): Int = x + y
addm: (x: Int, y: Int)Int
scala> val addf = (x: Int, y: Int) => x + y
addf: (Int, Int) => Int =
scala> addm
// 函数必须要有参数列表,而方法可以没有参数列表
scala> def m1 = “This is lagou edu”
m1: String
// 函数必须有参数列表
scala> val f1 = () => “This is lagou edu”
f1: () => String =
// 方法名是方法调用
scala> m1
res16: String = This is lagou edu
// 函数名代表函数对象
scala> f1
res17: () => String =
// 需要函数的地方,可以传递一个方法 scala> val list = (1 to 10).toList lst: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> def double(x: Int) = x*x double: (x: Int)Int
scala> list.map(double(_)) res20: List[Int] = List(1, 4, 9, 16, 25, 36, 49, 64, 81, 100)
- 将方法转换为函数:
```scala
scala> def f1 = double _ //注意:方法名与下划线之间有一个空格
f1: Int => Int
scala> f1
res21: Int => Int = <function1>
写程序的时候是定义方法、还是定义函数?
函数没有名字就是匿名函数;
- 匿名函数,又被称为 Lambda 表达式。 Lambda表达式的形式如下:
- (参数名1: 类型1, 参数名2: 类型2, … …) => 函数体
```scala
// 定义匿名函数
scala> (x: Int) => x + 1
res0: Int => Int =
// 函数没有名字,在集成开发环境中是无法被调用的 scala> res0(10) res1: Int = 11
scala> val list = (1 to 10).toList lst: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
// 将匿名函数作为参数传递给另一个函数 scala> list.map((x: Int) => x + 1) res2: List[Int] = List(2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
// x一定是Int类型,这里可以省略 scala> list.map((x) => x + 1) res3: List[Int] = List(2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
// 只有一个参数,小括号可以省略 scala> list.map(x => x + 1) res4: List[Int] = List(2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
// 使用占位符简化函数字面量 scala> list.map(_ + 1) res5: List[Int] = List(2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
// 实现将List中的每个元素*2 + 1,但是出错了
scala> list.map( + + 1)
// 这样是可行的 scala> list.map(2 * + 1) // 通过reduce这个高阶函数,将list列表中的元素相加求和 scala> list.reduce((x,y) => x + y) res0: Int = 55 // 使用占位符简化函数字面量 // 第一个下划线代表第一个参数,第二个下划线代表第二个参数 scala> list.reduce( + _) res1: Int = 55
- 多个下划线指代多个参数,而不是单个参数的重复运用
- 第一个下划线代表第一个参数
- 第二个下划线代表第二个参数
- 第三个......,如此类推
<a name="4859baeb"></a>
## 第 4 节 高阶函数
- 高阶函数:接收一个或多个函数作为输入 或 输出一个函数。
- 函数的参数可以是变量,而函数又可以赋值给变量,由于函数和变量地位一样,所以函数参数也可以是函数;
- 常用的高阶函数:map、reduce、flatMap、foreach、filter、count ... ... (接收函数作为参数)
```scala
object HighFunction {
def main(args: Array[String]): Unit = {
//定义一个函数
val func = (n) => "*" * n
//接收函数作为输入
(1 to 5).map(func(_)).foreach(println)
//输出一个函数
val urlBuilder= (ssl: Boolean, domainName: String) => {
val schema = if (ssl) "https://" else "http://"
//返回一个匿名函数
(endPoint: String, query: String) => s"$schema$domainName/$endPoint? $query"
}
val domainName = "www.lagou.com"
def getURL: (String, String) => String = urlBuilder(true, domainName)
val endPoint: String = "show"
val query: String = "id=1"
val url: String = getURL(endPoint, query)
println(url)
}
}
第 5 节 闭包
- 闭包是一种函数,一种比较特殊的函数,它和普通的函数有很大区别: ```scala // 普通的函数 val addMore1 = (x: Int) => x + 10
// 外部变量,也称为自由变量 var more = 10
// 闭包 val addMore2 = (x: Int) => x + more // 调用addMore1函数 println(addMore1(5)) // 每次addMore2函数被调用时,都会去捕获外部的自由变量 println(addMore2(10)) more = 100 println(addMore2(10)) more = 1000 println(addMore2(10))
- 闭包是在其上下文中引用了自由变量的函数;
- 闭包引用到函数外面定义的变量,定义这个函数的过程就是将这个自由变量捕获而构成的一个封闭的函数,也可理解为"把函数外部的一个自由变量关闭进来"。
- 何为闭包?需满足下面三个条件:
- 闭包是一个函数
- 函数必须要有返回值
- 返回值依赖声明在函数外部的一个或多个变量,用Java的话说,就是返回值和定义的全局变量有关
<a name="63adf3bb"></a>
## 第 6 节 柯里化
- 函数编程中, 接收多个参数的函数都可以转化为接收单个参数的函数 ,这个转化过程就叫柯里化(Currying)。
- Scala中,柯里化函数的定义形式和普通函数类似,区别在于柯里化函数拥有多组参数列表,每组参数用小括号括起来。
- Scala API中很多函数都是柯里化的形式。
```scala
// 使用普通的方式
def add1(x: Int, y: Int) = x + y
// 使用闭包的方式,将其中一个函数作为返回值
def add2(x: Int) = (y:Int) => x + y
// 使用柯里化的方式
def add(x: Int)(y: Int) = x + y
//调用柯里化函数add
scala> add(1)(2)
res1: Int = 3
//add(1)(2)实际上第一次调用使用参数x,返回一个函数类型的值,第二次使用参数y调用这个函数类型的值。
//实际上最先演变成这样的函数:def add(x: Int) = (y:Int) => x + y
//在这个函数中,接收一个x为参数,返回一个匿名函数,这个匿名函数的定义是:接收一个Int型参数y,函数体是x+y。
//调用过程如下:
scala> val result=add(1)
result: Int => Int = <function1>
scala> val sum=result(2)
sum: Int = 3
scala> sum
res0: Int = 3
第 7 节 部分应用函数
- 部分应用函数(Partial Applied Function)也叫偏应用函数,与偏函数从名称上看非常接近,但二者之间却有天壤之别。
- 部分应用函数是指缺少部分(甚至全部)参数的函数。
如果一个函数有n个参数, 而为其提供少于n个参数, 那就得到了一个部分应用函数。
// 定义一个函数 def add(x:Int, y:Int, z:Int) = x+y+z // Int不能省略 def addX = add(1, _:Int, _:Int) addX(2,3) addX(3,4) def addXAndY = add(10, 100, _:Int) addXAndY(1) def addZ = add(_:Int, _:Int, 10) addZ(1,2) // 省略了全部的参数,下面两个等价。第二个更常用 def add1 = add(_: Int, _: Int, _: Int) def add2 = add _第 8 节 偏函数
偏函数(Partial Function)之所以“偏”,原因在于它们并不处理所有可能的输入,而只处理那些能与至少一个 case 语句匹配的输入;
- 在偏函数中只能使用 case 语句 ,整个函数必须用 大括号 包围。这与普通的函数字面量不同,普通的函数字面量可以使用大括号,也可以用小括号;
- 被包裹在 大括号 中的一组case语句是一个偏函数,是一个并非对所有输入值都有定义的函数;
Scala中的Partial Function是一个trait,其类型为PartialFunction[A,B],表示:接收一个类型为A的参数,返回一个类型为B的结果。
// 1、2、3有对应的输出值,其它输入打印 Other val pf: PartialFunction[Int, String] = { case 1 => "One" case 2 => "Two" case 3 => "Three" case _=> "Other" } pf(1) // 返回: One pf(2) // 返回: Two pf(5) // 返回: Other需求:过滤List中的String类型的元素,并将Int类型的元素加 1 。
- 通过偏函数实现上述需求。 ```scala package cn.lagou.edu.scala.section3
object PartialFunctionDemo1 { def main(args: Array[String]): Unit = { // PartialFunction[Any, Int]: 偏函数接收的数据类型是Any,返回类型为Int val partialFun = new PartialFunction[Any, Int] { // 如果返回true,就调用 apply 构建实例对象;如果返回false,过滤String数据 override def isDefinedAt(x: Any): Boolean = { println(s”x = $x”) x.isInstanceOf[Int] } // apply构造器,对传入值+1,并返回 override def apply(v1: Any): Int = { println(s”v1 = $v1”) v1.asInstanceOf[Int] + 1 } } val lst = List(10, “hadoop”, 20, “hive”, 30, “flume”, 40, “sqoop”) // 过滤字符串,对整型+1 // collect通过执行一个并行计算(偏函数),得到一个新的数组对象 lst.collect(partialFun).foreach(println) // 实际不用上面那么麻烦 lst.collect{case x: Int => x+1}.foreach(println) } } ```

若有收获,就点个赞吧
0 人点赞
