七、函数
1. 系统内置函数
(官方文档)Hive内置函数:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inFunctions
查看系统函数
查看系统自带函数
show functions;
- 显示自带函数的用法(以upper函数为例)
— 时间戳转日期 select from_unixtime(1505456567); select from_unixtime(1505456567, ‘yyyyMMdd’); select from_unixtime(1505456567, ‘yyyy/MM/dd’); select from_unixtime(1505456567, ‘yyyy-MM-dd HH:mm:ss’); — 日期转时间戳 select unix_timestamp(‘2019-09-15 14:23:00’);
— 计算时间差 select datediff(‘2020-04-18’,’2019-11-21’); select datediff(‘2019-11-21’, ‘2020-04-18’); #结果为负数,可以加上abs()求得绝对值
— 查询当月第几天 select dayofmonth(current_date); — 计算月末: select last_day(current_date); — 当月第1天:(date_sub是日期相减的函数) select date_sub(current_date, dayofmonth(current_date)-1) — 下个月第1天:(add_months(date, n)表示在日期date基础上加上n月) select add_months(date_sub(current_date, dayofmonth(current_date)-1), 1)
— 字符串转时间(字符串必须为:yyyy-MM-dd格式) select to_date(‘2020-01-01’); select to_date(‘2020-01-01 12:12:12’);
— 日期、时间戳、字符串类型格式化输出标准时间格式 select date_format(current_timestamp(), ‘yyyy-MM-dd HH:mm:ss’); select date_format(current_date(), ‘yyyyMMdd’); select date_format(‘2020-06-01’, ‘yyyy-MM-dd HH:mm:ss’);
— 计算emp表中,每个人的工龄( round(a,n)表示小数a保留n位小数 ) select *, round(datediff(current_date, hiredate)/365,1) workingyears from emp;
<a name="Xzpbw"></a>### 字符串函数```sql-- 转小写。lowerselect lower("HELLO WORLD");-- 转大写。upperselect upper(ename), ename from emp;-- 求字符串长度。lengthselect length(ename), ename from emp;-- 字符串拼接。 concat 或 ||select empno || " " ||ename idname from emp;select concat(empno, " " ,ename) idname from emp;-- 拼接字符串,同时指定分隔符。concat_ws(separator, [string | array(string)]+)SELECT concat_ws('.', 'www', array('lagou', 'com'));select concat_ws(" ", ename, job) from emp;-- 求子串。substr(编号从1开始)SELECT substr('www.lagou.com', 5);SELECT substr('www.lagou.com', -5); # 表示后五个字符SELECT substr('www.lagou.com', 5, 5); # 表示从第五个字符开始,取五个字符-- 字符串切分。split,注意 '.' 要转义(因为 . 是正则表达式,表示任何字符都可以)select split("www.lagou.com", "\\.");
数学函数
- 数学函数太多了,此处仅为简要介绍 ```sql — 四舍五入。round select round(314.15926); select round(314.15926, 2); select round(314.15926, -2);
— 向上取整。ceil select ceil(3.1415926);
— 向下取整。floor select floor(3.1415926);
— 其他数学函数包括:绝对值、平方、开方、对数运算、三角运算等,需要用到时再查询官方文档
<a name="clcvj"></a>
### 条件函数【重点】
- 条件函数主要有:`if`、`case when`、`coalesce`、`nvl`、`isnull/isnotnull`、`nullif`
- 注意:条件函数相当于select语句返回的一个列,因此要与其他查询字段用逗号“`,`”分隔开
- if 和 case when 可以实现相同的功能,生产环境中 case when 更常用
- nvl 和 coalesce 可以实现相同的功能,不过 coalesce 可以针对多个参数进行操作,使用范围更广
```sql
-- if (boolean testCondition, T valueTrue, T valueFalseOrNull)
# 如果sal<=1500,则返回1,否则如果sal<=3000,返回2,其余的返回3
# 注意嵌套
select sal, if (sal<=1500, 1, if (sal <= 3000, 2, 3)) from emp;
-- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
-- 复杂条件用 case when 更直观
select sal, case when sal<=1500 then 1
when sal<=3000 then 2
else 3 end sallevel
from emp;
-- 以下语句等价(条件判断只涉及 = 的时候,不适用于 <、>、<=、>= 之类的判断)
select ename, deptno,
case deptno when 10 then 'accounting'
when 20 then 'research'
when 30 then 'sales'
else 'unknown' end deptname
from emp;
select ename, deptno,
case when deptno=10 then 'accounting'
when deptno=20 then 'research'
when deptno=30 then 'sales'
else 'unknown' end deptname
from emp;
-- (T v1, T v2, ...)。返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
select sal, coalesce(comm, 0) from emp;
-- nvl(T value, T default_value) -> 若value为空,则返回default_value,否则返回value
select empno, ename, job, mgr, hiredate, deptno, sal + nvl(comm,0) sumsal
from emp;
-- isnull(a) isnotnull(a)
select * from emp where isnull(comm); -- 等价于 select * from emp where comm is null;
select * from emp where isnotnull(comm); -- 等价于 select * from emp where comm is not null;
-- nullif(x, y) 相等返回null,否则返回x
SELECT nullif("b", "b"), nullif("b", "a");
UDTF 函数【重点、难点】
- UDTF : User Defined Table-Generating Functions。用户定义表生成函数,一行输入,多行输出。
- 注:
- 一行输入一行输出的函数:字符串函数 等等
- 多行输入一行输出的函数:聚合函数 等等,如 collect_set / collect_list ```sql — explode,炸裂函数 — 就是将一行中复杂的 array 或者 map 结构拆分成多行 select explode(array(‘A’,’B’,’C’)) as col; select explode(map(‘a’, 8, ‘b’, 88, ‘c’, 888));
— UDTF’s are not supported outside the SELECT clause, nor nested in expressions — SELECT pageid, explode(adid_list) AS myCol… is not supported — SELECT explode(explode(adid_list)) AS myCol… is not supported — lateral view 常与 表生成函数explode结合使用
— lateral view 语法: lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (‘,’ columnAlias) fromClause: FROM baseTable (lateralView)
— lateral view 的基本使用 with t1 as ( select ‘OK’ cola, split(‘www.lagou.com’, ‘\.’) colb ) select cola, colc from t1 lateral view explode(colb) t2 as colc;
<a name="tXK55"></a>
#### 案例一
```sql
-- 数据(uid tags):
1 1,2,3
2 2,3
3 1,2
--编写sql,实现如下结果:
1 1
1 2
1 3
2 2
2 3
3 1
3 2
-- 建表加载数据
create table market(
uid int,
tags string
)
row format delimited fields terminated by '\t';
load data local inpath '/hivedata/market.txt' into table market;
-- SQL
select uid, tag
from market
lateral view explode(split(tags, ",")) t2 as tag;
案例二
-- 数据准备
lisi|Chinese:90,Math:80,English:70
wangwu|Chinese:88,Math:90,English:96
maliu|Chinese:99,Math:65,English:60
-- 创建表
create table studscore(
name string,
score map<string,string>
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':';
-- 加载数据
load data local inpath '/home/hadoop/data/score.dat' overwrite into table studscore;
-- 需求:找到每个学员的最好成绩(两种办法)
-- 办法一:
select name, max(mark) max_mark
from (select name, course, mark
from stuscore lateral view explode(score) t1 as course, mark) t2
group by name;
-- 办法二(推荐):
with t1 as (select name, course, mark
from stuscore lateral view explode(score) t1 as course, mark)
select name, max(mark) max_mark
from t1
group by name;
2. 窗口函数【重点、难点】
- 窗口函数又名开窗函数,属于分析函数的一种。用于解决复杂报表统计需求的功能强大的函数,很多场景都需要用到。窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:窗口函数对于每个组返回多行,而聚合函数对于每个组只返回一行
窗口函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化
以下是用于窗口函数演示的例子
-- emp表的数据 empno ename job mgr hiredate sal comm deptno NULL CLERK 7902 NULL NULL NULL 20 NULL 7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30 7521 WARD SALESMAN 7698 2011-02-22 1250 500 30 7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20 7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30 7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30 7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10 7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20 7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10 7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30 7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20 7900 JAMES CLERK 7698 2011-12-03 950 NULL 30 7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20 7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10over 关键字
使用窗口函数前一般要通过
over()进行开窗- 注:窗口函数是针对每一行数据的,如果
over()中没有参数,默认的是全部结果集 ```sql — 查询emp表工资总和 select sum(sal) from emp;
— 不使用窗口函数,有语法错误:Line 1:7 Expression not in GROUP BY key ‘ename’ select ename, sal, sum(sal) salsum from emp;
— 使用窗口函数,查询员工姓名、薪水、薪水总和 select ename, sal, sum(sal) over() sal_sum, concat(round(sal / sum(sal) over()*100, 1),’%’) ratio_sal from emp;
— 以下是结果 ename sal sal_sum ratio_sal MILLER 1300 28225 4.6% FORD 3000 28225 10.6% JAMES 950 28225 3.4% ADAMS 1100 28225 3.9% TURNER 1500 28225 5.3% KING 5000 28225 17.7% SCOTT 3000 28225 10.6% CLARK 2450 28225 8.7% BLAKE 2850 28225 10.1% MARTIN 1250 28225 4.4% JONES 2975 28225 10.5% WARD 1250 28225 4.4% ALLEN 1600 28225 5.7% CLERK NULL 28225 NULL
<a name="UtJ5W"></a>
### partition by 子句
- 在 over 窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
```sql
-- 查询员工姓名、薪水、部门薪水总和
select ename, sal, sum(sal) over(partition by deptno) sal_sum
from emp;
order by 子句
- order by子句对输入的数据进行排序 ```sql — 增加了order by子句;sum:从分组的第一行到当前行求和 select ename, sal, deptno, sum(sal) over(partition by deptno order by sal) sal_sum from emp;
— 结果展示 ename sal deptno sal_sum CLERK NULL NULL NULL MILLER 1300 10 1300 CLARK 2450 10 3750 KING 5000 10 8750 ADAMS 1100 20 1100 JONES 2975 20 4075 SCOTT 3000 20 10075 FORD 3000 20 10075 JAMES 950 30 950 MARTIN 1250 30 3450 WARD 1250 30 3450 TURNER 1500 30 4950 ALLEN 1600 30 6550 BLAKE 2850 30 9400
<a name="nZx8l"></a>
### window 子句
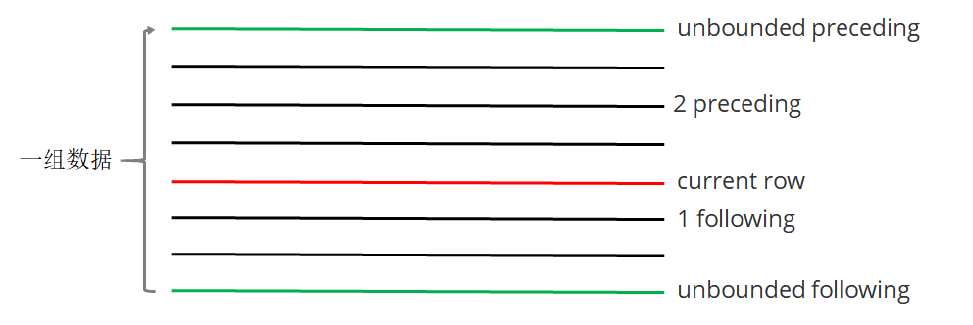
- `rows between ... and ...`
- 如果要对窗口的结果进行更细粒度的划分,使用window子句,有以下几个选项:
- `unbounded preceding`---组内第一行数据
- `n preceding`--------------组内当前行的前 n 行数据
- `current row`--------------当前行数据
- `n following`--------------组内当前行的后 n 行数据
- `unbounded following`---组内最后一行数据
```sql
-- rows between ... and ... 子句
-- 以下两个语句等价。组内,第一行到当前行的和
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename) sal_sum
from emp;
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and current row) sal_sum
from emp;
-- 结果展示
ename sal deptno sal_sum
CLERK NULL NULL NULL
CLARK 2450 10 2450
KING 5000 10 7450
MILLER 1300 10 8750
ADAMS 1100 20 1100
FORD 3000 20 4100
JONES 2975 20 7075
SCOTT 3000 20 10075
ALLEN 1600 30 1600
BLAKE 2850 30 4450
JAMES 950 30 5400
MARTIN 1250 30 6650
TURNER 1500 30 8150
WARD 1250 30 9400
---------------------------------------------
-- 组内,第一行到最后一行的和
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between unbounded preceding and unbounded following) sal_sum
from emp;
-- 结果展示
ename sal deptno sal_sum
CLERK NULL NULL NULL
CLARK 2450 10 8750
KING 5000 10 8750
MILLER 1300 10 8750
ADAMS 1100 20 10075
FORD 3000 20 10075
JONES 2975 20 10075
SCOTT 3000 20 10075
ALLEN 1600 30 9400
BLAKE 2850 30 9400
JAMES 950 30 9400
MARTIN 1250 30 9400
TURNER 1500 30 9400
WARD 1250 30 9400
---------------------------------------------
-- 组内,前一行 + 当前行 +后一行
select ename, sal, deptno,
sum(sal) over(partition by deptno order by ename
rows between 1 preceding and 1 following) sal_sum
from emp;
-- 结果展示
ename sal deptno sal_sum
CLERK NULL NULL NULL
CLARK 2450 10 7450
KING 5000 10 8750
MILLER 1300 10 6300
ADAMS 1100 20 4100
FORD 3000 20 7075
JONES 2975 20 8975
SCOTT 3000 20 5975
ALLEN 1600 30 4450
BLAKE 2850 30 5400
JAMES 950 30 5050
MARTIN 1250 30 3700
TURNER 1500 30 4000
WARD 1250 30 2750
排名函数
都是从1开始,生成数据项在分组中的排名
row_number()———排名顺序增加不会重复;如1、2、3、4、… …rank()———————排名相等会在名次中留下空位;如1、2、2、4、5、… …dense_rank()———排名相等会在名次中不会留下空位 ;如1、2、2、3、4、… …**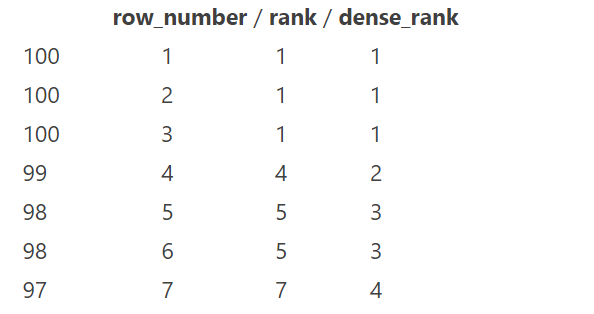 ```sql
— 数据准备
class1 s01 100
class1 s03 100
class1 s05 100
class1 s07 99
class1 s09 98
class1 s02 98
class1 s04 97
class2 s21 100
class2 s24 99
class2 s27 99
class2 s22 98
class2 s25 98
class2 s28 97
class2 s26 96
```sql
— 数据准备
class1 s01 100
class1 s03 100
class1 s05 100
class1 s07 99
class1 s09 98
class1 s02 98
class1 s04 97
class2 s21 100
class2 s24 99
class2 s27 99
class2 s22 98
class2 s25 98
class2 s28 97
class2 s26 96
— 创建表加载数据 create table t2( cname string, sname string, score int ) row format delimited fields terminated by ‘\t’;
load data local inpath ‘/home/hadoop/data/t2.dat’ into table t2;
— 按照班级,使用3种方式对成绩进行排名 select cname, sname, score, row_number() over (partition by cname order by score desc) rank1, rank() over (partition by cname order by score desc) rank2, dense_rank() over (partition by cname order by score desc) rank3 from t2;
— 求每个班级前3名的学员—前3名的定义是什么—假设使用dense_rank select cname, sname, score, rank from (select cname, sname, score, dense_rank() over(partition by cname order by score desc) rank from t2) tmp where rank <= 3;
<a name="9etTV"></a>
### 序列函数
- `lag`---------------返回当前数据行的上一行数据
- `lead`--------------返回当前数据行的下一行数据
- `first_value`----取分组内排序后,截止到当前行,第一个值
- `last_value`-----分组内排序后,截止到当前行,最后一个值
- `ntile`------------将分组的数据按照顺序切分成 n片,返回当前切片值
```sql
-- 测试数据 userpv.dat
-- cid ctime pv
cookie1,2019-04-10,1
cookie1,2019-04-11,5
cookie1,2019-04-12,7
cookie1,2019-04-13,3
cookie1,2019-04-14,2
cookie1,2019-04-15,4
cookie1,2019-04-16,4
cookie2,2019-04-10,2
cookie2,2019-04-11,3
cookie2,2019-04-12,5
cookie2,2019-04-13,6
cookie2,2019-04-14,3
cookie2,2019-04-15,9
cookie2,2019-04-16,7
-- 建表语句并加载数据
create table userpv(
cid string,
ctime date,
pv int
)
row format delimited fields terminated by ",";
Load data local inpath '/home/hadoop/data/userpv.dat' into table userpv;
-----------------------------------------------------
-- lag。 返回当前数据行的上一行数据
-- lead。返回当前数据行的下一行数据
select cid, ctime, pv,
lag(pv) over(partition by cid order by ctime) lagpv,
lead(pv) over(partition by cid order by ctime) leadpv
from userpv;
-- 结果展示
cid ctime pv lagpv leadpv
cookie1 2019-04-10 1 NULL 5
cookie1 2019-04-11 5 1 7
cookie1 2019-04-12 7 5 3
cookie1 2019-04-13 3 7 2
cookie1 2019-04-14 2 3 4
cookie1 2019-04-15 4 2 4
cookie1 2019-04-16 4 4 NULL
cookie2 2019-04-10 2 NULL 3
cookie2 2019-04-11 3 2 5
cookie2 2019-04-12 5 3 6
cookie2 2019-04-13 6 5 3
cookie2 2019-04-14 3 6 9
cookie2 2019-04-15 9 3 7
cookie2 2019-04-16 7 9 NULL
-----------------------------------------------------
-- first_value。分组内排序后,截止到当前行,第一个值 (即组内第一个值)
-- last_value。 分组内排序后,截止到当前行,最后一个值(即组内最后一个值)
select cid, ctime, pv,
first_value(pv) over(partition by cid order by ctime rows
between unbounded preceding and unbounded following) firstpv,
last_value(pv) over(partition by cid order by ctime rows
between unbounded preceding and unbounded following) lastpv
from userpv;
-- 结果展示
cid ctime pv firstpv lastpv
cookie1 2019-04-10 1 1 4
cookie1 2019-04-11 5 1 4
cookie1 2019-04-12 7 1 4
cookie1 2019-04-13 3 1 4
cookie1 2019-04-14 2 1 4
cookie1 2019-04-15 4 1 4
cookie1 2019-04-16 4 1 4
cookie2 2019-04-10 2 2 7
cookie2 2019-04-11 3 2 7
cookie2 2019-04-12 5 2 7
cookie2 2019-04-13 6 2 7
cookie2 2019-04-14 3 2 7
cookie2 2019-04-15 9 2 7
cookie2 2019-04-16 7 2 7
-----------------------------------------------------
-- ntile。按照cid进行分组,每组数据分成2份
select cid, ctime, pv,
ntile(2) over(partition by cid order by ctime) as ntile
from userpv;
-- 结果展示
cid ctime pv ntile
cookie1 2019-04-10 1 1
cookie1 2019-04-11 5 1
cookie1 2019-04-12 7 1
cookie1 2019-04-13 3 1
cookie1 2019-04-14 2 2
cookie1 2019-04-15 4 2
cookie1 2019-04-16 4 2
cookie2 2019-04-10 2 1
cookie2 2019-04-11 3 1
cookie2 2019-04-12 5 1
cookie2 2019-04-13 6 1
cookie2 2019-04-14 3 2
cookie2 2019-04-15 9 2
cookie2 2019-04-16 7 2
== 函数面试题 ==
① 连续值问题
- 连续七天登录的用户
- 用到的函数
row_number()over()date_sub()```sql — 数据。uid dt status(1 正常登录,0 异常) 1 2019-07-11 1 1 2019-07-12 1 1 2019-07-13 1 1 2019-07-14 1 1 2019-07-15 1 1 2019-07-16 1 1 2019-07-17 1 1 2019-07-18 1 2 2019-07-11 1 2 2019-07-12 1 2 2019-07-13 0 2 2019-07-14 1 2 2019-07-15 1 2 2019-07-16 0 2 2019-07-17 1 2 2019-07-18 0 3 2019-07-11 1 3 2019-07-12 1 3 2019-07-13 1 3 2019-07-14 0 3 2019-07-15 1 3 2019-07-16 1 3 2019-07-17 1 3 2019-07-18 1
— 建表语句 create table ulogin( uid int, dt date, status int ) row format delimited fields terminated by ‘ ‘;
— 加载数据 load data local inpath ‘/home/hadoop/data/ulogin.dat’ into table ulogin;
— 连续值的求解,面试中常见的问题。这也是同一类,基本都可按照以下思路进行 — 1、使用 row_number 在组内给数据编号(rownum) — 2、某个值 - rownum = gid,得到结果可以作为后面分组计算的依据 select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) gid from ulogin where status=1;
— 3、根据求得的gid,作为分组条件,求最终结果 select uid, count(*) countlogin from (select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) gid from ulogin where status=1) t1 group by uid, gid having countlogin >= 7;
<a name="VpgDL"></a>
#### ② TopN 问题
- 实现每个班前三名,分数一样并列,同时求出前三名按名次排序的分差
- 用到的函数
- `dense_rank()`
- `over()`
- `lag()`
- `nvl()`
```sql
-- 数据。sid class score
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87
-- 待求结果数据如下:
class score rank lagscore
1901 90 1 0
1901 90 1 0
1901 83 2 -7
1901 60 3 -23
1902 99 1 0
1902 87 2 -12
1902 67 3 -20
-- 建表语句
create table stu(
sno int,
class string,
score int
)
row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/home/hadoop/data/stu.dat' into table stu;
-- 求解思路:
-- 1、上排名函数,分数一样并列,所以用dense_rank
-- 2、将上一行数据下移(lag函数),相减即得到分数差
-- 3、处理 NULL
with tmp as (
select sno, class, score,
dense_rank() over (partition by class order by score desc) as rank
from stu
)
select class, score, rank,
nvl(score - lag(score) over (partition by class order by score desc), 0)
lagscore
from tmp
where rank<=3;
③ 行和列互相转化问题
(1)案例一
- 用到的函数
case when ... then ...sum()```sql — 数据:id course 1 java 1 hadoop 1 hive 1 hbase 2 java 2 hive 2 spark 2 flink 3 java 3 hadoop 3 hive 3 kafka
— 建表并加载数据 create table rowline1( id string, course string ) row format delimited fields terminated by ‘ ‘;
load data local inpath ‘/root/data/data1.dat’ into table rowline1;
— 编写sql,得到结果如下(1表示选修,0表示未选修) id java hadoop hive hbase spark flink kafka 1 1 1 1 1 0 0 0 2 1 0 1 0 1 1 0 3 1 1 1 0 0 0 1
— 使用 case when;group by + sum select id, sum(case when course=”java” then 1 else 0 end) as java, sum(case when course=”hadoop” then 1 else 0 end) as hadoop, sum(case when course=”hive” then 1 else 0 end) as hive, sum(case when course=”hbase” then 1 else 0 end) as hbase, sum(case when course=”spark” then 1 else 0 end) as spark, sum(case when course=”flink” then 1 else 0 end) as flink, sum(case when course=”kafka” then 1 else 0 end) as kafka from rowline1 group by id;
(2)案例二
- 用到的函数
- `collect_set()` / `collect_list()`
- `concat_ws()`
```sql
-- 数据。id1 id2 flag
a b 2
a b 1
a b 3
c d 6
c d 8
c d 8
-- 编写sql实现如下结果
id1 id2 flag
a b 2|1|3
c d 6|8
-- 创建表 & 加载数据
create table rowline2(
id1 string,
id2 string,
flag int
)
row format delimited fields terminated by ' ';
load data local inpath '/root/data/data2.dat' into table rowline2;
-- 第一步 将元素聚拢(题目要求去重,因此选用collect_set)
select id1, id2, collect_set(flag) flag from rowline2 group by id1, id2; # 去重
select id1, id2, collect_list(flag) flag from rowline2 group by id1, id2; # 不去重
select id1, id2, sort_array(collect_set(flag)) flag from rowline2 group by id1, id2;
-- 第二步 将元素连接在一起
select id1, id2, concat_ws("|", collect_set(flag)) flag
from rowline2
group by id1, id2;
-- 这里报错,CONCAT_WS must be "string or array<string>"。加一个类型转换即可
select id1, id2, concat_ws("|", collect_set(cast (flag as string))) flag
from rowline2
group by id1, id2;
3. 自定义函数
- 当 Hive 提供的内置函数无法满足实际的业务处理需要时,可以考虑使用用户自定义函数进行扩展。
用户自定义函数分为以下三类
- UDF(User Defined Function)
- 用户自定义函数,一进一出
- UDAF(User Defined Aggregation Function)
- 用户自定义聚集函数,多进一出,类似于 count、max等
- UDTF(User Defined Table-Generating Functions)
- 用户自定义表生成函数,一进多出,类似于explode
- UDF(User Defined Function)
UDF 开发
- 继承
org.apache.hadoop.hive.ql.exec.UDF - 需要实现 evaluate 函数;evaluate 函数支持重载
- UDF必须要有返回类型,可以返回null,但是返回类型不能为void
- 继承
UDF开发步骤
- 创建maven java 工程,添加依赖
- 开发java类继承UDF,实现evaluate 方法
- 将项目打包上传服务器
- 添加开发的jar包
- 设置函数与自定义函数关联
- 使用自定义函数
- 需求:扩展系统 nvl 函数功能
nvl(ename, "OK"): ename==null => (系统函数nvl)返回第二个参数nvl(ename, "OK"): ename==null or ename==”” or ename==” “ => (自定义函数nvl)返回第二个参数开发步骤
1、创建maven java 工程,添加pom依赖
2、开发java类继承UDF,实现evaluate 方法 ```java package com.lagou.hive.udf;<!-- pom.xml 文件 --> <dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>2.3.7</version> </dependency> </dependencies>
import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text;
public class Nvl extends UDF {
public Text evaluate(final Text x, final Text y) {
if (x == null || x.toString().trim().length() == 0) {
return y;
}
return x;
}
}
3、将项目打包上传服务器
- **注:使用 jdk11 可能会引起编译错误,最好使用 jdk1.8 版本**
4、添加开发的 jar 包至hive中(在Hive命令行中)
- `add jar /home/hadoop/data/hiveudf.jar;`
5、创建**临时**函数。指定类名一定要**完整的路径**,即包名加类名
- `create temporary function mynvl as "com.lagou.hive.udf.Nvl";`
6、执行查询
```sql
-- 基本功能还能实现
select mynvl(comm, 0) from mydb.emp;
-- 测试扩充的功能
select mynvl("", "OK");
select mynvl(" ", "OK");
-- 测试正常
7、退出Hive命令行,再进入Hive命令行。执行步骤6的测试,发现函数失效。
- 原因:以上创建的是临时函数,退出hive后会消失,需要使用以下语句重新创建
add jar /home/hadoop/data/hiveudf.jar;create ``temporary`` function mynvl as 'com.lagou.hive.udf.Nvl';
创建永久函数
- 将 jar 上传到 hdfs 中
hdfs dfs -put /home/hadoop/data/hiveudf.jar /user/hive/data/jar/
- 在 hive命令行中创建永久函数
create function mynvl as 'com.lagou.hive.udf.Nvl' using jar 'hdfs:/user/hive/data/jar/hiveudf.jar';
- 查询函数
- 使用
show functions;查看所有函数,发现存在函数 mynvl,而且前面有test1的前缀,即数据库.函数名的形式:test1.mynvl - 退出hive 后重新进入hive,发现该函数还在,如果在其他数据库中使用该函数,需要使用:test1.mynvl 才能访问
- 使用
- 删除自定义永久函数
drop function mynvl;
八、HQL操作之DML命令
- 数据操纵语言DML(Data Manipulation Language),DML主要有三种形式:
- 插入(INSERT)
- 删除(DELETE)
- 更新(UPDATE)
事务(transaction)是一组单元化操作,这些操作要么都执行,要么都不执行,是一个不可分割的工作单元。
- 四个要素:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),这四个基本要素通常称为ACID特性。
Hive从 0.14 版本开始支持 事务 和 行级更新,但缺省是不支持的,需要一些附加的配置。要想支持行级insert、update、delete,需要配置Hive支持事务
Hive事务的限制
Hive提供行级别的ACID语义
- BEGIN、COMMIT、ROLLBACK 暂时不支持,所有操作自动提交
- 目前只支持 ORC 的文件格式
- 默认事务是关闭的,需要设置开启
- 要是使用事务特性,表必须是分桶的(且分桶字段不能修改)
- 只能使用内部表
- 如果一个表用于ACID写入(INSERT、UPDATE、DELETE),必须在表中设置表属性 : “transactional=true”
- 必须使用事务管理器
**org.apache.hadoop.hive.ql.lockmgr.DbTxnManager** - 目前支持快照级别的隔离。就是当一次数据查询时,会提供一个数据一致性的快照
- LOAD DATA语句目前在事务表中暂时不支持
**
HDFS是不支持文件的修改;并且当有数据追加到文件,HDFS不对读数据的用户提供一致性的。为了在HDFS上支持数据的更新
- 表和分区的数据都被存在**基本文件**中(base files)
- 新的记录和更新,删除都存在**增量文件**中(delta files)
- 一个事务操作创建一系列的增量文件
- 在读取的时候,将基础文件和修改,删除合并,最后返回给查询
2. 操作示例
```sql — 这些参数也可以设置在hive-site.xml中 SET hive.support.concurrency = true; SET hive.enforce.bucketing = true; #— Hive 0.x and 1.x only SET hive.exec.dynamic.partition.mode = nonstrict; SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
— 创建表用于更新。满足条件:内部表、ORC格式、分桶、设置表属性 create table zxz_data( name string, nid int, phone string, ntime date ) clustered by(nid) into 5 buckets stored as orc tblproperties(‘transactional’=’true’);
— 创建临时表,用于向分桶表插入数据 create table temp1( name string, nid int, phone string, ntime date ) row format delimited fields terminated by “,”;
— 数据 name1,1,010-83596208,2020-01-01 name2,2,027-63277201,2020-01-02 name3,3,010-83596208,2020-01-03 name4,4,010-83596208,2020-01-04 name5,5,010-83596208,2020-01-05
— 向临时表加载数据;向事务表中加载数据(分桶表不支持直接使用 load data 导入数据) load data local inpath ‘/home/hadoop/data/zxz_data.txt’ overwrite into table temp1; insert into table zxz_data select * from temp1;
— 检查数据和文件 select * from zxz_data; dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
— DML 操作 delete from zxz_data where nid = 3; dfs -ls /user/hive/warehouse/mydb.db/zxz_data ; insert into zxz_data values (“name3”, 3, “010-83596208”, current_date); — 不支持 insert into zxz_data values (“name3”, 3, “010-83596208”, “2020-06-01”); — 执行 insert into zxz_data select “name3”, 3, “010-83596208”, current_date; dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
insert into zxz_data values (“name6”, 6, “010-83596208”, “2020-06-02”), (“name7”, 7, “010-83596208”, “2020-06-03”), (“name8”, 9, “010-83596208”, “2020-06-05”), (“name9”, 8, “010-83596208”, “2020-06-06”);
dfs -ls /user/hive/warehouse/mydb.db/zxz_data ;
update zxz_data set name=concat(name, “00”) where nid>3;
dfs -ls /user/hive/warehouse/mydb.db/zxz_data;
— 分桶字段不能修改,下面的语句不能执行 — Updating values of bucketing columns is not supported update zxz_data set nid = nid + 1; ```
小结
- Hive 支持 行事务(允许对数据进行修改),但是条件严格,不建议在生产环境中使用

若有收获,就点个赞吧
0 人点赞
