- 软件和操作系统
- JDK版本:JDK8版本及以上
Hadoop 搭建方式
三台虚拟机
- 静态IP
- 关闭防火墙
- 修改主机名
- 配置免密登录
- 集群时间同步
- 在
/opt目录下创建文件夹mkdir -p /opt/software—> 软件安装包存放目录mkdir -p /opt/servers—> 软件安装目录
- Hadoop下载地址
- 上传 Hadoop安装文件到
/opt/software目录中2 集群规划
| 框架 | linux121 | linux122 | linux123 | | :—-: | :—-: | :—-: | :—-: | | HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode | | YARN | NodeManager | NodeManager | ResourceManager、NodeManager |
3 安装 Hadoop
- 登录linux121节点,进入
/opt/software,解压安装文件到/opt/serverstar -zxvf hadoop-2.9.2.tar.gz -C /opt/servers
- 查看是否解压成功
ll /opt/servers/hadoop-2.9.2
添加 hadoop 环境变量
vim /etc/profile- 在
/etc/profile文件中添加以下内容# HADOOP_HOMEexport HADOOP_HOME=/opt/servers/hadoop-2.9.2export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
使环境变量生效
source /etc/profile
- 验证 hadoop
hadoop version

目录介绍
drwxr-xr-x. 2 root root 194 Nov 13 2018 bindrwxr-xr-x. 3 root root 20 Nov 13 2018 etcdrwxr-xr-x. 2 root root 106 Nov 13 2018 includedrwxr-xr-x. 3 root root 20 Nov 13 2018 libdrwxr-xr-x. 2 root root 239 Nov 13 2018 libexec-rw-r--r--. 1 root root 106210 Nov 13 2018 LICENSE.txt-rw-r--r--. 1 root root 15917 Nov 13 2018 NOTICE.txt-rw-r--r--. 1 root root 1366 Nov 13 2018 README.txtdrwxr-xr-x. 3 root root 4096 Nov 13 2018 sbindrwxr-xr-x. 4 root root 31 Nov 13 2018 share
- 寻找到配置文件所在目录
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop
① 配置:
hadoop-env.sh- 将JDK路径 明确配置 给 HDFS
- 寻找 JDK的目录:
echo $JAVA_HOME- 得到路径:
/usr/java/jdk1.8.0_231
- 得到路径:
- 将得到的路径加入到
hadoop-env.sh文件中# export JAVA_HOME=${JAVA_HOME}# 将以上语句修改为export JAVA_HOME=/usr/java/jdk1.8.0_231
- 寻找 JDK的目录:
- 将JDK路径 明确配置 给 HDFS
② 配置:
core-site.xml- 注:可以在hadoop官方文档中查看这些属性的默认值
- 官方默认hdfs的RPC端口号是 8020
- https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
```xml
fs.defaultFS hdfs://linux121:8020
hadoop.tmp.dir <value>/opt/lagou/servers/hadoop-2.9.2/data/tmp</value>
```
- 注:可以在hadoop官方文档中查看这些属性的默认值
③ 配置:
hdfs-site.xml注:可以在hadoop官方文档中查看这些属性的默认值
- https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
```xml
dfs.namenode.secondary.http-address linux123:50090
dfs.replication <value>3</value>
```
- https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
```xml
④ 配置:
slaves文件① 配置:
mapred-env.sh#添加以下语句export JAVA_HOME=/usr/java/jdk1.8.0_231
② 配置:
mapred-site.xml- 注:首先将
mapred-site.xml.template更名为mapred-site.xmlmv mapred-site.xml.template`` ``mapred-site.xml
- 官网默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
<configuration> <!--指定MapReduce运行在Yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>4.3 Yarn 集群配置
- 注:首先将
① 配置:
yarn-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_231② 配置:
yarn-site.xml- 官网默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
```xml
yarn.resourcemanager.hostname linux123
<name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>```
- 官网默认配置:https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
```xml
③ 配置:
slaves文件- 配置HDFS时已经配置过,无需再配置
注**:**
rsync 主要用于备份和镜像,具有速度快、避免复制相同内容和支持符号链接的优点
- rsync 与 scp 的区别
- rsync 速度比 scp 速度快
- rsync 只对差异文件做更新,而 scp 是把所有文件都复制过去
- rsync 基本语法
- 命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
rsync -rvl $pdir/$fname $user@host:$pdir/$fname
rsync 的使用案例
需求:循环复制文件到集群所有节点的相同目录下
- rsync 原始拷贝目录
rsync -rvl /opt/module root@linux123:/opt/
- rsync 原始拷贝目录
- 期望脚本
脚本 + 要同步的文件名称
- 说明
- 在
/usr/local/bin这个目录下存放的脚本,root 用户可以在系统任何地方直接执行
- 在
- 脚本实现
① 在 /usr/local/bin 目录下创建文件 rsync-script
touch /usr/local/bin/rsync-script- 文件内容细节说明
- basename 命令 可求得文件的文件名,如:
basename /usr/local/bin/rsync-script得到结果是:rsync-script
- dirname 命令 可求得文件所在目录,如:
dirname /usr/local/bin/rsync-script得到结果是:/usr/local/bin
- 在脚本文件中要用 反引号
file_name=basename /usr/local/bin/rsync-script``
- 在以下脚本中,如果拷贝文件的时候,文件名不带路径,那么
dirname命令得到的结果是.,表示当前目录。可以在此命令基础上再加一条命令:cd -P,表示进入物理路径,如:cd -P .,此时会进入该目录中,然后通过pwd打印出当前目录,即可获得该文件所在目录的路径,以下是一个例子:
- basename 命令 可求得文件的文件名,如:
1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$# if((paramnum==0)); then echo no params; exit; fi
2 根据传入参数获取文件名称
将传入的第一个参数赋值给变量p1
p1=$1
将命令 basename $p1 的执行结果 赋值给变量file_name
file_name=basename $p1
echo fname=$file_name
3 获取输入参数的绝对路径
pdir=cd -P $(dirname $p1); pwd
echo pdir=$pidr
4 获取用户名称
user=whoami
5 循环执行 rsync
for((host=121; host<124; host++)); do echo ————————————linux$host—————————————— rsync -rvl $pdir/$file_name $user@linux$host:$pdir done
**②** 修改脚本 rsync-script 的执行权限
- `chmod 777 rsync-script`
**③** 调用脚本形式:
- `rsync-script 文件路径+名称`
**④** 调用脚本分发Hadoop安装目录到其他节点
- **`rsync-script /opt/lagou/servers/hadoop-2.9.2`**
<a name="QQ42g"></a>
## 4.5 配置历史服务器
- 在 YARN 中运行任务产生的日志数据还不能查看。为了查看程序的历史运行情况,需要配置以下历史日志服务器。具体配置步骤如下:
1. **配置 **`**mapred-site.xml**`
- 在该文件中加入以下内容
```xml
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux121:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux121:19888</value>
</property>
从 linux121 分发
mapred-site.xml到其他节点rsync-script mapred-site.xml
启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver
查看历史服务器是否启动
jps
查看 JobHistory
http://linux121:19888/joinhistory
- 此时 每个节点计算后产生的日志还不能 聚集到同一个主机上,需再进行配置

配置日志的聚集
- 日志聚集:应用程序(Job)运行完成以后,将应用运行日志信息从各个 task 汇总上传到 HDFS 系统上
- 日志聚集功能的好处:可以方便地查看到程序运行详情,方便开发调试
- 注:开启日志聚集功能,需要重新启动 NodeManager、Resourcemanager 和 HistoryManager
- 开启日志聚集功能的步骤
① 配置 **yarn-site.xml**
- 在该文件中增加以下配置
```xml
yarn.log-aggregation-enable true
``
**②** **分发 **yarn-site.xml` 到集群其他节点
rsync-script yarn-site.xml
③ 关闭 Nodemanager、ResourceManager 和 HistoryManager
sbin/yarn-daemon.sh stop resourcemanagersbin/yarn-daemon.sh stop nodemanagersbin/mr-joinhistory-daemon.sh stop historyserver
④ 启动 Nodenamager、ResourceManager 和 HistoryManager
sbin/yarn-daemon.sh start resourcemanagersbin/yarn-daemon.sh start nodemanagersbin/mr-joinhistory-daemon.sh start historyserver
⑤ 删除 HDFS 上已经存在的输出文件
bin/hdfs dfs -rm -r /wcoutput
⑥ 执行 WordCount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput
⑦ 查看日志,如图所示
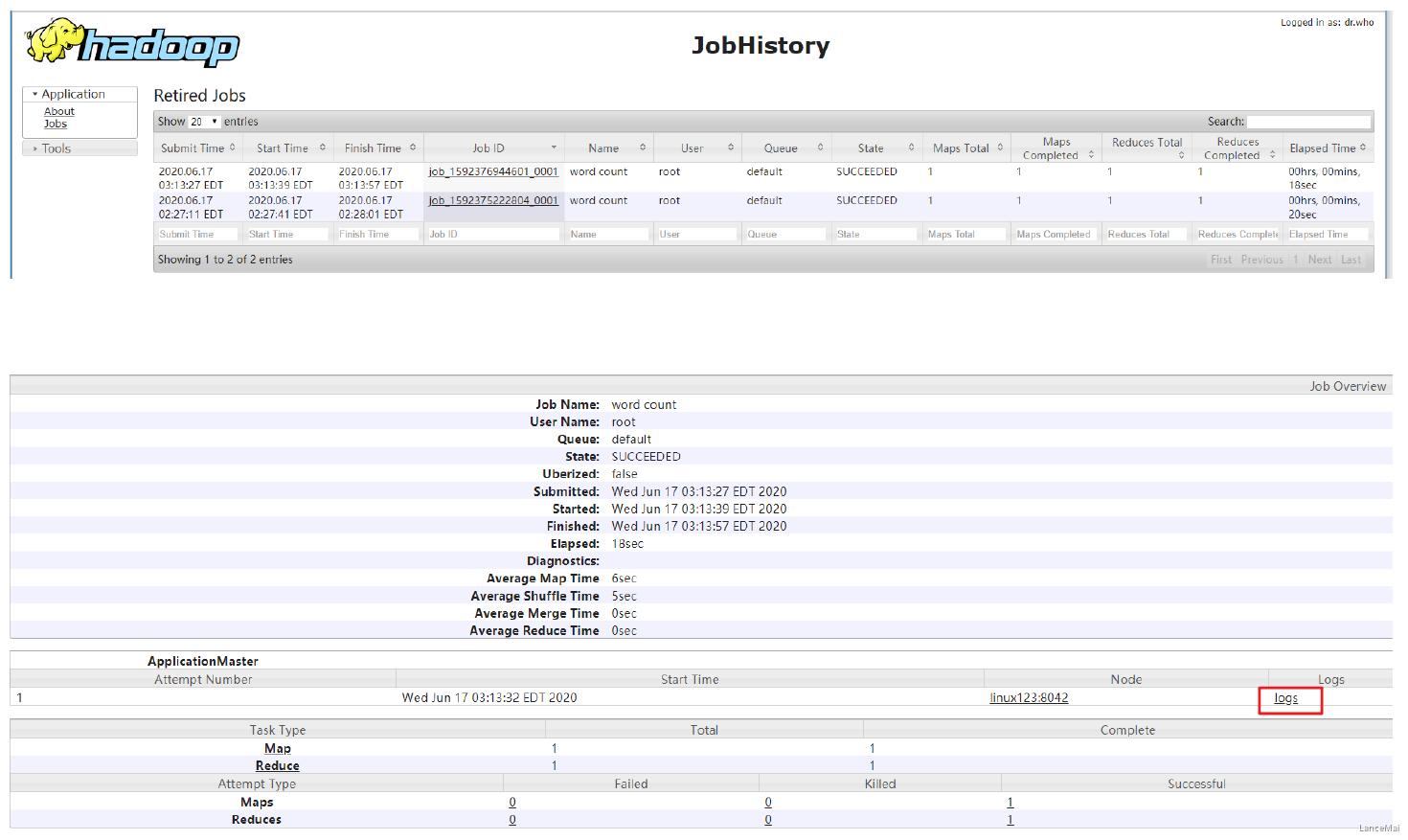

5 启动集群
注:如果集群是**第一次启动,需要在 NameNode所在节点** 格式化 NameNode,非第一次则一定不要执行格式化 NameNode 操作
5.1 单节点启动
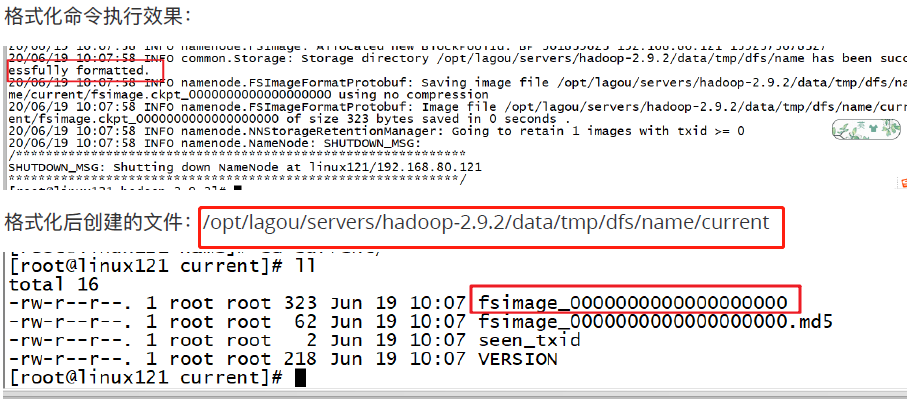
第一次启动时 格式化
hadoop namenode -format
- 在 linux121上启动 NameNode,并用 命令
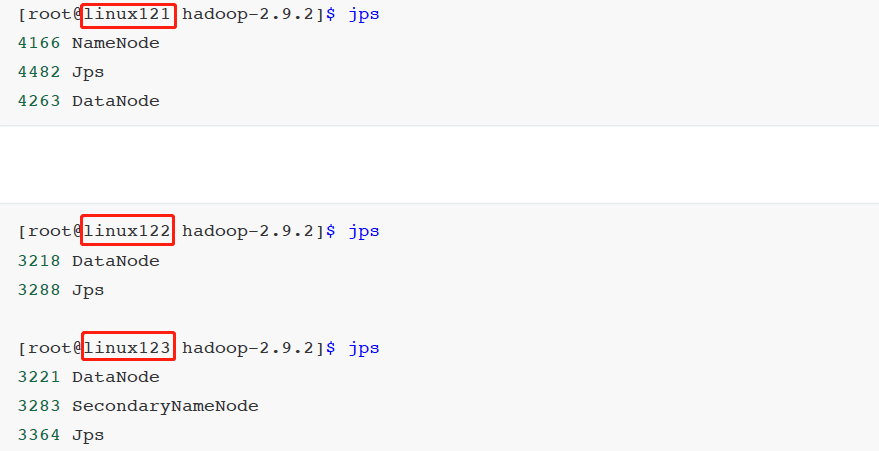
jps来查看 Java 进程hadoop-daemon.sh start namenodejps

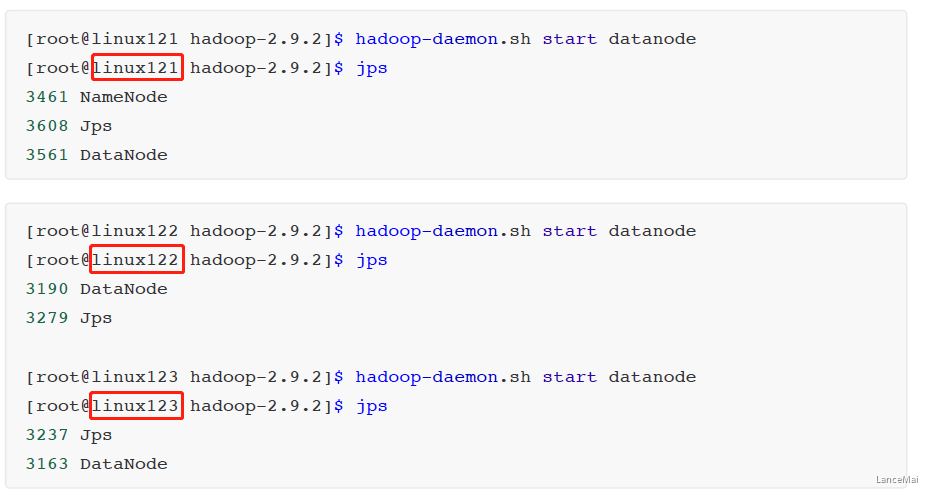
- 在 linux121、linux122、linux123上分别启动 DataNode
- 注:每台虚拟机都应该给 Hadoop安装目录 配置环境变量
hadoop-daemon.sh start datanodejps
- web 端查看 hdfs 界面(NameNode 所在节点)
- 在 浏览器窗口输入
linux121:50070可访问到 NameNode 首页
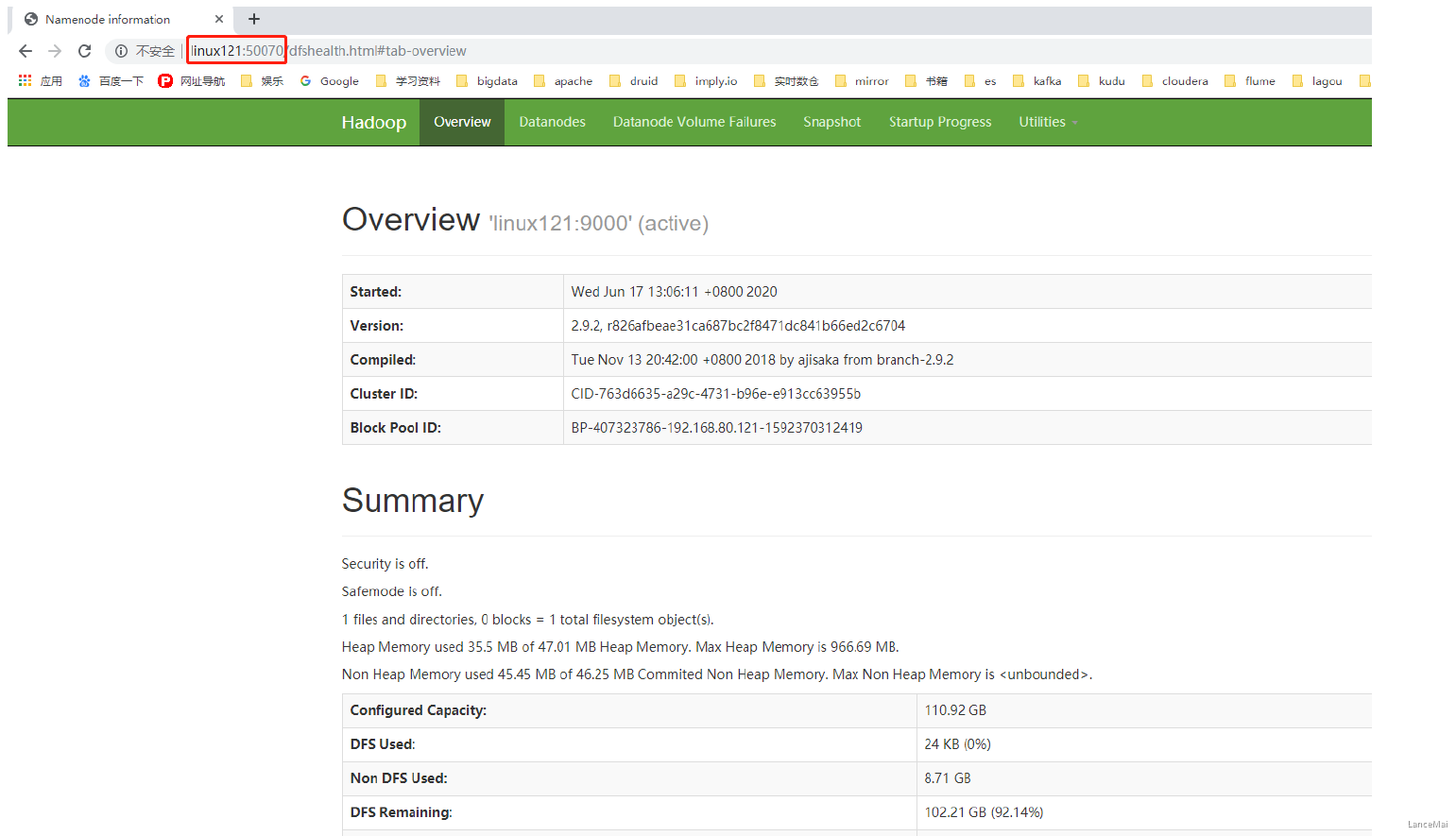
- 查看 HDFS 集群正常节点
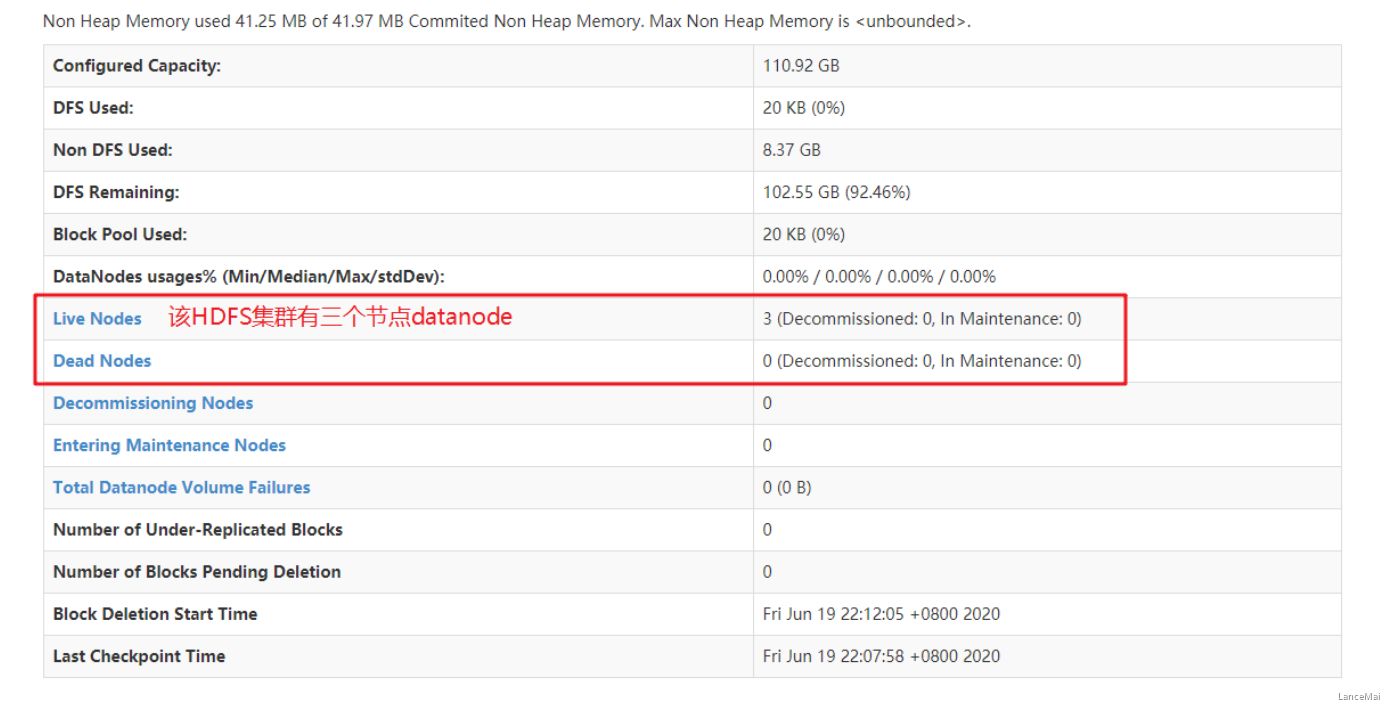
- Yarn 集群单节点启动
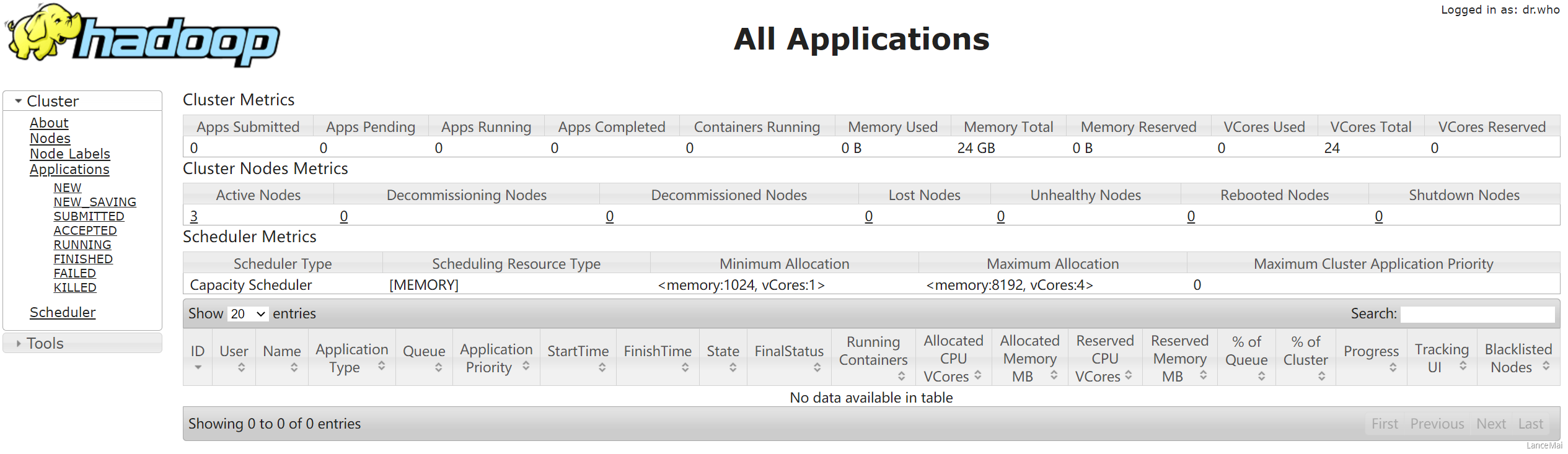
- 如果已经以单节点方式启动了 Hadoop,需要先停止之前启动的 NameNode 与 DataNode进程,如果之前 NameNode 没有执行格式化,这里需要执行格式化!!!
hadoop namenode -format
- 启动 HDFS
[root@linux121 hadoop-2.9.2]# start-dfs.sh
- 启动 YARN
[root@linux123 hadoop-2.9.2]# start-yarn.sh
- 注:NameNode 和 ResourceManager 不是同一台机器,应该在 **NameNode 所在机器启动 HDFS,在ResourceManager 所在的机器上启动 YARN**
5.3 集群启动停止命令汇总
- 各个服务组件逐一启动/停止
① 分别启动/停止 HDFS 组件
hadoop-daemon.sh`**start**/**stop****namenode**/**datanode**/**secondarynamenode`**
② 启动/停止 YARN
yarn-daemon.sh`**start**/**stop****resourcemanager**/**nodemanager`**
- 各个模块分开启动/停止(配置 ssh 是前提)—> **常用**
① 整体启动/停止 HDFS(在nn所在节点进行)
start-dfs.sh/stop-dfs.sh
② 整体启动/停止 YARN(在resourceManager所在节点进行)
start-yarn.sh/stop-yarn.sh

若有收获,就点个赞吧
0 人点赞
