- 1 Flink常用API
- 2 Flink Window窗口机制
- 2.3 会话窗口(Session Window)
- 3 Flink Time
- 3.3 使用Watermark解决
- 3.4 代码实现
- 数据源:
- 01,1586489566000 01,1586489567000 01,1586489568000 01,1586489569000 01,1586489570000
- 01,1586489571000 01,1586489572000 01,1586489573000
- 01,1586489574000
- 01,1586489575000
- 01,1586489576000
- 01,1586489577000
- 01,1586489578000
- 01,1586489579000
- 2020-04-10 11:32:46 2020-04-10 11:32:47 2020-04-10 11:32:48 2020-04-10 11:32:49 2020-04-10 11:32:50
- 代码:
1 Flink常用API
DataStream API主要分为 3 块:DataSource、Transformation、Sink
- DataSource是程序的数据源输入,可以通过StreamExecutionEnvironment.addSource(sourceFuntion)为程序添加一个数据源
- Transformation是具体的操作,它对一个或多个输入数据源进行计算处理,比如Map、FlatMap和Filter等操作
- Sink是程序的输出,它可以把Transformation处理之后的数据输出到指定的存储介质中。
1.1 Flink DataStream常用API
1.1.1 DataSource
Flink针对DataStream提供了大量已经实现的DataSource(数据源接口),比如如下 4 种:
- 基于文件 —> readTextFile(path)
读取文本文件,文件遵循TextInputFormat逐行读取规则并返回
tip:本地Idea读hdfs需要依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-hadoop-compatibility_2.11</artifactId><version>1.11.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.8.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.8.5</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.8.5</version></dependency>
- 基于Socket —> socketTextStream
从Socket中读取数据,元素可以通过一个分隔符分开
- 基于集合 —> fromCollection(Collection)
通过Java的Collection集合创建一个数据流,集合中的所有元素必须是相同类型的
如果满足以下条件,Flink将数据类型识别为POJO类型(并允许“按名称”字段引用):
- 该类是共有且独立的(没有非静态内部类)
- 该类有共有的无参构造方法
- 类(及父类)中所有的不被static、transient修饰的属性要么有公有的(且不被final修饰),要么是包含共有的getter和setter方法,这些方法遵循java bean命名规范。
实例:
package com.lagou.edu.streamsource;import org.apache.flink.api.common.functions.FilterFunction;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;public class StreamFromCollection {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// DataStreamSource data = env.fromElements("spark", "flink");ArrayList peopleList = new ArrayList();peopleList.add(new People("lucas", 18));peopleList.add(new People("jack", 30));peopleList.add(new People("jack", 40));DataStreamSource data = env.fromCollection(peopleList);// DataStreamSource data = env.fromElements(new People("lucas", 18), new People("jack", 30), new People("jack", 40));SingleOutputStreamOperator filtered = data.filter(new FilterFunction() {public boolean filter(People people) throws Exception {return people.age > 20;}});filtered.print();env.execute();}public static class People{public String name;public Integer age;public People(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}@Overridepublic String toString() {return "People{" +"name='" + name + ''' +", age=" + age +'}';}}
- 自定义输入
可以使用StreamExecutionEnvironment.addSource(sourceFunction)将一个流式数据源加到程序中。
Flink提供了许多预先实现的源函数,但是也可以编写自己的自定义源,方法是为
- 非并行源implements SourceFunction
- 并行源 implements ParallelSourceFunction接口
- extends RichParallelSourceFunction。
Flink也提供了一批内置的Connector(连接器),如下表列了几个主要的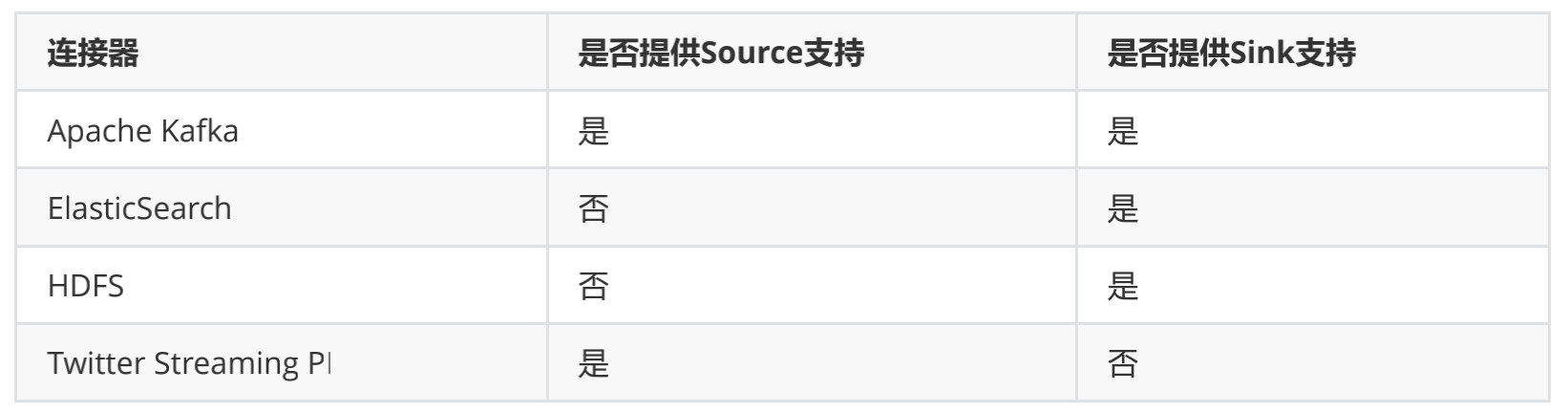
Kafka连接器
a、依赖:
b、代码:
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class StreamFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","hdp-2:9092");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>("mytopic2", new SimpleStringSchema(), properties);
DataStreamSource<String> data = env.addSource(consumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = data.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for (String word : s.split(" ")) {
collector.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1);
result.print();
env.execute();
}
}
c、启动kafka
- ./kafka-server-start.sh -daemon ../config/server.properties
d、创建topic
- bin/kafka-topics.sh —create —zookeepper teacher1:2181 —replication-factor 1 —partitions 1 —topic mytopic2
e、启动控制台kafka生产者
- ./kafka-console-consumer.sh —bootstrap-server hdp-2:9092 —topic animal
- 自定义数据源代码详见PDF。
总结自定义数据源:flinkkafkaconnector源码初探:
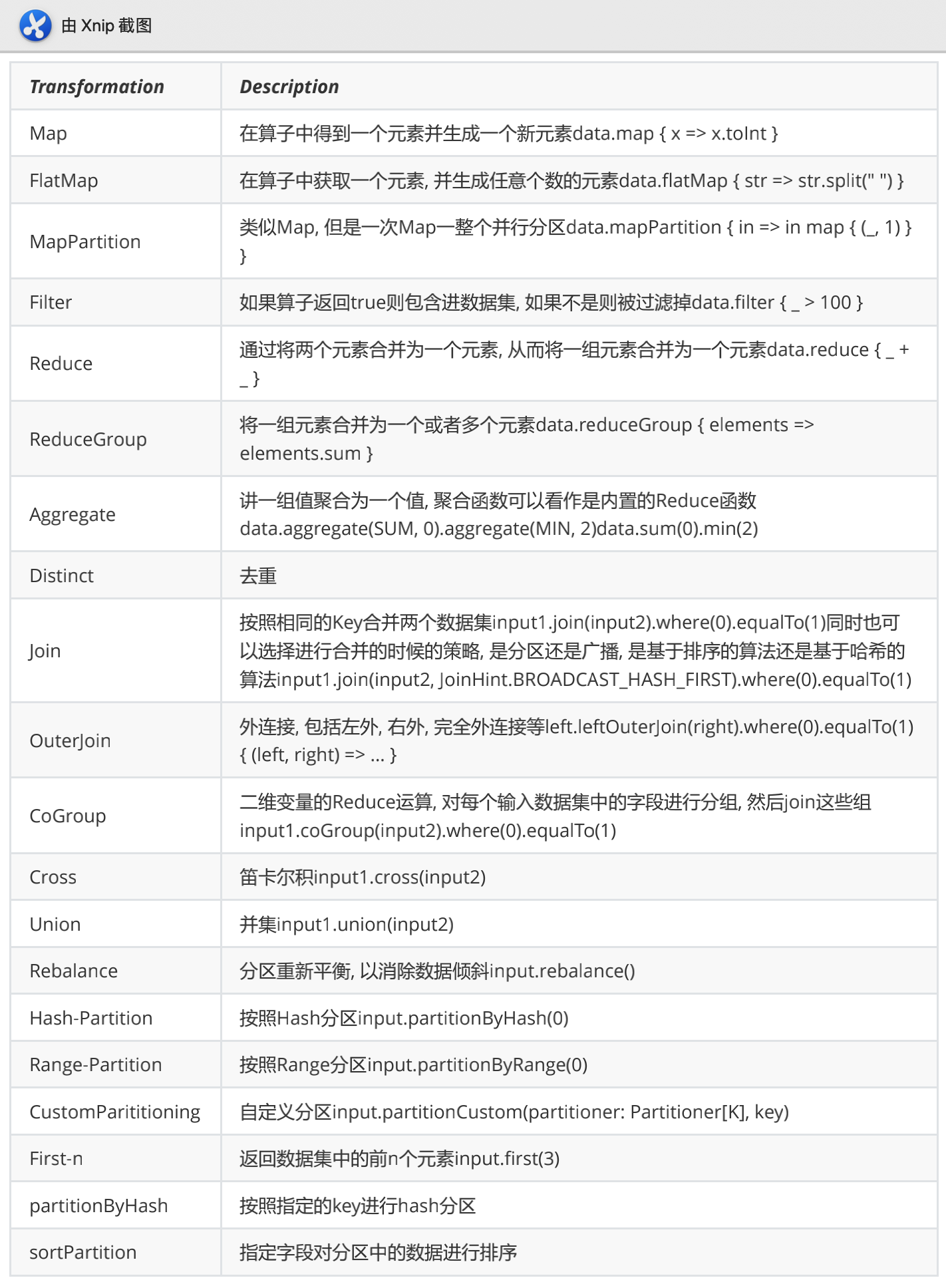
Map DataStream → DataStream Takes one element and produces one element. A map function that doubles the values of the input stream

- FlatMap DataStream → DataStream Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:

- Filter DataStream → DataStream Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:

- KeyBy DataStream → KeyedStream Logically partitions a stream into disjoint partitions. All records with the same key are assigned to the same partition. Internally, keyBy() is implemented with hash partitioning.There are different ways to specify keys.
This transformation returns a KeyedStream, which is, among other things, required to use keyed state.
Attention A type cannot be a key if:
it is a POJO type but does not override the hashCode() method and relies on the Object.hashCode() implementation. it is an array of any type.
Reduce KeyedStream → DataStream A “rolling” reduce on a
keyed data stream. Combines the current element with the last reduced value and emits the new value.
A reduce function that creates a stream of partial sums:
Fold KeyedStream → DataStream A “rolling” fold on a keyed data stream with an initial value. Combines the
current element with the last folded value and emits the new value.
A fold function that, when applied on the sequence (1,2,3,4,5), emits the sequence “start-1”, “start-1-2”,
“start-1-2-3”, …
Aggregations KeyedStream → DataStream Rolling aggregations on a keyed data stream. The difference
between min and minBy is that min returns the minimum value, whereas minBy returns the element that
has the minimum value in this field (same for max and maxBy).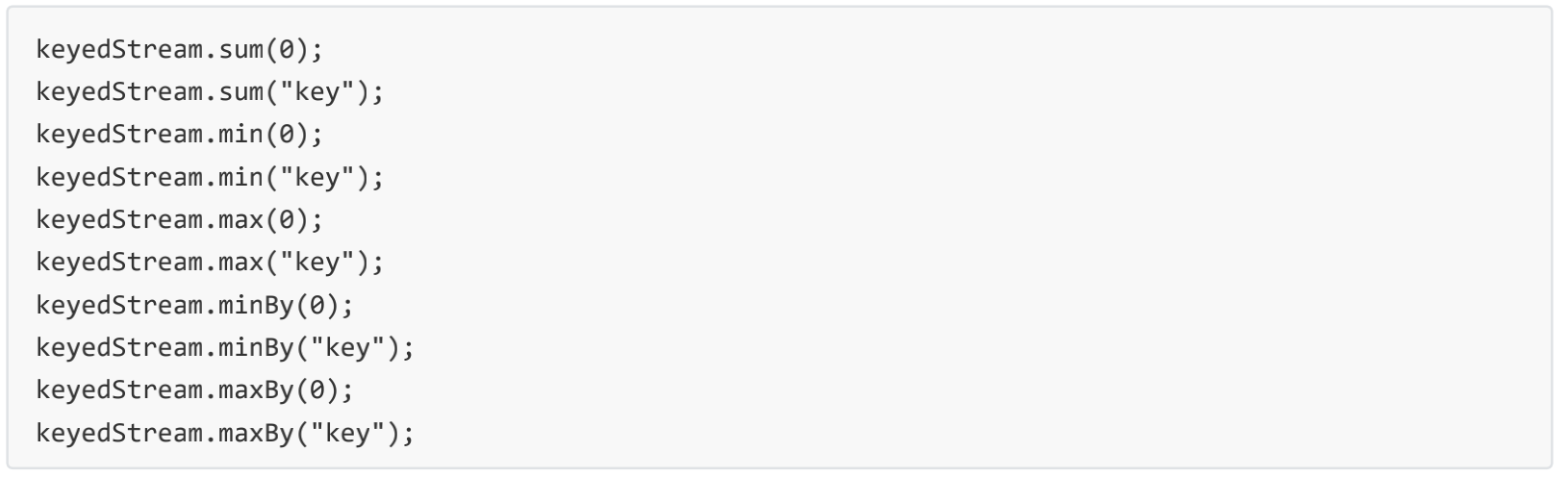
Window KeyedStream → WindowedStream Windows can be defined on already partitioned KeyedStreams.
Windows group the data in each key according to some characteristic (e.g., the data that arrived within the
last 5 seconds). See windows for a complete description of windows.
- WindowAll DataStream → AllWindowedStream Windows can be defined on regular DataStreams. Windows group all the stream events according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.
WARNING: This is in many cases a non-parallel transformation. All records will be gathered in one task for
the windowAll operator.
- Window Apply WindowedStream → DataStream AllWindowedStream → DataStream Applies a general function to the window as a whole. Below is a function that manually sums the elements of a window.
Note: If you are using a windowAll transformation, you need to use an AllWindowFunction instead.
Window Reduce WindowedStream → DataStream Applies a functional reduce function to the window and
returns the reduced value.
Window Fold WindowedStream → DataStream Applies a functional fold function to the window and returns
the folded value. The example function, when applied on the sequence (1,2,3,4,5), folds the sequence into
the string “start-1-2-3-4-5”:
Aggregations on windows WindowedStream → DataStream Aggregates the contents of a window. The
difference between min and minBy is that min returns the minimum value, whereas minBy returns the
element that has the minimum value in this field (same for max and maxBy).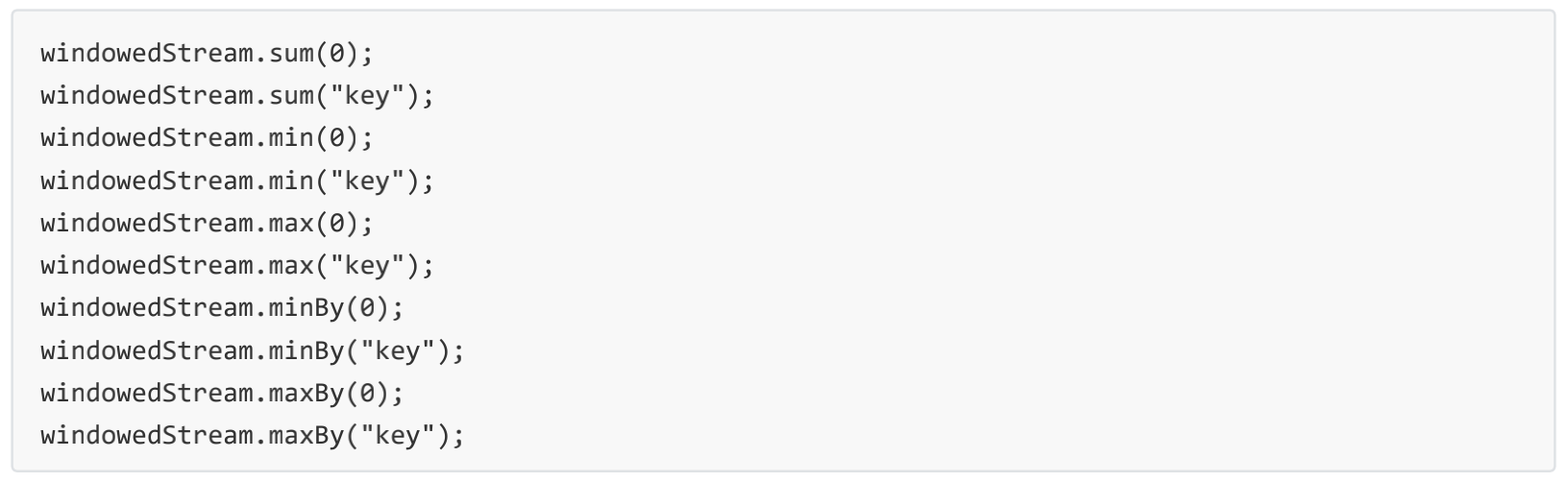
Union DataStream → DataStream Union of two or more data streams creating a new stream containing all the elements from all the streams. Note: If you union a data stream with itself you will get each element twice in the resulting stream.
dataStream.union(otherStream1, otherStream2, ...);Window Join DataStream,DataStream → DataStream Join two data streams on a given key and a common window.

- Interval Join KeyedStream,KeyedStream → DataStream Join two elements e1 and e2 of two keyed streams with a common key over a given time interval, so that e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound

- Window CoGroup DataStream,DataStream → DataStream Cogroups two data streams on a given key and a common window.

- Connect DataStream,DataStream → ConnectedStreams “Connects” two data streams retaining their types.Connect allowing for shared state between the two streams.

- CoMap, CoFlatMap ConnectedStreams → DataStream Similar to map and flatMap on a connected data stream

- Split DataStream → SplitStream Split the stream into two or more streams according to some criterion.

- Select SplitStream → DataStream Select one or more streams from a split stream.

- Iterate DataStream → IterativeStream → DataStream Creates a “feedback” loop in the flow, by redirecting the output of one operator to some previous operator. This is especially useful for defining algorithms that continuously update a model. The following code starts with a stream and applies the iteration body continuously. Elements that are greater than 0 are sent back to the feedback channel, and the rest of the elements are forwarded downstream. See iterations for a complete description.

1.1.3 Sink
Flink针对DataStream提供了大量的已经实现的数据目的地(Sink),具体如下所示
- writeAsText():讲元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
- print()/printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
- 自定义输出:addSink可以实现把数据输出到第三方存储介质中
案例1:将流数据下沉到redis中
1 、依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.1.5</version>
</dependency>
2 、关键代码:
//封装
SingleOutputStreamOperator<Tuple2<String, String>> l_wordsData = data.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
return new Tuple2<>("l_words", value);
}
});
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("hdp-1").setPort(6379).build();
RedisSink<Tuple2<String, String>> redisSink = new RedisSink<>(conf, new MyRedisMapper());
l_wordsData.addSink(redisSink);
public static class MyMapper implements RedisMapper<Tuple2<String,String>> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.LPUSH);
}
@Override
public String getKeyFromData(Tuple2<String,String> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String,String> data) {
return data.f1;
}
}
案例 2 :将流数据下沉到MySQL中—自定义 启动类:
启动类: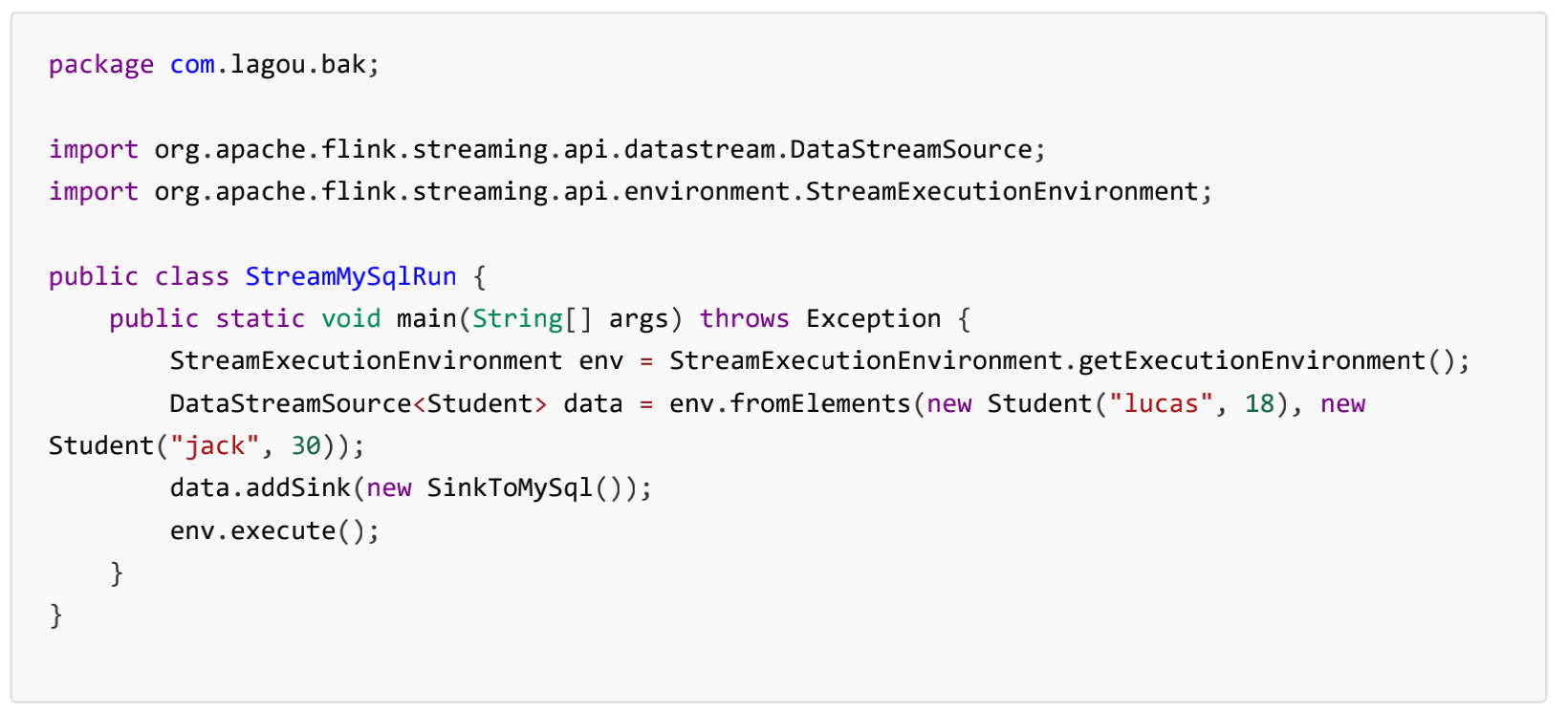
案例 3 :下沉到Kafka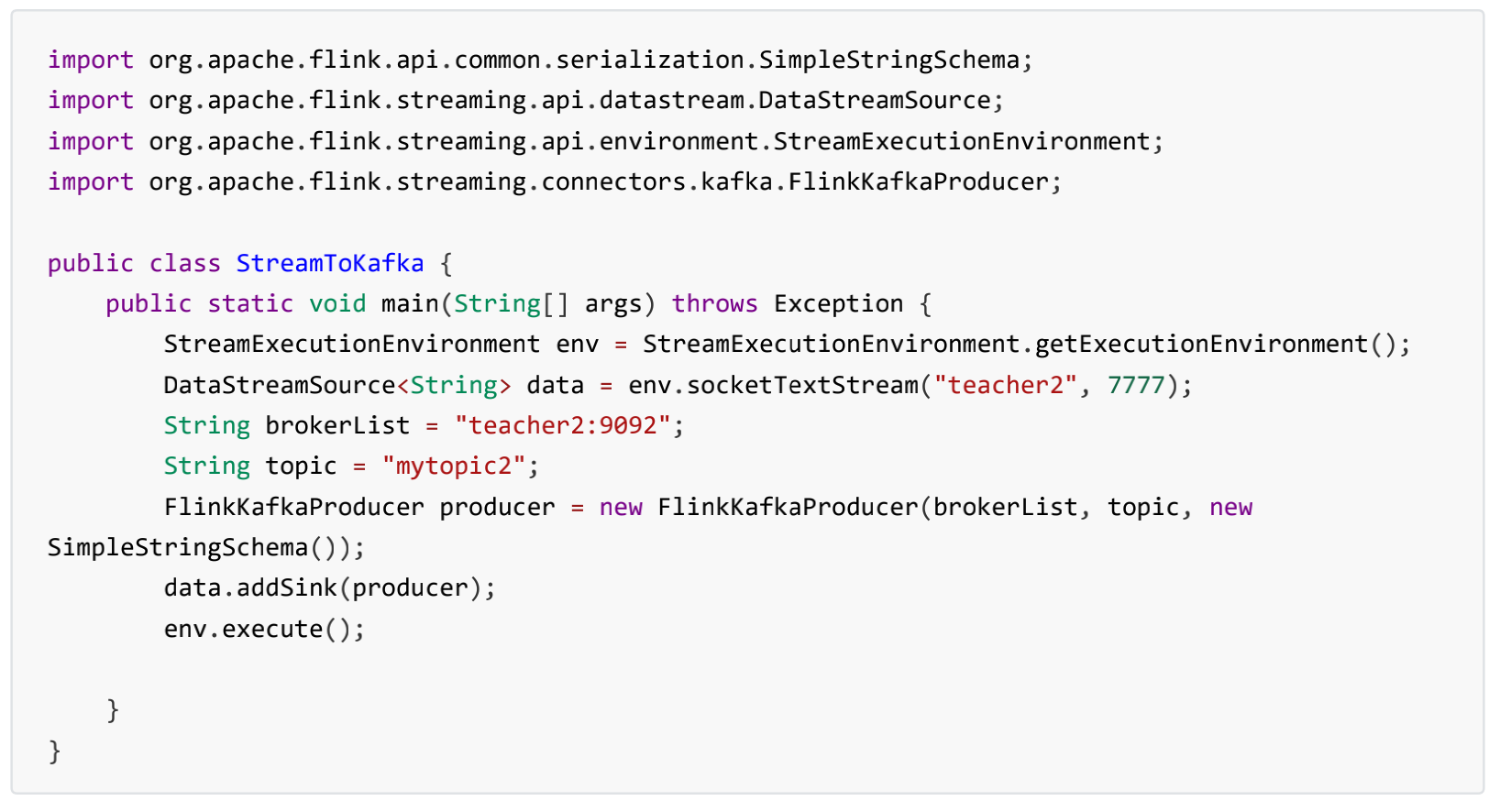
1.2 Flink DataSet常用API
DataSet API同DataStream API一样有三个组成部分,各部分作用对应一致,此处不再赘述
1.2.1 DataSource
对DataSet批处理而言,较为频繁的操作是读取HDFS中的文件数据,因为这里主要介绍两个DataSource组件
- 基于集合
- fromCollection(Collection),主要是为了方便测试使用
基于文件
Map:输入一个元素,然后返回一个元素,中间可以进行清洗转换等操作
- FlatMap:输入一个元素,可以返回 0 个、 1 个或者多个元素
- Filter:过滤函数,对传入的数据进行判断,符合条件的数据会被留下
- Reduce:对数据进行聚合操作,结合当前元素和上一次Reduce返回的值进行聚合操作,然后返回一个新的值
Aggregations:sum()、min()、max()等
1.2.3 Sink
Flink针对DataStream提供了大量的已经实现的数据目的地(Sink),具体如下所示
writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
- writeAsCsv():将元组以逗号分隔写入文件中,行及字段之间的分隔是可配置的,每个字段的值来自对象的toString()方法
print()/pringToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
1.3 Flink Table API和SQL_API
Apache Flink提供了两种顶层的关系型API,分别为Table API和SQL,Flink通过Table API&SQL实现了批流统一。其中Table API是用于Scala和Java的语言集成查询API,它允许以非常直观的方式组合关系运算符(例如select,where和join)的查询。Flink SQL基于Apache Calcite 实现了标准的SQL,用户可以使用标准的SQL处理数据集。Table API和SQL与Flink的DataStream和DataSet API紧密集成在一起,用户可以实现相互转化,比如可以将DataStream或者DataSet注册为table进行操作数据。值得注意的是,Table API and SQL目前尚未完全完善,还在积极的开发中,所以并不是所有的算子操作都可以通过其实现。
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>1.11.1</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<!-- Either... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<!-- or... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.11.1</version>
<scope>provided</scope>
</dependency>
基于TableAPI的案例:
package com.lagou.table;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
public class TableApiDemo {
public static void main(String[] args) throws Exception {
//Flink执行环境env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//用env,做出Table环境tEnv
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
//获取流式数据源
DataStreamSource<Tuple2<String, Integer>> data = env.addSource(new SourceFunction<Tuple2<String, Integer>>(){
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
while (true) {
ctx.collect(new Tuple2<>("name", 10 ));
Thread.sleep( 1000 );
}
}
@Override
public void cancel() {
}
});
//将流式数据源做成Table
Table table = tEnv.fromDataStream(data, $("name"), $("age"));
//对Table中的数据做查询
Table name = table.select($("name"));
//将处理结果输出到控制台
DataStream<Tuple2<Boolean, Row>> result = tEnv.toRetractStream(name, Row.class);
result.print();
env.execute();
}
}
2 Flink Window窗口机制
- Flink Window 背景
- Flink认为Batch是Streaming的一个特例,因此Flink底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从Streaming到Batch的桥梁。
- 通俗讲,Window是用来对一个无限的流设置一个有限的集合,从而在有界的数据集上进行操作的一种机制。流上的集合由Window来划定范围,比如“计算过去 10 分钟”或者“最后 50 个元素的和”。
- Window可以由时间(Time Window)(比如每30s)或者数据(Count Window)(如每 100 个元素)驱动。
- DataStream API提供了Time和Count的Window。
- 在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。
- 当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的 1 分钟内有多少用户点击了我们的网页。
- 在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
- 窗口可以是基于时间驱动的(Time Window,例如:每 30 秒钟)
- 也可以是基于数据驱动的(Count Window,例如:每一百个元素)
- 同时基于不同事件驱动的窗口又可以分成以下几类:
- 翻滚窗口 (Tumbling Window, 无重叠)
- 滑动窗口 (Sliding Window, 有重叠)
- 会话窗口 (Session Window, 活动间隙)
- 全局窗口 (略)
- Flink要操作窗口,先得将StreamSource 转成WindowedStream
- 步骤:
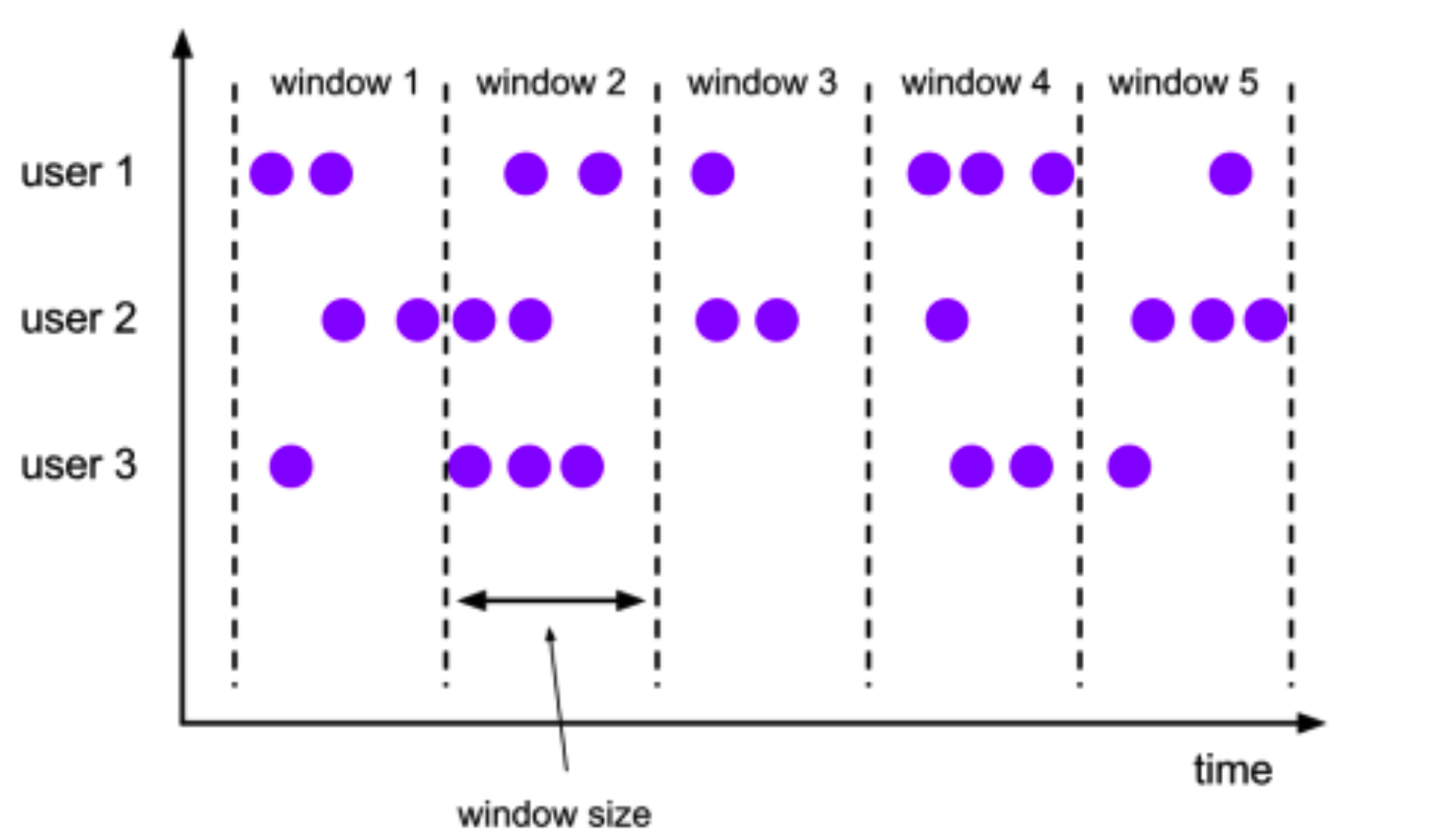
- 将数据依据固定的窗口长度对数据进行切分
- 特点:时间对齐,窗口长度固定,没有重叠
代码示例
package com.lagou.edu.flink.window;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.text.SimpleDateFormat;
import java.util.Random;
/**
* 翻滚窗口:窗口不重叠
* 1、基于时间驱动
* 2、基于事件驱动
*/
public class TumblingWindow {
public static void main(String[] args) {
//设置执行环境,类似spark中初始化sparkContext
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism( 1 );
DataStreamSource<String> dataStreamSource = env.socketTextStream("teache2", 7777 );
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeMillis = System.currentTimeMillis();
int random = new Random().nextInt(10);
System.out.println("value: " + value + " random: " + random + "timestamp: " + timeMillis + "|" + format.format(timeMillis));
return new Tuple2<String, Integer>(value, random);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapStream.keyBy( 0 );
// 基于时间驱动,每隔10s划分一个窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow = keyedStream.timeWindow(Time.seconds( 10 ));
// 基于事件驱动, 每相隔 3 个事件(即三个相同key的数据), 划分一个窗口进行计算
// WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> countWindow = keyedStream.countWindow(3);
// apply是窗口的应用函数,即apply里的函数将应用在此窗口的数据上。
timeWindow.apply(new MyTimeWindowFunction()).print();
// countWindow.apply(new MyCountWindowFunction()).print();
try {
// 转换算子都是lazy init的, 最后要显式调用 执行程序
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.1.1 基于时间驱动
场景:我们需要统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被成为翻滚时间窗口(Tumbling Time Window)
2.1.2 基于事件驱动
场景:当我们想要每 100 个用户的购买行为作为驱动,那么每当窗口中填满 100 个”相同”元素了,就会对窗口进行计算。
2.2 滑动窗口(Sliding Window)
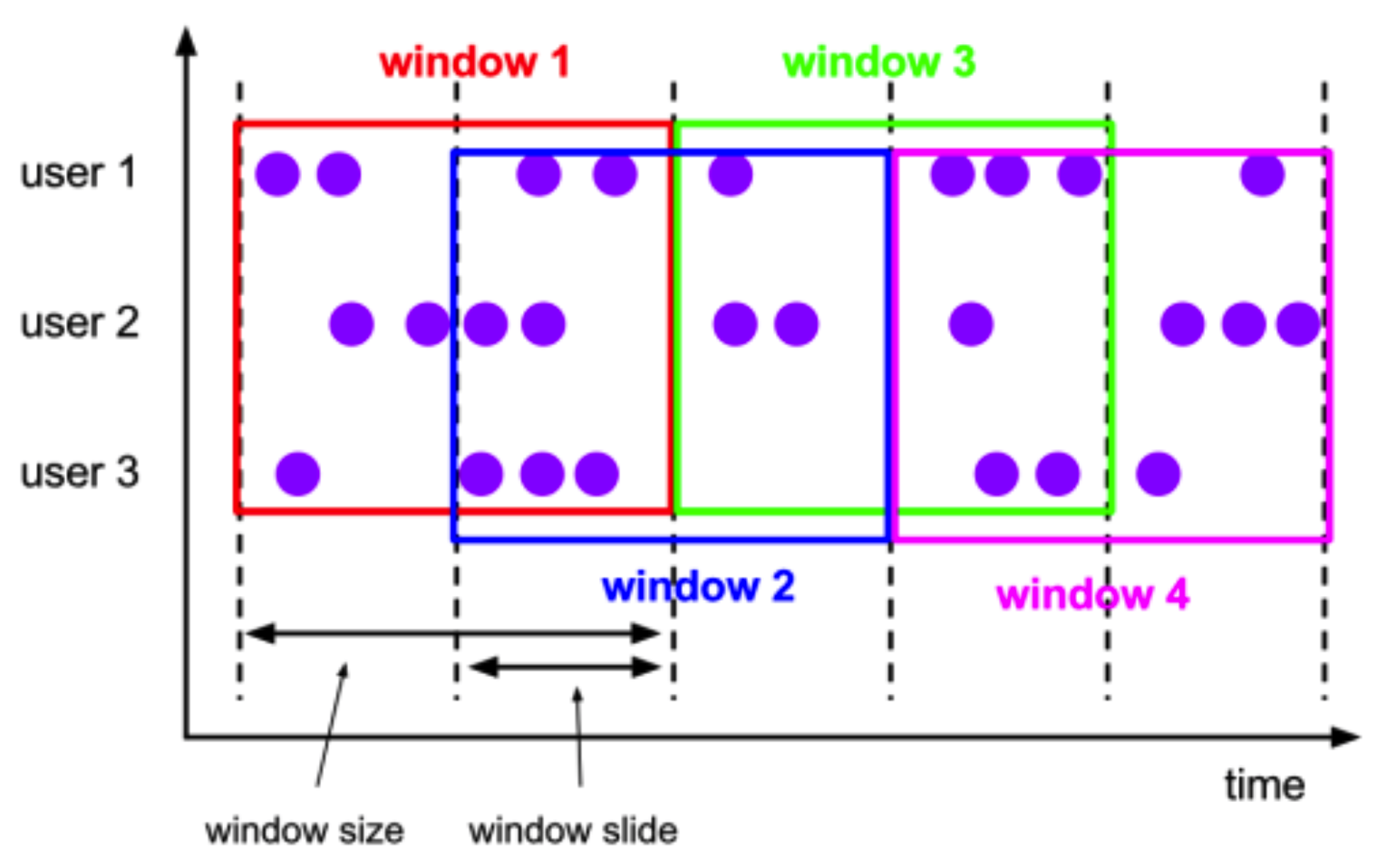
- 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
- 特点:窗口长度固定,可以有重叠
2.2.1 基于时间的滑动窗口
场景: 我们可以每 30 秒计算一次最近一分钟用户购买的商品总数
2.2.2 基于事件的滑动窗口
场景: 每 10 个 “相同”元素计算一次最近 100 个元素的总和
代码实现
package com.lagou.edu.flink.window;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.text.SimpleDateFormat;
import java.util.Random;
/**
* 滑动窗口:窗口可重叠
* 1、基于时间驱动
* 2、基于事件驱动
*/
public class SlidingWindow {
public static void main(String[] args) {
// 设置执行环境, 类似spark中初始化SparkContext
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism( 1 );
DataStreamSource<String> dataStreamSource = env.socketTextStream("teacher2", 7777 );
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource.map(new
MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeMillis = System.currentTimeMillis();
int random = new Random().nextInt( 10 );
System.err.println("value : " + value + " random : " + random + " timestamp : "
+ timeMillis + "|" + format.format(timeMillis));
return new Tuple2<String, Integer>(value, random);
}
});
2.3 会话窗口(Session Window)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和
固定的开始时间和结束时间的情况
session窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产
生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
特点
会话窗口不重叠,没有固定的开始和结束时间
与翻滚窗口和滑动窗口相反, 当会话窗口在一段时间内没有接收到元素时会关闭会话窗口。
后续的元素将会被分配给新的会话窗口
案例描述
计算每个用户在活跃期间总共购买的商品数量,如果用户 30 秒没有活动则视为会话断开
代码实现
package com.lagou.edu.flink.window;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.text.SimpleDateFormat;
import java.util.Random;
public class SessionWindow {
public static void main(String[] args) {
// 设置执行环境, 类似spark中初始化sparkContext
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism( 1 );
DataStreamSource<String> dataStreamSource = env.socketTextStream("teacher2", 7777 );
SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = dataStreamSource.map(new
MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
3 Flink Time
3.1 Time
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeMillis = System.currentTimeMillis();
int random = new Random().nextInt( 10 );
System.err.println("value : " + value + " random : " + random + " timestamp : "
+ timeMillis + "|" + format.format(timeMillis));
return new Tuple2<String, Integer>(value, random);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapStream.keyBy( 0 );
//如果连续10s内,没有数据进来,则会话窗口断开。
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window =
keyedStream.window(ProcessingTimeSessionWindows.withGap(Time.seconds( 10 )));
// window.sum(1).print();
window.apply(new MyTimeWindowFunction()).print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
- EventTime[事件时间]
事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间
如果以EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带EventTime
- IngestionTime[摄入时间]
数据进入Flink的时间,如某个Flink节点的source operator接收到数据的时间,例如:某个source消费到kafka中
的数据
如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准
- ProcessingTime[处理时间]
某个Flink节点执行某个operation的时间,例如:timeWindow处理数据时的系统时间,默认的时间属性就是
Processing Time
如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的systemTime为准
在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用
ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置使用事件时间
3.2 数据延迟产生的问题
l 示例 1
现在假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。
选好了外卖后,你就用在线支付功能付款了,这个时候是 11 点 50 分。恰好这时,你走进了地下停车库,而这里并
没有手机信号。因此外卖的在线支付并没有立刻成功,而支付系统一直在Retry重试“支付”这个操作。
当你找到自己的车并且开出地下停车场的时候,已经是 12 点 05 分了。这个时候手机重新有了信号,手机上的支付
数据成功发到了外卖在线支付系统,支付完成。
在上面这个场景中你可以看到,支付数据的事件时间是 11 点 50 分,而支付数据的处理时间是 12 点 05 分
一般在实际开发中会以事件时间作为计算标准
l 示例 2
一条日志进入Flink的时间为2019-08-12 10:00:01,摄入时间
到达Window的系统时间为2019-08-12 10:00:02,处理时间
日志的内容为:2019-08-12 09:58:02 INFO Fail over to rm2 ,事件时间
对于业务来说,要统计1h内的故障日志个数,哪个时间是最有意义的?—-事件时间
EventTime,因为我们要根据日志的生成时间进行统计。
l 示例 3
某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。
A 用户在 11:02 对 App 进行操作,B 用户在 11:03 操作了 App,
但是 A 用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到 B 用户 11:03 的消息,然后再接受到
A 用户 11:02 的消息,消息乱序了。
l 示例 4
在实际环境中,经常会出现,因为网络原因,数据有可能会延迟一会才到达Flink实时处理系统。
我们先来设想一下下面这个场景:
1. 使用时间窗口来统计 10 分钟内的用户流量
2. 有一个时间窗口
- 开始时间为:2017-03-19 10:00:00
- 结束时间为:2017-03-19 10:10:00
3. 有一个数据,因为网络延迟
- 事件发生的时间为:2017-03-19 10:10:00
- 但进入到窗口的时间为:2017-03-19 10:10:02,延迟了 2 秒中
4. 时间窗口并没有将 59 这个数据计算进来,导致数据统计不正确
这种处理方式,根据消息进入到window时间,来进行计算。在网络有延迟的时候,会引起计算误差。
如何解决?—-使用水印解决网络延迟问题
通过上面的例子,我们知道,在进行数据处理的时候应该按照事件时间进行处理,也就是窗口应该要考虑到事件时间
但是窗口不能无限的一直等到延迟数据的到来,需要有一个触发窗口计算的机制
也就是我们接下来要学的watermaker水位线/水印机制
3.3 使用Watermark解决
水印(watermark)就是一个时间戳,Flink可以给数据流添加水印,
可以理解为:收到一条消息后,额外给这个消息添加了一个时间字段,这就是添加水印。
- 水印并不会影响原有Eventtime事件时间
- 当数据流添加水印后,会按照水印时间来触发窗口计算
也就是说watermark水印是用来触发窗口计算的
- 一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟达到多久
(即水印时间 = 事件时间 - 允许延迟时间)10:09:57 = 10:10:00 - 3s
- 当接收到的 水印时间 >= 窗口结束时间,则触发计算 如等到一条数据的水印时间为10:10:00 >= 10:10:00 才触发
计算,也就是要等到事件时间为10:10:03的数据到来才触发计算
(即事件时间 - 允许延迟时间 >= 窗口结束时间 或 事件时间 >= 窗口结束时间 + 允许延迟时间)
总结:watermaker是用来解决延迟数据的问题
如窗口10:00:00~10:10:00
而数据到达的顺序是: A 10:10:00 ,B 10:09:58
如果没有watermaker,那么A数据将会触发窗口计算,B数据来了窗口已经关闭,则该数据丢失
那么如果有了watermaker,设置允许数据迟到的阈值为3s
那么该窗口的结束条件则为 水印时间>=窗口结束时间10:10:00,也就是需要有一条数据的水印时间= 10:10:00
而水印时间10:10:00= 事件时间- 延迟时间3s
也就是需要有一条事件时间为10:10:03的数据到来,才会真正的触发窗口计算
而上面的 A 10:10:00 ,B 10:09:58都不会触发计算,也就是会被窗口包含,直到10:10:03的数据到来才会计算窗口
10:00:00~10:10:00的数据
Watermark案例
步骤:
1 、获取数据源
2 、转化
3 、声明水印(watermark)
4 、分组聚合,调用window的操作
5 、保存处理结果
注意:
当使用EventTimeWindow时,所有的Window在EventTime的时间轴上进行划分,
也就是说,在Window启动后,会根据初始的EventTime时间每隔一段时间划分一个窗口,
如果Window大小是 3 秒,那么 1 分钟内会把Window划分为如下的形式:
[00:00:00,00:00:03)
[00:00:03,00:00:06)
[00:00:03,00:00:09)
[00:00:03,00:00:12)
[00:00:03,00:00:15)
[00:00:03,00:00:18)
[00:00:03,00:00:21)
[00:00:03,00:00:24)
…
[00:00:57,00:00:42)
[00:00:57,00:00:45)
[00:00:57,00:00:48)
…
如果Window大小是 10 秒,则Window会被分为如下的形式:
[00:00:00,00:00:10)
[00:00:10,00:00:20)
…
[00:00:50,00:01:00)
l 注意:
1.窗口是左闭右开的,形式为:[window_start_time,window_end_time)。
2.Window的设定基于第一条消息的事件时间,也就是说,Window会一直按照指定的时间间隔进行划分,不论这
个Window中有没有数据,EventTime在这个Window期间的数据会进入这个Window。
3.Window会不断产生,属于这个Window范围的数据会被不断加入到Window中,所有未被触发的Window都会等
待触发,只要Window还没触发,属于这个Window范围的数据就会一直被加入到Window中,直到Window被触发
才会停止数据的追加,而当Window触发之后才接受到的属于被触发Window的数据会被丢弃。
4.Window会在以下的条件满足时被触发执行:
(1)在[window_start_time,window_end_time)窗口中有数据存在
(2)watermark时间 >= window_end_time;
5.一般会设置水印时间,比事件时间小几秒钟,表示最大允许数据延迟达到多久
(即水印时间 = 事件时间 - 允许延迟时间)
当接收到的 水印时间 >= 窗口结束时间且窗口内有数据,则触发计算
(即事件时间 - 允许延迟时间 >= 窗口结束时间 或 事件时间 >= 窗口结束时间 + 允许延迟时间)
3.4 代码实现
数据源:
01,1586489566000 01,1586489567000 01,1586489568000 01,1586489569000 01,1586489570000
01,1586489571000 01,1586489572000 01,1586489573000
01,1586489574000
01,1586489575000
01,1586489576000
01,1586489577000
01,1586489578000
01,1586489579000
2020-04-10 11:32:46 2020-04-10 11:32:47 2020-04-10 11:32:48 2020-04-10 11:32:49 2020-04-10 11:32:50
代码:
package com.lagou.Time;
import org.apache.commons.math3.fitting.leastsquares.EvaluationRmsChecker;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import sun.nio.cs.StreamEncoder;
import javax.annotation.Nullable;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
import java.util.Iterator;
public class WaterDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism( 1 );
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource data = env.socketTextStream(“teacher2”, 7777 );
SingleOutputStreamOperator
MapFunction
@Override
public Tuple2
String[] split = value.split(“,”);
return new Tuple2<>(split[ 0 ], Long.valueOf(split[ 1 ]));
}
});
SingleOutputStreamOperator
maped.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks
Long currentMaxTimestamp = 0l;
final Long maxOutOfOrderness = 10000l;
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss.SSS”);
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(Tuple2
previousElementTimestamp) {
long timestamp = element.f1;
// System.out.println(“timestamp:” + timestamp + “…” );
// System.out.println(“…” + sdf.format(timestamp));
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
System.out.println(“key:” + element.f0
- “…eventtime:[“ + element.f1 + “|” + sdf.format(element.f1)
/+ “],currentMaxTimestamp:[“ + currentMaxTimestamp + “|” +
sdf.format(currentMaxTimestamp)/
/+ “],watermark:[“ + getCurrentWatermark().getTimestamp() + “| “ +
sdf.format(getCurrentWatermark().getTimestamp() + “]”)/);
System.out.println(“currentMaxTimestamp” + currentMaxTimestamp + “…” +
sdf.format(currentMaxTimestamp));
System.out.println(“watermark:” + getCurrentWatermark().getTimestamp() + “…” +
sdf.format(getCurrentWatermark().getTimestamp()));
return timestamp;
}
});
SingleOutputStreamOperator res =
watermarks.keyBy( 0 ).window(TumblingEventTimeWindows.of(Time.seconds( 3 ))).apply(new
WindowFunction
@Override

若有收获,就点个赞吧
0 人点赞
