第一部分 Spark Core
第 1 节 Spark概述
1.1 什么是Spark
Spark 是一个快速、通用的计算引擎。Spark的特点:速度快、使用简单、通用、兼容好。
1.2 Spark 与 Hadoop
从狭义的角度上看:Hadoop是一个分布式框架,由存储、资源调度、计算三部分组成;
- Spark是一个分布式**计算**引擎;
- 从广义的角度上看,Spark是Hadoop生态中不可或缺的一部分;
- Spark在借鉴MapReduce优点的同时,很好地解决了MapReduce所面临的问题。
- 备注:Spark的计算模式也属于MapReduce;Spark框架是对MR框架的优化;
- Spark 为什么比 MapReduce 快:
- Spark积极使用内存。 MR框架中一个Job 只能拥有一个 map task 和一个 reduce task。如果业务处理逻辑复杂,一个map和一个reduce是表达不出来的,这时就需要将多个 job 组合起来;然而前一个job的计算结果必须写到HDFS,才能交给后一个job。这样一个复杂的运算,在MR框架中会发生很多次写入、读取操作操作;Spark框架则可以把多个map reduce task组合在一起连续执行,中间的计算结果不需要落地;
复杂的MR任务:mr + mr + mr + mr +mr …
复杂的Spark任务:mr -> mr -> mr ……
- 多进程模型(MR) vs 多线程模型(Spark) 。MR框架中的的Map Task和Reduce Task是进程级别的,而Spark Task是基于线程模型的。MR框架中的 map task、reduce task都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间。Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的系统开销。
1.3 系统架构
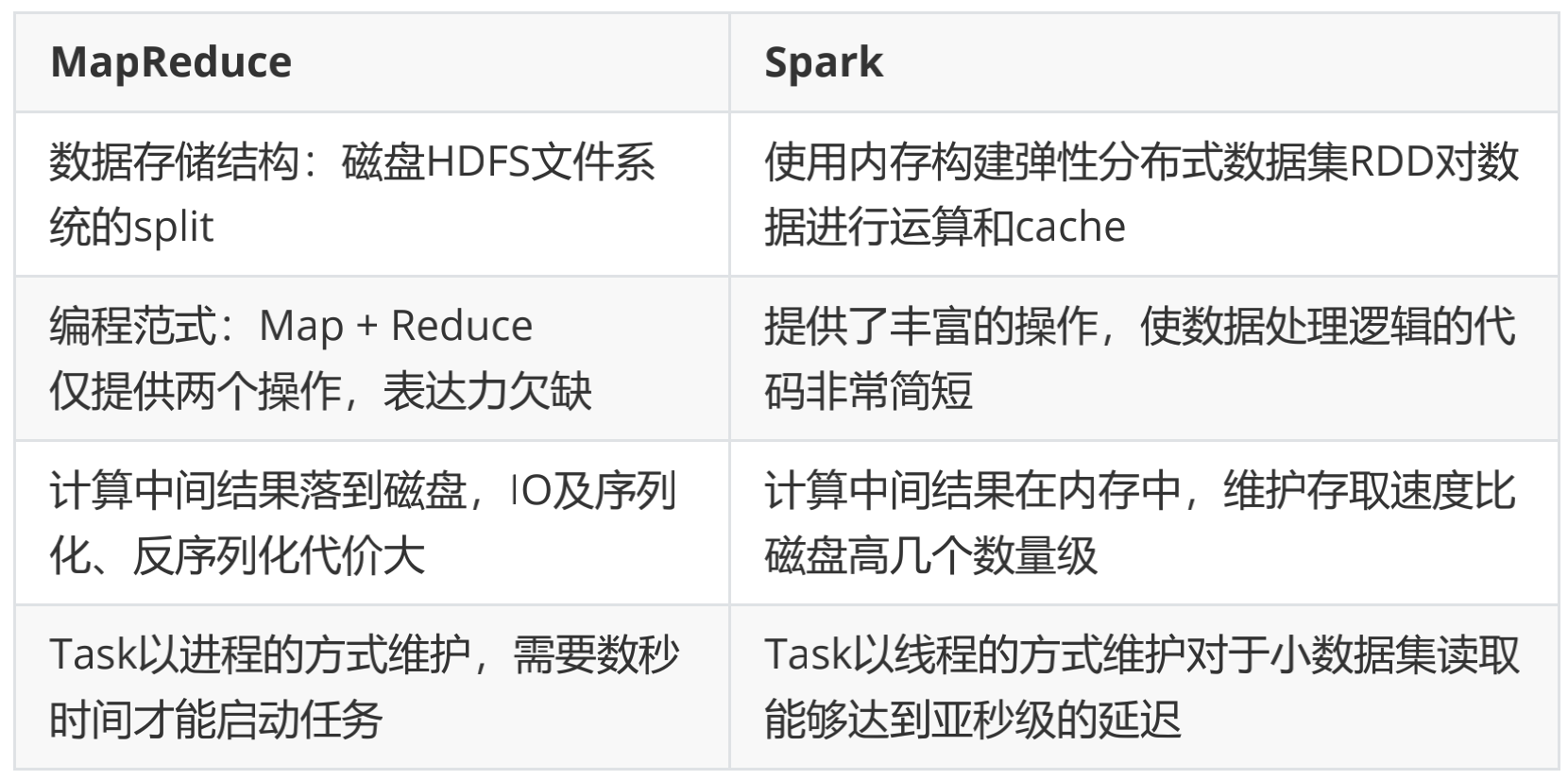
- Spark运行架构包括:
- Cluster Manager
- Worker Node
- Driver
- Executor
- Cluster Manager 是集群资源的管理者。Spark支持 3 种集群部署模式:
- Standalone
- Yarn
- Mesos
- Worker Node 工作节点,管理本地资源;
- Driver Program。运行应用的 main() 方法并且创建了 SparkContext。由ClusterManager分配资源,SparkContext 发送 Task 到 Executor 上执行;
- Executor:在工作节点上运行,执行 Driver 发送的 Task,并向 Dirver 汇报计算结果;
1.4 Spark集群部署模式
- Standalone模式
- 独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。从一定程度上说,该模式是其他两种的基础
- Cluster Manager:Master
- Worker Node:Worker
- 仅支持粗粒度的资源分配方式
- Spark On Yarn模式
- Yarn拥有强大的社区支持,且逐步已经成为大数据集群资源管理系统的标准在国内生产环境中运用最广泛的部署模式
- Spark on yarn 的支持两种模式:
- yarn-cluster:适用于生产环境
- yarn-client:适用于交互、调试,希望立即看到app的输出
- Cluster Manager:ResourceManager
- Worker Node:NodeManager
- 仅支持粗粒度的资源分配方式
Spark On Mesos模式
- 官方推荐的模式。Spark开发之初就考虑到支持Mesos,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然
- Cluster Manager:Mesos Master
- Worker Node:Mesos Slave
- 支持粗粒度、细粒度的资源分配方式
粗粒度模式(Coarse-grained Mode) :每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
- 细粒度模式(Fine-grained Mode) :鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,核心思想是按需分配。
三种集群部署模式如何选择:
- Application: 用户提交的spark应用程序,由集群中的一个driver 和 许多executor 组成
- Application jar: 一个包含spark应用程序的jar,jar不应该包含 Spark 或 Hadoop的 jar,这些jar应该在运行时添加
- Driver program: 运行应用程序的main(),并创建SparkContext(Spark应用程序)
- Cluster manager :管理集群资源的服务,如standalone,Mesos,Yarn
- Deploy mode: 区分 driver 进程在何处运行。在 Cluster 模式下,在集群内部运行 Driver。 在 Client 模式下,Driver 在集群外部运行
- Worker node :运行应用程序的工作节点
- Executor :运行应用程序 Task 和保存数据,每个应用程序都有自己的executors,并且各个executor相互独立
- Task: executors应用程序的最小运行单元
- Job: 在用户程序中,每次调用Action函数都会产生一个新的job,也就是说每个Action 生成一个job
Stage :一个 job 被分解为多个 stage,每个 stage 是一系列 Task 的集合
第 2 节 Spark安装配置
2.1 Spark安装
- 文档地址:http://spark.apache.org/docs/latest/
- 下载地址:http://spark.apache.org/downloads.html
- 下载Spark安装包
- 备注:不用安装scala
- 安装步骤:
- 下载软件解压缩,移动到指定位置 ```shell cd /opt/lagou/software/
tar zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz mv spark-2.4.5-bin-without-hadoop-scala-2.12/ ../servers/spark- 2.4.5/
- **设置环境变量,并使之生效**```shellvi /etc/profileexport SPARK_HOME=/opt/lagou/servers/spark-2.4.5export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinsource /etc/profile
- 修改配置
- 文件位置:
$SPARK_HOME/conf - 修改文件:
slaves、spark-defaults.conf、spark-env.sh、log4j.properties
- 文件位置:
修改slaves
linux
linux
linux
修改spark-defaults.conf
spark.master spark://linux121: 7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux121:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
- 创建 HDFS 目录:
hdfs dfs -mkdir /spark-eventlog - 备注:
- spark.master。定义master节点,缺省端口号 7077
- spark.eventLog.enabled。开启eventLog
- spark.eventLog.dir。eventLog的存放位置
- spark.serializer。一个高效的序列化器
- spark.driver.memory。定义driver内存的大小(缺省1G)
修改spark-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2
export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/lagou/servers/hadoop-2.9.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=linux
export SPARK_MASTER_PORT= 7077
备注:这里使用的是 spark-2.4.5-bin-without-hadoop,所以要将 Hadoop 相关jars 的位置告诉Spark
将Spark软件分发到集群;修改其他节点上的环境变量
cd /opt/lagou/software/ scp -r spark-2.4.5/ linux122:$PWD scp -r spark-2.4.5/ linux123:$PWD启动集群
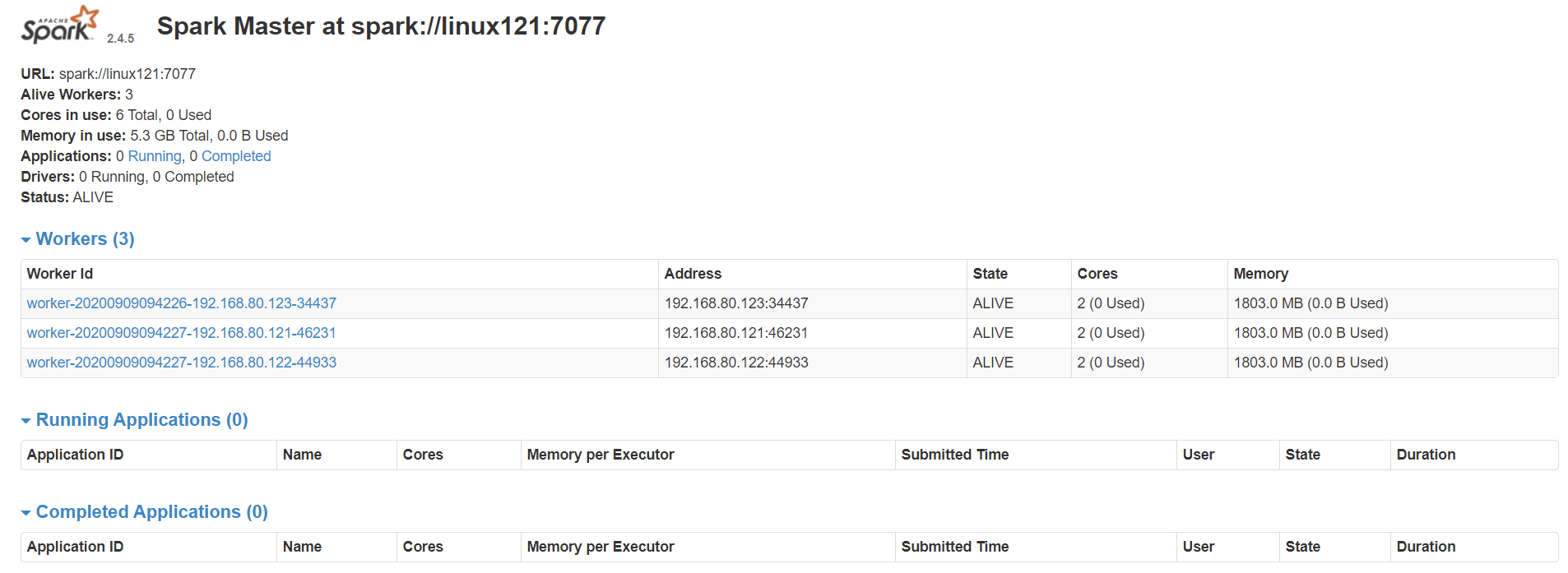
cd $SPARK_HOME/sbin./start-all.sh- 分别在linux121、linux122、linux123上执行 jps,可以发现:
- linux121:Master、Worker
- linux122:Worker
- linux123:Worker
- 此时 Spark 运行在 Standalone 模式下。
- 在浏览器中输入:http://linux121:8080/可以看见如下 Spark 的 Web 界面:
- 备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和stop-all.sh 文件。在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会产生冲突。
- 解决方案:
- 将其中一组命令重命名。如:将 $HADOOP_HOME/sbin 路径下的命令重命名为:start-all-hadoop.sh / stop-all-hadoop.sh(推荐)
- 集群测试 ```shell run-example SparkPi 10
spark-shell
// HDFS 文件 val lines = sc.textFile(“/wcinput/wc.txt”) lines.flatMap(.split(“ “)).map((, 1)).reduceByKey(+).collect().foreach(println)
- Spark集群是否一定依赖hdfs?不是的,除非我用到了hdfs。
- Apache Spark支持多种部署模式:
- 本地模式。最简单的运行模式,Spark所有进程都运行在一台机器的 JVM 中
- 伪分布式模式。在一台机器中模拟集群运行,相关的进程在同一台机器上(用的非常少)
- 分布式模式。包括:Standalone、Yarn、Mesos
- Standalone。使用Spark自带的资源调度框架
- Yarn。使用 Yarn 资源调度框架
- Mesos。使用 Mesos 资源调度框架
<a name="81ed118f"></a>
### 2.2 本地模式
- 本地模式部署在单机,主要用于测试或实验;最简单的运行模式,所有进程都运行在一台机器的 JVM 中;
- 本地模式用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题;
- 这种模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。**不用启动Spark的Master、Worker守护进程** ,也不用启动Hadoop的服务(除非用到HDFS)。
- local:在本地启动一个线程来运行作业;
- local[N]:启动了N个线程;
- local[*]:使用了系统中所有的核;
- local[N,M]:第一个参数表示用到核的个数;第二个参数表示容许作业失败的次数
- 前面几种模式没有指定M参数,其默认值都是 1 ;
- 测试:
- 关闭相关服务
- `stop-dfs.sh `
- `stop-all.sh `
- 启动 Spark 本地运行模式
- `spark-shell --master local`
- 备注:此时可能有错误。主要原因是配置了日志聚合(即是用来了hdfs,但hdfs服务关闭了),关闭该选项即可
- 
- 使用 jps 检查,发现一个 SparkSubmit 进程
- 这个SparkSubmit进程又当爹、又当妈。既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。
<a name="df870436"></a>
### 2.3 伪分布式
- 这种模式不常用,而且有bug,详见PDF
<a name="7521a544"></a>
### 2.4 集群模式--Standalone模式
- 参考:[http://spark.apache.org/docs/latest/spark-standalone.html](http://spark.apache.org/docs/latest/spark-standalone.html)
- 与单机运行的模式不同,这里必须先启动Spark的Master和Worker守护进程;
- 关闭 yarn 对应的服务
- 不用启动Hadoop服务,除非要使用HDFS的服务
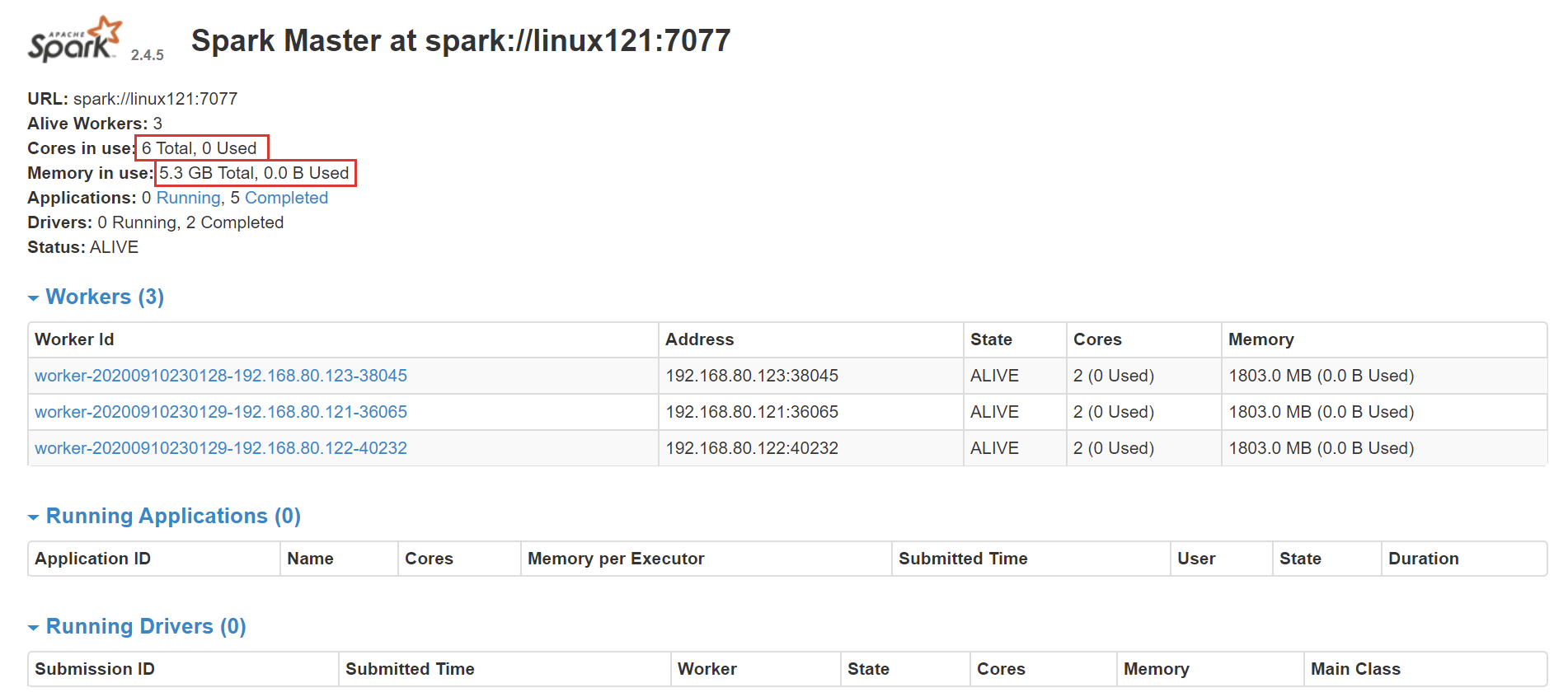
- 使用jps检查,可以发现:
- linux121:Master、Worker
- linux122:Worker
- linux123:Worker
- 使用浏览器查看(linux121:8080)
- 
<a name="9L7tZ"></a>
#### 2.4.1 Standalone 配置
```shell
sbin/start-master.sh / sbin/stop-master.sh
sbin/start-slaves.sh / sbin/stop-slave.sh
sbin/start-slave.sh / sbin/stop-slaves.sh
sbin/start-all.sh / sbin/stop-all.sh
- 备注:
./sbin/start-slave.sh [options];启动节点上的worker进程,调试中较为常用 - 在 spark-env.sh 中定义:

- SPARK_WORKER_CORES :Total number of cores to allow Spark applications to use on the machine (default: all available cores).
- SPARK_WORKER_MEMORY :Total amount of memory to allow Spark applications to use on the machine, e.g. 1000m, 2g (default: total memory minus 1 GiB); note that each application’s individual memory is configured using its spark.executor.memory property.
- 测试在
spark-env.sh中增加参数,分发到集群,重启服务:export SPARK_WORKER_CORES= 10export SPARK_WORKER_MEMORY=20g
在浏览器中观察集群状态,测试完成后将以上两个参数分别改为 2 、2g,重启服务。
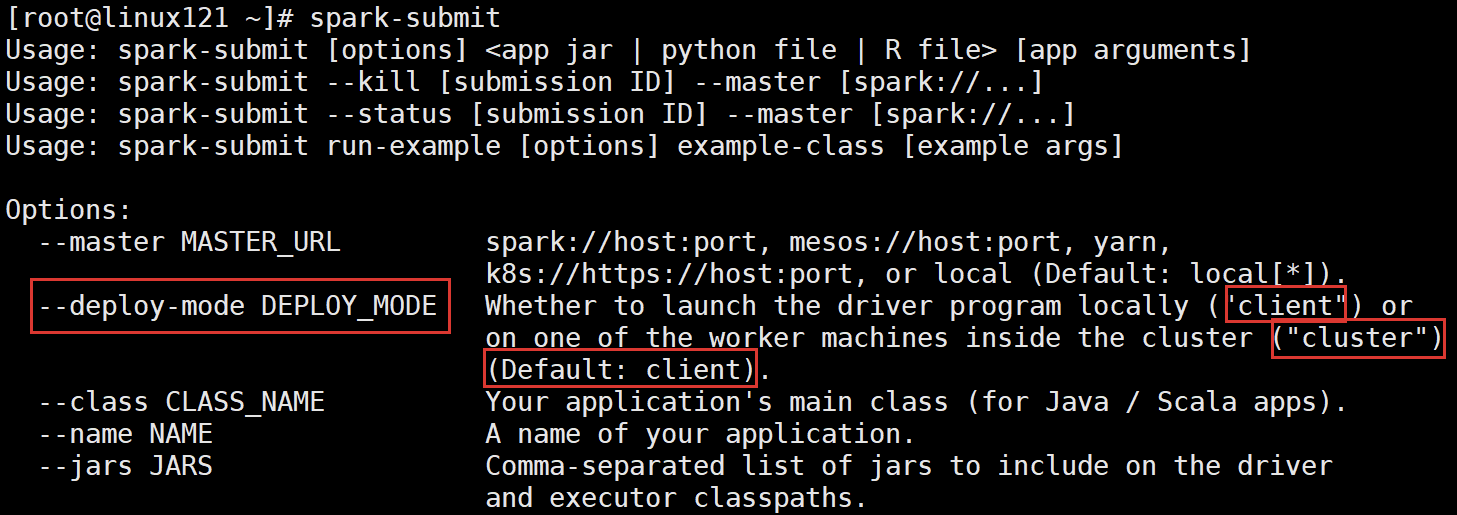
2.4.2 运行模式(cluster / client)
最大的区别:Driver运行在哪里;client是缺省的模式,能看见返回结果,适合调试;cluster与此相反;
- Client模式(缺省)。Driver运行在提交任务的Client,此时可以在Client模式下,看见应用的返回结果,适合交互、调试
- Cluster模式。Driver运行在Spark集群中,看不见程序的返回结果,合适生产环境
- 测试 1 (Client 模式):
spark-submit --class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 1000
- 再次使用 jps 检查集群中的进程:
- Master进程做为cluster manager,管理集群资源
- Worker 管理节点资源
- SparkSubmit 做为Client端,运行 Driver 程序。Spark Application执行完成,进程终止
- CoarseGrainedExecutorBackend,运行在Worker上,用来并发执行应用程序
- 测试 2 (Cluster 模式):
spark-submit --class org.apache.spark.examples.SparkPi \
--deploy-mode cluster \$SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 1000
- 再次使用 jps 检查集群中的进程:
- SparkSubmit 进程会在应用程序提交给集群之后就退出
- Master会在集群中选择一个 Worker 进程生成一个子进程 DriverWrapper 来启动 Driver 程序
- Worker节点上会启动 CoarseGrainedExecutorBackend
- DriverWrapper 进程会占用 Worker 进程的一个core(缺省分配 1 个core,1G内存)
- 应用程序的结果,会在执行 Driver 程序的节点的 stdout 中输出,而不是打印在屏幕上
- 在启动 DriverWrapper 的节点上,进入 $SPARK_HOME/work/,可以看见类似driver-20200810233021-0000 的目录,这个就是 driver 运行时的日志文件,进入该目录,会发现:
- 修改配置文件并分发
```shell
spark-defaults.conf
history server
spark.eventLog.enabled true spark.eventLog.dir hdfs://linux121:9000/spark-eventlog spark.eventLog.compress true
spark-env.sh
export SPARK_HISTORY_OPTS=”-Dspark.history.ui.port=18080 - Dspark.history.retainedApplications=50 - Dspark.history.fs.logDirectory=hdfs://linux121:9000/spark- eventlog”
- spark.history.retainedApplications。设置缓存Cache中保存的应用程序历史记录的个数(默认 50 ),如果超过这个值,旧的将被删除;
- 缓存文件数不表示实际显示的文件总数。只是表示不在缓存中的文件可能需要从硬盘读取,速度稍有差别
- 前提条件:启动hdfs服务(日志写到HDFS)
- 启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。
- `$SPARK_HOME/sbin/start-history-server.sh`
- web端地址:[http://linux121:18080/](http://linux121:18080/)
<a name="e7d543eb"></a>
#### 2.4.4 高可用配置
- Spark Standalone集群是 Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存着Master单点故障的问题。如何解决这个问题,Spark提供了两种方案:
- **基于zookeeper的Standby Master**
- 适用于生产模式。将 Spark 集群连接到Zookeeper,利用 Zookeeper 提供的选举和状态保存的功能,一个 Master 处于Active 状态,其他 Master 处于Standby状态;
- 保证在ZK中的元数据主要是集群的信息,包括:Worker,Driver和Application以及Executors的信息;
- 如果Active的Master挂掉了,通过选举产生新的 Active 的 Master,然后执行状态恢复,整个恢复过程可能需要1~2分钟;
- **基于文件系统的单点恢复** (Single-Node Rcovery with Local File System)
- 主要用于开发或者测试环境。将 Spark Application 和 Worker 的注册信息保存在文件中,一旦Master发生故障,就可以重新启动Master进程,将系统恢复到之前的状态
- 配置步骤:
- 安装ZooKeeper,并启动
- 修改 spark-env.sh 文件,并分发到集群中
```shell
# 注释以下两行!!!
# export SPARK_MASTER_HOST=linux121
# export SPARK_MASTER_PORT=7077
# 添加以下内容
export SPARK_DAEMON_JAVA_OPTS="- Dspark.deploy.recoveryMode=ZOOKEEPER - Dspark.deploy.zookeeper.url=linux121,linux122,linux123 - Dspark.deploy.zookeeper.dir=/spark"
- 备注:
- spark.deploy.recoveryMode:可选值 Zookeeper、FileSystem、None
- deploy.zookeeper.url:Zookeeper的URL,主机名:端口号(缺省2181)
- deploy.zookeeper.dir:保存集群元数据信息的地址,在ZooKeeper中保存该信息
启动 Spark 集群(linux121)
$SPARK_HOME/sbin/start-all.sh- 浏览器输入:http://linux121:8080/,刚开始 Master 的状态是STANDBY,稍等一会变为:RECOVERING,最终是:ALIVE
- 在 linux122 上启动master
- 进入浏览器输入:http://linux122:8080/,此时 Master 的状态为:STANDBY
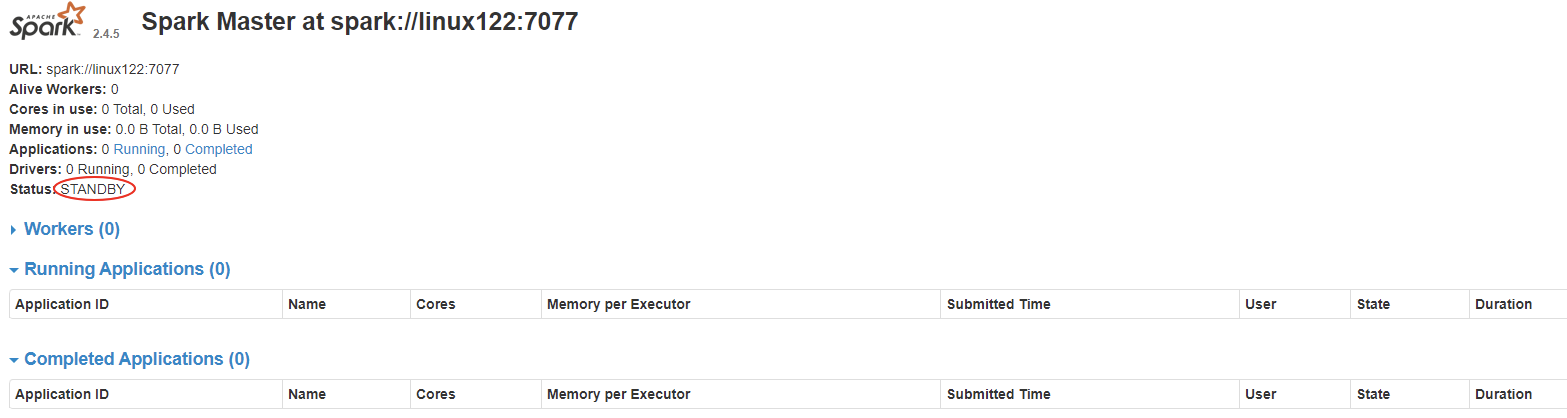
- 杀到linux121上 Master 进程,再观察 linux122 上 Master 状态,由 STANDBY=> RECOVERING => ALIVE
2.4.5 小结
- 配置每个worker的core、memory
- 运行模式:cluster、client;client缺省模式,有返回结果,适合调试;cluster与此相反
- History server
高可用(ZK、Local File;在ZK中记录集群的状态)
2.5 集群模式—Yarn模式
- 需要启动的服务:hdfs服务、yarn服务
- 需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二虎!
- 在Yarn模式中,Spark应用程序有两种运行模式:
- yarn-client。Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
- yarn-cluster。Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
- 二者的主要区别:Driver在哪里
- 关闭 Standalone 模式下对应的服务;开启 hdfs、yarn、historyserver 服务
修改 yarn-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn服务
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>备注:
- yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
- yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true
- 修改配置,分发到集群
```shell
spark-env.sh 中这一项必须要有
export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop
spark-default.conf(以下是优化)
与 hadoop historyserver集成
spark.yarn.historyServer.address linux121:18080
添加(以下是优化)
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar
将 $SPARK_HOME/jars 下的jar包上传到hdfs
hdfs dfs -mkdir -p /spark-yarn/jars/ cd $SPARK_HOME/jars hdfs dfs -put * /spark-yarn/jars/
- 测试
```shell
# client
spark-submit --master yarn \
--deploy-mode client \
--class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 2000
- 在提取App节点上可以看见:SparkSubmit、CoarseGrainedExecutorBackend
- 在集群的其他节点上可以看见:CoarseGrainedExecutorBackend
在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)
# cluster spark-submit --master yarn \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 2000在提取App节点上可以看见:SparkSubmit
- 在集群的其他节点上可以看见:CoarseGrainedExecutorBackend、ApplicationMaster(Driver运行在此)
- 在提取App节点上看不见最终的结果
整合HistoryServer服务
- 前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
- Hadoop:JobHistoryServer
Spark:HistoryServer
spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar \ 20
修改 spark-defaults.conf,并分发到集群 ```shell
修改 spark-defaults.conf
spark.master spark://linux121: 7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://linux121:9000/spark-eventlog spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 512m
新增
spark.yarn.historyServer.address linux121: 18080 spark.history.ui.port 18080
- 重启/启动 spark 历史服务
```shell
stop-history-server.sh
start-history-server.sh
提交任务
spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar \ 100Web页面查看日志(图见上)
- 备注:
- 在课程学习的过程中,大多数情况使用Standalone模式 或者 local模式
- 建议不使用HA;更多关注的Spark开发
2.6 开发环境搭建IDEA
- 前提:安装scala插件;能读写HDFS文件
pom.xml:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>LagouBigData</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.12.10</scala.version> <spark.version>2.4.5</spark.version> <hadoop.version>2.9.2</hadoop.version> <encoding>UTF-8</encoding> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <!-- 编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <!-- 编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler- plugin</artifactId> <version>3.5.1</version> </plugin> </plugins> </pluginManagement> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <executions> <execution> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <!-- 打jar插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META- INF/*.SF</exclude> <exclude>META- INF/*.DSA</exclude> <exclude>META- INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>```scala package cn.lagou.sparkcore import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster(“local”).setAppName(“WordCount”) val sc = new SparkContext(conf)
// val lines: RDD[String] = sc.textFile("hdfs://linux121:9000/wcinput/wc.txt")
val lines: RDD[String] = sc.textFile("/wcinput/wc.txt")
// val lines: RDD[String] = sc.textFile("data/wc.dat")
lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println)
sc.stop()
} } ```
- 备注:core-site.xml;链接源码;

若有收获,就点个赞吧
0 人点赞
