3.1 什么是RDD
- RDD 是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
- RDD(Resilient Distributed Dataset)是 Spark 中的核心概念,它是一个容错、可以并行执行的分布式数据集。

RDD包含 5 个特征:
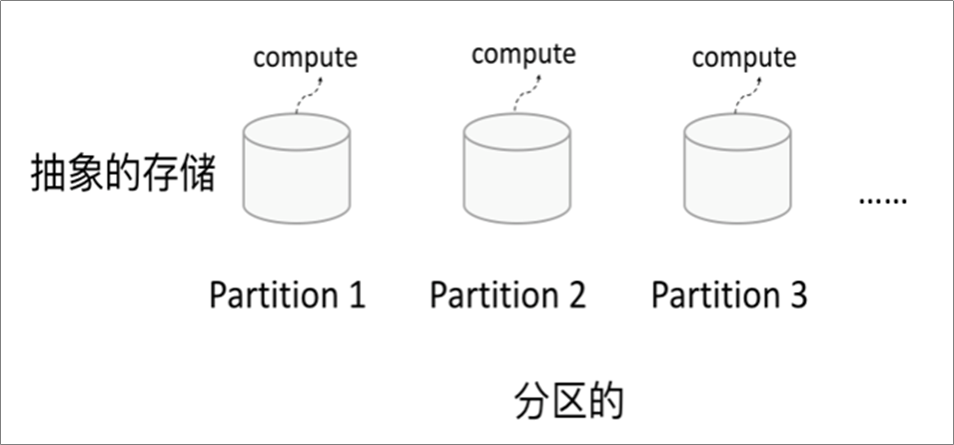
RDD逻辑上是分区的 ,每个分区的数据是 抽象存在 的,计算的时候会通过一个compute 函数得到每个分区的数据。如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
-
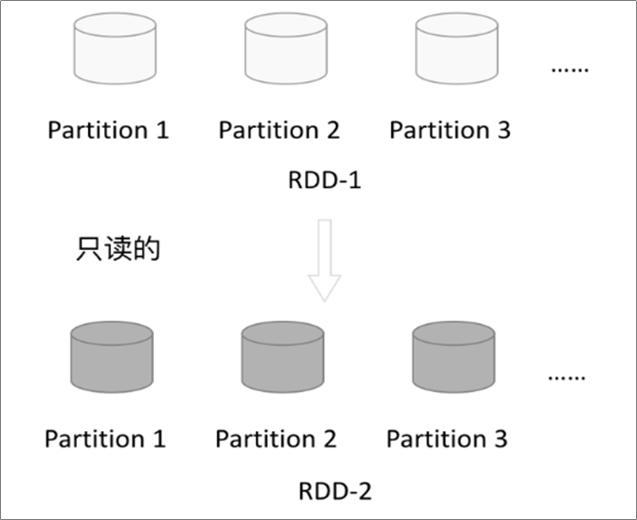
3.2.2 只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD;
- 一个RDD转换为另一个RDD,通过丰富的操作算子(map、filter、union、join、reduceByKey… …)实现,不再像MR那样只能写map和reduce了。
RDD的操作算子包括两类:
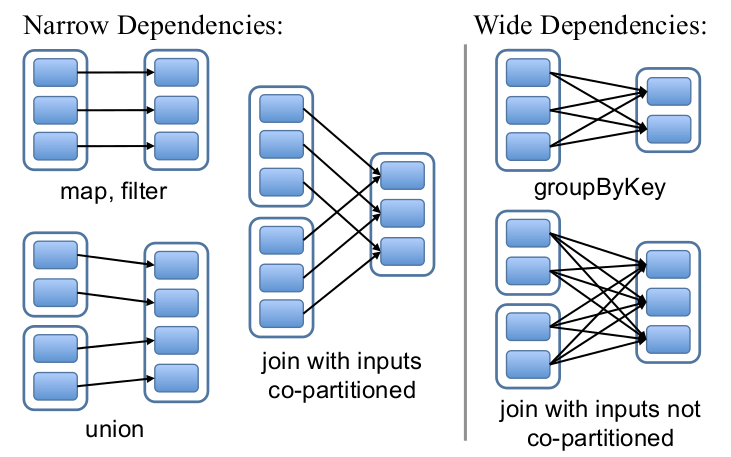
RDDs通过操作算子进行转换,转换得到的新RDD包含了从其他RDDs衍生所必需的信息,RDDs之间维护着这种血缘关系(lineage),也称之为依赖。依赖包括两种:
- 窄依赖。RDDs之间分区是一一对应的(1:1 或 n:1)
- 宽依赖。子RDD每个分区与父RDD的每个分区都有关,是多对多的关系(即n:m) 。有shuffle发生
-
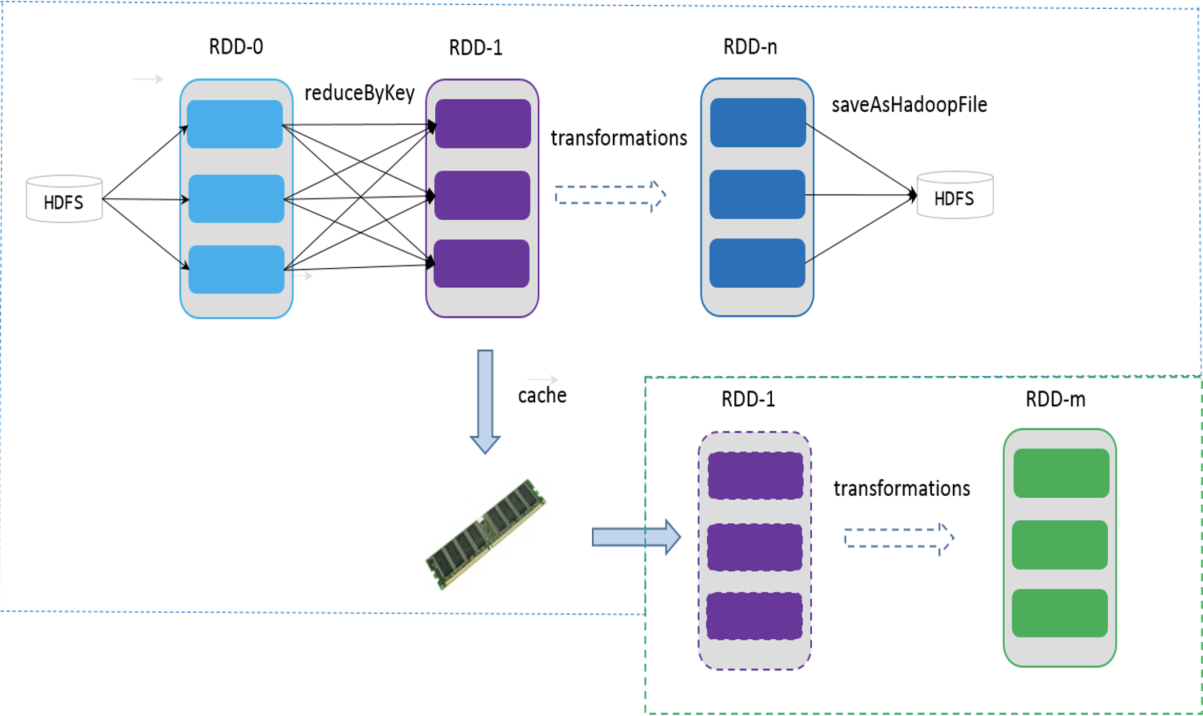
3.2.4 缓存
可以控制存储级别(内存、磁盘等)来进行缓存。
- 如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
3.2.5 checkpoint
- 虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。
- 但是于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。
RDD支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从 checkpoint 处拿到数据。
3.3 Spark编程模型
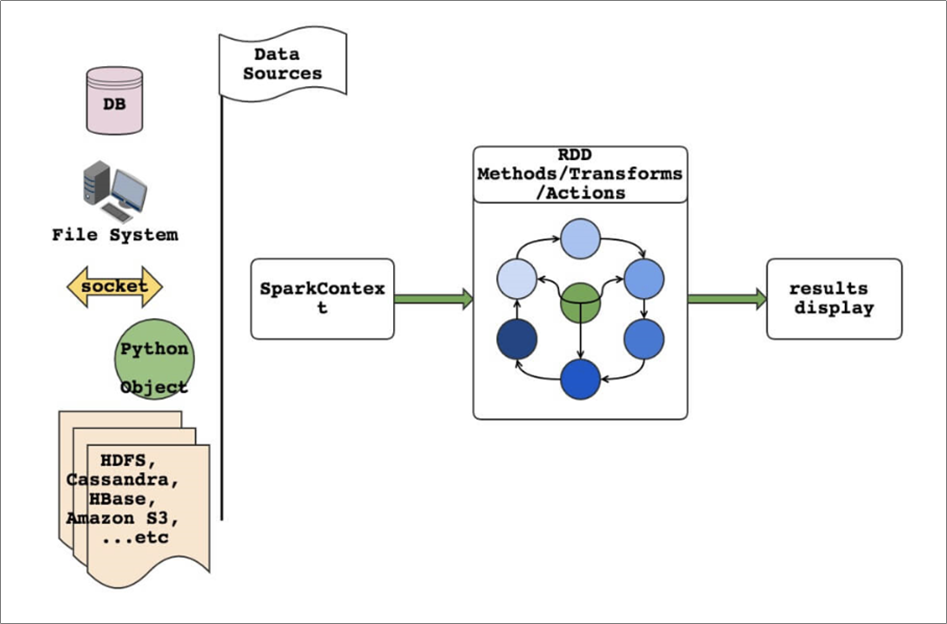
RDD表示数据对象
- 通过对象上的方法调用来对RDD进行转换
- 最终显示结果 或 将结果输出到外部数据源
- RDD转换算子称为Transformation是Lazy的(延迟执行)
- 只有遇到Action算子,才会执行RDD的转换操作
要使用Spark,需要编写 Driver 程序,它被提交到集群运行
SparkContext是编写Spark程序用到的第一个类,是Spark的主要入口点,它负责和整个集群的交互;
- 如把Spark集群当作服务端,那么Driver就是客户端,SparkContext 是客户端的核心;
- SparkContext是Spark的对外接口,负责向调用者提供 Spark 的各种功能;
- SparkContext用于连接Spark集群、创建RDD、累加器、广播变量;
- 在 spark-shell 中 SparkContext 已经创建好了,可直接使用;
- 编写Spark Driver程序第一件事就是:创建SparkContext;
建议:Standalone模式或本地模式学习RDD的各种算子;不需要HA;不需要IDEA
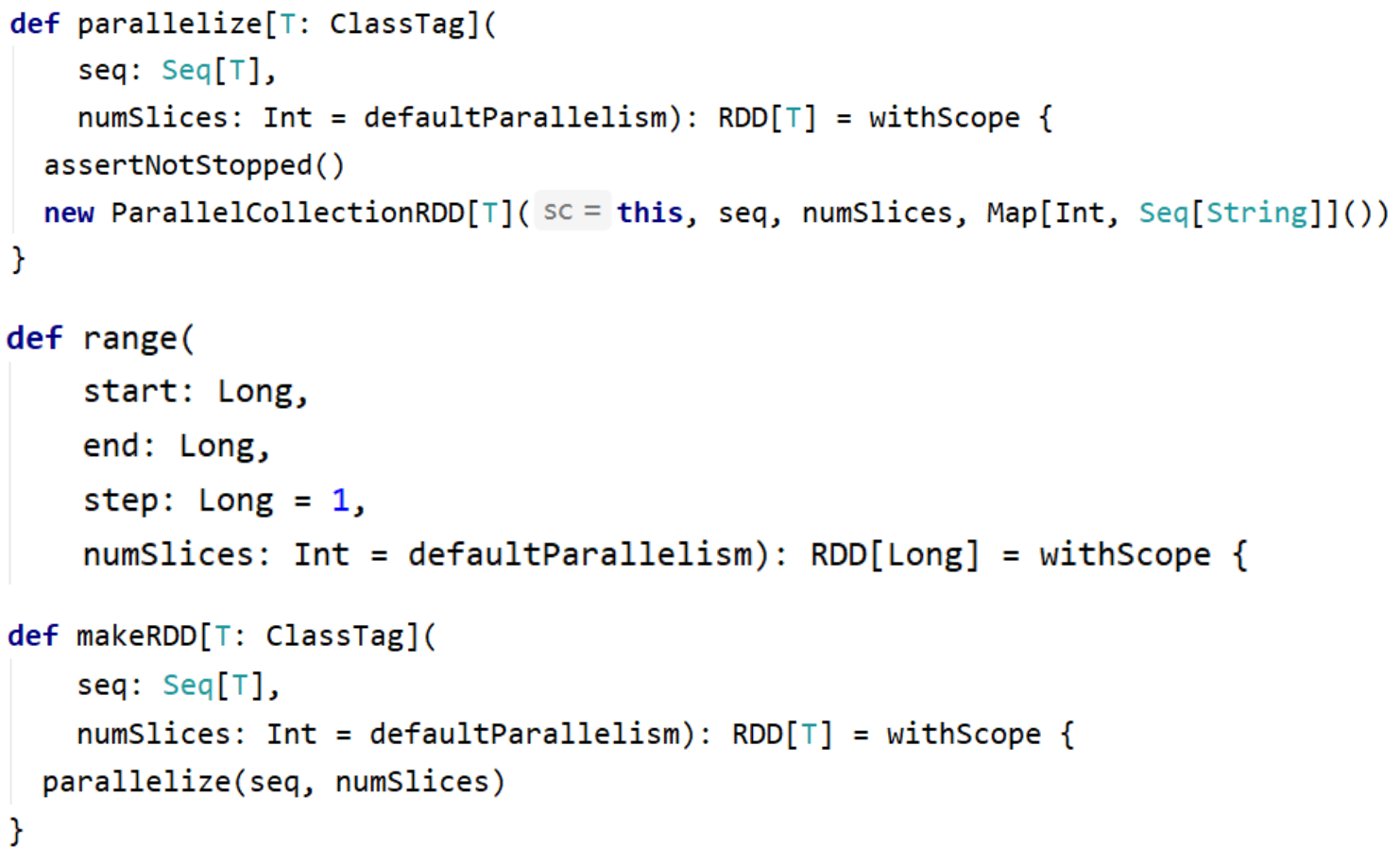
3.4.2 从集合创建RDD
从集合中创建RDD,主要用于测试。Spark 提供了以下函数:parallelize、makeRDD、range
 ```scala
val rdd1 = sc.parallelize(Array(1,2,3,4,5))
val rdd2 = sc.parallelize(1 to 100)
```scala
val rdd1 = sc.parallelize(Array(1,2,3,4,5))
val rdd2 = sc.parallelize(1 to 100)
// 检查 RDD 分区数 rdd2.getNumPartitions rdd2.partitions.length
// 创建 RDD,并指定分区数 val rdd2 = sc.parallelize(1 to 100) rdd2.getNumPartitions val rdd3 = sc.makeRDD(List(1,2,3,4,5)) val rdd4 = sc.makeRDD(1 to 100) rdd4.getNumPartitions val rdd5 = sc.range(1, 100, 3) rdd5.getNumPartitions val rdd6 = sc.range(1, 100, 2 ,10) rdd6.getNumPartitions
- 备注:rdd.collect 方法在生产环境中不要使用,会造成Driver OOM<a name="FD1js"></a>## 3.4.3 从文件系统创建RDD- 用 textFile() 方法来从文件系统中加载数据创建RDD。方法将文件的 URI 作为数,这个URI可以是:- 本地文件系统- 使用本地文件系统要注意:该文件是不是在所有的节点存在(在Standalone模式下)- 分布式文件系统HDFS的地址- Amazon S3的地址```scala// 从本地文件系统加载数据val lines = sc.textFile("file:///root/data/wc.txt")// 从分布式文件系统加载数据val lines = sc.textFile("hdfs://linux121:9000/user/root/data/uaction.dat")val lines = sc.textFile("/user/root/data/uaction.dat")val lines = sc.textFile("data/uaction.dat")
3.4.4 从RDD创建RDD
本质是将一个RDD转换为另一个RDD。详细信息参见 3.5 Transformation
3.5 Transformation【重要】
RDD的操作算子分为两类:
- Transformation。用来对RDD进行转化,这个操作时延迟执行的(或者说是Lazy 的);
- Action。用来触发RDD的计算;得到相关计算结果 或者 将结果保存的外部系统中;
- Transformation:返回一个新的RDD
- Action:返回结果int、double、集合(不会返回新的RDD)
要很准确区分Transformation、Action
每一次 Transformation 操作都会产生新的RDD,供给下一个“转换”使用;
- 转换得到的RDD是惰性求值的。也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到 Action 操作时,才会发生真正的计算,开始从血缘关系(lineage)源头开始,进行物理的转换操作;
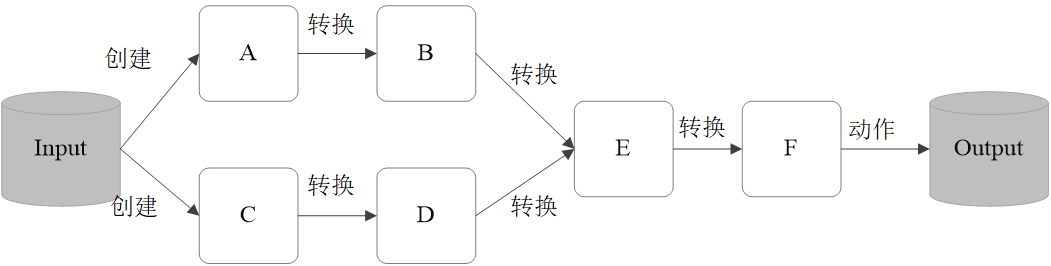
常见的 Transformation 算子:
map(func) :对数据集中的每个元素都使用func,然后返回一个新的RDD
- filter(func) :对数据集中的每个元素都使用func,然后返回一个包含使func为true的元素构成的RDD
- flatMap(func) :与 map 类似,每个输入元素被映射为 0 或多个输出元素
- mapPartitions(func) :和map很像,但是map是将func作用在每个元素上,而mapPartitions是func作用在整个分区上。假设一个RDD有N个元素,M个分区(N>> M),那么map的函数将被调用N次,而mapPartitions中的函数仅被调用M次,一次处理一个分区中的所有元素
- mapPartitionsWithIndex(func) :与 mapPartitions 类似,多了分区的索引值的信息
- 全部都是窄依赖 ```scala val rdd1 = sc.parallelize(1 to 10) val rdd2 = rdd1.map(*2) val rdd3 = rdd2.filter(>10)
// 以上都是 Transformation 操作,没有被执行。如何证明这些操作按预期执行,此时 需要引入Action算子 rdd2.collect rdd3.collect // collect 是Action算子,触发Job的执行,将RDD的全部元素从 Executor 搜集到 Driver 端。生产环境中禁用
// flatMap 使用案例 val rdd4 = sc.textFile(“data/wc.txt”) rdd4.collect rdd4.flatMap(_.split(“\s+”)).collect
// RDD 是分区,rdd1有几个区,每个分区有哪些元素 rdd1.getNumPartitions rdd1.partitions.length
rdd1.mapPartitions{ iter => Iterator(s”${iter.toList}”) }.collect rdd1.mapPartitions{ iter => Iterator(s”${iter.toArray.mkString(“-“)}”) }.collect rdd1.mapPartitionsWithIndex{ (idx, iter) => Iterator(s”$idx:${iter.toArray.mkString(“-“)}”) }.collect
// 每个元素 2 val rdd5 = rdd1.mapPartitions(iter => iter.map(_2)) rdd5.collect
- map 与 mapPartitions 的区别
- map:每次处理一条数据
- mapPartitions:每次处理一个分区的数据,分区的数据处理完成后,数据才能释放,资源不足时容易导致OOM
- 最佳实践:当内存资源充足时,建议使用mapPartitions,以提高处理效率
<a name="qLKM8"></a>
## 常见转换算子 2
- groupBy(func): 按照传入函数的返回值进行分组。将key相同的值放入一个迭代器
- glom(): 将每一个分区形成一个数组,形成新的RDD类型 RDD[Array[T]]
- sample(withReplacement, fraction, seed): 采样算子。以指定的随机种子(seed)随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样
- distinct([numTasks])): 对RDD元素去重后,返回一个新的RDD。可传入numTasks参数改变RDD分区数
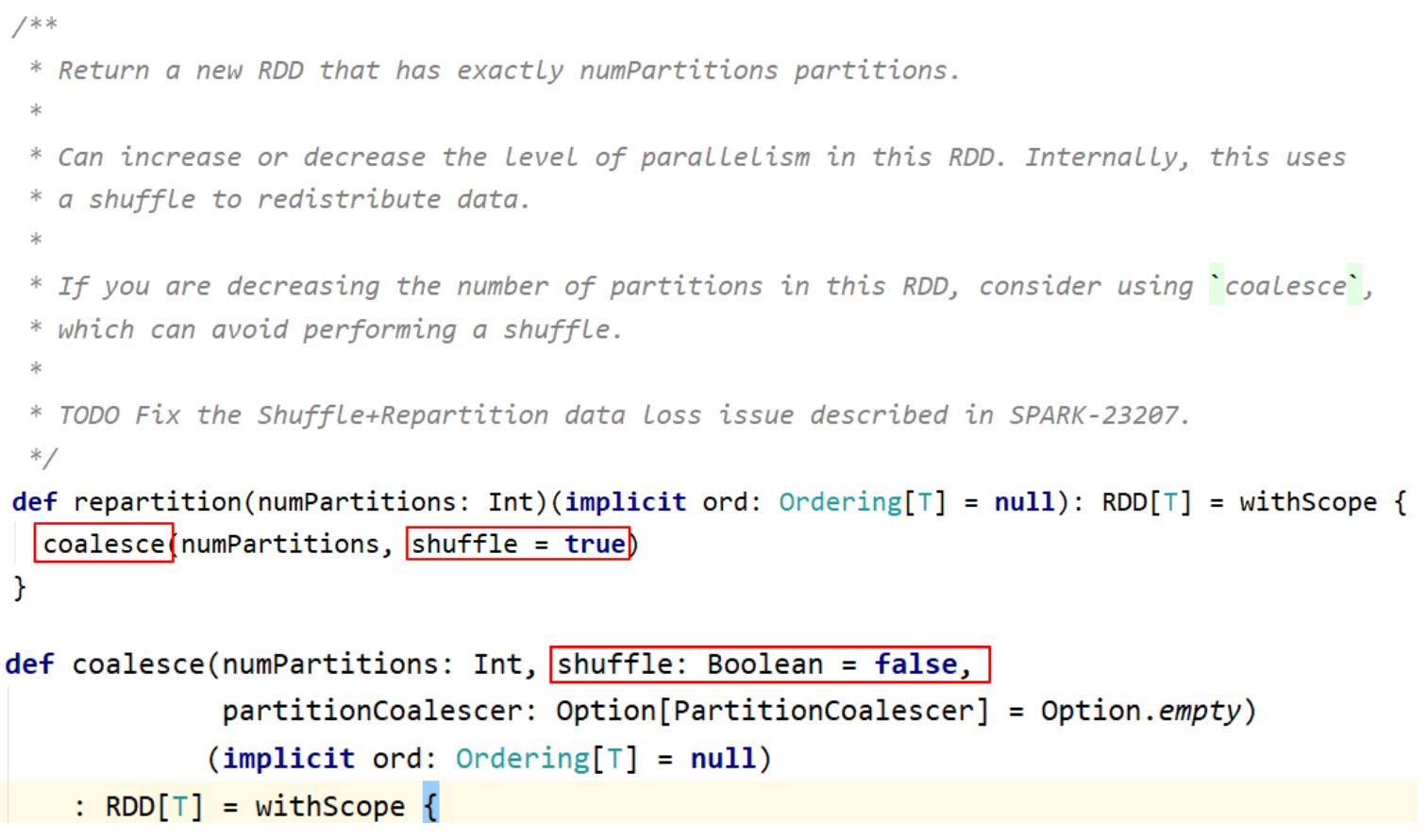
- coalesce(numPartitions): 缩减分区数,无shuffle
- repartition(numPartitions): 增加或减少分区数,有shuffle
- sortBy(func, [ascending], [numTasks]): 使用 func 对数据进行处理,对处理后的结果进行排序
- 宽依赖的算子(shuffle):groupBy、distinct、repartition、sortBy
```scala
// 将 RDD 中的元素按照3的余数分组
val rdd = sc.parallelize(1 to 10)
val group = rdd.groupBy(_%3)
group.collect
// 将 RDD 中的元素每10个元素分组
val rdd = sc.parallelize(1 to 101)
rdd.glom.map(_.sliding(10, 10).toArray) // sliding是Scala中的方法
// 对数据采样。fraction采样的百分比,近似数
// 有放回的采样,使用固定的种子
rdd.sample(true, 0.2, 2).collect
// 无放回的采样,使用固定的种子
rdd.sample(false, 0.2, 2).collect
// 有放回的采样,不设置种子
rdd.sample(false, 0.2).collect
// 数据去重
val random = scala.util.Random
val arr = (1 to 20).map(x => random.nextInt(10))
val rdd = sc.makeRDD(arr)
rdd.distinct.collect
// RDD重分区
val rdd1 = sc.range(1, 10000, numSlices=10)
val rdd2 = rdd1.filter(_%2==0)
rdd2.getNumPartitions
// 减少分区数;都生效了
val rdd3 = rdd2.repartition(5)
rdd3.getNumPartitions
val rdd4 = rdd2.coalesce(5)
rdd4.getNumPartitions
// 增加分区数
val rdd5 = rdd2.repartition(20)
rdd5.getNumPartitions
// 增加分区数,这样使用没有效果
val rdd6 = rdd2.coalesce(20)
rdd6.getNumPartitions
// 增加分区数的正确用法
val rdd6 = rdd2.coalesce(20, true)
rdd6.getNumPartitions
// RDD元素排序
val random = scala.util.Random
val arr = (1 to 20).map(x => random.nextInt(10))
val rdd = sc.makeRDD(arr)
rdd.collect
// 数据全局有序,默认升序
rdd.sortBy(x=>x).collect
// 降序
rdd.sortBy(x=>x,false).collect
- coalesce 与 repartition 的区别
小结:
RDD之间的交、并、差算子,分别如下:
- intersection(otherRDD)
- union(otherRDD)
- subtract (otherRDD)
- cartesian(otherRDD) :笛卡尔积
- zip(otherRDD) :将两个RDD组合成 key-value 形式的RDD,默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
- 宽依赖的算子(shuffle):intersection、subtract 、cartesian ```scala val rdd1 = sc.range(1, 21) val rdd2 = sc.range(10, 31) rdd1.intersection(rdd2).sortBy(x=>x).collect
// 元素求并集,不去重 rdd1.union(rdd2).sortBy(x=>x).collect rdd1.subtract(rdd2).sortBy(x=>x).collect
// 检查分区数 rdd1.intersection(rdd2).getNumPartitions rdd1.union(rdd2).getNumPartitions rdd1.subtract(rdd2).getNumPartitions
// 笛卡尔积 val rdd1 = sc.range(1, 5) val rdd2 = sc.range(6, 10) rdd1.cartesian(rdd2).collect
// 检查分区数 rdd1.cartesian(rdd2).getNumPartitions
// 拉链操作 rdd1.zip(rdd2).collect rdd1.zip(rdd2).getNumPartitions // zip操作要求:两个RDD的partition数量以及元素数量都相同,否则会抛出异常 val rdd2 = sc.range(6, 20) rdd1.zip(rdd2).collect
- 备注:
- union是窄依赖。得到的RDD分区数为:两个RDD分区数之和
- cartesian是窄依赖。得到的RDD分区数为:两个RDD分区数之积。慎用
<a name="C9oSP"></a>
# 3.6 Action
- Action 用来触发RDD的计算,得到相关计算结果;
- Action触发Job。一个Spark程序(Driver程序)包含了多少 Action算子,那么就有多少Job;
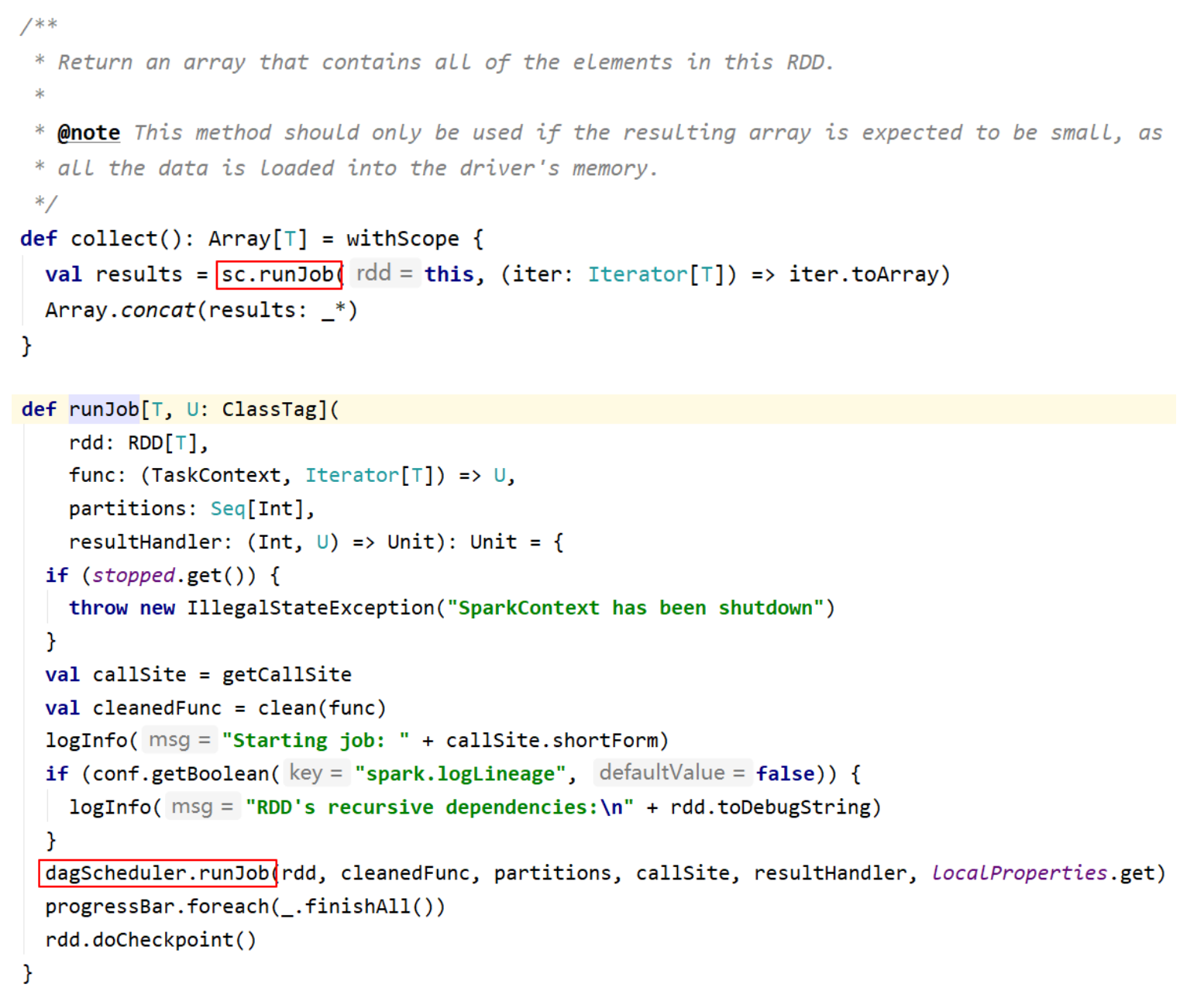
- 典型的Action算子: collect / count
- collect() => sc.runJob() => ... => dagScheduler.runJob() => 触发了 Job
- 要求:能快速准确的区分:Transformation、Action
- collect() / collectAsMap()
- stats / count / mean / stdev / max / min
- reduce(func) / fold(func) / aggregate(func)

- first() :Return the first element in this RDD
- take(n) :Take the first num elements of the RDD
- top(n): 按照默认(降序)或者指定的排序规则,返回前num个元素。
- takeSample(withReplacement, num, [seed]) :返回采样的数据
- foreach(func) / foreachPartition(func) :与map、mapPartitions类似,区别是foreach 是 Action
- saveAsTextFile(path) / saveAsSequenceFile(path) / saveAsObjectFile(path)
```scala
// 返回统计信息。仅能作用 RDD[Double] 类型上调用
val rdd1 = sc.range(1, 101)
rdd1.stats
val rdd2 = sc.range(1, 101)
// 不能调用
rdd1.zip(rdd2).stats
// count在各种类型的RDD上,均能调用
rdd1.zip(rdd2).count
// 聚合操作
val rdd = sc.makeRDD(1 to 10, 2)
rdd.reduce(_+_)
rdd.fold(0)(_+_)
rdd.fold(1)(_+_)
rdd.fold(1)((x, y) => { println(s"x=$x, y=$y") x+y })
rdd.aggregate(0)(_+_, _+_)
rdd.aggregate(1)(_+_, _+_)
rdd.aggregate(1)(
(a, b) => {
println(s"a=$a, b=$b")
a+b
},
(x, y) => {
println(s"x=$x, y=$y")
x+y
})
// first / take(n) / top(n) :获取RDD中的元素。多用于测试
rdd.first
rdd.take(10)
rdd.top(10)
// 采样并返回结果
rdd.takeSample(false, 5)
// 保存文件到指定路径(rdd有多少分区,就保存为多少文件,保存文件时注意小文件问题)
rdd.saveAsTextFile("data/t1")
3.7 Key-Value RDD操作
- RDD整体上分为 Value 类型和 Key-Value 类型。
- 前面介绍的是 Value 类型的RDD的操作,实际使用更多的是 key-value 类型的RDD,也称为 PairRDD。
- Value 类型RDD的操作基本集中在 RDD.scala 中;
- key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;
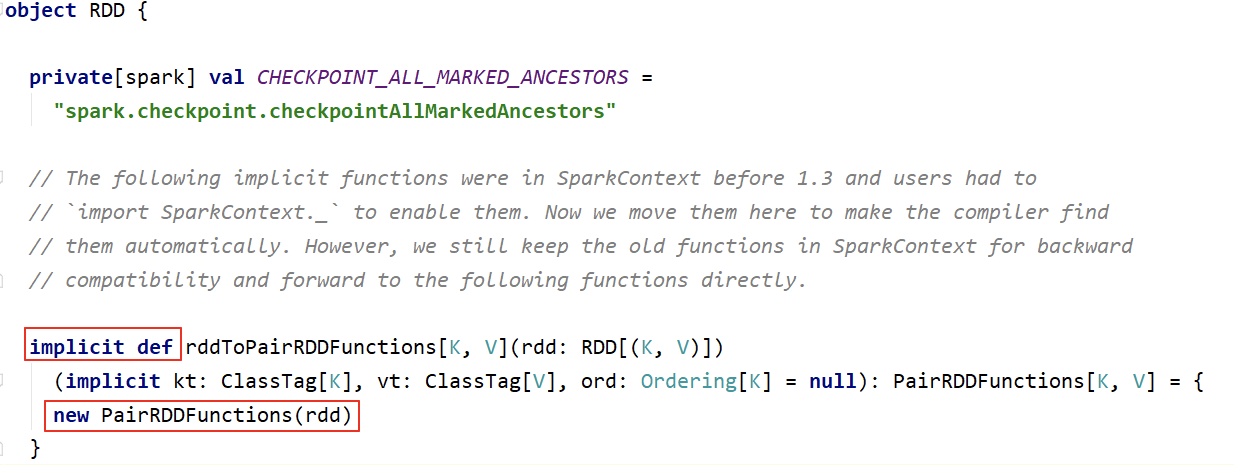
- 前面介绍的大多数算子对 Pair RDD 都是有效的。Pair RDD还有属于自己的Transformation、Action 算子;
3.7.1 创建Pair RDD
```scala val arr = (1 to 10).toArray val arr1 = arr.map(x => (x, x10, x100))
// rdd1 不是 Pair RDD val rdd1 = sc.makeRDD(arr1) // rdd2 是 Pair RDD val arr2 = arr.map(x => (x, (x10, x100))) val rdd2 = sc.makeRDD(arr2)
<a name="b39Mn"></a>
## 3.7.2 Transformation操作
<a name="c6062488"></a>
### 1 类似 map 操作
- mapValues / flatMapValues / keys / values,这些操作都可以使用 map 操作实现,是简化操作。
```scala
val a = sc.parallelize(List((1,2),(3,4),(5,6)))
// 使用 mapValues 更简洁
val b = a.mapValues(x=>1 to x)
b.collect
// 可使用map实现同样的操作
val b = a.map(x => (x._1, 1 to x._2))
b.collect
val b = a.map{case (k, v) => (k, 1 to v)}
b.collect
// flatMapValues 将 value 的值压平
val c = a.flatMapValues(x=>1 to x)
c.collect
val c = a.mapValues(x=>1 to x).flatMap{case (k, v) => v.map(x => (k, x))}
c.collect
c.keys
c.values
c.map{case (k, v) => k}.collect
c.map{case (k, _) => k}.collect
c.map{case (_, v) => v}.collect
2 聚合操作【重要、难点】
- PariRDD(k, v)使用范围广,聚合
- groupByKey / reduceByKey / foldByKey / aggregateByKey
- combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现
subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的素
小案例:给定一组数据:(“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”,15), (“scala”, 26), (“spark”, 25), (“spark”, 23), (“hadoop”, 16), (“scala”, 24), (“spark”,16), 键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均值,也就是计算每种图书的每天平均销量。 ```scala val rdd = sc.makeRDD(Array((“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”, 15), (“scala”, 26), (“spark”, 25), (“spark”, 23), (“hadoop”, 16), (“scala”, 24), (“spark”, 16)))
// groupByKey rdd.groupByKey().map(x=>(x._1, x._2.sum.toDouble/x._2.size)).collect rdd.groupByKey().map{case (k, v) => (k, v.sum.toDouble/v.size)}.collect rdd.groupByKey.mapValues(v => v.sum.toDouble/v.size).collect
// reduceByKey rdd.mapValues((_, 1)).reduceByKey( (x, y)=> (x._1+y._1, x._2+y._2) ). mapValues(x => (x._1.toDouble / x._2)). collect()
// foldByKey rdd.mapValues((_, 1)).foldByKey((0, 0)) ( (x, y) => { (x._1+y._1, x._2+y._2) } ).mapValues(x=>x._1.toDouble/x._2).collect
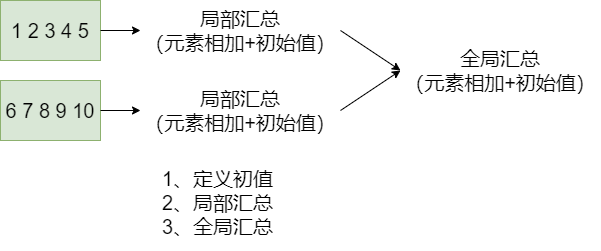
// aggregateByKey // aggregateByKey => 定义初值 + 分区内的聚合函数 + 分区间的聚合函数 rdd.mapValues((_, 1)).aggregateByKey((0,0)) ( (x, y) => (x._1 + y._1, x._2 + y._2), (a, b) => (a._1 + b._1, a._2 + b._2) ).mapValues(x=>x._1.toDouble / x._2). collect
// 初值(元祖)与RDD元素类型(Int)可以不一致 rdd.aggregateByKey((0, 0)) ( (x, y) => {println(s”x=$x, y=$y”); (x._1 + y, x._2 + 1)}, (a, b) => {println(s”a=$a, b=$b”); (a._1 + b._1, a._2 + b._2)} ).mapValues(x=>x._1.toDouble/x._2).collect
// 分区内的合并与分区间的合并,可以采用不同的方式;这种方式是低效的! rdd.aggregateByKey(scala.collection.mutable.ArrayBufferInt) ( (x, y) => {x.append(y); x}, (a, b) => {a++b} ).mapValues(v => v.sum.toDouble/v.size).collect
// combineByKey(理解就行) rdd.combineByKey( (x: Int) => {println(s”x=$x”); (x,1)}, (x: (Int, Int), y: Int) => {println(s”x=$x, y=$y”);(x._1+y, x._2+1)}, (a: (Int, Int), b: (Int, Int)) => {println(s”a=$a, b=$b”); (a._1+b._1, a._2+b._2)} ).mapValues(x=>x._1.toDouble/x._2).collect
// subtractByKey val rdd1 = sc.makeRDD(Array((“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”, 15))) val rdd2 = sc.makeRDD(Array((“spark”, 100), (“hadoop”, 300))) rdd1.subtractByKey(rdd2).collect()
// subtractByKey val rdd = sc.makeRDD(Array((“a”,1), (“b”,2), (“c”,3), (“a”,5), (“d”,5))) val other = sc.makeRDD(Array((“a”,10), (“b”,20), (“c”,30))) rdd.subtractByKey(other).collect()
- 结论:效率相等用最熟悉的方法;groupByKey在一般情况下效率低,尽量少用
- 初学:最重要的是实现;如果使用了groupByKey,寻找替换的算子实现;
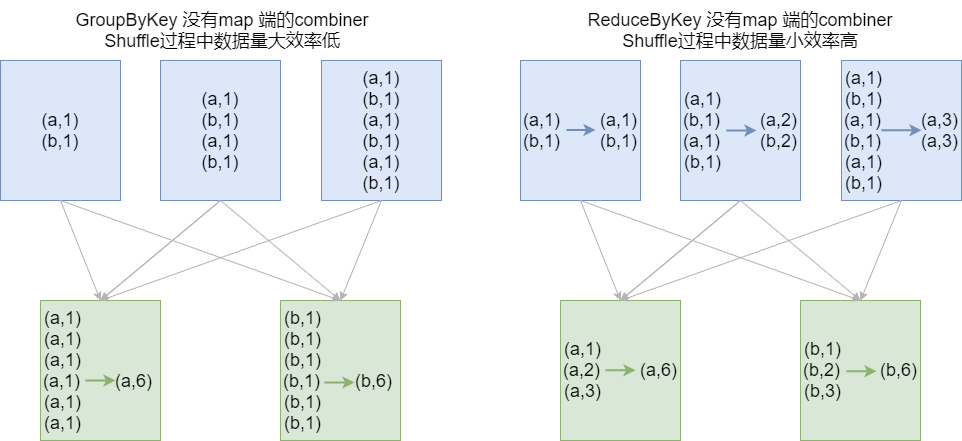
- groupByKey Shuffle过程中传输的数据量大,效率低
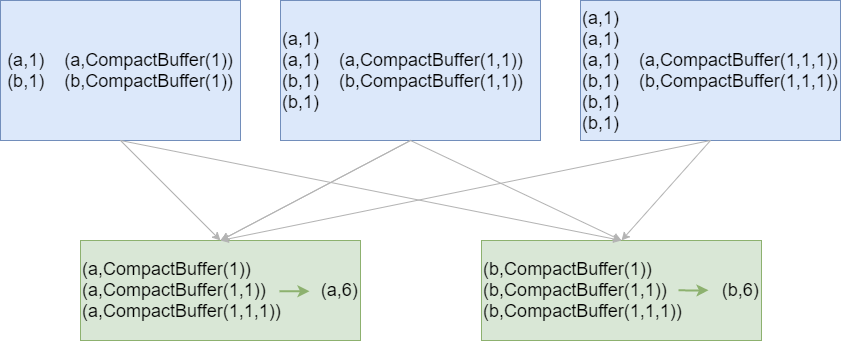
<a name="2adf5001"></a>
### 3 排序操作
- sortByKey:sortByKey函数作用于PairRDD,对Key进行排序。在org.apache.spark.rdd.OrderedRDDFunctions 中实现:
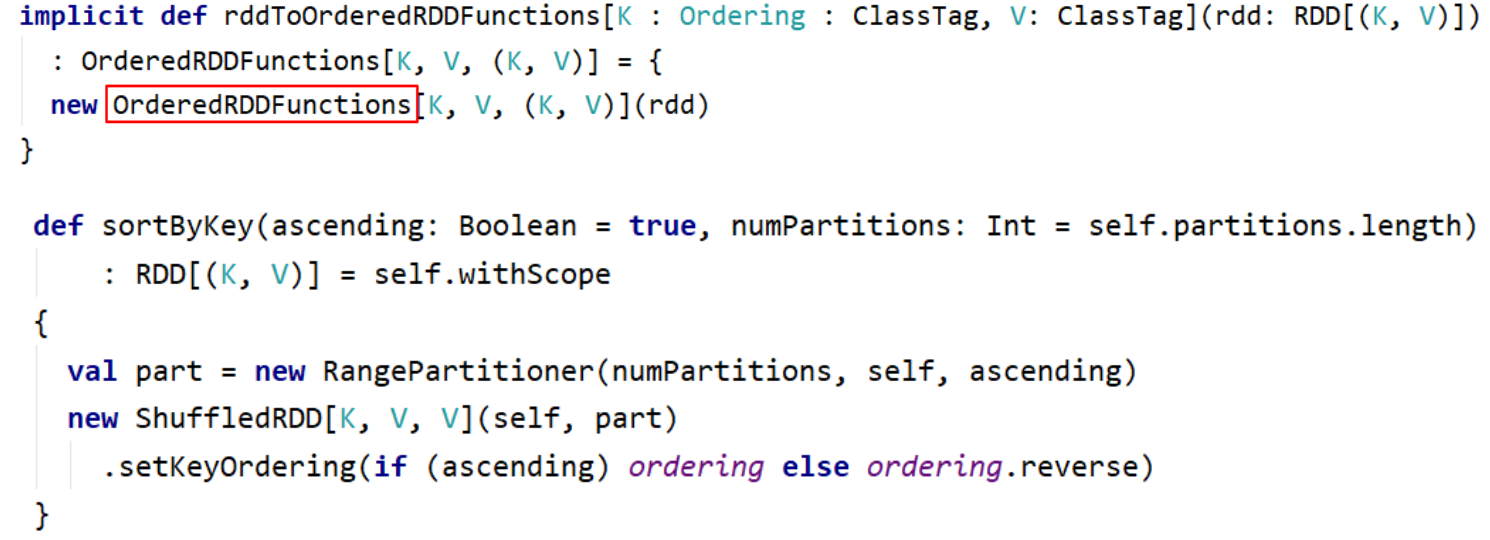
```scala
val a = sc.parallelize(List("wyp", "iteblog", "com", "397090770", "test"))
val b = sc.parallelize (1 to a.count.toInt)
val c = a.zip(b)
c.sortByKey().collect
c.sortByKey(false).collect
4 join操作
- cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin

val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"), (3,"Kylin"), (4,"Flink")))
val rdd2 = sc.makeRDD(Array((3,"李四"), (4,"王五"), (5,"赵六"), (6,"冯七")))
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect.foreach(println)
rdd3.filter{case (_, (v1, v2)) => v1.nonEmpty & v2.nonEmpty}.collect
// 仿照源码实现join操作
rdd3.flatMapValues( pair => for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w))
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"), ("3","Scala"),("4","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),("5","25K"), ("6","10K")))
rdd1.join(rdd2).collect
rdd1.leftOuterJoin(rdd2).collect
rdd1.rightOuterJoin(rdd2).collect
rdd1.fullOuterJoin(rdd2).collect
3.7.3 Action操作
- collectAsMap / countByKey / lookup(key)
- countByKey源码:

- lookup(key):高效的查找方法,只查找对应分区的数据(如果RDD有分区器的话)
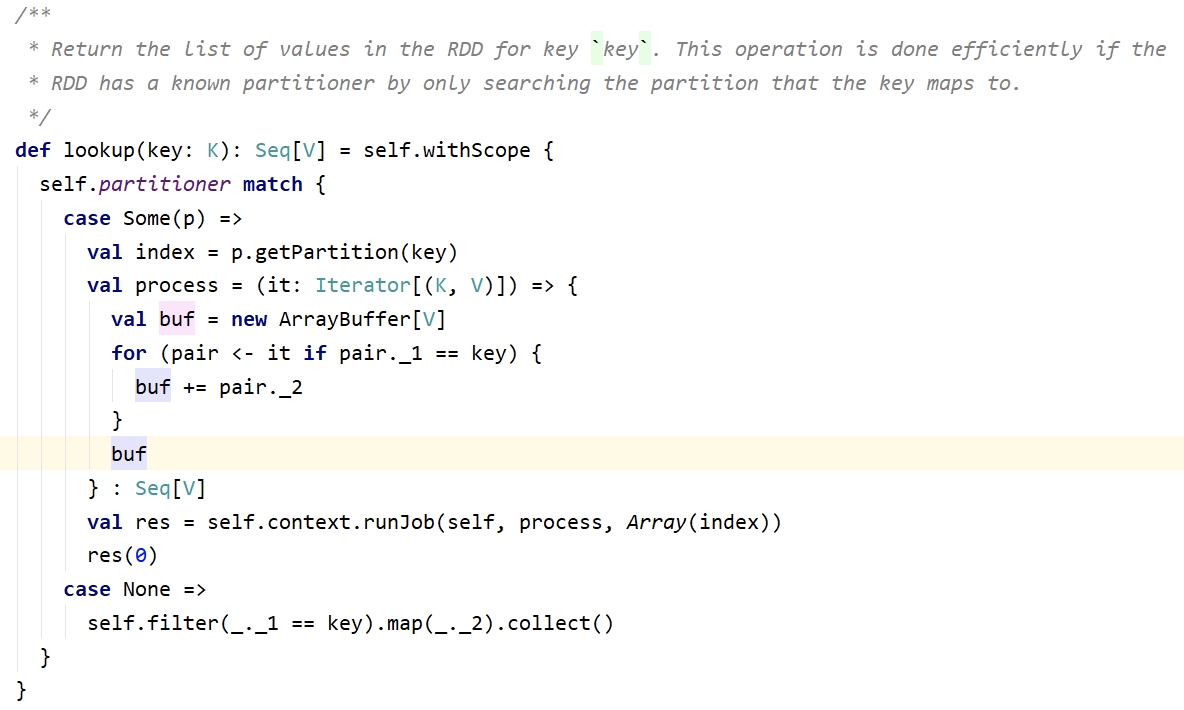
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"),("3","Scala"),("1","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),("5","25K"),("6","10K")))
rdd1.lookup("1")
rdd2.lookup("3")
3.8 输入与输出
3.8.1 文件输入与输出
1 文本文件
- 数据读取:textFile(String)。可指定单个文件, 支持通配符。
- 这样对于大量的小文件读取效率并不高,应该使用 wholeTextFiles
- def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions):RDD[(String, String)])
- 返回值RDD[(String, String)], 其中Key是文件的名称,Value是文件的内容
数据保存:saveAsTextFile(String)。指定的输出目录。
2 csv文件
读取 CSV(Comma-Separated Values)/TSV(Tab-Separated Values) 数据和读取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一行进行解析实现对CSV的读取。
CSV/TSV 数据的输出也是需要将结构化RDD通过相关的库转换成字符串RDD,然后使用 Spark 的文本文件 API 写出去。
3 json文件
如果 JSON 文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。
- JSON数据的输出主要是通过在输出之前将由结构化数据组成的 RDD 转为字符串RDD,然后使用 Spark 的文本文件 API 写出去。
-
4 SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。 Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext中,可以调用:sequenceFile[keyClass, valueClass];
调用 saveAsSequenceFile(path) 保存PairRDD,系统将键和值能够自动转为Writable类型。
5 对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
通过objectFilek,v接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指定类型。
3.8.2 JDBC
-
3.9 算子综合应用案例
1 WordCount - scala
备注:打包上传服务器运行 ```scala package cn.lagou.sparkcore import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object ScalaWordCount { def main(args: Array[String]): Unit = { // 1、创建SparkContext val conf = new SparkConf().setAppName(“WordCount”) val sc = new SparkContext(conf) sc.setLogLevel(“WARN”)
// 2、读本地文件(集群运行:输入参数)
val lines: RDD[String] = sc.textFile(args(0))
// 3、RDD转换
val words: RDD[String] = lines.flatMap(line => line.split("\\s+"))
val wordsMap: RDD[(String, Int)] = words.map(x => (x, 1))
val result: RDD[(String, Int)] = wordsMap.reduceByKey(_ + _)
// 4、输出
result.foreach(println)
// 5、关闭SparkContext
sc.stop()
// 6、打包,使用spark-submit提交集群运行
// spark-submit --master local[*] --class cn.lagou.sparkcore.WordCount \
// original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
// spark-submit --master yarn --class cn.lagou.sparkcore.WordCount \
// original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
} }
<a name="uFQK9"></a>
## 2 WordCount - java
- Spark提供了:Scala、Java、Python、R语言的API;
- 对 Scala 和 Java 语言的支持最好;
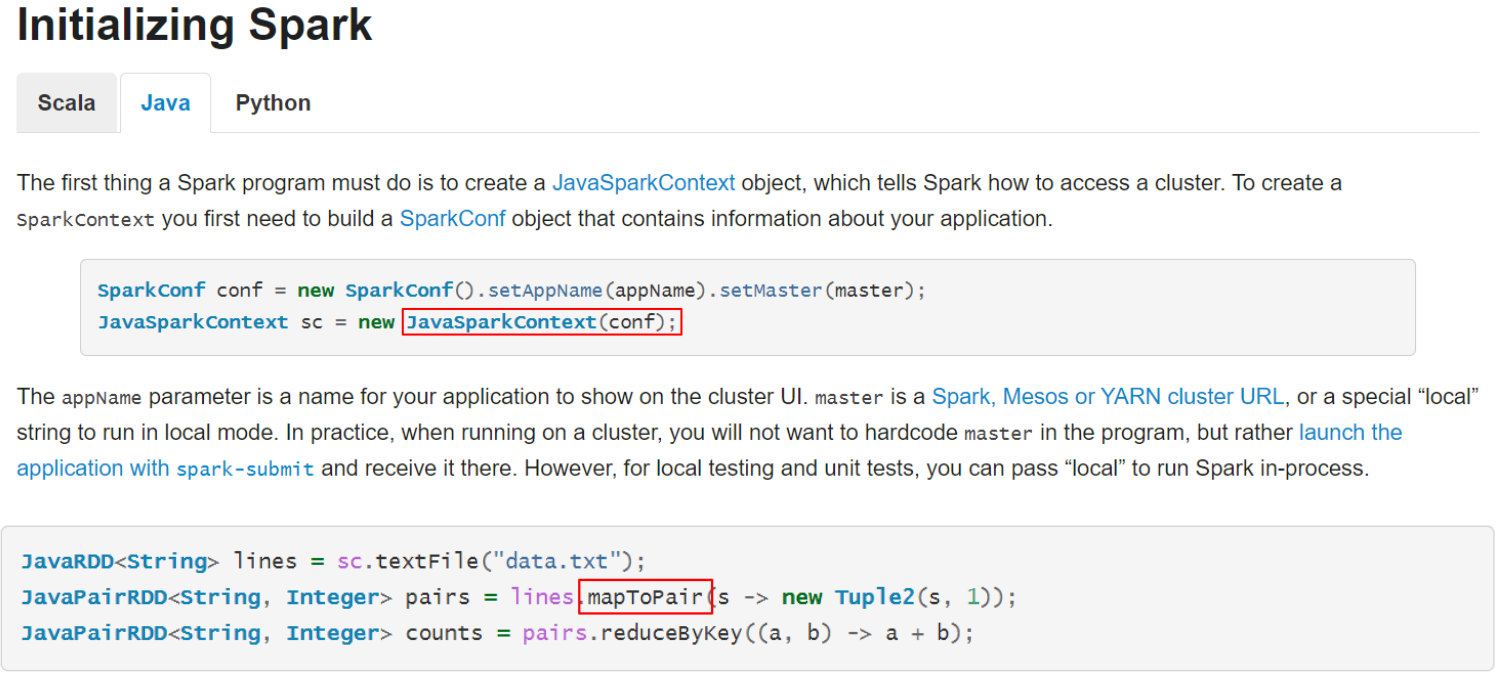
```scala
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class JavaWordCount {
public static void main(String[] args) {
// 1 创建 JavaSparkContext
SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local[*]");
JavaSparkContext jsc = new JavaSparkContext(conf);
jsc.setLogLevel("warn");
// 2 生成RDD
JavaRDD<String> lines = jsc.textFile("file:///C:\\Project\\LagouBigData\\data\\wc.txt");
// 3 RDD转换
JavaRDD<String> words = lines.flatMap(line -> Arrays.stream(line.split("\\s+")).iterator());
JavaPairRDD<String, Integer> wordsMap = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> results = wordsMap.reduceByKey((x, y) -> x + y);
// 4 结果输出
results.foreach(elem -> System.out.println(elem));
// 5 关闭SparkContext
jsc.stop();
}
}
- 备注:
 ```scala
package cn.lagou.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
import scala.math.random
```scala
package cn.lagou.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
import scala.math.random object SparkPi { def main(args: Array[String]): Unit = { // 1、创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster(“local[*]”) val sc = new SparkContext(conf) sc.setLogLevel(“WARN”)
// 2、生成RDD;RDD转换
val slices = if (args.length > 0) args(0).toInt else 10
val N = 100000000
val count = sc.makeRDD(1 to N, slices).map(
idx => {
val (x, y) = (random, random)
if (x*x + y*y <= 1) 1 else 0
}).reduce(_+_)
// 3、结果输出
println(s"Pi is roughly ${4.0 * count / N}")
// 4、关闭SparkContext
sc.stop()
} }
<a name="zmoEj"></a>
## 4 广告数据统计
- 数据格式:timestamp province city userid adid
时间点 省份 城市 用户 广告
- 需求: 1 、统计每一个省份点击TOP3的广告ID
2 、统计每一个省份每一个小时的TOP3广告ID
```scala
package cn.lagou.sparkcore
import org.apache.spark.{SparkConf, SparkContext}
object AdStat {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(s"${this.getClass.getCanonicalName.init}").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val N = 3
// 读文件
// 字段:时间、省份、城市、用户、广告
val lines = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\advert.log")
val rawRDD = lines.map(
line =>{
val arr = line.split("\\s+")
(arr(0), arr(1), arr(4))
})
// 需求1:统计每个省份点击 TOP3 的广告ID
rawRDD.map{
case (_, province, adid) => ((province, adid), 1)
} .reduceByKey(_ + _) .map{
case ((province, adid), count) => (province, (adid, count))
} .groupByKey().mapValues(_.toList.sortWith(_._2 > _._2).take(N)).foreach(println)
// 需求2:统计每个省份每小时 TOP3 的广告ID
rawRDD.map{
case (time, province, adid) => ((getHour(time), province, adid), 1)
}.reduceByKey(_ + _).map {
case ((hour, province, adid), count) => ((hour, province), (adid, count))
}.groupByKey() .mapValues(_.toList.sortWith(_._2 > _._2).take(N)).foreach(println)
sc.stop()
}
def getHour(timelong: String): String = {
import org.joda.time.DateTime
val datetime = new DateTime(timelong.toLong)
datetime.getHourOfDay.toString
}
}
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.9.7</version>
</dependency>
- 在Java 8出现前的很长时间内成为Java中日期时间处理的事实标准,用来弥补JDK的不足。
- Joda 类具有不可变性,它们的实例无法被修改。(不可变类的一个优点就是它们是线程安全的)
- 在 Spark Core 程序中使用时间日期类型时,不要使用 Java 8 以前的时间日期型,线程不安全。
5 找共同好友
- 原始数据:
- 100, 200 300 400 500 600
- 200, 100 300 400
- 300, 100 200 400 500
- 400, 100 200 300
- 500, 100 300
- 600, 100
第一列表示用户,后面的表示该用户的好友
要求:
- 查找两两用户的共同好友
- 最后的结果按前两个id号有序排序 ```scala package cn.lagou.sparkcore import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object FindFriends { def main(args: Array[String]): Unit = { // 创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster(“local[*]”) val sc = new SparkContext(conf) sc.setLogLevel(“WARN”)
val lines: RDD[String] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\fields.dat" )
// 方法一:核心思想利用笛卡尔积求两两的好友,然后去除多余的数据
val friendsRDD: RDD[(String, Array[String])] = lines.map{
line =>
val fields: Array[String] = line.split(",")
val userId = fields(0).trim
val friends: Array[String] = fields(1).trim.split("\\s+")
(userId, friends)
}
friendsRDD.cartesian(friendsRDD)
.filter{
case ((id1, _), (id2, _)) => id1 < id2
}
.map{
case ((id1, friends1), (id2, friends2)) =>
//((id1, id2), friends1.toSet & friends2.toSet)
((id1, id2), friends1.intersect(friends2).sorted.toBuffer)
}.sortByKey().collect().foreach(println)
// 方法二:消除笛卡尔积,更高效。
// 核心思想:将数据变形,找到两两的好友,再执行数据的合并
println("*****************************************************************")
friendsRDD.flatMapValues(friends => friends.combinations(2))
// .map(x => (x._2.mkString(" & "), Set(x._1)))
.map{case (k, v) => (v.mkString(" & "), Set(k))}
.reduceByKey(_ | _)
.sortByKey().collect().foreach(println)
// 备注:flatMapValues / combinations / 数据的变形 / reduceByKey / 集合的操作
// 关闭SparkContext
sc.stop()
} }
<a name="iTAhA"></a>
## 6 SuperWordCount
- 要求:将单词全部转换为小写,去除标点符号(难),去除停用词(难);最后按照count 值降序保存到文件,同时将全部结果保存到MySQL(难);标点符号和停用词可以自定义。
- 停用词:语言中包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是[限定词](the、a、an、that、those),介词(on、in、to、from、over等)、代词、数量词等。
- Array[(String, Int)] => scala jdbc => MySQL
```scala
package cn.lagou.sparkcore
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount1 {
private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each".split("\\s+")
private val punctuation = "[\\)\\.,:;'!\\?]"
def main(args: Array[String]): Unit = {
// 创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMa ster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// RDD转换 // 换为小写,去除标点符号(难),去除停用词(难)
val lines: RDD[String] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\swc.dat")
lines.flatMap(_.split("\\s+"))
.map(_.toLowerCase)
.map(_.replaceAll(punctuation, ""))
.filter(word => !stopWords.contains(word) && word.trim.length>0)
.map((_, 1)) .reduceByKey(_+_) .sortBy(_._2, false) .collect.foreach(println)
// 结果输出
// 关闭SparkContext
sc.stop()
}
}
- 引入依赖
```scala package cn.lagou.sparkcore import java.sql.{Connection, DriverManager, PreparedStatement}<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency>
object JDBCDemo { def main(args: Array[String]): Unit = { // 定义结果集 val str = “hadoop spark java scala hbase hive sqoop hue tez atlas datax grinffin zk kafka” val result: Array[(String, Int)] = str.split(“\s+”).zipWithIndex
// 定义连接信息
val username = "hive"
val password = "12345678"
val url = "jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false"
var conn: Connection = null
var stmt: PreparedStatement = null
val sql = "insert into wordcount values (?, ?)"
try{
conn = DriverManager.getConnection(url, username, password)
stmt = conn.prepareStatement(sql)
result.foreach{
case (word, count) =>
stmt.setString(1, word)
stmt.setInt(2, count)
stmt.executeUpdate()
}
}
catch {
case e: Exception => e.printStackTrace()
}
finally {
if (stmt != null)
stmt.close()
if (conn != null)
conn.close()
}
} }
- `create table ``wordcount(word ``varchar``(``30``), ``count ``int``); `
- 未优化的程序:使用 foreach 保存数据,要创建大量的链接
```scala
package cn.lagou.sparkcore
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount2 {
val stopword = List("the", "a", "in", "and", "to", "of", "for", "is", "are", "on", "you", "can", "your", "as")
val punctuation = """[,\\.?;:!"'()]"""
def main(args: Array[String]): Unit = {
// 1、创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// 2、生成RDD
val lines: RDD[String] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\swc.dat")
// 3、RDD转换
// 单词切分、转为小写
val words: RDD[String] = lines.flatMap(_.split("\\s+")).map(_.trim.toLowerCase())
// 去停用词、标点
val cleanWords: RDD[String] = words.filter(!stopword.contains(_)).map(_.replaceAll(punctuation, ""))
// 计算词频,并按降序排序
val result: RDD[(String, Int)] = cleanWords.map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false)
// 4、结果输出
result.foreach(println)
//result.saveAsTextFile("file:///C:\\Project\\LagouBigData\\data\\w coutput")
// 数据输出到 MySQL
val username = "hive"
val password = "12345678"
val url = "jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false"
var conn: Connection = null
var stmt: PreparedStatement = null
val sql = "insert into wordcount values (?, ?)"
result.foreach{case (word, count) =>
try{
conn = DriverManager.getConnection(url, username, password)
stmt = conn.prepareStatement(sql)
stmt.setString(1, word)
stmt.setInt(2, count)
stmt.executeUpdate()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) stmt.close()
if (conn != null) conn.close()
}
}
// 5、关闭SparkContext
sc.stop()
}
}
- 优化后的程序:使用 foreachPartition 保存数据,一个分区创建一个链接;cache RDD ```scala package cn.lagou.sparkcore import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext}
object SuperWordCount3 { private val stopword = List(“the”, “a”, “in”, “and”, “to”, “of”, “for”, “is”, “are”, “on”, “you”, “can”, “your”, “as”) private val punctuation = “””[,\.?;:!”‘()]””” private val username = “hive” private val password = “12345678” private val url = “jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false”
def main(args: Array[String]): Unit = { // 1、创建SparkContext val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster(“local[*]”) val sc = new SparkContext(conf) sc.setLogLevel(“WARN”)
// 2、生成RDD
val lines: RDD[String] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\swc.dat")
// 3、RDD转换
// 单词切分、转为小写
val words: RDD[String] = lines.flatMap(_.split("\\s+")).map(_.trim.toLowerCase())
// 去停用词、标点
val cleanWords: RDD[String] = words.filter(!stopword.contains(_)).map(_.replaceAll(punctuation, ""))
// 计算词频,并按降序排序
val result: RDD[(String, Int)] = cleanWords.map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false)
result.cache()
// 4、结果输出
result.foreach(println)
result.saveAsTextFile("file:///C:\\Project\\LagouBigData\\data\\wcoutput")
// 数据输出到 MySQL
result.foreachPartition(saveAsMySQL(_))
// 5、关闭SparkContext
sc.stop()
}
def saveAsMySQL(iter: Iterator[(String, Int)]): Unit = { var conn: Connection = null var stmt: PreparedStatement = null val sql = “insert into wordcount values (?, ?)” try{ conn = DriverManager.getConnection(url, username, password) stmt = conn.prepareStatement(sql) iter.map{ case (word, count) => stmt.setString(1, word) stmt.setInt(2, count) stmt.executeUpdate() } } catch { case e: Exception => e.printStackTrace() } finally { if (stmt != null) stmt.close() if (conn != null) conn.close() } } } ```
- 备注:
- SparkSQL有方便的读写MySQL的方法,给参数直接调用即可;
- 但以上掌握以上方法非常有必要,因为SparkSQL不是支持所有的类型的数据库

若有收获,就点个赞吧
0 人点赞
