范式:
在关系型数据库中,关于数据表设计的基本原则,规则就成为范式
目前关系型数据库有六种常见范式,按照范式级别,从低到高分别是:第一范式(1NF)、第二范式
(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美
范式)。
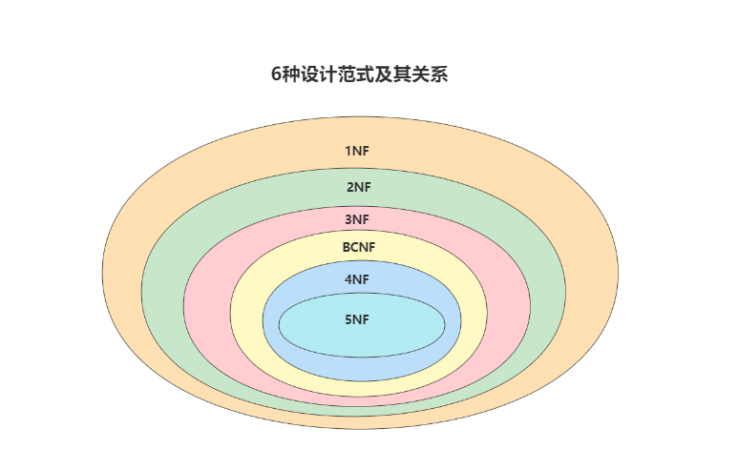
数据库的范式设计越高阶,冗余度就越低,同时高阶的范式一定符合低阶范式的要求,最低要求为第一范式
一般来说,在关系型数据库设计中,最高也就遵循到BCNF(巴斯范式),普遍还是3NF,但也不是绝对,有时候为了提高某些查询性能,我们还需要破坏范式规则,也就是反范式化
第一范式:
确保数据表中每个字段的值必须具有原子性,也就是说每个数据表中每个字段的值为不可再次拆分的最小单元数据
第二范式:
在满足第一范式的基础上,还要满足数据表中的每一条记录都是可唯一标识的,而且所有的非主键字段,都必须完全依赖主键,不能只依赖主键的一部分
例如:成绩表中,学号和课程号可以决定成绩,但是学号不能决定成绩,课程号也不能决定成绩,
所以(学号、课程号)—》成绩 就是完全依赖关系
第三范式:
在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段
即:
不能存在非主键字段A依赖于非主键B,而非主键B又依赖于主键C,即存在A->B->C的关系
总结:
1.第一范式,确保了每列保持原子性
2.第二范式,确保了每列都和主键完全依赖
3.第三范式,确保了每列都和主键列直接相关而不能间接相关(A->B,B->C,不能是A->B->C)
优点:数据的标准化有助于消除数据库中的数据冗余,第三范式通常被认为在性能,扩展性和数据完整性方面达到了最好的平衡
缺点:范式的使用可能会降低查询效率,因为范式的等级越高,设计出来的数据表就越多,越精细,数据的冗余度越低,进行数据查询的时候可能就需要关联多张表,也可能导致一些索引策略失效
反范式化:
不能只按照范式的要求进行数据库表的设计,要遵循业务优先的原则
有时候可以考虑适当增加冗余的字段来减少表的关联查询,从而达到对性能优化的效果,增加冗余字段就是反范式化
规范化 vs 性能
- 为满足某种商业目标 , 数据库性能比规范化数据库更重要
- 在数据规范化的同时 , 要综合考虑数据库的性能
- 通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间
- 通过在给定的表中插入计算列,以方便查询
反范式化的新问题:
1.存储空间变大了
2.一个表中字段做了修改,另一个表中冗余的字段也需要同步修改,否则数据不一致
3.若采用存储过程来支持数据的更新、删除等操作,如果更新频繁会很消耗系统资源
4.在数据量小的情况下,反范式化不能体现性能的优势,可能还会让数据库表的设计更加复杂
使用场景:
当冗余信息有价值或者能大幅度提升查询效率的时候才会使用反范式化
1.增加冗余字段的建议:
①:冗余字段不需要经常进行修改
②:冗余字段查询的时候不可或缺
2.历史快照、历史数据的需要
比如订单中的收货人,地址等信息,每次发生的订单收货信息都属于历史数据,需要进行保存,但是用户随时有可能对收货信息进行修改,所以冗余字段的保存是十分必要的
3.数据仓库的设计中通常使用反范式化
数据仓库通常用来存储历史信息,对于信息的修改比较少,但是设置冗余字段可能更利于数据分析
4.巴斯范式 BCNF

若有收获,就点个赞吧
0 人点赞
