如果我们把指标比喻成一棵树上的果实,那模型就是这棵大树的躯干,想让果实结得好,必须让树干变得粗壮。大多数公司的分析师会结合业务做一些数据分析(需要用到大量的数据),通过报表的方式服务于业务部门的运营。但是在数据中台构建之前,分析师经常发现自己没有可以复用的数据,不得不使用原始数据进行清洗、加工、计算指标。
由于他们大多是非技术专业出身,写的 SQL 质量比较差,甚至有5 层以上的嵌套。这种 SQL 对资源消耗非常大,会造成队列阻塞,影响其他数仓任务,会引起数据开发的不满。数据开发会要求收回分析师的原始数据读取权限,分析师又会抱怨数仓数据不完善,要啥没啥,一个需求经常要等一周甚至半个月。分析师与数据开发的矛盾从此开始。
这个矛盾的根源在于数据模型无法复用,数据开发是烟囱式的,每次遇到新的需求,都从原始数据重新计算,自然耗时。而要解决这个矛盾,就要搞清楚我们的数据模型应该设计成什么样子。
什么才是一个好的数据模型设计?
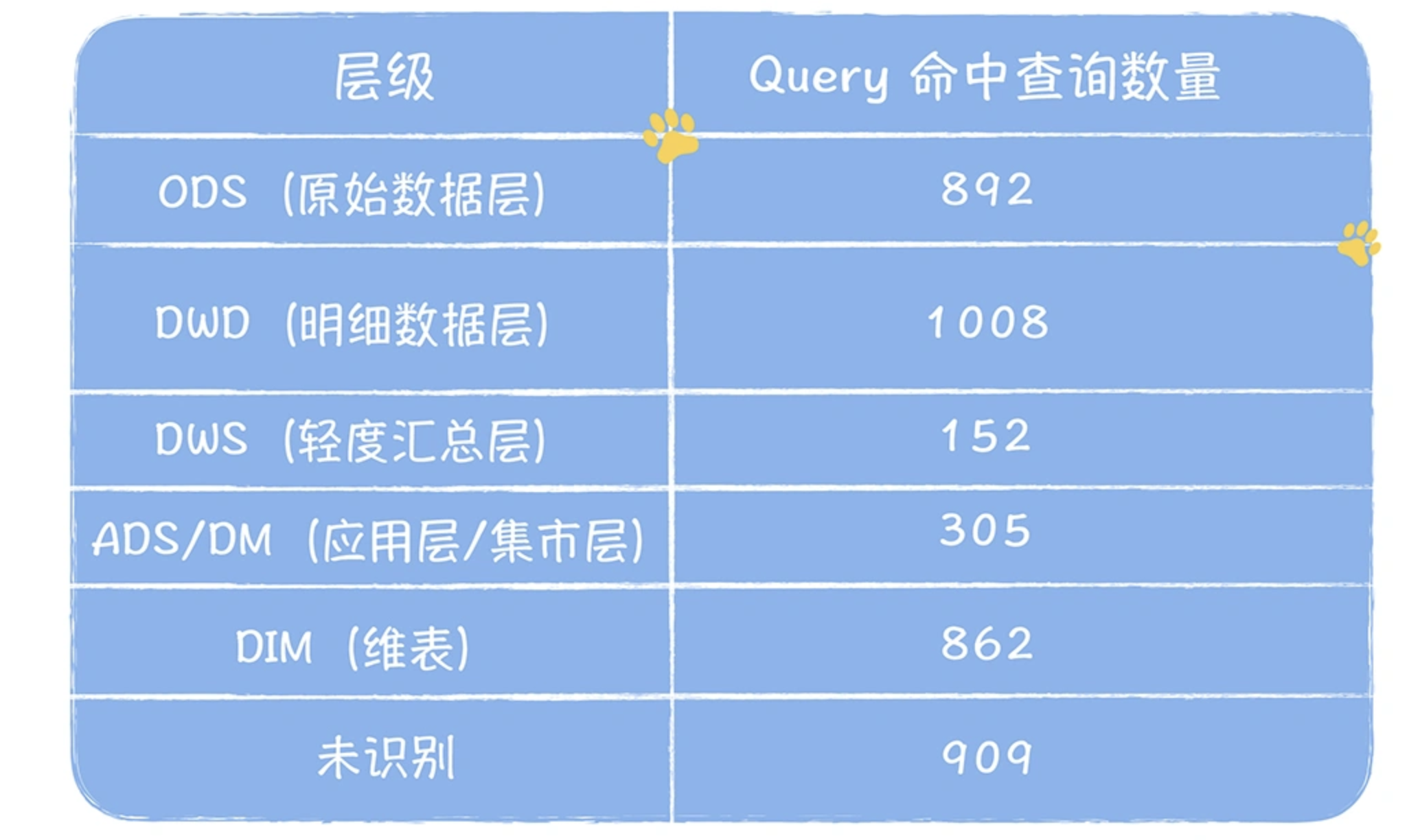
这两个表格是基于元数据中心提供的血缘信息,分别对大数据平台上运行的任务和分析查询进行的统计。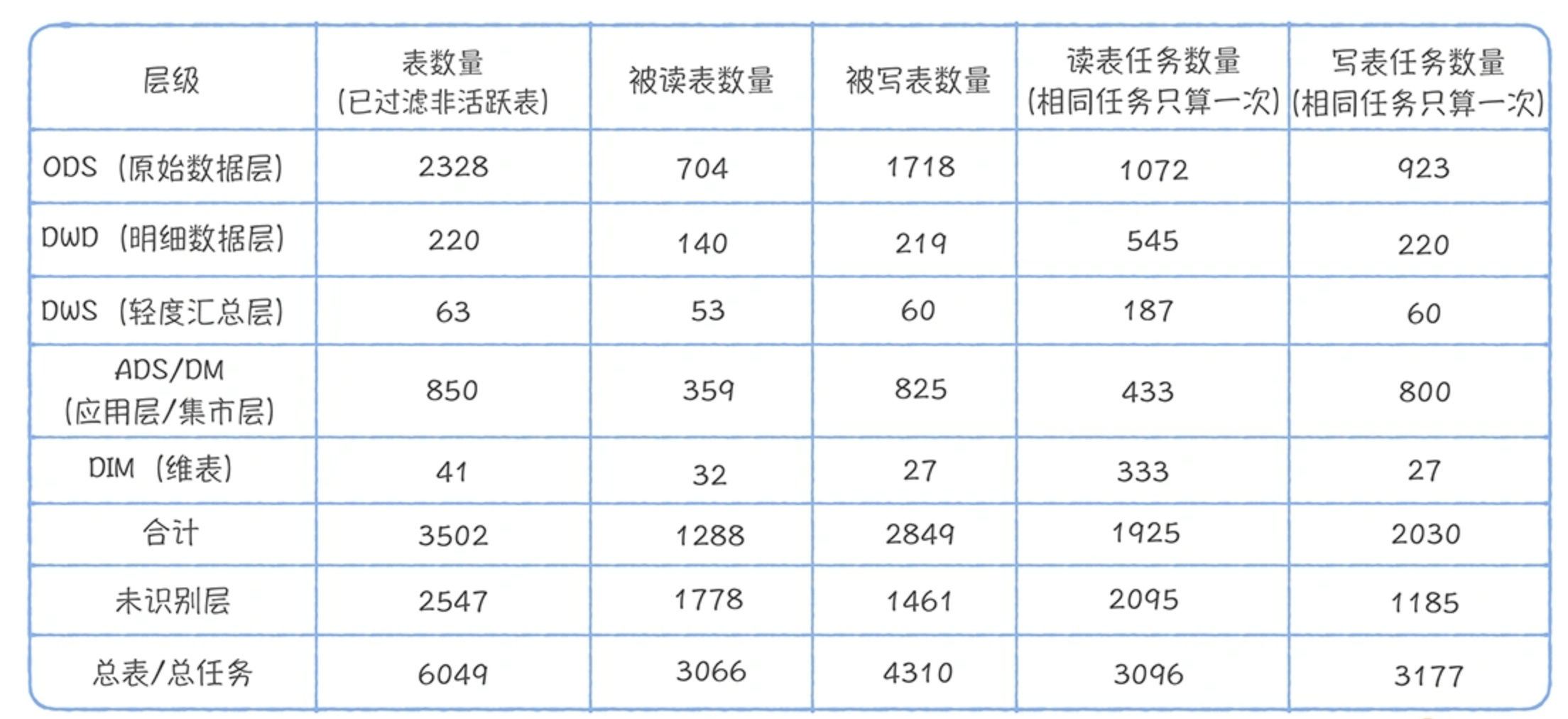
数仓分层架构图:
表 1 中有 2547 张未识别分层的表,占总表 6049 的 40%,它们基本没办法复用。 重点是在已识别分层的读表任务中,ODS:DWD:DWS:ADS 的读取任务分别是 1072:545:187:433,直接读取 ODS 层任务占这四层任务总和的 47.9%,这说明有大量任务都是基于原始数据加工,中间模型复用性很差。
表 2在已识别的分层的查询中,ODS:DWD:DWS:ADS 的命中的查询分别是 892:1008:152:305,有 37.8% 的查询直接命中 ODS 层原始数据,说明 DWD、DWS、ADS 层数据建设缺失严重。尤其是 ADS 和 DWS,查询越底层的表,就会导致查询扫描的数据量会越大,查询时间会越长,查询的资源消耗也越大,使用数据的人满意度会低。最后,我们进一步对 ODS 层被读取的 704 张表进行分解,发现有 382 张表的下游产出是 DWS,ADS,尤其是 ADS 达到了 323 张表,占 ODS 层表的比例 45.8%,说明有大量 ODS 层表被进行物理深加工。
通过上面的分析,我们似乎已经找到了一个理想的数仓模型设计应该具备的因素,那就是“数据模型可复用,完善且规范”。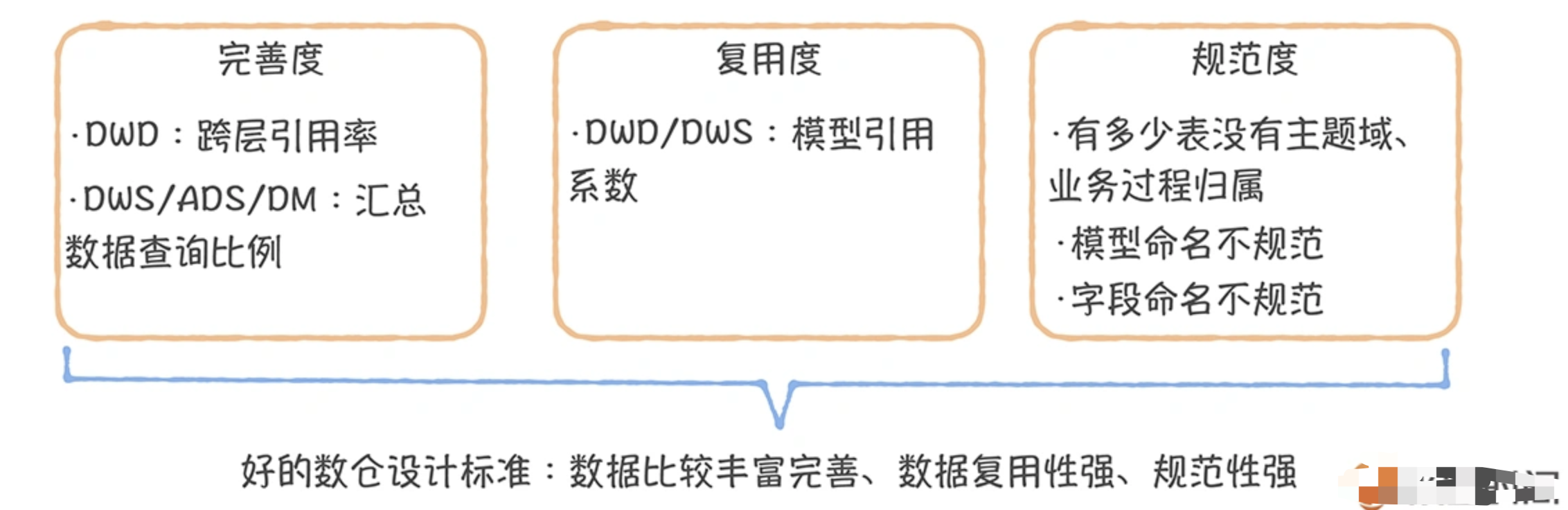
如何衡量完善度DWD 层完善度:
衡量 DWD 层是否完善,最好看 ODS 层有多少表被 DWS/ADS/DM 层引用。因为 DWD 以上的层引用的越多,就说明越多的任务是基于原始数据进行深度聚合计算的,明细数据没有积累,无法被复用,数据清洗、格式化、集成存在重复开发。因此,用跨层引用率指标衡量 DWD 的完善度。
跨层引用率:ODS 层直接被 DWS/ADS/DM 层引用的表,占所有 ODS 层表(仅统计活跃表)比例。跨层引用率越低越好,在数据中台模型设计规范中,不允许出现跨层引用,ODS 层数据只能被 DWD 引用。
DWS/ADS/DM 层完善度:考核汇总数据的完善度,我认为主要看汇总数据能直接满足多少查询需求(也就是用汇总层数据的查询比例衡量)。如果汇总数据无法满足需求,使用数据的人就必须使用明细数据,甚至是原始数据。
汇总数据查询比例:DWS/ADS/DM 层的查询占所有查询的比例。跨层引用率不同,汇总查询比例不可能做到 100%,但值越高,说明上层的数据建设越完善,对于使用数据的人来说,查询速度和成本会减少,用起来会更爽。
如何衡量复用度
数据中台模型设计的核心是追求模型的复用和共享,通过元数据中心的数据血缘图,可以看到,一个比较差的模型设计,自下而上是一条线。而一个理想的模型设计,它应该是交织的发散型结构。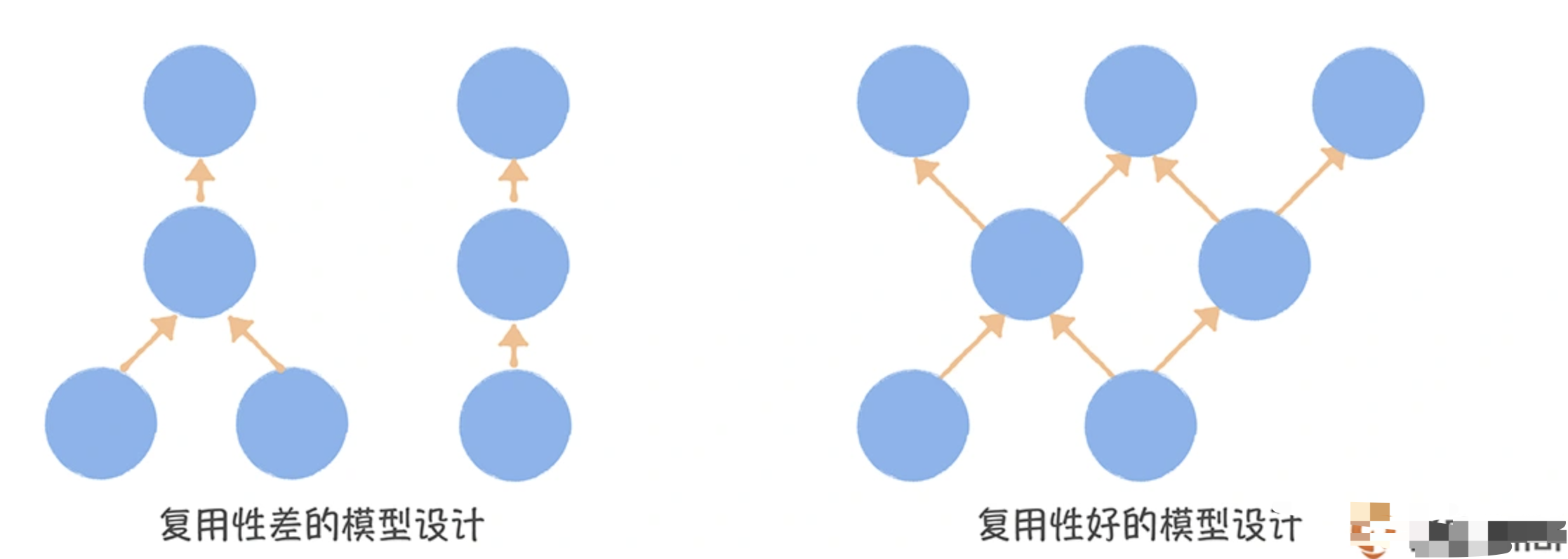
用模型引用系数作为指标,衡量数据中台模型设计的复用度。引用系数越高,说明数仓的复用性越好。模型引用系数:一个模型被读取,直接产出下游模型的平均数量。比如一张 DWD 层表被 5 张 DWS 层表引用,这张 DWD 层表的引用系数就是 5,如果把所有 DWD 层表(有下游表的)引用系数取平均值,则为 DWD 层表平均模型引用系数,一般低于 2 比较差,3 以上相对比较好(经验值)
如何衡量规范度
表 1 中,超过 40% 的表都没有分层信息,在模型设计层面,这显然是不规范的。除了看这个表有没有分层,还要看它有没有归属到主题域(例如交易域)如果没有归属主题域,就很难找到这张表,也无法复用。其次,要看表的命名。拿 stock 这个命名为例,当你看到这个表时,知道它是哪个主题域、业务过程?是全量数据的表,还是每天的增量数据?总的来说,通过这个表名获取的信息太有限了。一个规范的表命名应该包括主题域、分层、表是全量快照,还是增量等信息。除此之外,如果在表 A 中用户 ID 的命名是 UserID,在表 B 中用户 ID 命名是 ID,就会对使用者造成困扰,这到底是不是一个东西。所以我们要求相同的字段在不同的模型中,它的命名必须是一致的。
- 可以拿着这些指标去评估一下,自己的数仓现状如何。
- 然后制订一些针对性的改进计划,比如把这些不规范命名的表消灭掉,把主题域覆盖的表比例提高到 90% 以上。
- 在尝试完一段时间的模型重构和优化后,再拿着这些指标去测一测是不是真的变好了。我见过很多数据开发在向上级汇报工作时,喜欢用重构了多少模型说明工作成果,很多老大会想,这些重构到底对数据建设有多少帮助?有没有一些量化的指标可以衡量?有上面的知识,可以应对这个问题。
现在知道什么是好的数仓设计了,可目前已经存在了大量烟囱式开发,具体怎么做才能让它变成一个数据中台呢?
如何从烟囱式的小数仓到共享的数据中台
建设数据中台本质就是构建企业的公共数据层,把原先分散的、烟囱式的、杂乱的小数仓,合并成一个可共享、可复用的数据中台。
第一,接管 ODS 层,控制源头。
ODS 是业务数据进入数据中台的第一站,是所有数据加工的源头,控制住源头,才能从根本上防止一个重复的数据体系的出现。数据中台团队必须明确职责,全面接管 ODS 层数据,从业务系统的源数据库权限入手,确保数据从业务系统产生后进入数据仓库时,只能在数据中台保持一份。这个可以跟业务系统数据库管理者达成一致,只有中台团队的账号才能同步数据。ODS 层表的数据必须和数据源的表结构、表记录数一致,高度无损,对于 ODS 层表的命名采用 ODS 业务系统数据库名 业务系统数据库表名方式,比如 ods_warehous_stock,warehous 是业务系统数据库名,stock 是该库下面的表名。
第二,划分主题域,构建总线矩阵。
主题域是业务过程的抽象集合。可能这么讲,稍微有点儿抽象,但其实业务过程就是企业经营过程中一个个不可拆分的行为事件,比如仓储管理里面有入库、出库、发货、签收,都是业务过程,抽象出来的主题域就是仓储域。

若有收获,就点个赞吧
0 人点赞
