爬虫第一步-获取网页
爬虫模拟浏览器的工作,向服务器提供请求,获取数据并进行解析 。
爬虫需要的基本库:
urlib/requests:发送数据请求,获取网页 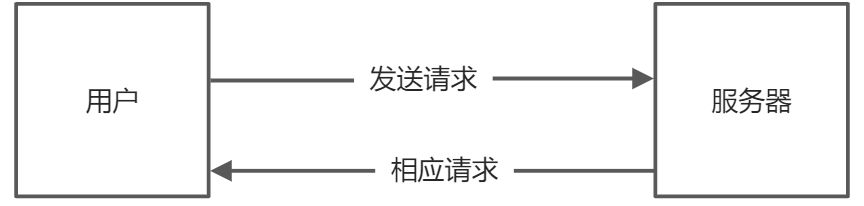
爬虫第二步-提取信息
抓取隐藏在网页源码中的关键信息
python爬虫需要的基本库:
Bs4/Beatufilsoup :
从网页中抓取数据(第一步)
表达式规则建立(第二步)
爬虫第三步-保存数据
保存为TXT或者导入 pandas的dataframe 或者导入数据库
爬虫第四步-分析数据
对数据根据业务指标进行分析和挖掘

若有收获,就点个赞吧
0 人点赞
