对于一个早期的推荐系统来说,基于内容推荐离不开为用户构建一个初级的画像,这种初级的画像一般叫做用户画像(User Profile),一些大厂内部还习惯叫做 UP,今天我就来讲一讲从大量文本数据中挖掘用户画像常常用到的一些算法。
从文本开始
用户这一端比如说有:
- 注册资料中的姓名、个人签名;
- 发表的评论、动态、日记等;
- 聊天记录(不要慌,我举个例子而已,你在微信上说的话还是安全的)。
物品这一端也有大量文本信息,可以用于构建物品画像( Item Profile ),并最终帮助丰富 用户画像(User Profile),这些数据举例来说有:
- 物品的标题、描述;
- 物品本身的内容(一般指新闻资讯类);
- 物品的其他基本属性的文本
文本数据是互联网产品中最常见的信息表达形式,数量多、处理快、存储小,因为文本数据的特殊地位,所以今天我专门介绍一些建立用户画像过程中用到的文本挖掘算法。
构建用户画像
要用物品和用户的文本信息构建出一个基础版本的用户画像,大致需要做这些事:
1. 把所有非结构化的文本结构化,去粗取精,保留关键信息;
2. 根据用户行为数据把物品的结构化结果传递给用户,与用户自己的结构化信息合并。
第一步最关键也最基础,其准确性、粒度、覆盖面都决定了用户画像的质量。仿佛如果真的要绘制一个用户的模样,要提前给他拍照,这个拍照技术决定了后面的描绘情况,无论是采用素描、油画、工笔还是写意。这一步要用到很多文本挖掘算法。
第一步最关键也最基础,其准确性、粒度、覆盖面都决定了用户画像的质量。仿佛如果真的要绘制一个用户的模样,要提前给他拍照,这个拍照技术决定了后面的描绘情况,无论是采用素描、油画、工笔还是写意。这一步要用到很多文本挖掘算法,稍后会详细介绍。
一、结构化文本
我们拿到的文本,常常是自然语言描述的,用行话说,就是“非结构化”的,但是计算机在处理时,只能使用结构化的数据索引,检索,然后向量化后再计算;所以分析文本,就是为了将非结构化的数据结构化,好比是将模拟信号数字化一样,只有这样才能送入计算机,继续计算。这个很好理解,不多解释。
- 从物品端的文本信息,我们可以利用成熟的 NLP 算法分析得到的信息有下面几种。关键词提取:最基础的标签来源,也为其他文本分析提供基础数据,常用 TF-IDF 和 TextRank。
- 实体识别:人物、位置和地点、著作、影视剧、历史事件和热点事件等,常用基于词典的方法结合 CRF 模型。
- 内容分类:将文本按照分类体系分类,用分类来表达较粗粒度的结构化信息。
- 文本 :在无人制定分类体系的前提下,无监督地将文本划分成多个类簇也很常见,别看不是标签,类簇编号也是用户画像的常见构成。
- 主题模型:从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况,也很实用,其实这也是一种聚类思想,主题向量也不是标签形式,也是用户画像的常用构成。
- 嵌入:“嵌入”也叫作 Embedding,从词到篇章,无不可以学习这种嵌入表达。嵌入表达是为了挖掘出字面意思之下的语义信息,并且用有限的维度表达出来。
1 TF-IDF
TF 全称就是 Term Frequency,是词频的意思,IDF 就是 Inverse Document Frequency 是逆文档频率的意思。TF-IDF 提取关键词的思想来自信息检索领域,其实思想很朴素,包括了两点:在一篇文字中反复出现的词会更重要,在所有文本中都出现的词更不重要。非常符合我们的直觉,这两点就分别量化成 TF 和 IDF 两个指标:
- TF,就是词频,在要提取关键词的文本中出现的次数;
- IDF,是提前统计好的,在已有的所有文本中,统计每一个词出现在了多少文本中,记为 n,也就是文档频率,一共有多少文本,记为 N。
IDF 就是这样计算: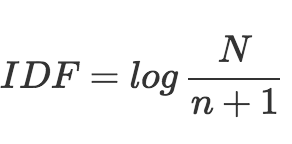
计算过程为:词出现的文档数加 1,再除总文档数,最后结果再取对数。
IDF 的计算公式有这么几个特点:
- 所有词的 N 都是一样的,因此出现文本数越少 (n) 的词,它的 IDF 值越大;
- 如果一个词的文档频率为 0,为防止计算出无穷大的 IDF,所以分母中有一个 1;
- 对于新词,本身应该 n 是 0,但也可以默认赋值为所有词的平均文档频率。
计算出 TF 和 IDF 后,将两个值相乘,就得到每一个词的权重。根据该权重筛选关键词的方式有:
给定一个 K,取 Top K 个词,这样做简单直接,但也有一点,如果总共得到的词个数少于 K,那么所有词都是关键词了,显然这样做不合理;
计算所有词权重的平均值,取在权重在平均值之上的词作为关键词;
另外,在某些场景下,还会加入以下其他的过滤措施,如:只提取动词和名词作为关键词。
2 TextRank
TextRank 这个名字看上去是不是和著名的 PageRank 有点亲戚关系?是的,TextRank 是 PageRank 的私生子之一,著名的 PageRank 算法是 Google 用来衡量网页重要性的算法,TextRank 算法的思想也与之类似,可以概括为:
- 文本中,设定一个窗口宽度,比如 K 个词,统计窗口内的词和词的共现关系,将其看成无向图。图就是网络,由存在连接关系的节点构成,所谓无向图,就是节点之间的连接关系不考虑从谁出发,有关系就对了;
- 所有词初始化的重要性都是 1;
- 每个节点把自己的权重平均分配给“和自己有连接“的其他节点;
- 每个节点将所有其他节点分给自己的权重求和,作为自己的新权重;
- 如此反复迭代第 3、4 两步,直到所有的节点权重收敛为止。
通过 TextRank 计算后的词语权重,呈现出这样的特点:那些有共现关系的会互相支持对方成为关键词。
3 内容分类

若有收获,就点个赞吧
0 人点赞
