供应链部门运营陈英俊(化名)每天上班第一件事情,就是打开供应链辅助决策系统(数据产品),根据系统上给出的商品库存数据、区域下单数据,制订商品的采购计划,然后发送给供货商。可是今天当他准备工作时,突然发现系统中部分商品库存数据显示为 0,他第一时间将问题反馈给了数据部门。与此同时,与他一样无法工作的还有供应链部门的其他 50 多名运营。
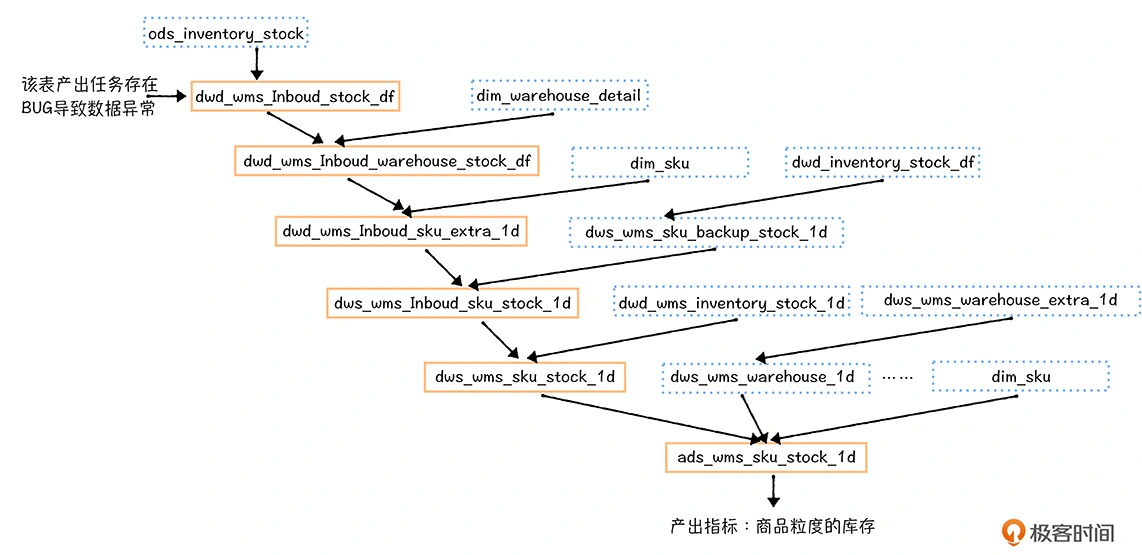
接到投诉后,负责库存域的数据开发郝建(化名)立即开始定位,首先就“商品库存”指标的产出表 ads_wms_sku_stock_1d 进行排查,确认它产出任务没有问题,是这个任务的上游输入表数据有问题,引发下游表数据异常。
从数据血缘图中你可以看到,ads_wms_sku_stock_1d 上游有 20 多张表,郝建逐层校验是哪个表的数据出现问题,结果锁定在了 dwd_wms_inbound_stock_df。这张表的产出任务在前一天有一次线上变更,任务代码存在漏洞,对部分商品入库数据格式解析异常,但是没有将异常抛出,导致产出数据表 dwd_wms_inbound_stock_df 数据异常,进而影响了所有下游表。
排查问题用了近 3 个小时。
既然问题定位清楚,就要开始修复的流程。修改好代码后,郝建重新跑了 dwd_wms_inbound_stock_df 的产出任务,确认数据没有问题,然后需要重跑该任务下游链路上的 5 个任务(图中红色表的产出任务)。
运行完任务用了 5 个小时。
经过数据验证,确认没有问题,此时已经过去了将近 9 个小时。对于像陈英俊这样的运营来说,一天都无法工作。如果你是陈英俊, 对数据会满意吗?所以,光快还不够,还要保证质量。
当然,这个例子暴露出这样几个问题:
- 数据部门晚于业务方发现数据异常,被投诉后才发现问题。
- 出现问题后,数据部门无法快速定位到数据异常的根源,排查用了较长的时间。
- 故障出现在数据加工链路的上游顶端,出现问题没有第一时间报警处理,导致问题修复时,所有下游链路上的任务都要运行,修复时间成本非常高。
这些问题最终导致了数据长时间不可用。那如何解决这些问题,确保数据高质量的交付呢? 首先,你要了解产生这些问题的根源,毕竟认识问题才能解决问题。
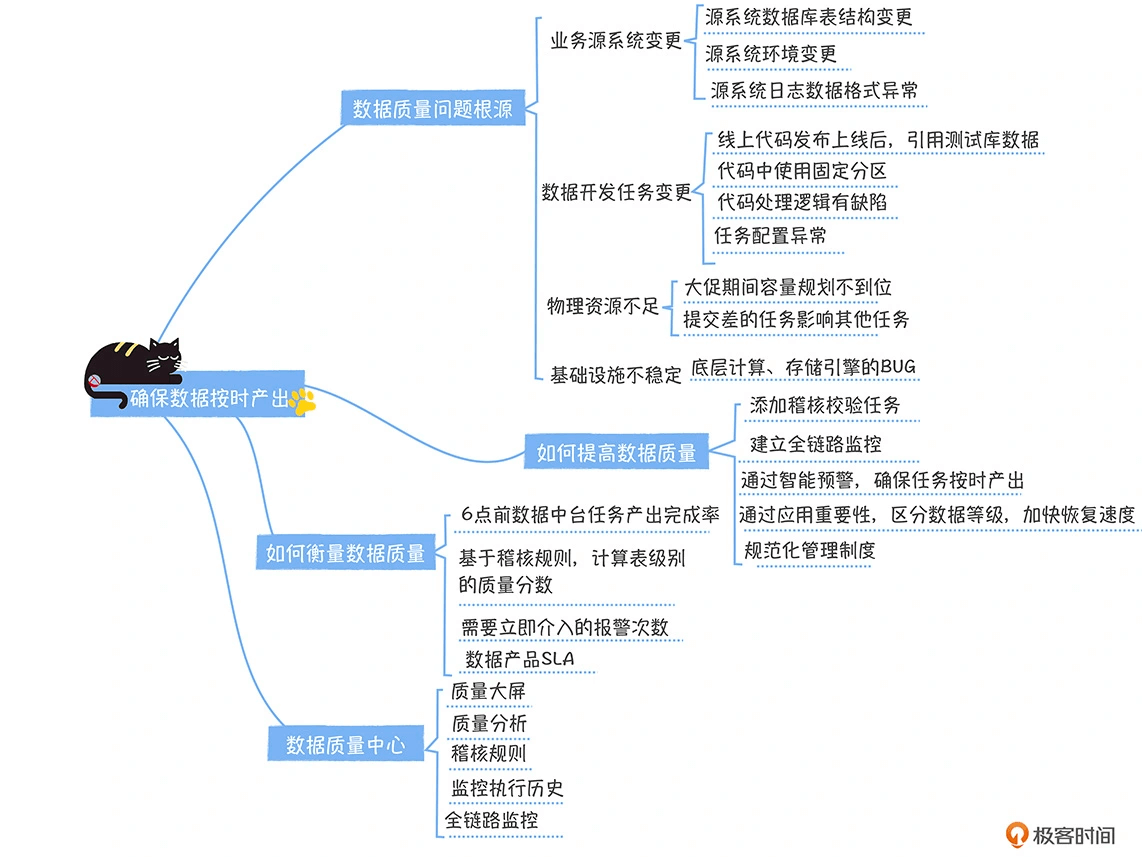
数据质量问题的根源
在电商业务数据中台构建之初,对数据团队一年内,记录在案的 321 次数据质量事件做了逐一分析,对这些事件的原因进行了归纳,主要有下面几类。这里多说一句,如果你想改进数据质量,不妨也对过去踩过的坑做一次复盘,归一下类,看看问题都出在哪里,然后制定针对性的改进计划。
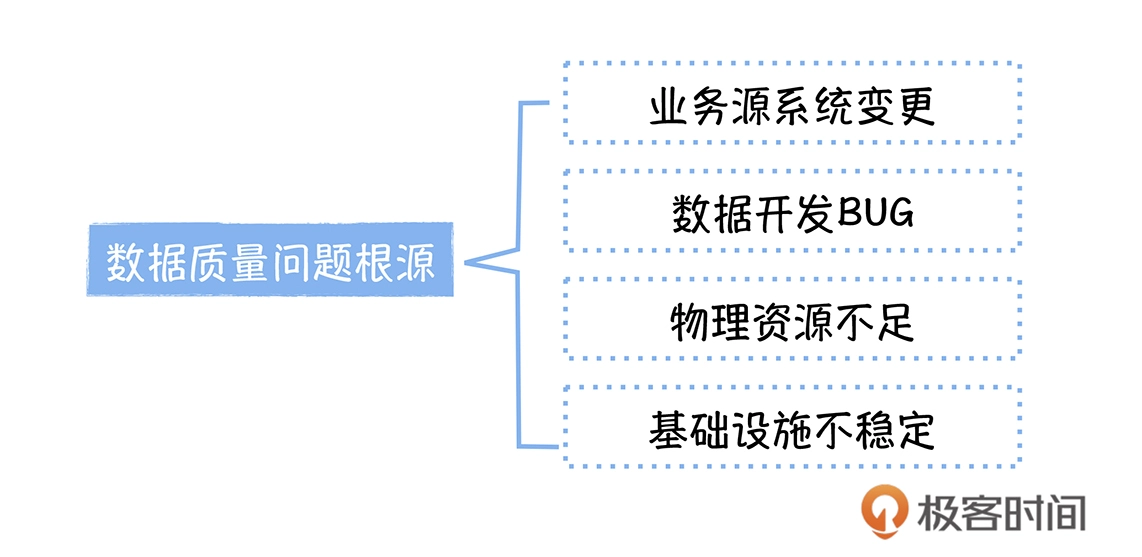
业务源系统变更
数据中台的数据来源于业务系统,而源系统变更一般会引发 3 类异常情况,
首先是源系统数据库表结构变更。例如业务系统新版本发布上线,对数据库进行了表结构变更,增加了一个字段,同时对部分字段的类型、枚举值进行了调整。这种表结构变更没有通知到数据团队,导致数据同步任务或者数据清洗任务异常,进而影响了下游数据产出。
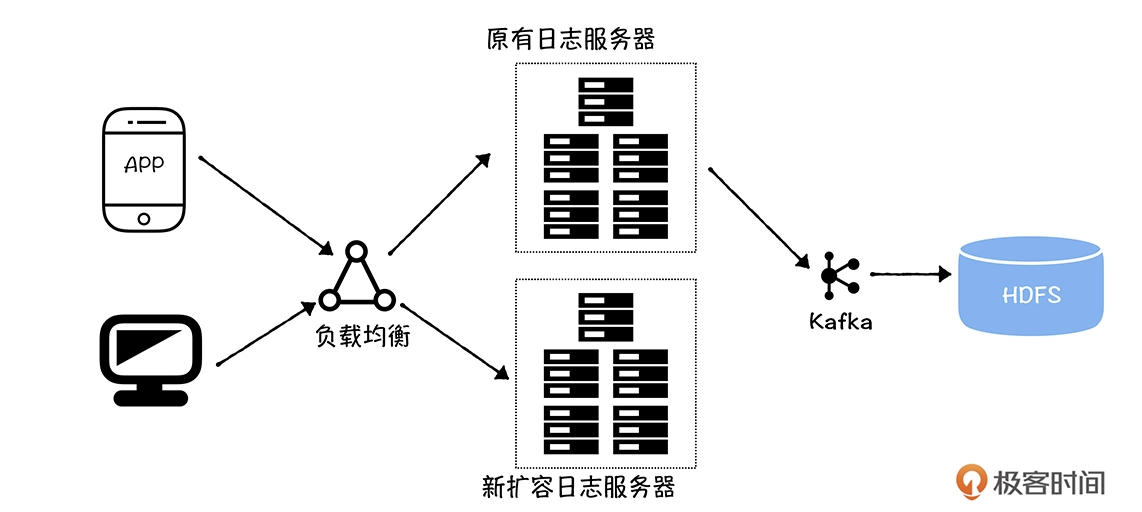
第二个是源系统环境变更。我经常在大促期间见到这种情况,其中的典型是前端用户行为埋点日志量暴增,系统管理员紧急对服务器进行扩容,上线了 5 台新的服务器,但是没有配置这 5 台服务器的日志同步任务,结果导致数据侧少了这 5 台服务器的数据,最终影响了数据计算结果的准确性。
最后一个是源系统日志数据格式异常。这种情况通常出现在前后端埋点日志中。业务系统发布上线引入埋点 BUG,导致 IP 格式出现了不符合约定的格式(比如,我们一般约定的 IP 格式是 166.111.4.129,结果出现了 166.111.4.null),最终也会导致计算结果错误。
数据开发任务变更
这种情况在数据质量事件中占到了 60% 以上,而它大多数是由于数据开发的纰漏引发的,来看几个你比较熟悉的例子:
- 任务发布上线,代码中引用的测试库没有修改为线上库,结果污染了线上数据;
- 任务发布上线,代码中使用了固定分区,没有切换为“${azkaban.flow.1.days.ago}”,导致数据异常;
- 前面例子中,数据格式处理错误,代码忽略了异常,导致数据错误;
- 任务配置异常,它通常表现在任务没有配置依赖,前一个任务没有运行完,后一个任务就开始运行,输入数据不完整,导致下游数据产出错误。
物理资源不足
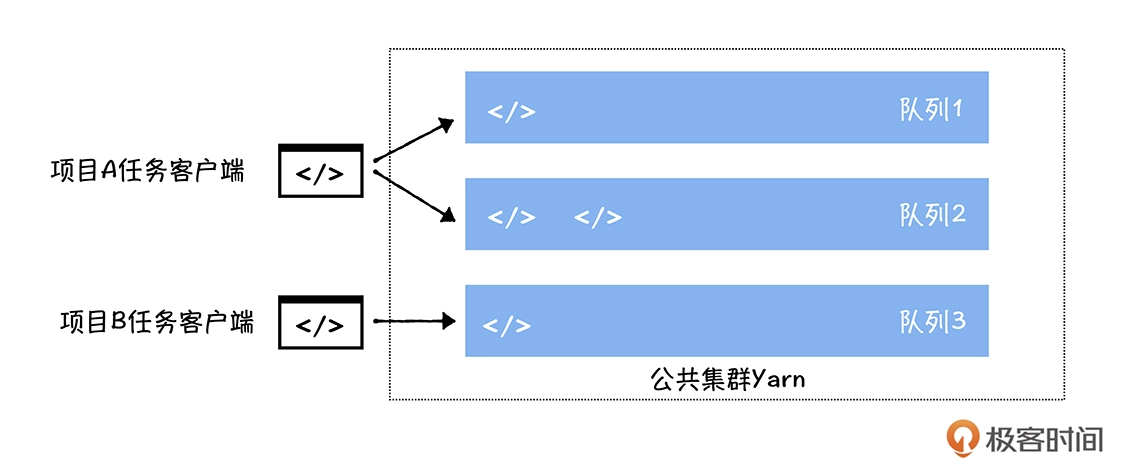
在多租户下,Hadoop 生态的大数据任务(MR,Hive,Spark)一般运行在 yarn 管理的多个队列上(调度器为 CapacityScheduluer),每个队列都是分配了一定大小的计算资源(CPU、内存)。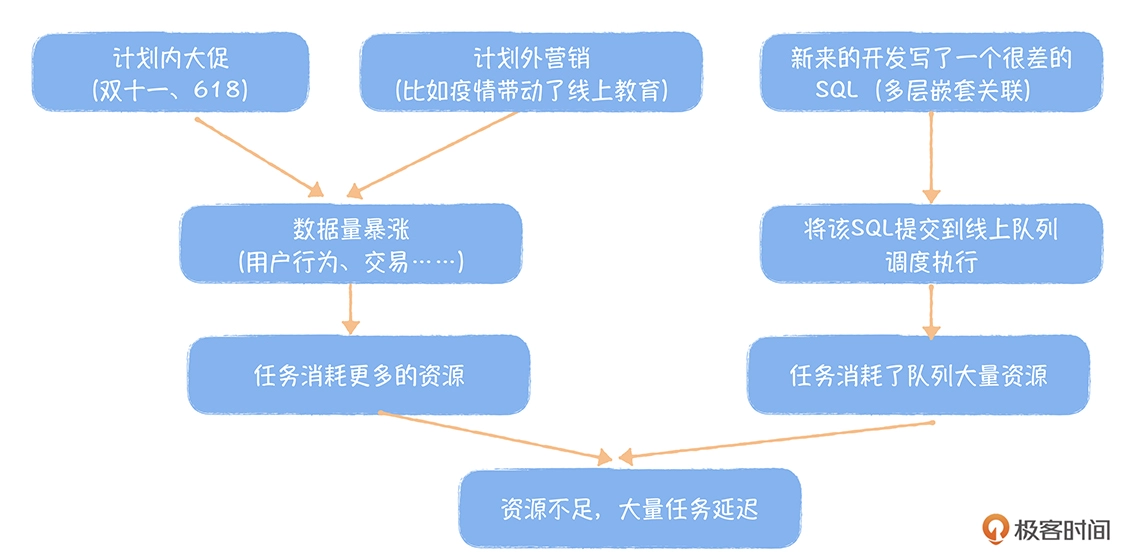
基础设施不稳定
从数量上来看,这类异常不算多,但影响却是全局性的。我们曾经在大促期间,碰到了一个Hadoop 2.7 NameNode 的 BUG,造成 HDFS 整个服务都停止读写,最终通过临时补丁的方式才修复。总的来说,出现问题并不可怕,可怕的是,我们没有及时发现问题,尽快恢复服务,举一反三地通过流程和技术手段,降低问题出现的概率。所以接下来我们就来看一看,如何提高数据质量?如何提高数据质量?
我认为,要想提升数据质量,最重要的就是“早发现,早恢复”:
早发现,是要能够先于数据使用方发现数据的问题,尽可能在出现问题的源头发现问题,这样就为“早恢复”争取到了大量的时间。
早恢复,就是要缩短故障恢复的时间,降低故障对数据产出的影响。那具体如何做到这两个早呢?我总结了一套数据质量建设的方法,包括这样几个内容。
添加稽核校验任务
在数据加工任务中,对产出表按照业务规则,设计一些校验逻辑,确保数据的完整性、一致性和准确性,这是提升数据质量最行之有效的方法。
通常建议你在数据产出任务运行结束后,启动稽核校验任务对数据结果进行扫描计算,判断是否符合规则预期。如果不符合,就根据提前设定的强弱规则,触发不同的处理流程。
如果是强规则,就立即终止任务加工链路,后续的任务不会执行,并且立即发出电话报警,甚至我们要求,关键任务还要开启循环电话报警,直到故障被认领;
如果是弱规则,任务会继续执行。但是存在风险,这些风险会通过邮件或者短信的方式,通知到数据开发,由人来进一步判断风险严重程度。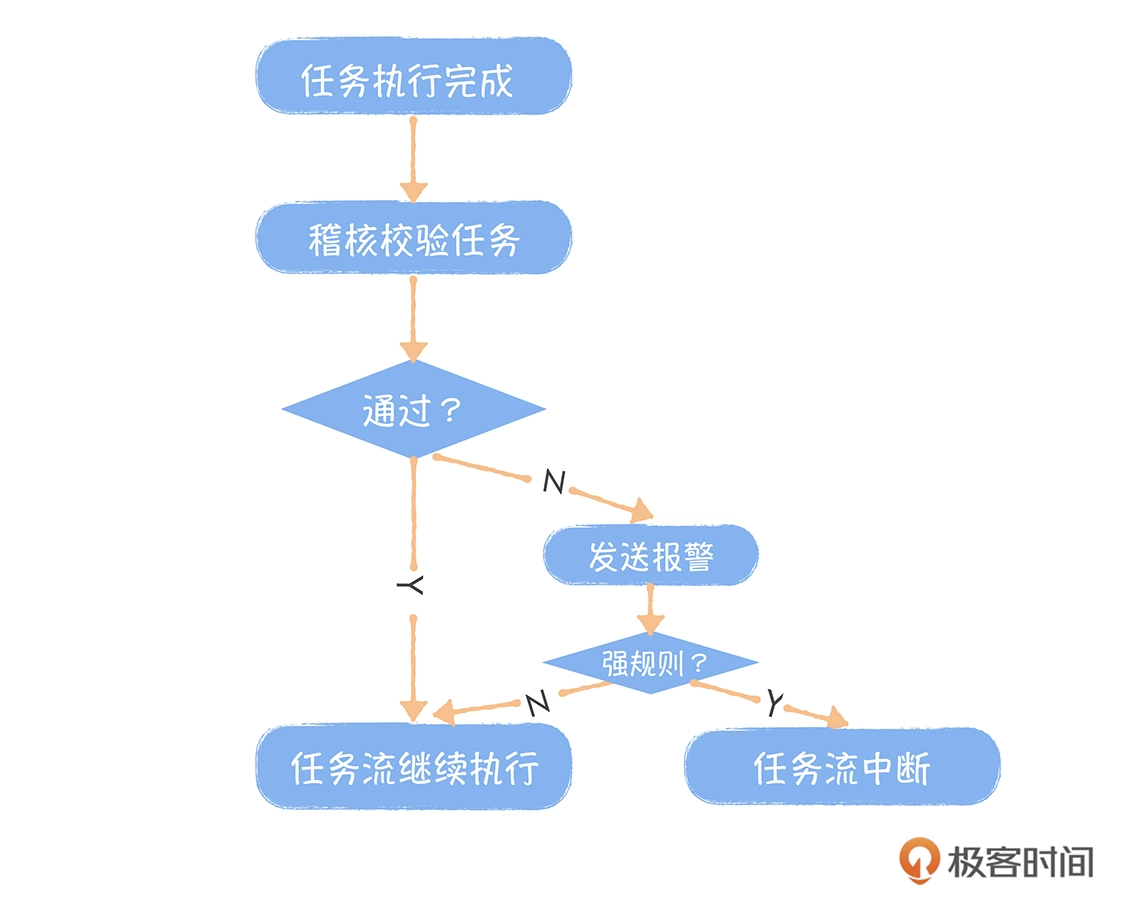
那具体要加哪些稽核规则呢?
完整性规则。主要目的是确保数据记录是完整的,不丢失。常见的稽核规则有表数据量的绝对值监控和波动率的监控(比如表波动超过 20%,就认为是异常)。还有主键唯一性的监控,它是判断数据是否有重复记录的监控规则,比较基础。除了表级别的监控,还有字段级别的监控(比如字段为 0、为 NULL 的记录)。
一致性规则。主要解决相关数据在不同模型中一致性的问题。商品购买率是通过商品购买用户数除以商品访问 uv 计算而来的,如果在不同的模型中,商品购买用户数是 1W、商品访问 uv10W,商品购买率 20%,那这三个指标就存在不一致。
准确性规则。主要解决数据记录正确性的问题。常见的稽核规则有,一个商品只能归属在一个类目,数据格式是不是正确的 IP 格式,订单的下单日期是还没有发生的日期等等。
它们是强规则还是弱规则,取决于业务对上述异常的容忍度(比如涉及到交易、支付跟钱相关的,一般都会设置为强规则,对于一些偏行为分析的,一般都是弱规则)。
建立全链路监控
数据中台的模型设计是分层的,确保中间结果可以被多个模型复用。
不过这会导致数据加工的链路变长,加工链路的依赖关系会非常复杂,最终当下游表上的某个指标出现问题,排查定位问题的时间都会比较长。所以,我们有必要基于数据血缘关系,建立全链路数据质量监控。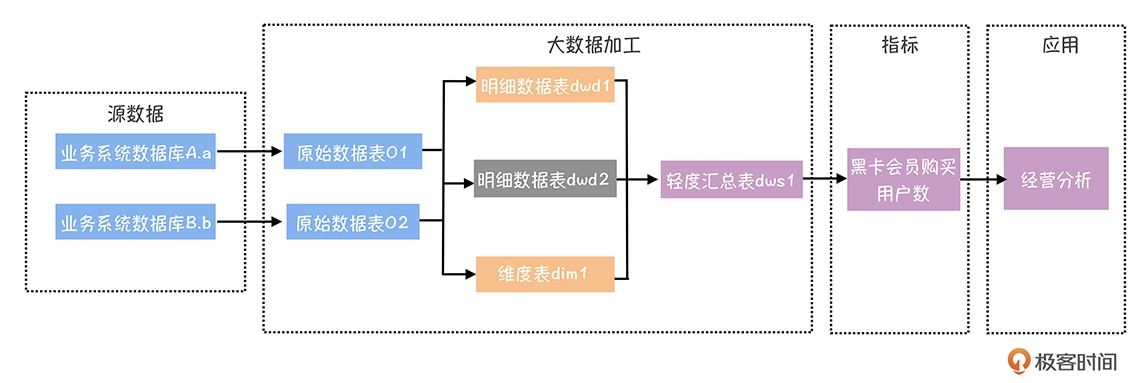
从这个图中你可以看到,业务系统的源数据库表是起点,经过数据中台的数据加工链路,产出指标“黑卡会员购买用户数”,数据应用是链路的终点。
对链路中每个表增加稽核校验规则之后,当其中任何一个节点产出的数据出现异常时,你能够第一时间发现,并立即修复,做到早发现、早修复。另外,即使是使用方反馈经营分析上的黑卡会员购买用户数,相较于昨天数据大幅下降超过 30%,你也可以快速判定整个指标加工链路上节点是否运行正常,产出任务是否有更新,提高了问题排查速度。
通过智能预警,确保任务按时产出。
在数据质量问题中,我提到会存在物理资源不足,导致任务产出延迟的情况。所有数据中台产出的指标要求 6 点前产出。为了实现这个目标,我们需要对指标加工链路中的每个任务的产出时间进行监控,基于任务的运行时间和数据血缘,对下游指标产出时间进行实时预测,一旦发现指标无法按时产出,则立即报警,数据开发可以终止一些低优先级的任务,确保核心任务按时产出。
通过应用的重要性区分数据等级,加快恢复速度。
稽核校验会消耗大量的资源,所以只有核心任务才需要。核心任务的定义是核心应用(使用范围广、使用者管理级别高)数据链路上的所有任务。
规范化管理制度
数据质量取决于稽核规则的完善性,如果数据开发没有添加,或者添加的规则不全,是不是就达不到早发现、早恢复?
这个问题戳中了要害,就是规则的完备性如何来保障。在我看来,这不仅仅是一个技术问题,也涉及管理。我们会制定一些通用的指导规则(比如,所有数据中台维护的表都需要添加主键唯一性的监控规则),但这些通用规则往往与业务关系不大。如果涉及业务层面,就要由数据架构师牵头,按照主题域、业务过程,对每个表的规则进行评审,决定这些规则够不够。
那我想建议你,如果要做稽核校验,可以通过组建数据架构师团队,由这个团队负责核心表的规则审核,确保规则的完备性。
那么当你按照这几个方法建立了数据质量体系之后,要如何验证体系是否有效呢?
如何衡量数据质量?
做数据治理,我一直奉行“效果可量化”的原则,否则这个治理做到什么程度,很难衡量。那么如何评价数据质量是否有改进呢?除了故障次数,你还可以有这样几个指标。
- 4 点半前数据中台核心任务产出完成率。这个指标是一个综合性指标,如果任务异常,任务延迟,强稽核规则失败,都会导致任务无法在规定时间前产出。
- 基于稽核规则,计算表级别的质量分数。根据表上稽核规则的通过情况,为每个表建立质量分数,对于分数低的表,表负责人要承担改进责任。
- 需要立即介入的报警次数,通常以开启循环报警的电话报警次数为准。对于核心任务,任务异常会触发循环电话报警,接到报警的数据开发需要立即介入。
- 数据产品 SLA。每个数据产品上所有指标有没有在 9 点产出,如果没有,开始计算不可用时间,整体可以按照不同数据产品的重要性进行折算,99.8% 是数据产品一个相对比较好的 SLA。
数据质量中心
数据质量中心(以下简称 DQC)的核心功能是稽核校验和基于数据血缘的全链路数据质量监控。
DQC 的首页是质量大屏,提供了稽核规则的数量、表的覆盖量以及这些规则的执行通过情况。通过这些数据,你就能跟你的老板讲清楚,目前数据质量水平建设如何?目标是多少?距离目标还有多少差距。
在 DQC 中创建稽核规则非常简单,DQC 内置了大量的基础规则,例如 IP 字段格式校验,主键唯一性校验,表行数波动率校验,同时还提供了自定义 SQL 的方式,允许业务层面的规则创建,例如我们前面提到的一致性规则中,两个指标相除等于第三个指标,就可以通过自定义 SQL 解决。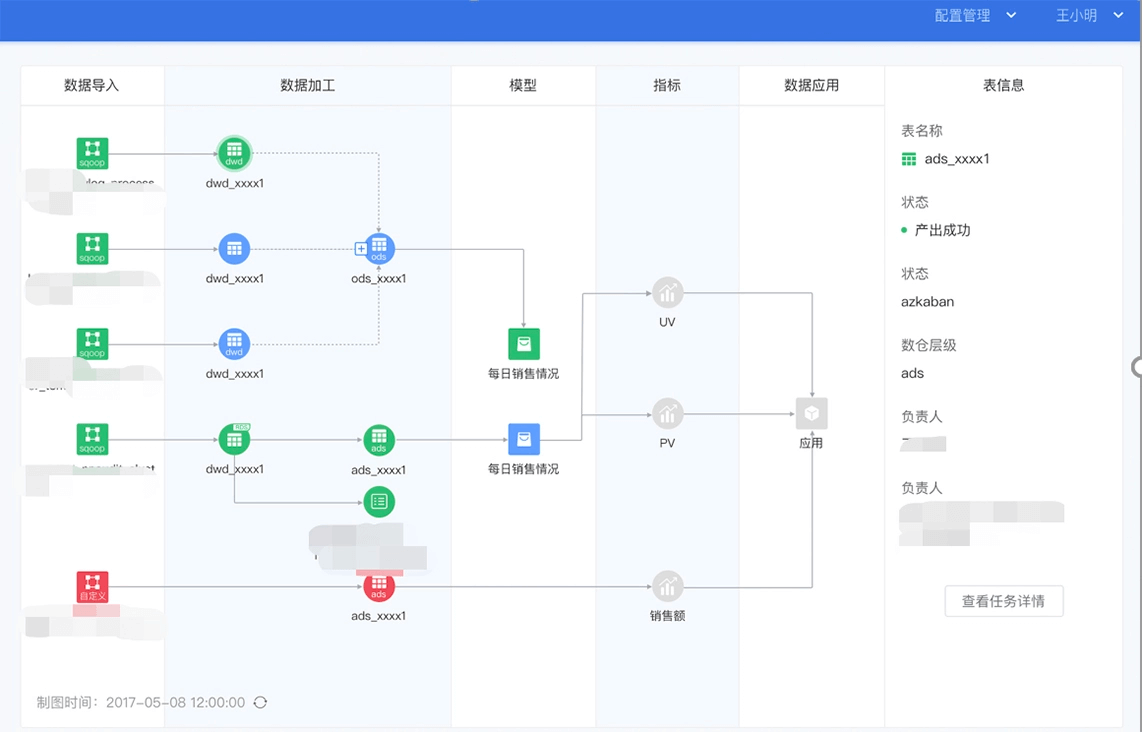
DQC 还提供了全链路监控的功能,覆盖了从数据导入、数据加工、模型产出、指标、到数据应用的完整链路。绿色节点代表数据正常,蓝色节点代表数据正在产出中,红色节点代表数据异常,灰色节点代表产出任务还未被调度到。通过这个监控,大幅提高了问题发现和定位的速度。
所以你可以发现,一个好用的 DQC, 必须要具备的功能就是质量度量、稽核规则管理以及全链路监控。
总结
- 数据质量治理必须要做到全链路,从业务系统的数据源到指标所在的应用,这样可以提前发现问题,将故障消灭在摇篮中;
- 根据应用的优先级和全链路血缘关系,圈定核心任务,要确保核心任务的稽核规则全覆盖,优先保障核心任务的按时产出,在资源紧缺时,有必要停止非核心任务;
- 稽核规则的完备性,可以通过数据架构师团队对每个域下的核心表进行评审的方式保障,同时问题回溯和复盘,也可以不断地完善。

若有收获,就点个赞吧
0 人点赞
