SQL执行过程和优化器
首先看一下MySQL中,一条sql的执行过程,这里主要是引用了《高性能MySQL》中的内容: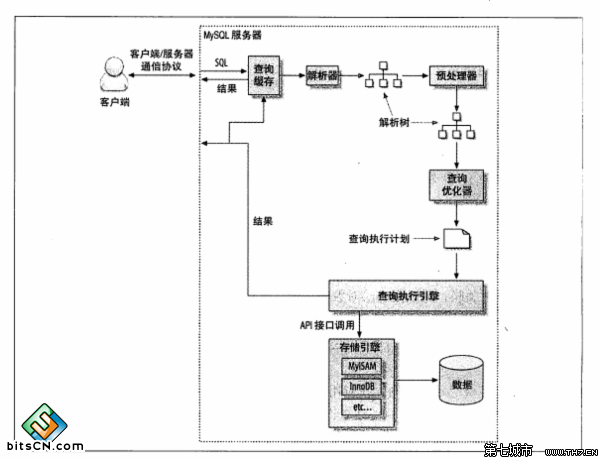
1、客户端发送一条查询给服务器
2、服务器先检查查询缓存,如果命中缓存则立刻返回存储在缓存中的结果,否则进入下一阶段。
3、服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
4、MYSQL根据优化器生成的执行计划调用存储引擎的API来执行查询
5、将结果返回给客户端
对于mysql来说,底层的存储引擎主要的工作就是对数据的磁盘文件进行操作,上层的sql解析等操作主要放在服务器层,服务器层根据sql进行优化和解析生成执行计划,最后存储引擎根据执行计划来调用数据,有机会一定要读一下这个源码,体会一下这个过程。
Tips:一个sql查询往往有很多种方式,可以弄成子查询,也可以用表连接,这个地方的选择主要就是由优化器来负责。在oracle中,优化器主要有:
- rbo:基于规则的优化器
- cbo:基于代价的优化器
rbo已经被抛弃不使用了,目前主流使用基于代价的cbo。
基于代价就要计算代价,初始情况下,计算代价的最小单位就是随机读取一个4k页面的成本,并选择其中成本最小的执行计划,后来引入了一些复杂的计算因子来计算某些操作的代价。机器毕竟是机器,很多情况下,cbo优化器也会发生优化不准确的情况,所以这也是为什么需要了解执行过程的原因。
很多情况下都会导致优化器选择了错误的执行计划,并不能获得最好的性能:
- 统计信息不准确,mysql依赖存储引擎提供的统计信息来评估成本,但是有的存储引擎提供的信息是准确的,有的不准确
- 执行计划中的成本估算不等同于实际执行的成本,因为MYSQL层面并不知道那些页面在内存和磁盘上所以到底需要多少次物理IO未知。
- MySQL的最优化和你的最优化并不一样(目标不同,可能你希望最少时间,MySQL优化目标是最大吞吐量)
- MYSQL不考虑并发查询
- MYSQL并不是任何时候都基于成本优化
- MYSQL不会考虑不受其控制的操作的成本
执行计划分析
Mysql Explain执行计划
通过再查询SQL前面添加Explain关键字,来实现查看 执行计划
EXPLAIN select * from wx_ib where id=500;
- select_type
每个select子句的类型,主要分成下面几种:
a. SIMPLE:查询中不包含任何子查询或者union
b. PRIMARY:查询中包含了任何复杂的子部分,最外层的就会变成PRIMARY
c. SUBQUERY:在SELECT或者WHERE列表中包含了子查询
d. DERIVED:在FROM中包含了子查询
e. UNION:如果第二个SELECT出现在UNION之后,则被标记为UNION,如果UNION包含在FROM子句的子查询中,外层SELECT会被标记为:DERIVED
f. UNION RESULT从UNION表获取结果的select - type
是指MySQL在表中找到所需行的方式,也就是访问行的”类型”,从a开始,效率逐渐上升:
a:all:全表扫描,效率最低
b:index:index会根据索引树遍历
c:range:索引范围扫描,返回匹配值域的行。
d:ref:非唯一性索引扫描,返回匹配某个单独值的所有行。一般是指多列的唯一索引中的某一列。
e:eq_ref:唯一性索引扫描,表中只有一条记录与之匹配。
f:const、system:主要针对查询中有常量的情况,如果结果只有一行会变成system
g:NULL:显而易见,既不走表,也不走索引 - possible_keys
possible_keys列预估了mysql能够为当前查询选择的索引,这个字段是完全独立于执行计划中输出的表的顺序,意味着在实际查询中可能用不到这些索引。
如果该字段为空则意味着没有可使用的索引,这个时候你可以考虑为where后面的字段建立索引 - key
这个字段表示了mysql真实使用的索引。如果mysql优化过程中没有加索引,可以强制加hint使用索引
性能明细查看
show profiles;(如果未开启的话,set profiling=1;)
可以查看具体的耗时信息

若有收获,就点个赞吧
0 人点赞
