1. 概论
几个概念:
- InnoDB的行锁是建立在索引的基础之上的,行锁锁的是索引,不是数据,所以提高并发写的能力要在查询字段添加索引
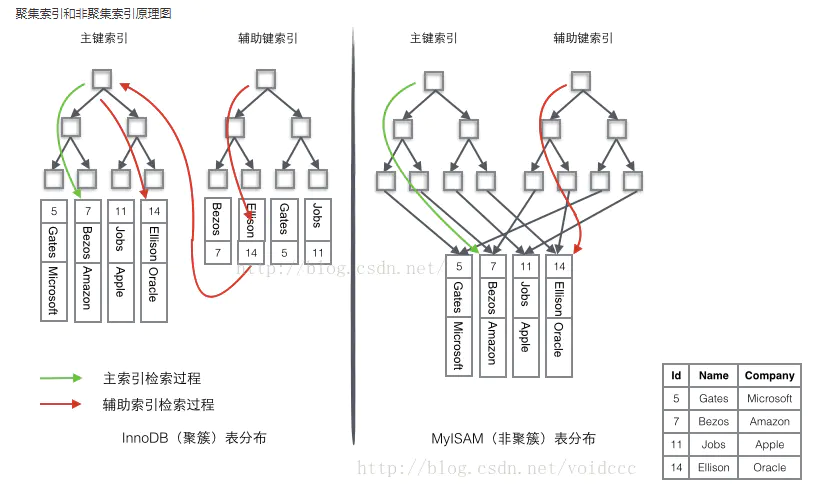
- 主索引和辅助索引:主索引就是主键索引,辅助索引就是根据业务需要,自己设置的普通的非主键的索引。这个在Myisam里面区别不大,但是在Innodb的时候差别很大
- 聚簇索引:Innodb的主索引采用的是聚簇索引,一个表只能有1个聚簇索引,因为表数据存储的物理位置是唯一的。聚簇索引的value存的就是真实的数据,不是数据的地址。主索引树里面包含了真实的数据。key是主键值,value值就是data,key值按照B+树的规则分散排布的叶子节点。
- 非聚簇索引:Myisam的主索引和辅助索引都采用的是非聚簇索引,索引和表数据是分离的,索引的value值指向的物理的存储地址。
- Innodb的索引:主索引采用聚簇索引,叶子节点的value值,直接存储的真实的数据。辅助索引是非聚簇索引,value值指向主索引的位置。所以Innodb中,根据辅助索引查询值需要遍历2次B+树,同时主键的长度越短越好,越短副主索引的value值就越小。但是Innodb中根据主键进行范围查询,会特别快。
- Myisam的索引:主索引和辅助索引都是非聚簇索引
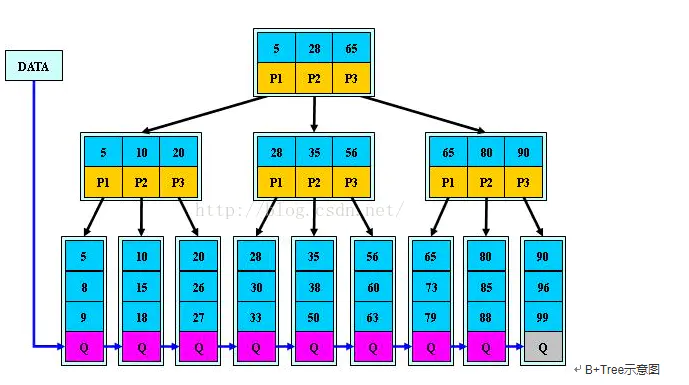
- B+树:不管是什么索引,在mysql中的数据结构都是B+树的结构,可以充分利用数据块,来减少IO查询的次数,提升查询的效率,如图所示,一个数据块data里面,存储了很多个相邻key的value值,所有的非叶子节点都不存储数据,都是指针。
- Mysql采用B+树的优点:IO读取次数少(每次都是页读取),范围查找更快捷(相邻页之间有指针)
2. 聚集索引
- 聚集索引就是叶子节点的顺序和物理存储的顺序是一样的,所以范围查找的时候效率很高,但是DML操作的时候,为了维护物理存储的顺序和叶子节点一样,涉及到大量的数据位移调整。
- 聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。正因为一个表最多只能有一个聚簇索引,所以它显得更为珍贵,一个表设置什么为聚簇索引对性能很关键
举例:主键为id的表中,范围查找 where id<1000 and id>200
则只需要找到ID=200和 ID=1000的叶子节点对应的位置,捞取数据块中间的所有的数据,就是要查找的范围数据了。但是如果以前没有ID=300这个数据,现在新增一个ID=300的数据,那么 ID>300的所有的数据都要往后挪一个位置。
3. 树形结构科普
1. 叶子节点
叶子节点,指的是最外层的节点,就像一棵树,只有最外层的节点才长叶子
2. 二叉搜索树的特点
- 所有结点至多拥有两个儿子(Left和Right);
- 所有结点只存储一个关键字(可以理解为索引,比如ID值);
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
- 二叉搜索树如果是满二叉树时,查找的性能逼近有序数组的二分查找,同时插入的性能远远高于有序数组,因为只需要再对应的节点添加引用,而不需要移动任何老的节点
3. B-Tree的特点(B树)
- 所有键值分布在整个树中(区别与B+树,B+树的值只分部在叶子节点上)
- 任何关键字出现且只出现在一个节点中(区别与B+树)
- 搜索有可能在非叶子节点结束(区别与B+树,因为值都在叶子节点上,只有搜到叶子节点才能拿到值)
- 在关键字全集内做一次查找,性能逼近二分查找算法
4. B+树的结构特点
- B+树索引并不能找到一个给定键值的具体行,它找到的只是被查找数据行所在的页,接着数据库会把页读入到内存,再在内存中进行查找,最后得到要查找的数据。数据的读取是精确到页的,因为页是计算机管理存储器的逻辑块,IO的磁盘读取,每次都读取数据的大小是一个页大小的整数倍。
- 假设B+Tree的高度为h,一次检索最多需要h-1次I/O(根节点常驻内存),复杂度O(h) = O(logmN),m指的是一个节点存储的数据的个数。实际应用场景中,M通常较大,常常超过100,因此树的高度一般都比较小,通常不超过3。
- B+树与B树的不同在于:
- 所有关键字存储在叶子节点,非叶子节点不存储真正的data
- 为所有叶子节点(左右相邻的节点之间)增加了一个链指针
5. 为什么数据库使用B+而不使用红黑树呢?
- 计算器在IO磁盘读取的时候,为了降低读取的次数,默认一次会读取一个页的数据量,MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。linux 默认页大小为4K。所以每次IO读取,都是读取一个页的数据量,所以B树的节点都是存储一个页的节点,这样的查询效率才是最高的
- 每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。这样大大降低了树的高度
6. 为什么mysql的索引使用B+树而不是B树呢?
- 范围查找更快,mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树的数据有一部分存在在非叶子节点上面,而且默认的B树的相邻的叶子节点之间是没有指针的,所以范围查找相对更慢。
- 降低树的高度,但是最底下一层的节点会更多,因为所有的数据都堆积在最底下一层了,用空间换速度。B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高
4. B+树插入和删除的逻辑
- 插入:和红黑树特别像,新数据插入到一个满了的节点中时,会优先进行左旋右旋,如果邻近的节点都满了的话,会取中间的一个key往上一个层级插入,直至到Root节点,树的高度的增加,都是通过根节点的拆分来完成的,这保证了所有左右节点的高度差不超过1
- 删除:会进行调整优化树形结构,使树的数据更分散,以及降低树的高度。比如如果该节点的数据过少,可以从邻近的节点左旋 右旋数据来填充。可能的话,降低一个树的高度。
5. 为什么Mysql不选择Hash索引?
Hash索引的优势是精确查找的话,速度会更快,为什么不选择Hash索引
- Hash索引不适合范围查找,而B+树特别适合范围查找(特别是聚簇索引的时候)
- Hash索引每次查询要加载所有的索引数据到内存当中,而B+树只需要根据匹配规则选择对应的叶子数据加载即可
- 另外B+树引入了缓存机制 和 数据页技术来提升性能(不过理论上来说,这两个特性Hash索引也可以实现)

若有收获,就点个赞吧
0 人点赞
