outline
- 概念
- 预处理
- 特征选择
-
概念
数据集由数据对象组成,一个数据对象代表一个实体
属性(attribute)是一个数据字段,表示数据对象的一个特征。属性向量(或特征向量)是用来描述一个给定对象的一组属性。
属性的分类: 标称属性(nominal attribute)
- 二元属性(binary attribute)
- 序数属性(ordinal attribute)—- 常量表中的某个值
数值属性(numerical attribute)= 离散属性 + 连续属性
数据清洗
数据增强( Data Augmentation)
数据增强是指从给定数据导出的新数据的添加
如CV领域中的图像增广技术预处理
缺失值的处理
(1)丢弃
(2)均值
(3)上下数据填充
(4)插值法 线性插值
(5)随机森林拟合标准化和归一化
标准化
标准化是依照特征矩阵的列处理数据,使每个特征中的数值平均变为0(将每个特征的值都减掉原始资料中该特征的平均)、标准差变为1
基于正态分布假设
标准化后可能为负
(X-X_mean)/std- 归一化
对每个样本计算其p-范数,再对每个元素除以该范数,这使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。 - 区间缩放法
常见的一种为利用两个最值进行缩放
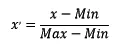
具有加速收敛的作用,原因如下图:
可以使用sklearn中的preproccessing库来进行数据预处理
特征选择
定义: 从给定的特征集合中选择出相关特征子集的过程
两个关键问题:
- 子集搜索
forward搜索: 逐渐增加相关特征的策略
backward搜索:逐渐减少特征的策略
bidirectional搜索 - 子集评价
特征选择的作用
- 减少(冗余)特征数量、降维,使模型泛化能力更强,减少过拟合
- 增强对特征和特征值之间的理解
-
过滤式(filter)
特点:特征选择过程和学习器无关
通过特征的某个统计量值来进行排序,选择Top K特征
from sklearn.feature_selection import SelectKBest 基于方差
- 基于信息增益
去除方差较小的特征,譬如某些特征只有一个值
ID3算法在选择节点对应的特征时也是使用信息增益
对于决策树来说,树节点的划分属性所组成的集合就是选择出的特征子集
- Pearson相关系数
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。 - 互信息量
互信息(Mutual Information)是度量两个事件集合之间的相关性(mutual dependence)。互信息最常用的单位是bit。
根据互信息计算公式可得: 当互信息MI=0时,两个变量(两个事件集合)之间相互独立 χ2统计量(卡方检验)
χ²检验用来检验两个事件的独立性。
χ2 值越大,则表明实际观察值与期望值偏离越大,也说明两个事件的相互独立性越弱。
wrapper
特点:将后续学习器的性能作为特征子集的评价准则
将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较
启发式算法
from sklearn.feature_selection import RFELas Vegas Wrapper(LVW)
在LVW中,特征子集搜索采用了随机策略,然后训练学习器进行交叉校验。- 基于学习模型的特征排序
这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。交叉验证后,根据分数值对特征进行排序。
特征和响应变量之间的关系是线性:线性回归
假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等embedding
特点:特征选择过程与学习训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择
from sklearn.feature_selection import SelectFromModel
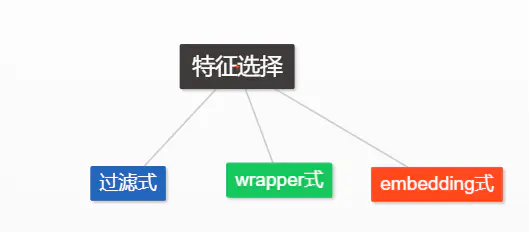
L1和L2范数都有助于降低过拟合风险L1正则化/Lasso
L1正则化将系数w的l1范数作为惩罚项加到损失函数上,由于正则项非零,这就迫使那些弱的特征所对应的系数变成0
防止过拟合
更容易获得系数解
L2正则化/Ridge regression岭回归
L2正则化对于特征理解来说更加有用:表示能力强的特征对应的系数是非零
降维
定义:通过某种数学变化将原始高维属性空间转变为低维子空间(subspace)
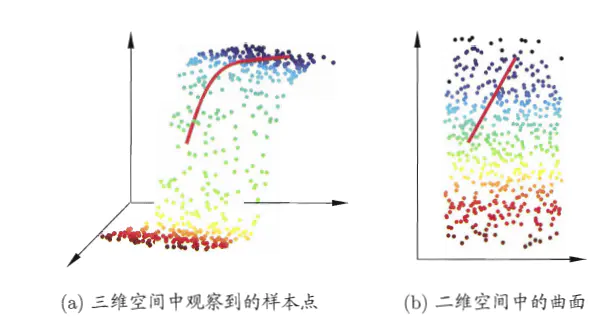
低维嵌入(三维—>二维):
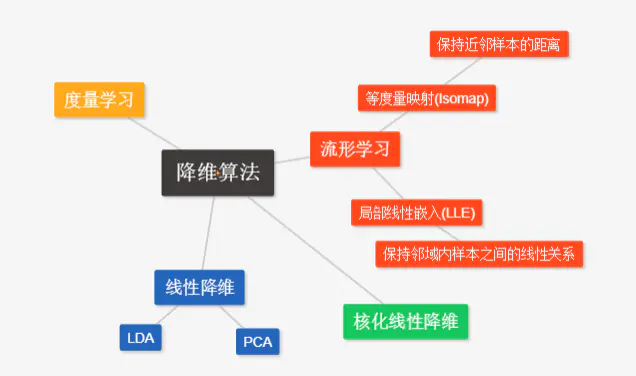
降维方法分类
一、简述:
在机器学习领域,有一句话说“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”可见特征工程和数据在机器学习中占有相当重要的位置。在实际的应用中,很多数据挖掘比赛例如天池比赛,优秀选手最后的成绩往往是特征做做足了文章从而使得最后的效果比较好,因此数据是基础,特征是成功的关键。
下面主要从下面三个方面来学习特征工程:
l 特征工程是什么?
l 为什么要做特征工程?
l 怎么做特征工程?
l 特征工程的处理过程?
二、特征工程是什么
特征工程,就是最大限度的从原始数据中提取特征(包括不同维度的、组合的、单一的)以供算法和模型使用。通过特征工程提取的特征能够基本全面的通过不同的维度描述原始数据。在数学角度上就是一个多项式公式:y=w1x1 w2x2 …….其中,x1,x2….等就是特征。
三、特征工程的必要性
任何一个机器学习问题,最终都会转化为算法模型、样本数据、样本数据的特征及评估效果精度。他们之间是相互依赖的。
l 特征越好,灵活性越强
算法模型依赖于数据和特征,只要特征选择的好,那么一般的算法模型就会获取比较好的效果,因此,对于好的特征方便选择复杂程度不同的算法模型,进行多次尝试。
l 特征越好,模型的效果就越好
四、特征工程的构建流程
业界的特征工程一般包括特征构建、特征提取、特征选择这三个子模块。
1、特征构建:
特征构建是从原始数据中人工找出一些具有物理意义的特征。需要全面的了解数据样本,人工的创建特征。
通常使用的方法包括:
属性组合:比如将多个属性组合成为一个特征,比如性别女和年龄25可以构造出女青年的特征,年龄35和女性可以标记为女中年。
属性分割:日期数据可以分割为季度、周期、具体时间段等特征。
2、特征提取
特征提取的对象是原始数据,目的是将原始的特征转化为一组具有明显物理意义或者统计意义的特征。比如说通过变换特征取值来减少原始数据中某个特征取值的个数。或者将连续的特征变化为离散的特征。
常用的方法有下面几个:
(1) PCA主成分分析
主成份分析目的就是使得数据点在特定的向量上的投影方差最大。而我们就是要求出这个向量。当数据的维度很大时,对高维数据的计算可能会耗费大量的计算资源,通过PCA可以降低计算的复杂性避免过拟合现象的发生。
具体流程是:主成份分析就是求出原始数据矩阵的协方差矩阵对应的特征值和特征向量,对特征值进行由大而小的排序,再根据特征值对应的特征向量进行线性变换,得到新的向量(新的向量间相互正交)。通过设定阈值可以用低维的新向量近似表示高维的原向量(协方差矩阵为非奇异的);若协方差矩阵为奇异的,且零特征值较多,这种情况使用低维的新向量也可以完全表示高维原向量。
(2) LDA线性判别分析
LDA的原理是将带上标签的数据(点),通过投影的方法,投影到维度更低的空间,使得投影后的点,会形成按类别区分,相同类别的点,将会在投影后更接近,不同类别的点距离越远。
(3) ICA 独立成分分析
PCA特征转换降维,提取的是不相关的部分,ICA独立成分分析,获得的是相互独立的属性。ICA算法本质寻找一个线性变换z = Wx,使得z的各个特征分量之间的独立性最大。ICA相比与PCA更能刻画变量的随机统计特性,且能抑制噪声。
3、特征选择
特征选择是剔除不相关或者冗余的特征,减少有效特征的个数,减少模型训练的时间,提高模型的精确度。特征提取通过特征转换实现降维,特征选择则是依靠统计学方法或者于机器学习模型本身的特征选择(排序)功能实现降维。特征选择是个重复迭代的过程,有时可能自己认为特征选择做的很好,但实际中模型训练并不太好,所以每次特征选择都要使用模型去验证,最终目的是为了获得能训练出好的模型的数据,提升模型的性能。
通常衡量特征与目标变量之间的关系,然后选择排名靠前的特征,从而达到特征选择的目的,通常的方法有:
(1)Filter(刷选器):它主要侧重于单个特征跟目标变量的相关性。优点是计算时间上较高效,对于过拟合问题也具有较高的鲁棒性。缺点就是倾向于选择冗余的特征,因为他们不考虑特征之间的相关性,有可能某一个特征的分类能力很差,但是它和某些其它特征组合起来会得到不错的效果。
(1.1) Pearson相关系数
公式: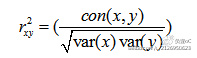
其中x属于X,X表一个特征的多个观测值,y表示这个特征观测值对应的类别列表。Pearson相关系数的取值在到1之间,通过相关系数,就会得到一个特征排名。
(1.2) Frequency :如果是文本,去掉停用词等,特征就是词频
(1.3) TF/IDF :(tf/n)/log(df 1),其中tf表示词在该篇文档中频率,n表示该篇文档词总数,df表示该词在文档集的文档频率。
(1.4) 信息增益:选择一个特征,对于当前这个数据集分类的效果有多大的提升。信息增益的本质计算的是,使用该特征,使得数据集不确定性减少的多少,换言之就是该特征带来了多少的信息量。
(1.5) 互信息:互信息,描述的是两个变量之间的依赖程度,互信息越大,关联性越强。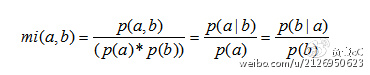
其描述的就是某个变量在另一个变量出现的情况下的条件概率,占该变量出现情况的比例。这个比例越大,显然这两个变量越相关。如果其中一个变量是分类的结果,那么其表示的就是一个特征和分类结果的相关程度。但是该方法有个弊端就是,倾向于选出低频的变量,因为越是低频的特征,分子和分母接近的可能性越大,所以导致这个方法选出的特征比较低频。
(1.6) 方差选择法:使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
(2)Wrapper(封装器):封装器用选取的特征子集对样本集进行分类,分类的精度作为衡量特征子集好坏的标准,经过比较选出最好的特征子集。优点是考虑了特征与特征之间的关联性,缺点是:当观测数据较少时容易过拟合,而当特征数量较多时,计算时间又会增长。
常用的有逐步回归(Stepwise regression):递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练
向前选择(Forward selection)和向后选择(Backward selection)
(3)Embeded(集成方法):自主的学习选择特征,比如用正则化、或者GBDT、随机森林等选择特征。
正则化包括L1和L2正则化。其中L1正则化趋向于使得不重要的特征为,直接使用重要的特征。L2正则化趋向于使得不重要的特征接近于,使得其重要性降低。
或者通过GBDT选择组合特征,作为其他模型的输入特征。常用的情况就是利用GDBT产生新的特征。作为LR模型使用。
例如:在推荐系统中,常见的CTR预测使用的是LR模型,但是因为特征的局限性,往往由于特征数量少或者特征质量差导致模型的效果不是很好。因此利用GDBT模型能够发现多种有区分性的特征以及组合特征。决策树的路径可以直接作为LR输入特征使用。
五、特征处理的过程
一般的机器学习过程主要包括下面几个方面:
1)选择数据:选择基础数据
2)数据预处理:数据格式化,数据清理,数据采样等,属于特征工程的一部分
3)数据转化:特征工程另一部分
4)数据建模:建立模型,评估模型并不断迭代优化,主要是交叉验证。
其中2)和3)中都可以作为特征工程的一部分。
在数据预处理的过程中:
首先是进行异常数据清洗,剔除掉不符合要求的基本数据,同时因为样本很多时候是不平衡的,所以必须对样本进行采样,包括上采样和下采样,这样就不会因为样本不平衡影响最后模型的学习精度。
其次是对一些单个特征进行数据处理,包括归一化,离散化、缺失值补填、数据变换(log、指数变换等)。
下面举例说明特征工程的处理。
1、对于特征处理,假设数据中有一个人物类别的特征,比如:cat,取值只有三个,分别是:青年,中年,老年。这是一个离散的特征,可以转化为一个二值特征,取值为或者1. 其中1表示中年以上,表示中年以下,这样就可以通过线性模型进行训练。
2、常见的特征就是时间特征,数据格式往往是这样的:2016-12-12 20:45:40 .对于时间的处理,可以从中提取出来很多属性,比如季节、月份、周期、天,等特征。比如目前是冬季、12月、星期一、晚上等。这样就能构建出来很多人工特征,然后经过特征工程处理为模型可用的特征。

若有收获,就点个赞吧
0 人点赞
