机器学习是解决人工智能问题的最核心的技术
机器学习的核心是,从数据中自动学出规律,可以简单的理解为归纳总结。
深度学习是机器学习的一个分支,是一个算法,指的不是一个特定的模型,而是一个框架,或者可以认为是一类方法论。
机器学习分为监督学习、无监督学习
监督学习拥有大量例子,只要有标签,而且跟预测有关
无监督学习主要以聚类分析为主,不依赖于数据的标签
机器学习还包括强化学习,经典代表作:AlphaGo
监督学习的例子:人脸识别、语音识别、主题分类、机器翻译、目标检测、金融风控、情感分析、自动驾驶
无监督学习的例子:相似样本分类、用户分层(兴趣爱好相同)
区分监督学习和无监督学习:有没有使用数据的标签
常见的机器学习的算法:
监督学习: 无监督学习:
线性回归 PCA(降维)
逻辑回归 K-means
朴素贝叶斯(文本分类) Gmm
决策树 LDA(抽取主题特征)
随机森林
SVM
神经网络
回归与分类问题:
回归问题:输出是连续性数值,比如温度,身高,气温等。
分类问题:输出是定性输出,比如阴或晴、好与坏
训练数据:用来训练模型
测试数据:用来评估模型
机器学习建模流程Data source ——>数据预处理——>特征工程——>建模——>验证
((语音识别)——>从数据预处理跳过特征工程直接建模:端到端的方法)——>集中在深度学习
KNN,中文叫K近邻算法。KNN主要用于分类问题,但这不意味着不能解决回归问题
一般对于二分类问题来说,把K设置为奇数是容易防止平局的现象。
实现一个KNN算法,我们需要具备四个方面的信息:

任何的算法的输入一定是数量化的信息,我们把它叫做特征,需要把现实生活中的物体通过数字化的特征来进行描述
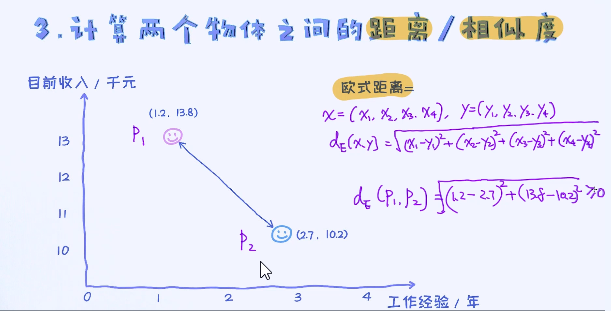
KNN是监督学习算法,所以需要提前标注好的样本。需要想办法来计算两个样本之间的距离或者相似度,之后才能选出最相近的样本。
自己手动写一个KNN算法解决分类问题。 主要的模块包括欧式距离的计算以及投票环节。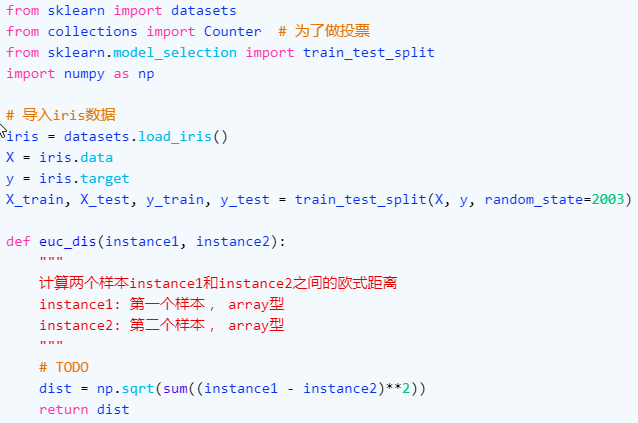

为了理解K值对算法的影响,我们首先要了解一个很重要的概念叫做决策边界
比如我的决策是:当华为Mate降价到2000元的时候购买一个。对于这个问题,我的决策边界是2000元
决策边界分成两大类,分别是线性决策边界和非线性决策边界。拥有线性决策边界的模型我们称为线性模型,反之非线性模型。
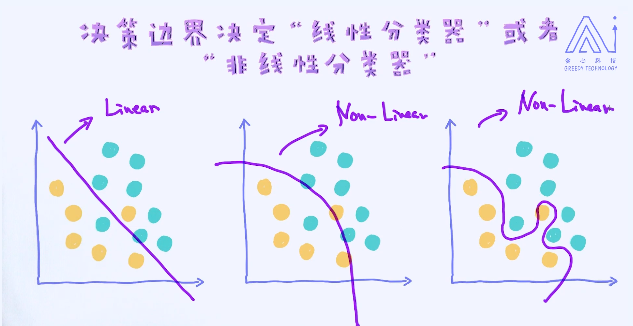
以上图中最后一个决策边界在数据上的表现是最好的。但这不代表未来数据上,也就是测试数据上表现最好。这里涉及到了一个很重要的概念,叫做模型的泛化能力,可以简单理解成“它在新的环境中的适应能力”,当然这个环境需要跟已有的环境类似才行。
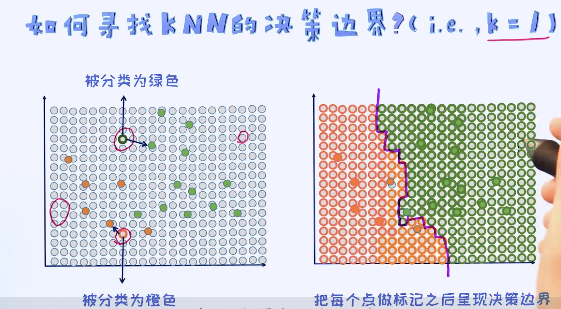
K=1时候的决策边界我们已经知道如何去找了,那K取其他值的时候呢? 其实过程都一样。我们都要通过KNN算法去预测每一个点,然后最终即可以得到决策边界。随着K值的增加,决策边界确实会变得更加平滑。决策边界的平滑也意味着模型的稳定性。这个其实很好理解,平时工作当中多个人共同决策要比一个人决策会大概率上减少犯错误。但稳定不代表,这个模型就会越准确。
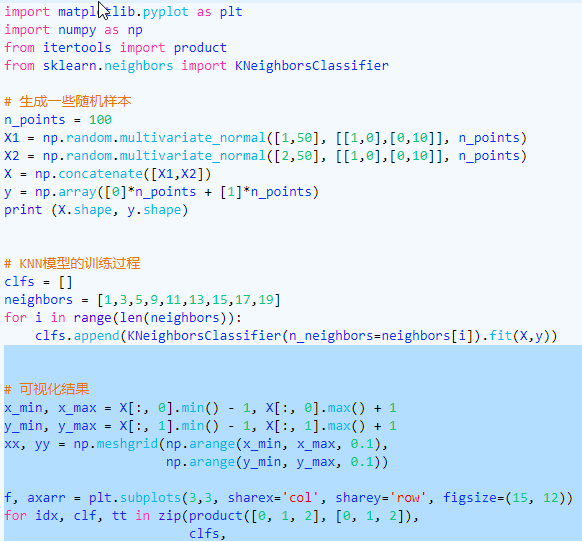

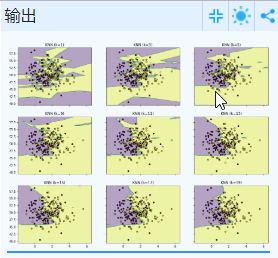 很容易看出K值的增加会导致决策边界越来越平滑。虽然决策边界平滑会使得模型变得更加稳定,但稳定不代表模型的准确率更高。
很容易看出K值的增加会导致决策边界越来越平滑。虽然决策边界平滑会使得模型变得更加稳定,但稳定不代表模型的准确率更高。
这就类似于我们投资股票,我们如果寻求特别的稳定,就意味着最终的收益会很少,但至少抗风险能力会很强。所以一般都会平衡风险和收益,从而选择最合适的平衡点。那这个平衡点,又如何选择呢? 答案就是交叉验证(cross validation)
交叉验证是机器学习建模中非常非常重要的一步,也是大多数人所说的“调参”的过程。
在KNN里,通过交叉验证,我们即可以得出最合适的K值。它的核心思想无非就是把一些可能的K逐个去尝试一遍,然后选出效果最好的K值。
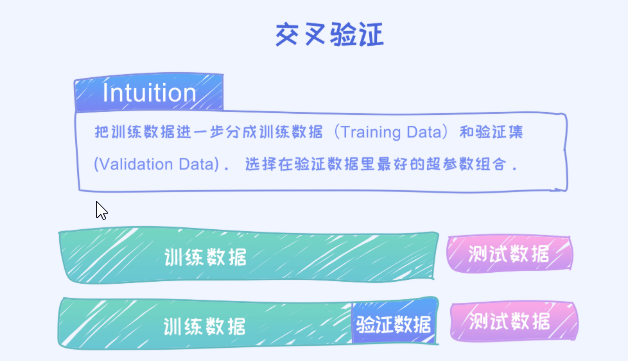
常用的交叉验证技术叫做K折交叉验证(K-fold Cross Validation)。 我们先把训练数据再分成训练集和验证集,之后使用训练集来训练模型,然后再验证集上评估模型的准确率。举个例子,比如一个模型有个参数叫\alphaα,我们一开始不清楚要选择0.1还是1,所以这时候我们进行了交叉验证:把所有训练集分成K块,依次对每一个\alphaα值评估它的准确率。
总结起来的话,针对不同的K值,逐一尝试从而选择最好的。并且,这种参数我们称作超参数(Hyperparameter)。
一般情况下数据量较少的时候我们取的K值会更大,为什么呢? 因为数据量较少的时候如果每次留出比较多的验证数据,对于训练模型本身来说是比较吃亏的,所以这时候我们尽可能使用更多的数据来训练模型。由于每次选择的验证数据量较少,这时候K折中的K值也会随之而增大,但到最后可以发现,无论K值如何选择,用来验证的样本个数都是等于总样本个数。
最极端的情况下,我们可以采用leave_one_out交叉验证,也就是每次只把一个样本当做验证数据,剩下的其他数据都当做是训练样本。
实现一段KNN的交叉验证代码:

上述代码是从零开始写的,但实际上我们可以直接使用sklearn来实现同样的逻辑,只需要调用即可以实现K折交叉验证:
那具体候选的K值是如何提前设定好的呢? 答案是认为的方式提前都列好的。
那如何列出比较靠谱的候选K值呢?对于KNN来讲,我们一般从K=1开始尝试,但不会选择太大的K值。而且这也取决于计算硬件,因为交叉验证是特别花时间的过程,因为逐个都要去尝试。
怎样提高交叉验证的效率呢?
最简单的方法就是通过并行化、分布式的处理。针对于不同值的交叉验证之间是相互独立的,完全可以并行化处理。
注意:绝对不能用测使数据来引导(guide)模型的训练!
绝对不能把测试数据用在交叉验证的过程中,测试数据的作用永远是做最后一步的测试,看是否模型满足上线的标准,但绝对不能参与到模型的训练。
使用KNN算法的时候,特征值上的范围的差异对算法影响非常大。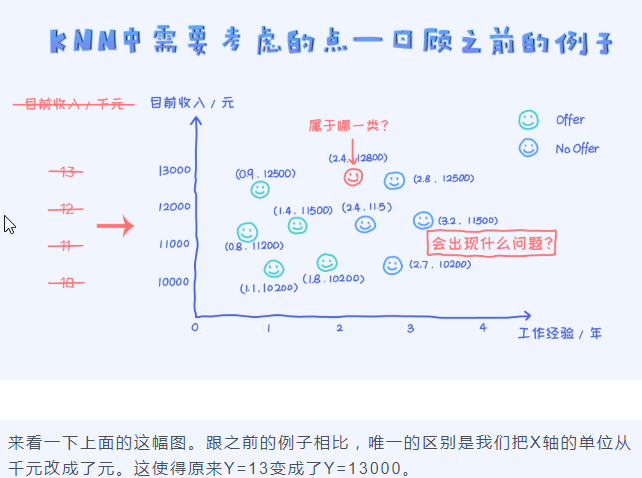
其实不仅仅是KNN算法,只要依赖于距离计算的算法都有这个问题,比如K-means聚类算法。
为了解决这个问题,在应用KNN之前我们经常使用标准化的操作,也就是把特征映射到类似的量纲空间,目的是不让某些特征的影响变得太大。

线性归一化指的是把特征值的范围映射到[0,1]区间,标准差标准化的方法使得把特征值映射到均值为0,标准差为1的正态分布。
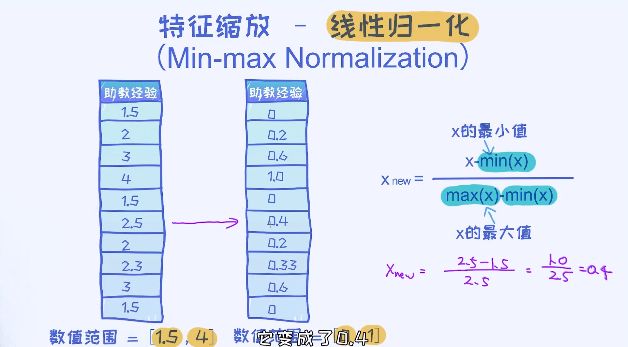

使用上述方法,需要注意的一点是转换后的特征有负有正,而且它们的均值为0。

若有收获,就点个赞吧
0 人点赞
