学习KNN的复杂度以及如何优化KNN的搜索时效
复杂度一般分为两种,时间复杂度和空间复杂度。这里的时间复杂度指的是程序运行时花费的时间,空间复杂度指的是内存消耗的大小。

随着N的增加,复杂度也会以线性的方式增加
常数项不影响N,所以可以去掉,时间复杂度为o(N)
叫做常数的复杂度,即使N变得很大,也是只需要一个常数的空间,空间复杂度为O(1)

随着N的增加,是以N的平方的数组来增加的,时间复杂度为图上
上面的例子相对比较简单,只需要关注循环模块就可以得出结论
时间复杂度:

从小到大:
分析一个递归类程序的复杂度:
一个经典的例子:计算斐波那契数列中的第N个项:
当前的数等于前面两个数相加
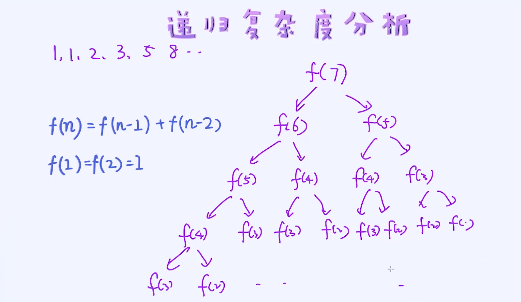
计算每层结点:

时间复杂度:
叫做指数级复杂度
空间复杂度:







除了这些,对于递归类算法比如归并排序,也经常会使用主定理(Master’s Theorem)来求解它的复杂度。可以参考 http://people.csail.mit.edu/thies/6.046-web/master.pdf
KNN在搜索阶段的时间复杂度是多少?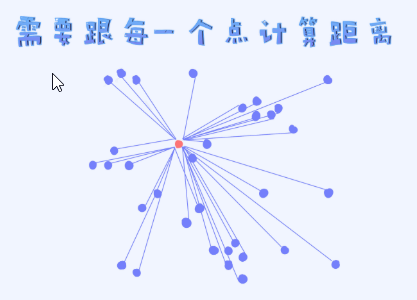
知道KNN在训练阶段不参与任何实质性的模型训练,但在测试阶段需要跟每一个样本做距离的计算。数据量少的时候倒没有关系,但一旦数据量很大时就成为一个瓶颈。
假如有N个样本,而且每个样本的特征为D维的向量。那对于一个目标样本的预测,需要的时间复杂度是多少?正确答案是O(N*D
这个问题其实很简单,首先对于任何一个目标样本,为了做预测需要循环所有的训练样本,这个复杂度为O(N)。另外,当我们计算两个样本之间距离的时候,这个复杂度就依赖于样本的特征维度,复杂度为O(D)。
把循环样本的过程看做是外层循环,计算样本之间距离看作是内层循环,所以总的复杂度为它俩的乘积,也就是O(N*D)。
知道了KNN存在时效性的问题,那有没有办法提升KNN搜索的效率呢?

对于这个问题,其实是存在一些解决方案的,只不过不存在一个完美的方案而已:
第一、时间复杂度高的根源在于样本数量太多。所以,一种可取的方法是从每一个类别里选出具有代表性的样本。

上面的这幅图里,我们从每一个类别中选出了3个具有代表性的样本。在之后的预测阶段,我们只需要计算跟这些样本之间的距离就可以了。
如何选择这些具有代表性的样本呢? 其中一个简单的方法是,对于每一个类的样本做聚类,从而选出具有一定代表性的样本。另一种方法,可以使用近似KNN算法。这种算法仍然是KNN,但是在搜索的过程会做一些近似运算来提升效率,但同时也会牺牲一些准确率。可以参考以下链接:https://www.cs.umd.edu/~mount/ANN/。第三、使用KD树来加速搜索速度,但一般只适合用在低维的空间。
KD树的核心思想:
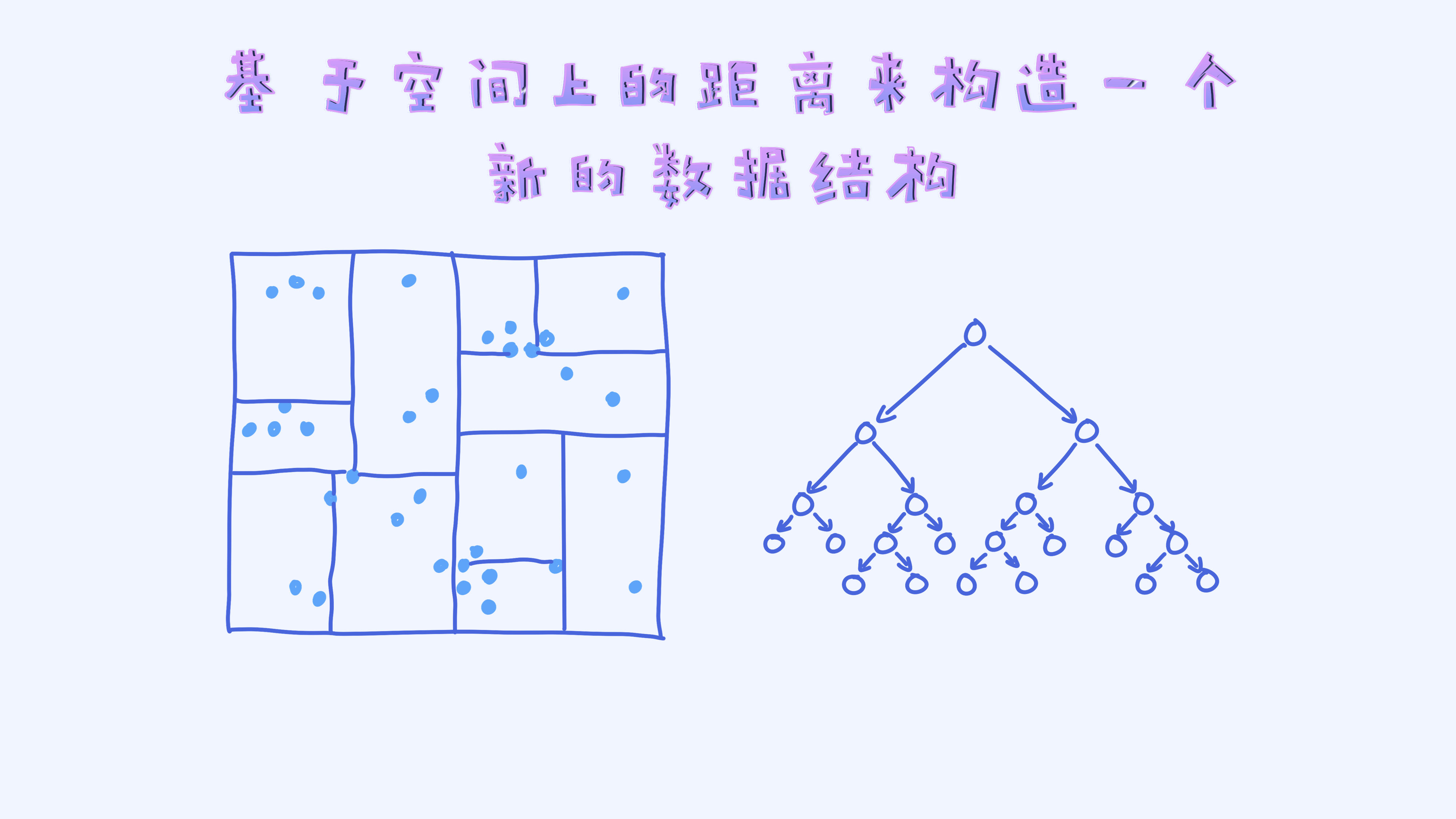
给定左边的这幅图,其实人类是很容易看出哪些点离得比较近,哪些点离得比较远的。而且即便有了新的预测样本,也马上可以通过肉眼观察到离它最近的是哪个,当然说的是在二维的空间里。
但计算机就做不到这一点,它只能通过计算才能判断出哪些点离得比较近,哪些点离得远。所以,我们这里的核心问题是如何让机器也能一眼就能感知到哪些点是离得近的,哪些点是离得远的呢?
为了达到这个目的,我们可以对所有的样本根据它们的位置来划分区域,这样一来每个区域内部的点很大概率上会离得比较近。
所以,我们可以把KD树看作是一种数据结构,而且这种数据结构把样本按照区域重新做了组织,这样的好处是一个区域里的样本互相离得比较近。假如之后来了一个新的预测样本,这时候我们首先来判定这个预测样本所在的区域,而且离它最近的样本很有可能就在这个区域里面。
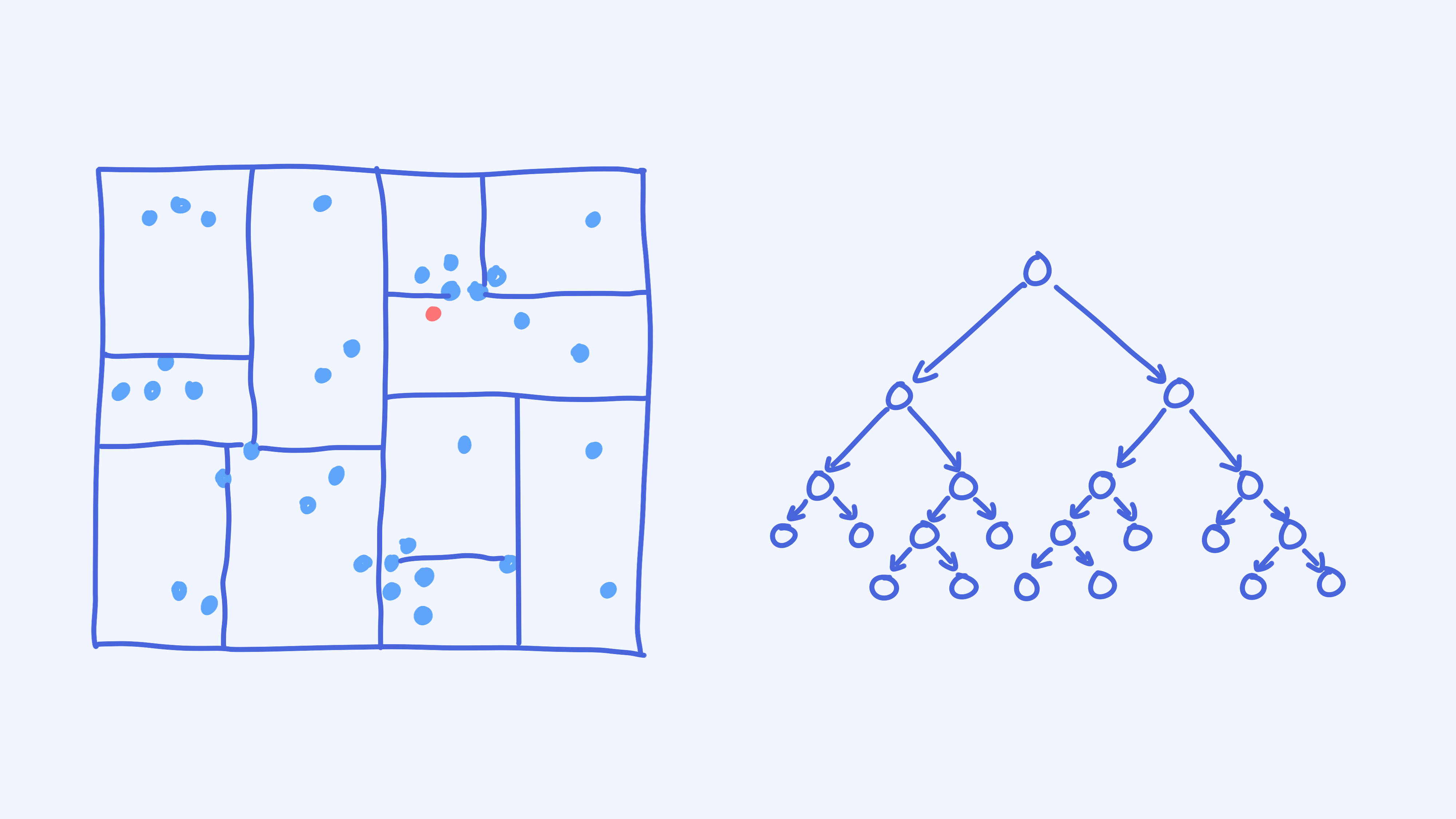
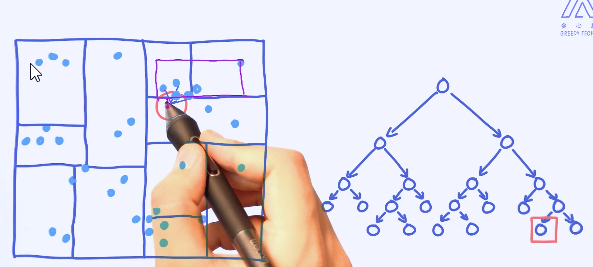
这里的每一个区域在KD树里是一个节点。接下来,我们来看如何基于样本来构造一棵KD树。
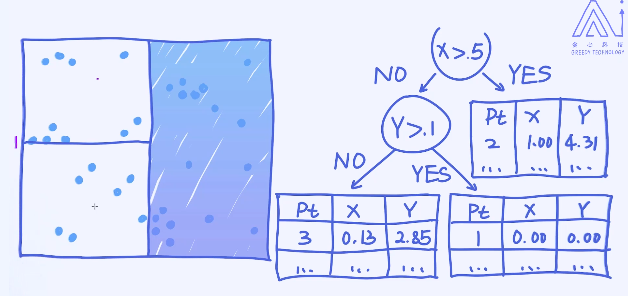
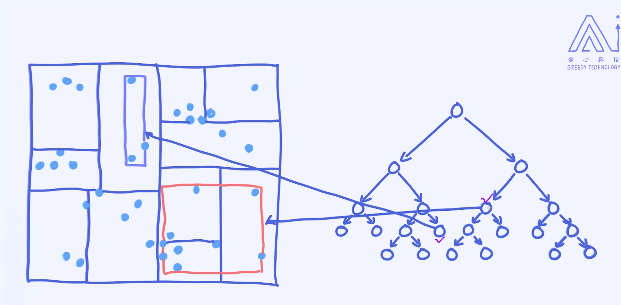
构造完KD树之后,我们就可以用它来辅助KNN的搜索了。
假如图片中红色的点是需要预测的样本,那接下来如何使用KD树来加速搜索过程呢?
确定区域: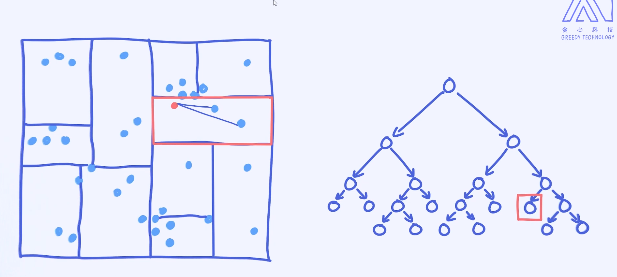
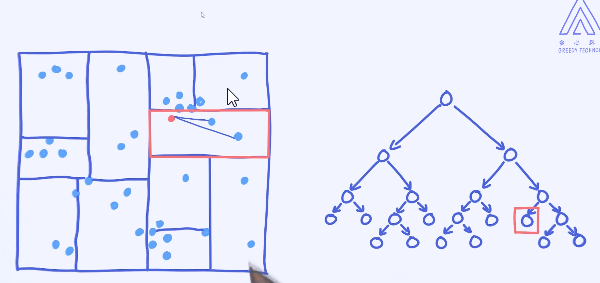
能否确保距离最短的点一定会落在跟预测样本同一个区域里呢?
显然是不能保证的。比如最近的样本有可能在隔壁的区域里。
为了保证能够找到全局最近的点,我们需要适当去检索其他区域里的点,这个过程也叫作Backtracking。
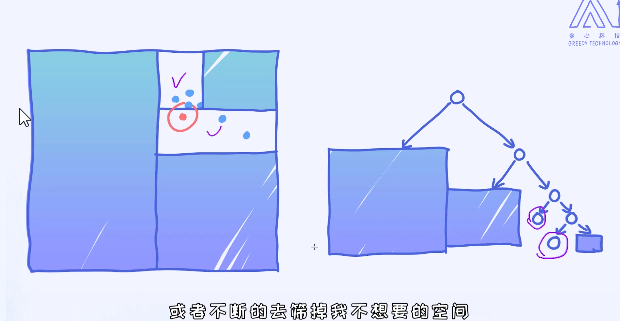

这里的核心思想是:通过KD树这样的数据结构来尽可能减小搜索空间,从而提升效率。
理解了KD树的运行机理之后,我们来分析一下KD树搜索过程所需要的时间复杂度。 一般来讲,搜索的过程需要O(log N)的时间复杂度,这明显要比原来O(N)的复杂度快很多。但是最坏情况下搜索复杂度仍然是O(N),也就是通过Backtracking几乎搜了一遍所有的节点。从这个角度,我们可以得出复杂度的范围为O(log N)和O(N)区间。
然而,上面的复杂度我们只考虑了跟样本数之间的关系。还有一个重要信息是样本的维度,那搜索效率跟特征维度又如何相关呢?
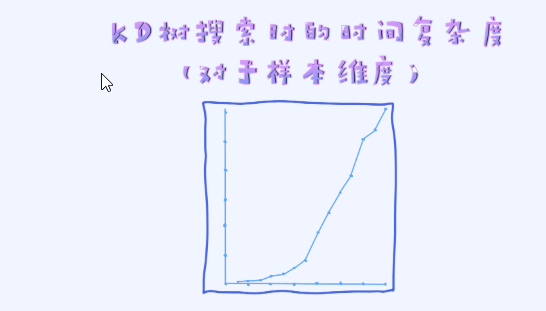
随着特征维度的增加,搜索的时间复杂度会指数级增加,其实没有办法把KD树用在高维的空间里。
由于这个缺点,我们一般在低维的空间里才会试着使用KD树来提升搜索效率。在2,3维空间里尤其常见。
kD树的经典利用场景是地图的搜索
一个KNN的一个拓展应用,叫做带权重的KNN,在之前的应用中不管是分类还是回归,把每一个样本都看作是同等重要。比如在回归问题里,直接做了平均的操作。但这种方法是否合理呢? 接下来看一个例子。
距离越短,权重越大: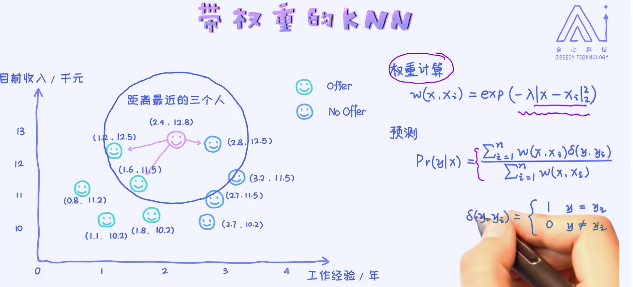
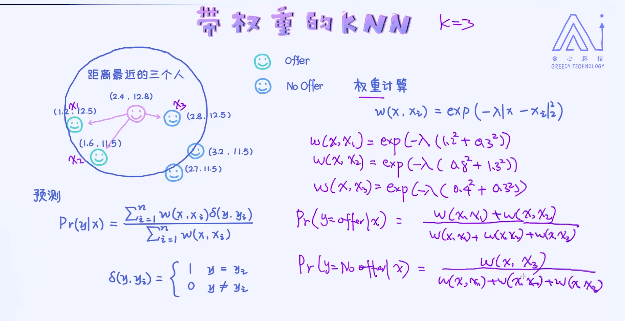
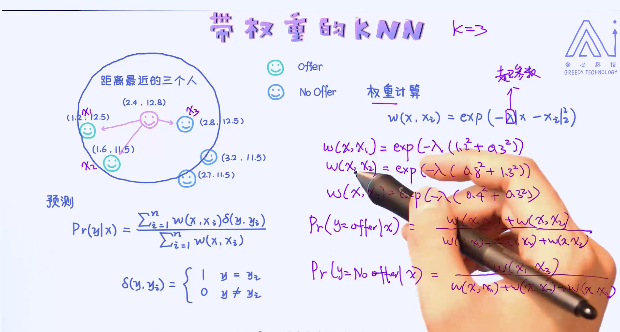
核心思路是,跟预测目标越近的样本给与了更高的权重,离预测目标越远的样本就越低的权重。最后做了加权平均。

若有收获,就点个赞吧
0 人点赞
