我们知道机器学习项目的核心是建模,它的基础是数据。而且,它的输入一定是数值类型的,所以我们不能把一个字符串直接作为一个模型的输入,需要把字符串转换成数值类型,比如向量或矩阵形式。
类别型变量:
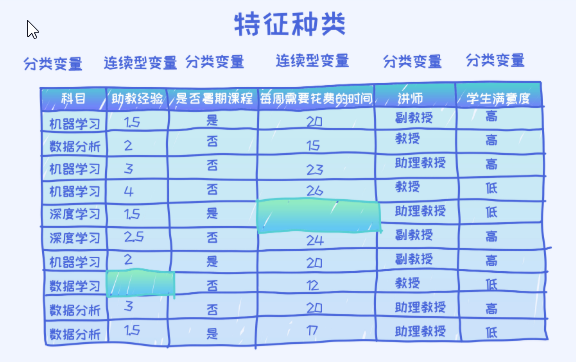
在上面的数据中,科目,是否暑期课程,讲师列都由字符串来表示,所以需要首先把它们转换成数值类型。我们把这个过程叫做特征编码(feature encoding)。
这三个特征都叫做类别(categorical)特征,因为这些特征值之间没有大小关系,而且只代表某一种类别。所以需要采用针对类别特征的编码技术。其中最常用的技术叫做独热编码(one-hot encoding)。
理解什么叫独热编码,首先来看什么叫标签编码(label encoding), 也就是把一个类别表示成一个数值,比如0,1,2,3….
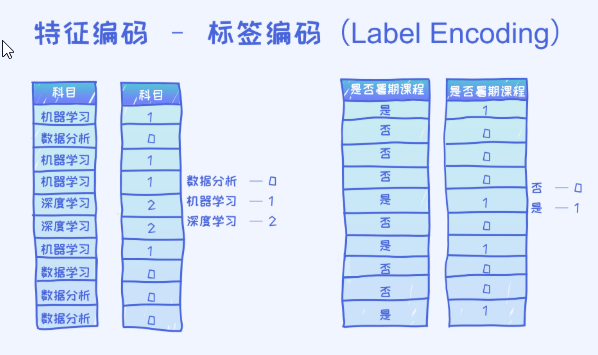
在上面的图中,我们针对两个特征做了标签编码的操作,分别是科目和是否暑期课程特征。 对于科目特征来说,它的取值只有三种:机器学习,数据分析和深度学习。所以在标签编码阶段给每一个赋予了一个值,数据分析为0, 机器学习为1,深度学习为2。这样以来,每一个类别都有了相对应的一个值。
当然这些值的顺序是可以互换的比如机器学习为0,深度学习为1, 数据分析为2。类似的,对于是否暑期课程特征,有两种取值:是或者否,所以分别用0和1来表示。
注意:我们不能直接把它们的标签编码作为特征输入到模型里
原因:假如我们直接使用标签编码来代表这里每一个类别特征是有问题的。那具体存在什么问题呢? 可以这么想,如果我们直接把类别特征看作是具体的数比如0,1,2… 那这时候,数与数之间是有大小关系的,比如2要大于1,1要大于0,而且这些大小相关的信息必然会用到模型当中。
但这就跟原来特征的特点产生了矛盾,因为对于深度学习,数据分析来说它们之间并不存在所谓的“大小”,可以理解为平行关系。所以对于这类特征来说,直接用0,1,2.. 的方式来表示是存在问题的,所以结论是不能这么做。
如何表达一个类别性特征呢? 答案就是独热编码。

在标签特征的基础上需要创建一个向量。这个向量的长度跟类别种类的个数等同的,另外,除了一个位置是1,其他位置均为0, 1的位置对应的是相应类别出现的位置。
比如有三个类别0,1,2… 那这时候向量的长度为3。 对应于0的向量为(1,0,0), 对应于1的向量为(0,1,0)2的向量为(0,0,1)。 但实际上,由于没有顺序的先后关系,设置独热编码向量时可以有很多不同的方法。
类别型特征是没有大小的顺序的,所以独热编码来说它的顺序也无关紧要,只要我们能保证每一个类别有一个对应的编码就可以了,而且确保编码是一对一对应。
数值型的变量:
一般如何处理数值型变量呢? 其实就是直接去使用,不做任何的编码。 比如一个人的身高是150,就直接把150当作特征来使用。唯一的处理就是做必要的标准化操作,让变量具有类似的取值范围。
那是不是数值类型的变量真的就没必要做一些编码操作呢? 其实不一定的。有一种技术叫做变量的离散化操作。


独热编码可以增加模型的非线性性
所以总结起来,连续性特征的离散化操作可以增加模型的非线性型,同时也可以有效地处理数据分布的不均匀的特点。
除了类别型变量和数值型变量,还有一个种类型的特征叫做顺序(ordinal)变量。最经典的例子就是问卷调查中用户的评价,比如非常满意,满意,一般,不满意等, 或者我们在购买物品之后给商品评价3颗星,还是4颗星…
这些变量都有一个共同的特点,就是每一种值都有大小的关系,也就是程度上的好坏之分,所以这一点跟类别型变量是不一样的。所以一种常见的处理方法就是把这些变量直接看作是数值型变量来处理,这也是最常用的方法。
当然,我们也可以把顺序型变量转换成独热编码的形式,但这么做就失去了大小关系,所以很少会这么使用。
对于顺序型变量,大部分情况下把它当做数值型变量来使用就可以了。

若有收获,就点个赞吧
0 人点赞
