当我们拿到数据之后,第一步一般是分析数据的特点比如有没有缺失值,有没有异常值以及数据分布是如何的。
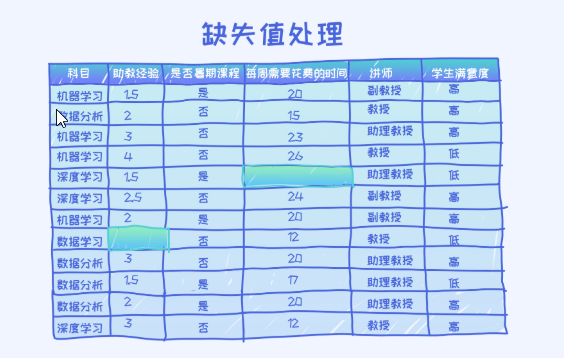
通过数据的观察,其实很容易知道这个数据针对的是分类问题。也就是通过给定的5个课程方面的特征来预测学生对课程满意度。
另外,这数据表格里有两个缺失值,分别是助教经验属性栏,还有每周需要花费的时间栏。
缺失值对于算法的影响很大,因为大部分算法没有办法处理这些缺失值。这就意味着,我们需要提前把这些缺失值处理好。
对于缺失值处理上,最简单的处理方法叫做”删除法“:一旦遇到了缺失值,我们就删掉相应的记录。
第一种删除法是把相应的属性全部删掉,也就是删掉整个列。
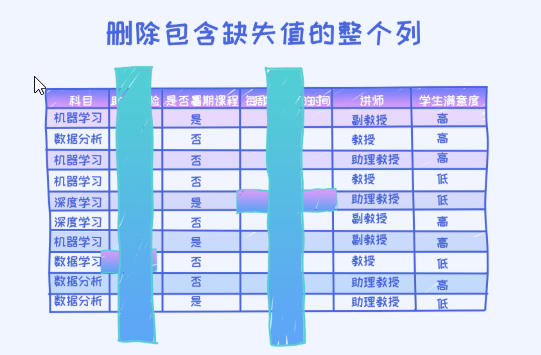
对于某一些特征,可能存在大量的缺失值。 简单的例子是,比如我们发起了一个问卷调查,其中有必填项也有选填项,但有可能只有不到30%的人填写了选填项,这个时候就产生大量的缺失值。而且,如果我们觉得这个选填项没有非常大的价值,其实可以丢弃掉,不放在模型里。但如果一个特征中只有几个样本缺失了这条特征,全部删掉整个列是不太明智的。因为等同于完全废弃掉了此特征,所以实际使用的时候还是要多加深思。
第二种删除法是删除相应的记录。 只要一个记录里包含了缺失值,就丢弃掉此记录。
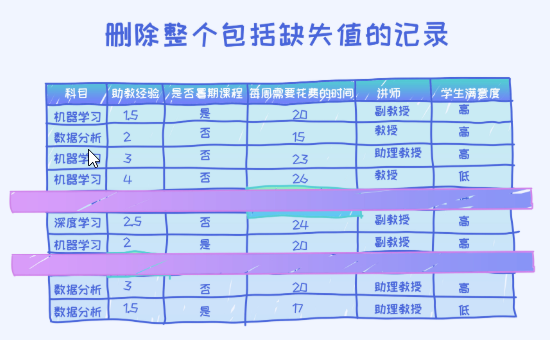
如上图所示,丢弃掉了第五条和第八条记录,因为这两条记录分别包含了缺失值。这种方法也简单且直接,也是平时工程里常用的方法,实现起来也非常简单。
删除记录的方法确实是一个非常实用的方法,而且广泛应用于很多的场景。但它也有些缺点。
对于维度很多的数据,假如大量的维度都存在缺失值,这个方法很容易丢弃掉大量的样本。
设想一下数据里含有100多个特征,而且其中60多个特征都允许出现缺失值(可以理解为选填项), 那这个时候对于一个记录来讲,它有大概率包含至少一个缺失值。所以,如果这时候使用此方案,最终会发现大量的记录都被我们丢弃掉了,这使得样本数据量急剧变小,从而影响后续建模的效果。
所以这是为什么对数据的理解非常重要,因为只有通过对数据的理解,才能一开始就觉察到哪些特征”有可能“重要,哪些特征根本就不重要。再有,理解数据中缺失值的分布情况有助于选择合适的方法去处理缺失值。
除了删除法,另一种方法叫做填补法,也就是尝试着用一个新的值来填补缺失值。对于数值型(real-valued)变量,我们经常使用平均法则,就是用平均值来填补缺失值。
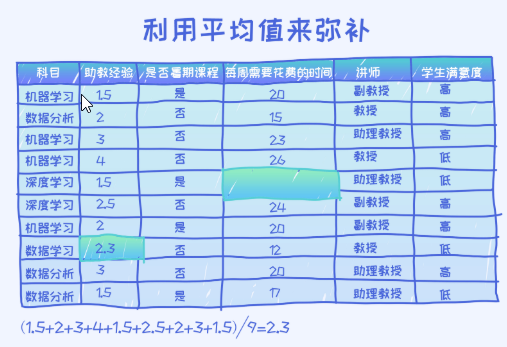
如上图所示,对于助教经验那一列,使用了平均填补法。方法很简单,把这一列的所有的值加起来做个平均,然后把这个平均值填补到每一个缺失值的地方。 除了平均值,有些人可能也会想到使用中位数来调补,两者均可。
那这种平均值/中位数填补法有什么缺点呢?
虽然这种方法比较有效,但也避免不了一些缺点。比如填补的值对于当前的样本来说很不合理,这时候反而会影响模型的效果。举个例子,目前在某公司担任技术专家的张三,他没有提供自己的薪资,如果这时候我们使用所有IT从业人员的平均薪资来填补缺失值,那对于张三来说是不太合理的。
,假如大量的维度都存在缺失值,这个方法很容易丢弃掉大量的样本对于维度很多的数据,假如大量的维度
都存在缺失值,这个方法很容易丢弃掉大量的样本
对于维度很多的数据,假如大量的维度都存在缺失值,这个方法很容易丢弃掉大量的样本
对于维度很多的数据,假如大量的维度都存在缺失值,这个方法很容易丢弃掉大量的样本

若有收获,就点个赞吧
0 人点赞
