

目前不能再简化了。那这里的w和b到底如何求出来呢? 这是优化算法的主要职责。

在图中列了两种比较常用的优化方法。第一种是把导数设置为0,并求出指定的参数。 第二种是使用迭代式的方法比如梯度下降法来求解参数。

把导数设置为0并求出最优解是属于最简单的优化算法,在高中数学里已经接触过。那对于上述逻辑回归的目标函数,不可以通过把导数设置为0的方式来求出最优解。所以,这种方法不是万能的。对于某些问题当我们把导数设置为0之后,没有办法写出参数的表达式。这时候可以考虑迭代式的优化算法。 其中一个最经典的迭代式算法叫做梯度下降法。 这种算法的核心是通过不断迭代的方式来求解函数的最优解。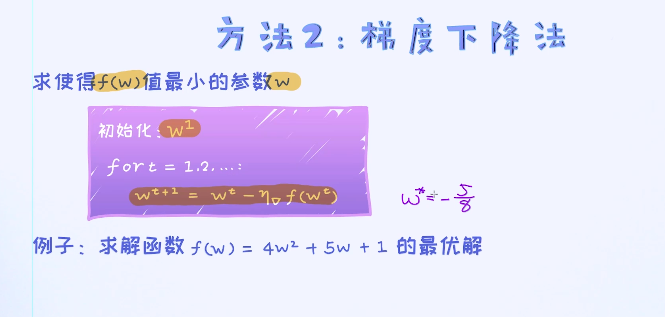
最后存在收敛的情况


对于梯度下降法,有一个重要的参数叫做学习率(learning rate),它控制着每一次迭代的程度。学习率越大,学习速度会越快; 学习率越小,学习速度越慢。但有一个潜在问题是,一旦学习率大于一定的值之后算法就无法收敛,这是不想看到的结果。
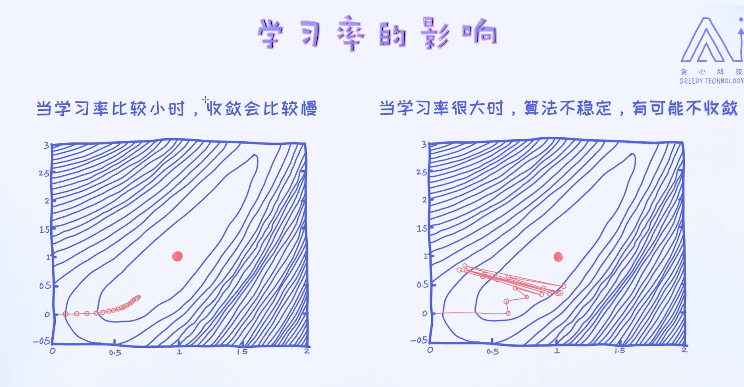
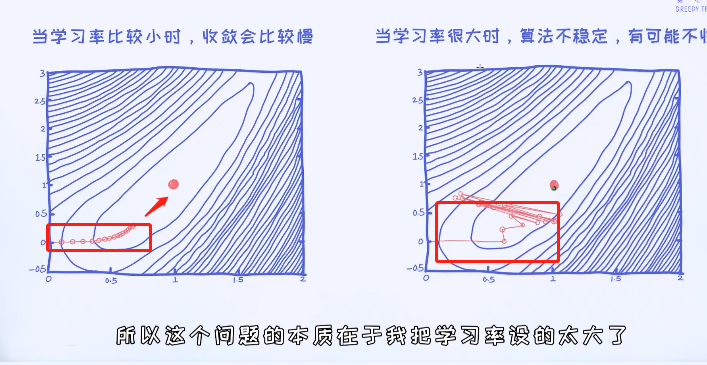
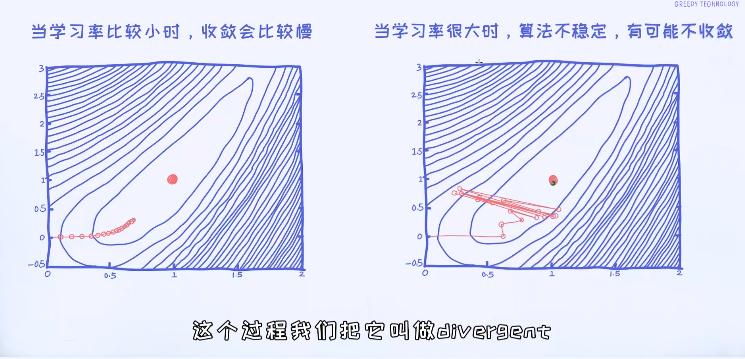
接着我们试着通过梯度下降法来求解逻辑回归的最优解。

简单的求导:

复合函数的求导:
除了复合函数的求导,对于逻辑回归来说,我们也需要知道如何对逻辑函数本身求导。

理解了上述所有基础概念之后,我们就可以开始研究如何对逻辑回归的目标函数求最优解了!使用梯度下降法的核心是,分别计算目标对参数ww和bb的梯度,之后就可以每隔一个时间段来更新这些参数。



对于逻辑回归模型,梯度下降法的最终结果为如下图所示。

一开始需要随机初始化参数w和b。 之后就可以通过循环来不断更新参数的值了,直到整个优化过程收敛为止。
那如何判断是否已经收敛呢? 一种简单的方法是每隔一段时间计算一下当前时间下的损失函数,如果在相邻两个时间段损失函数没有任何变化或者变化很小即可以认为优化过程已收敛,就可以停下来了。
如果在相邻两个时间段损失函数没有任何变化或者变化很小即可以认为优化过程已收敛;
如果在相邻两个时间段参数的值没有变化或者变化很小即可以认为优化过程已收敛;
另外,算法的开始会随机初始化参数。不同的初始化结果都是一样的。
最终的结果到底一不一样得看目标函数的性质。一般我们把目标函数分为两大类,分别是凸函数和非凸函数。不管怎么初始化,结果是一样的
如果一个目标函数是凸函数就意味着它的最优解就是全局最优解,反之我们只能保证找到局部最优解。在第二种情况下,不同的初始化会带来不一样的最终结果,也可以理解为不同的初始化值有好有坏。那好的初始化可以带来更好的局部最优解。
这里幸运的是,逻辑回归的目标函数是凸函数,所以我们可以保证找到的是全局最优解。所以不管如何初始化参数,只要梯度下降法实现上没问题,就可以找到同一个全局最优解。
另外,梯度下降法里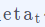 代表的是每一时刻的学习率,它是可以随时间而动态变化的。一般情况下,我们以人工的方式来定义学习率的变化。通常使用的标准是随着时间的推移,学习率不断变小。
代表的是每一时刻的学习率,它是可以随时间而动态变化的。一般情况下,我们以人工的方式来定义学习率的变化。通常使用的标准是随着时间的推移,学习率不断变小。
这就好比,我们刚接触一个新的领域的时候,一开始几天的进步是很快的,因为是从零开始接触。但等我们已经熟悉了这个领域之后就会发现进步的速度会逐渐放慢下来。其实跟梯度下降法是同一个道理,越到最后,改变就越小。
不管怎么初始化,结果是一样的

若有收获,就点个赞吧
0 人点赞
