哪一个算法在机器学习领域最重要且实用? 神经网络? SVM? 决策树? 其实都不是! 机器学习界的经典非逻辑回归莫属!
绝大部分分类问题我们实际上都可以使用逻辑回归来解决,说的是在线上环境下。

它非常实用,而且是线上系统中最为常用的模型,对于大部分问题来讲,它是我们的首选。由于简单,它也适用于数据量特别大的情况。对于逻辑回归,我们也有比较成熟的分布式的解决方案。
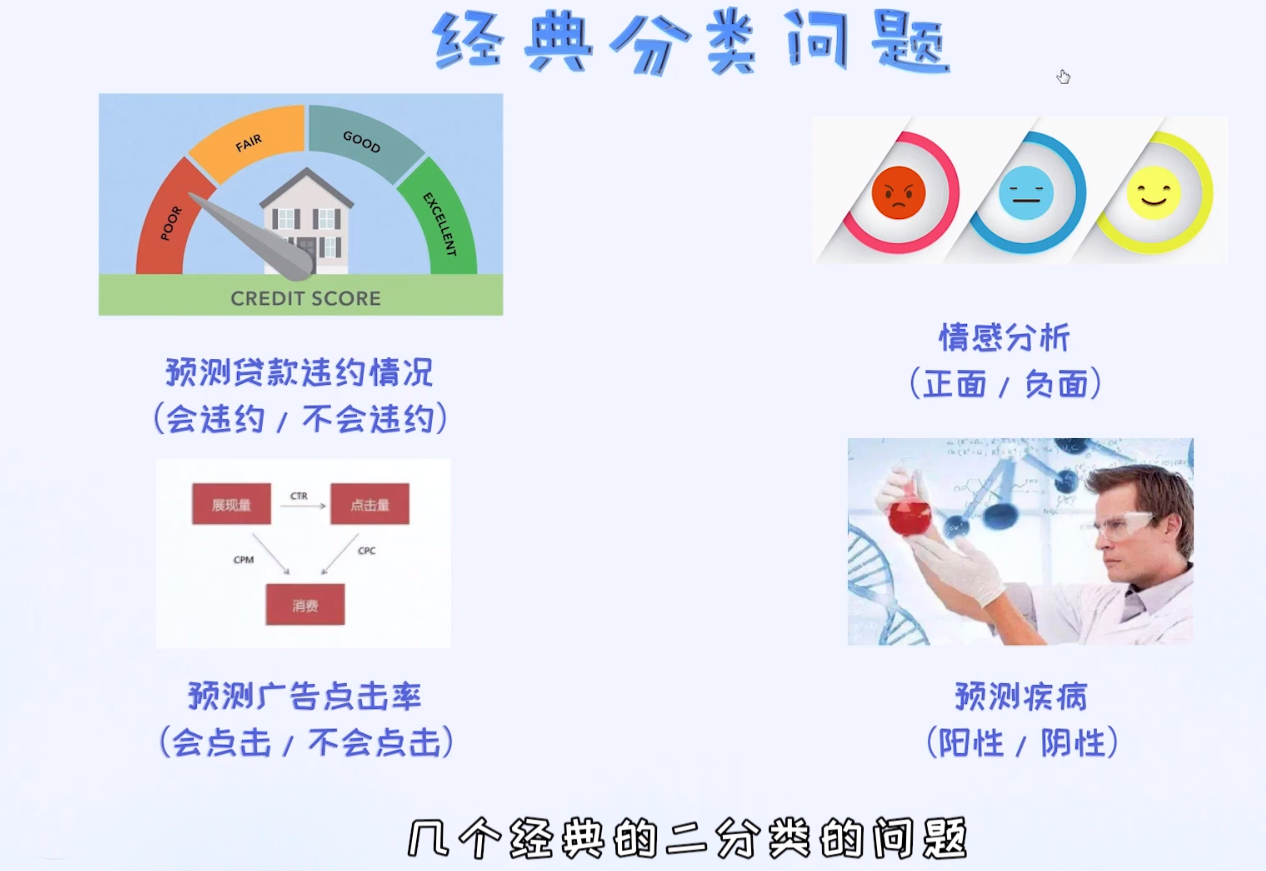
当然除了上述几个应用场景,任何一个分类问题其实都可以使用逻辑回归来解决。至少,逻辑回归是一个非常靠谱的基准(Baseline)。
由于AI系统本身的特点,我们经常会提到基准的概念,也就是在设计模型阶段我们首先试图通过简单的方法来快速得到答案,这种方法所提供的结果可以认为是基准。之后在这个基准的前提下,再通过一些优化手段来不断提升系统的性能。
逻辑回归是分类型问题一个好的基准
线性回归是回归问题一个好的基准
看一个具体的样本数据:
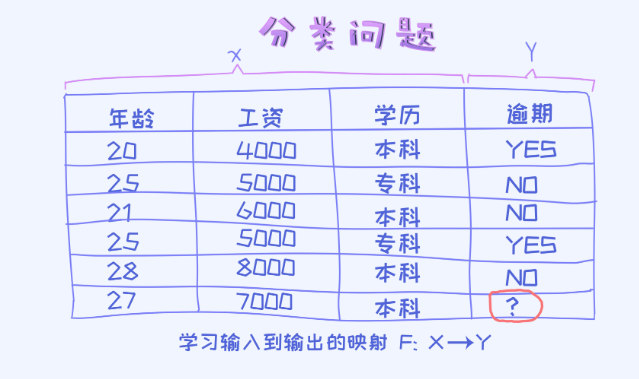
在这个表格里,有三个特征和一个预测变量叫作逾期,而且逾期类别可以取两个不同的值。所以,这是经典的二分类问题。 我们可以把特征值看作是向量x, 预测值看作是一个具体的类别值y。
对于分类问题呢,实际上试图通过训练模型的方式来学出x到y之间的映射关系。有了这个映射关系之后,即可以对新的数据做类别的预测。
那究竟如何表示x和y之间的关系呢? 这里就牵涉到了模型的选择。每一种类型的模型其实可以看作是对这个映射关系种类的假设。比如我们使用逻辑回归,就意味着这样的映射关系是线性的;但如果使用的是神经网络,就意味着这种映射关系是很复杂的非线性关系。
那对于逻辑回归,我们又如何去定义此映射关系呢?
逻辑回归本身解决的是二分类问题,所以在这里我们就假定y的取值为0或者1。当然逻辑回归也可以用于多分类问题中。
上述所谓的x到y之间的映射关系也可以通过条件概率p(y|x)来表示。由于y的取值为0或者1, 只要我们能计算出p(y=1|x)和p(y=0|x), 即可以对任何一个给定的样本x做预测了。
比如对于给定的一个样本x, 假如p(y=1|x) > p(y=0|x), 就可以把样本x分类成类别1了, 反之就类别0。
所以,这里的核心问题是如何通过条件概率p(y|x)来描述x和y之间的关系 ,而且上面已经提到,逻辑回归其实是线性模型。
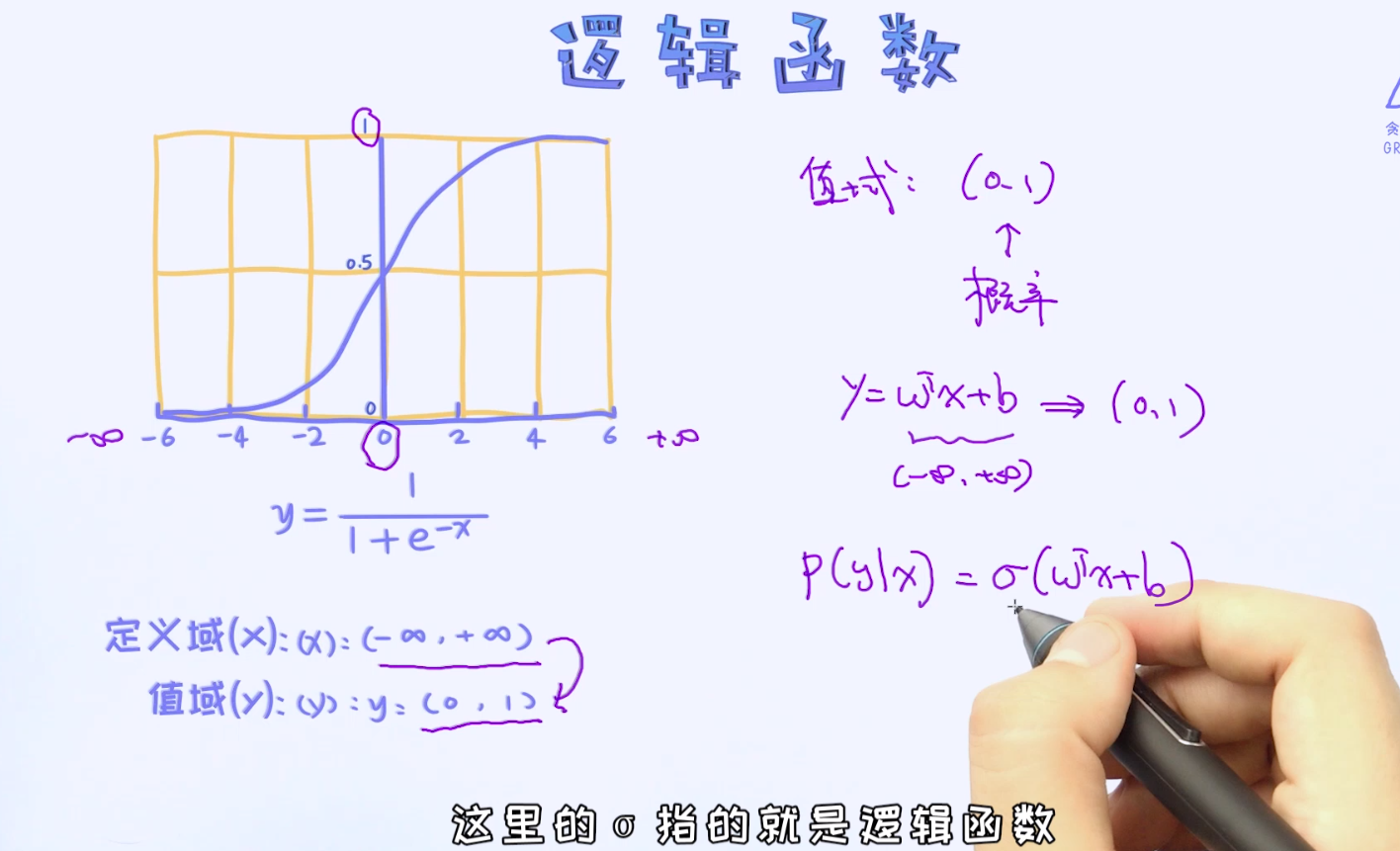
问题:那我们是否可以把条件概率表示成这种形式呢?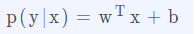
不可以!
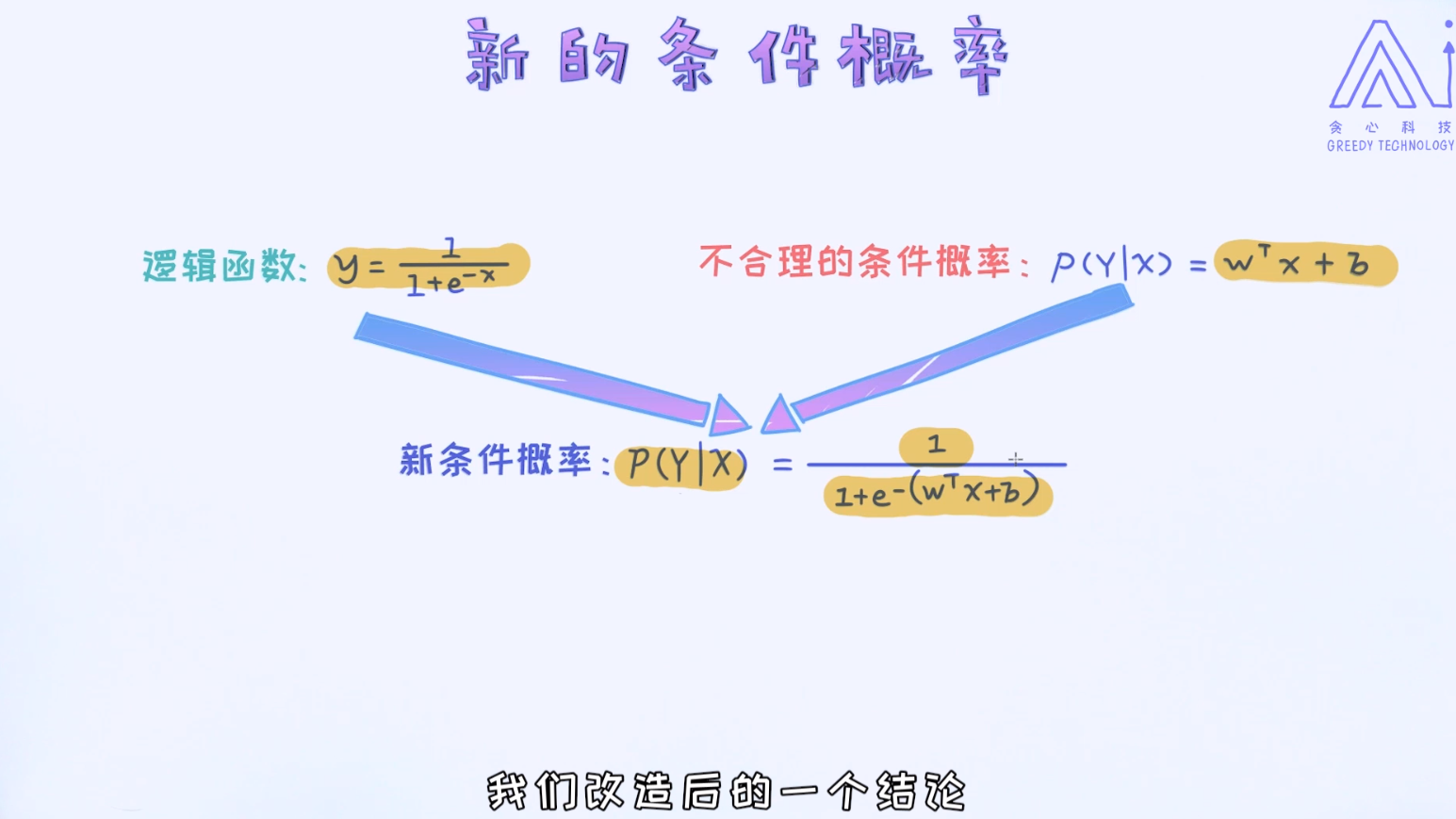
这里最明显的问题是定义域和值域的不匹配。假如我们把p(y|x)看作是一个条件概率,它一定是一个合理的概率值,也就是它的取值范围一定会落在0和1之间,因为一个概率值不可能小于0或者大于1的。但是,假如我们使用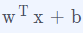 的方式来描述,则它的值域是负无穷到正无穷区间, 显然这不符合概率的定义。
的方式来描述,则它的值域是负无穷到正无穷区间, 显然这不符合概率的定义。
但无论如何,通过线性回归的方式来构建逻辑归回这个方向是正确的。那接下来题就来了,有没有办法在原来的基础上做改造呢?

也就是如何把正无穷到负无穷的值域映射到(0, 1)之间呢? 那这样一来,就可以得到合理的概率值了! 答案就是使用逻辑函数。
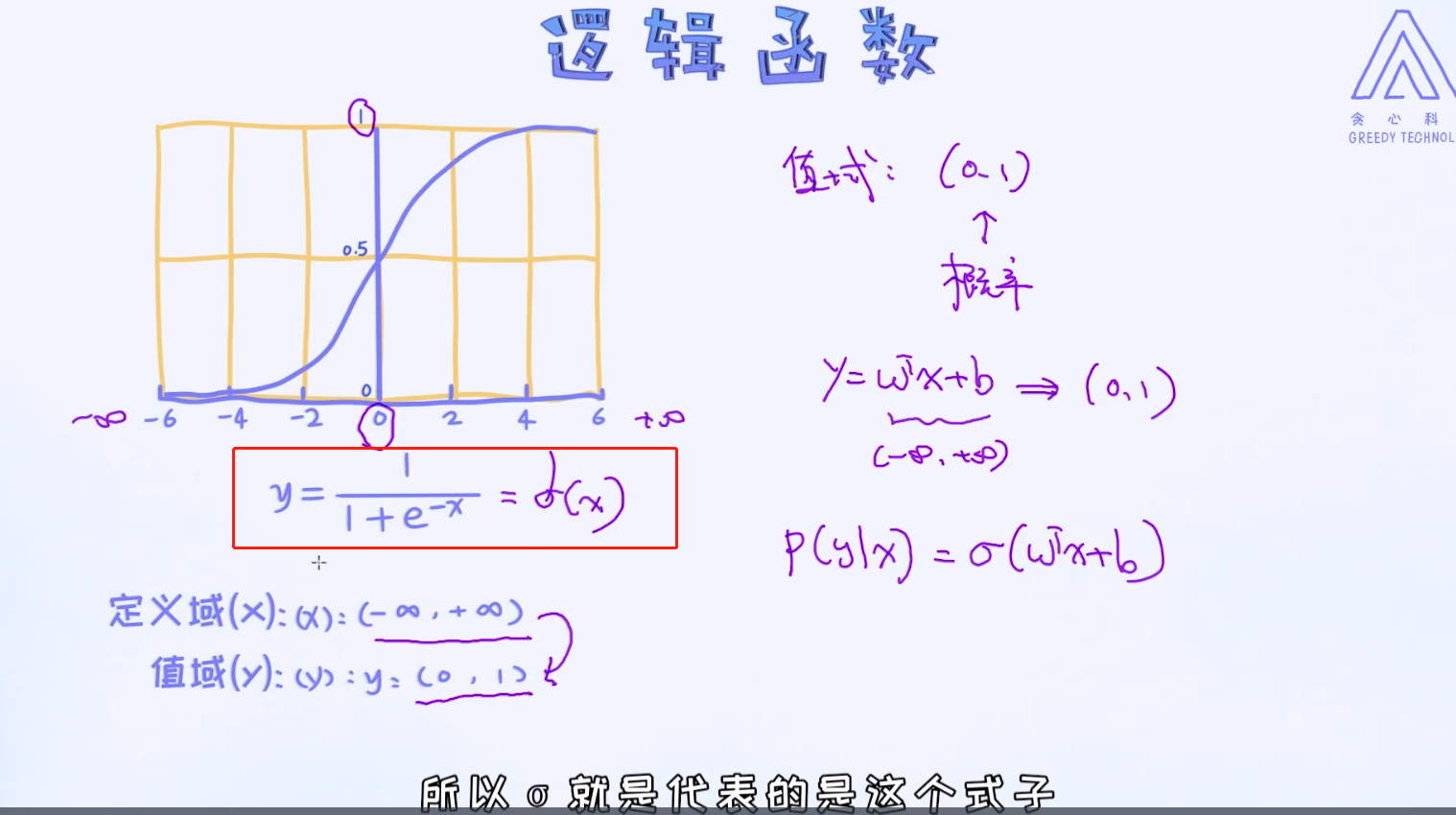
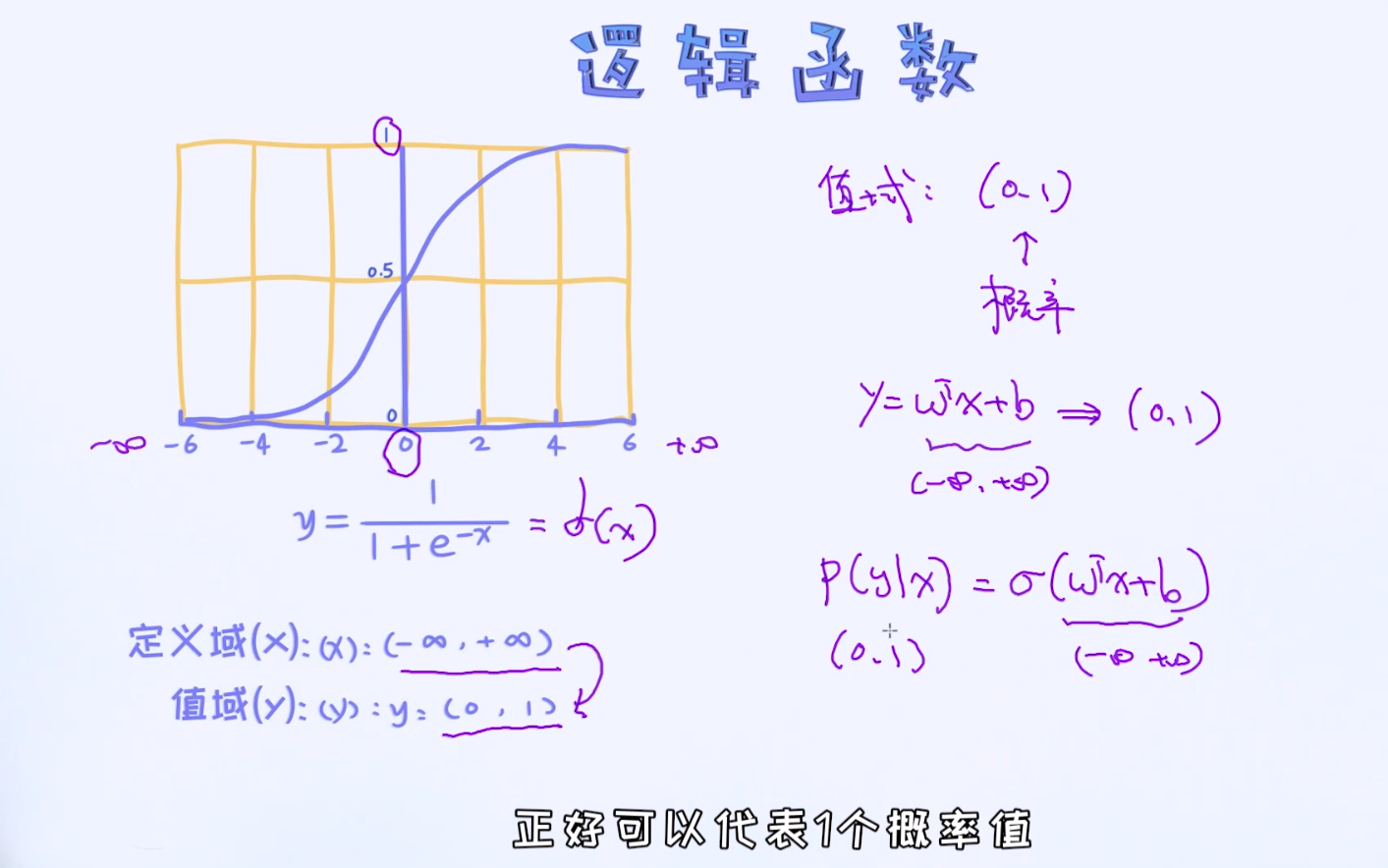
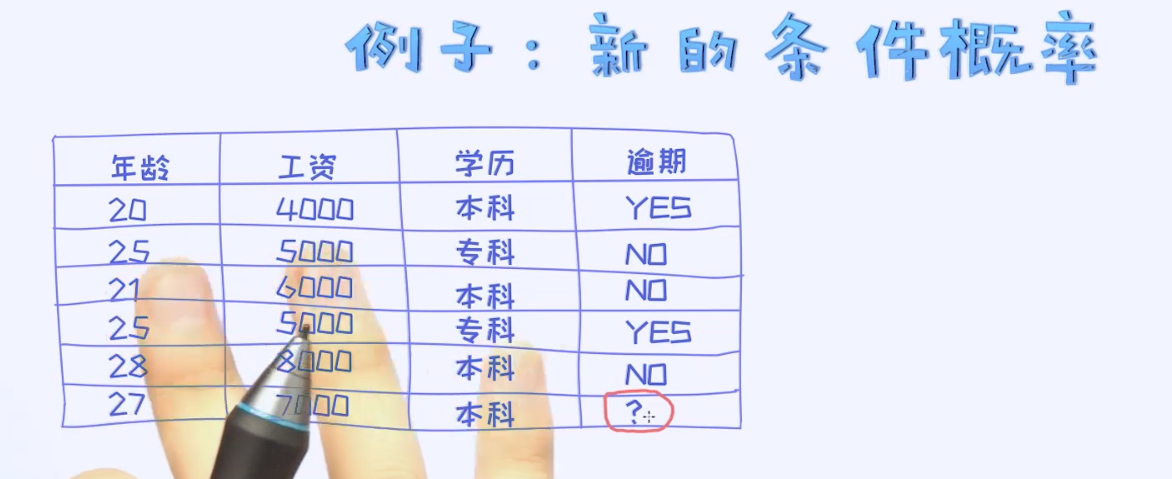

本科是字符串,要用独热编码表示(one-hot-encoding:独热编码)。学历有本科和专科之分,所以用二维向量表示本科,W变成了4维
通过上述的转换,最终我们可以把条件概率写成如下形式:

对于逻辑回归,它的参数是 \mathbf w和b,前者是向量,后者是标量(Scalar)。问题:这里的两个条件概率是否可以替换一下顺序呢?
是可以替换的。其实只要能保证它俩的之和为1就可以了。最终,可以把这两个条件概率合并成一个式子。

合并之后的式子不难理解。当y=1时,后面那一项不起任何作用也就变成了第一个条件概率; 当y=0时,前面那一项不起作用,也就等同于第二个条件概率。
有了这两个条件概率之后,我们可以试图去寻找逻辑回归模型的决策边界了。前面说过,逻辑回归是线性模型,所以它的决策边界也是线性。那如何去证明这一点呢?
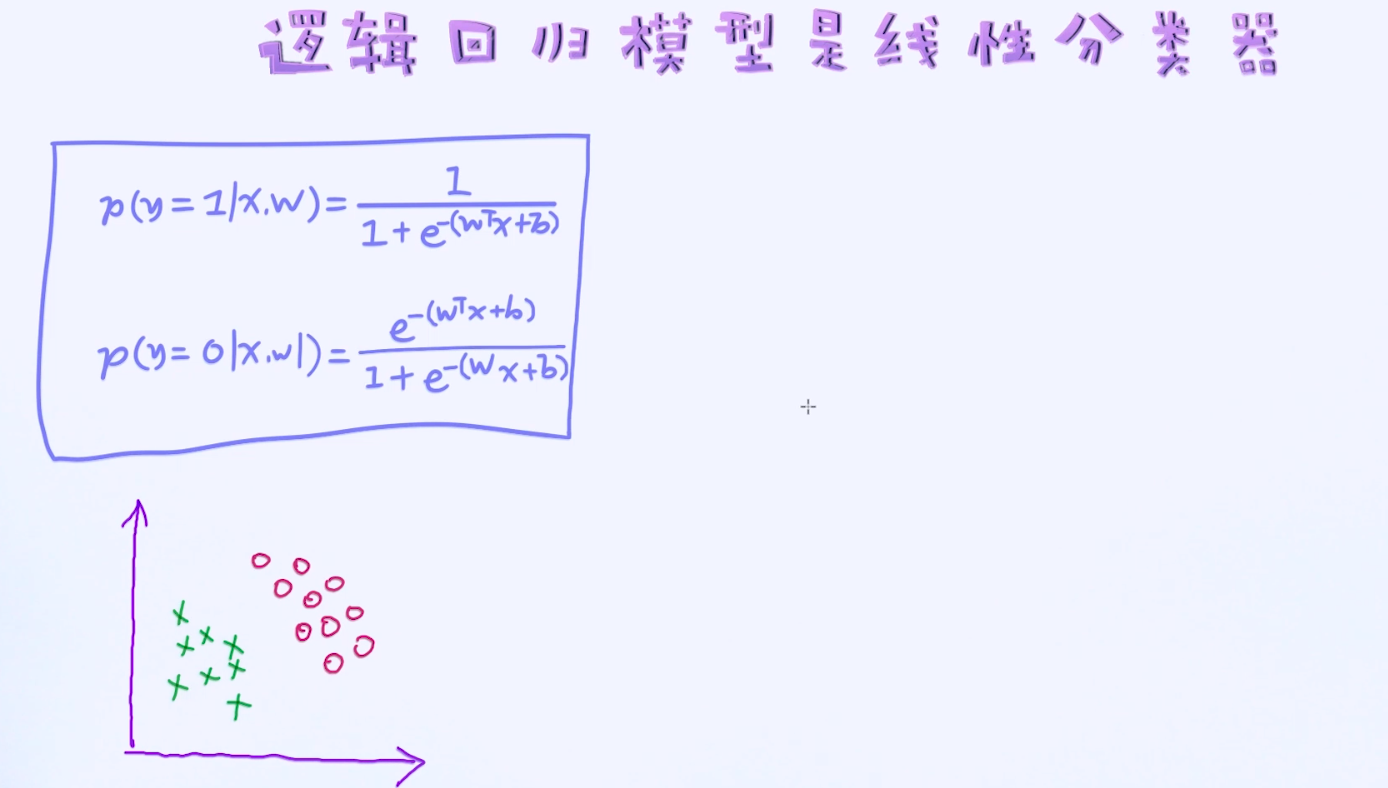
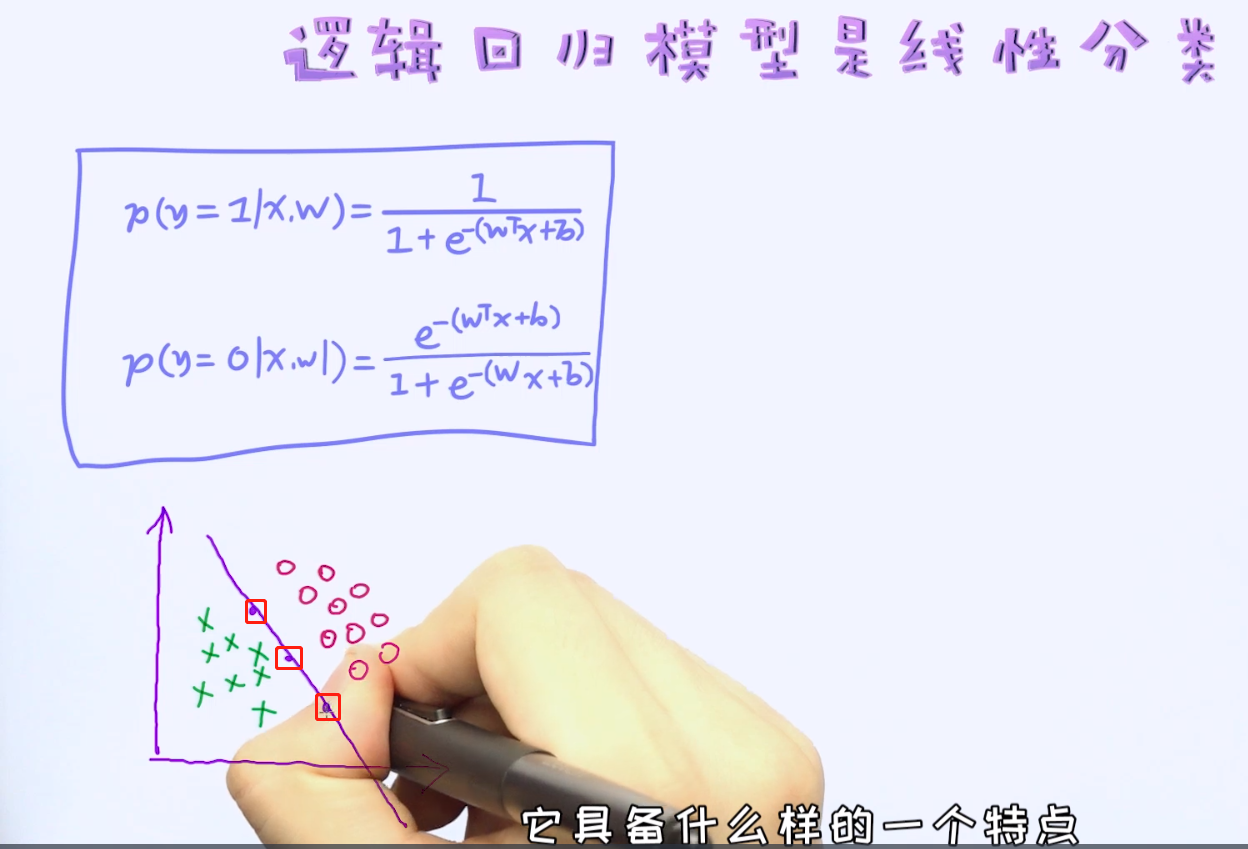
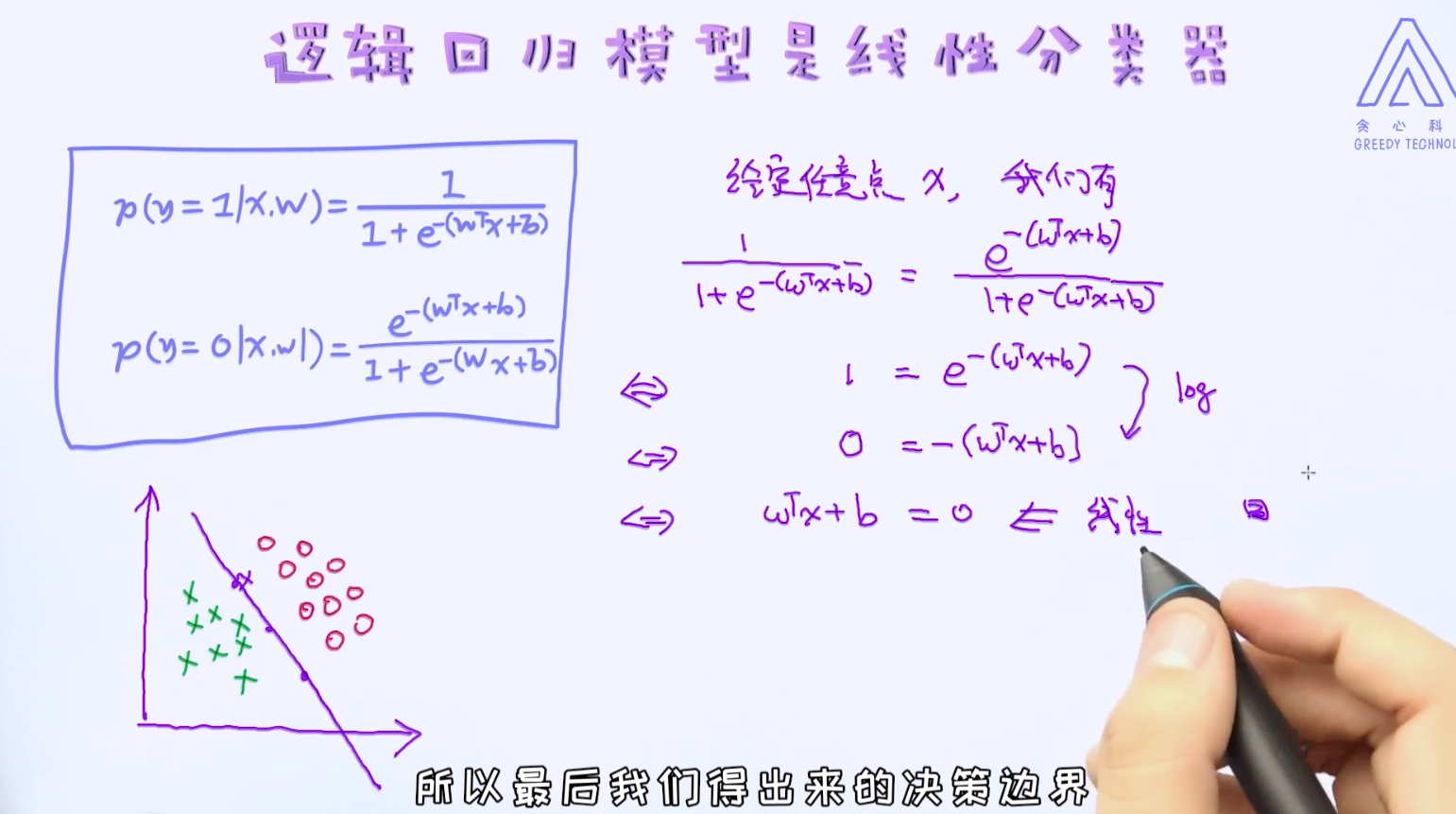
到此为止,我们对逻辑回归已经有了大体的认识,以及知道如何通过条件概率来描述特征与预测值之间的关系了

若有收获,就点个赞吧
0 人点赞
