题目描述
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回 0。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
来源,leetcode 每日一题 127. 单词接龙
例如:
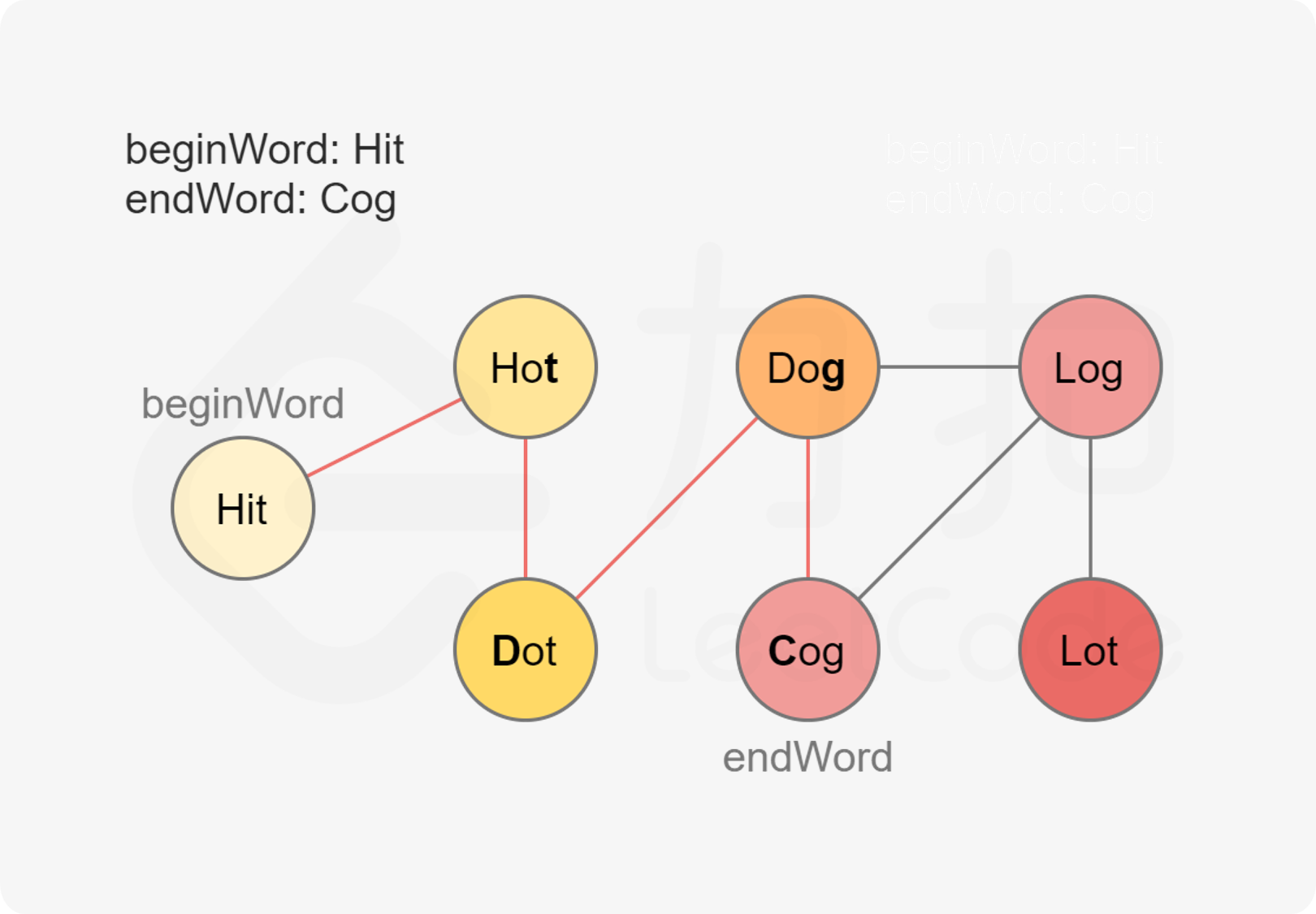
输入:beginWord = "hit",endWord = "cog",wordList = ["hot","dot","dog","lot","log","cog"]输出: 5解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog",返回它的长度 5。
解题思路
- 采用深度优先遍历或者广度优先遍历,当有一个词的时候,去寻找可能为它变换来的词是什么,然后迭代进行,当发现了target之后停止迭代,并且记录当前的变换长度,取最短的那个即可。
- 但是这样的话,由遍历的范围,太广,容易造成时间超限的错误。所以采用优化建图的方式进行优化。具体地,我们可以创建虚拟节点。对于单词 hit,我们创建三个虚拟节点 it、ht、hi*,并让 hit 向这三个虚拟节点分别连一条边即可。如果一个单词能够转化为 hit,那么该单词必然会连接到这三个虚拟节点之一。对于每一个单词,我们枚举它连接到的虚拟节点,把该单词对应的 id 与这些虚拟节点对应的 id 相连即可。
- 最后我们将起点加入队列开始广度优先搜索,当搜索到终点时,我们就找到了最短路径的长度。注意因为添加了虚拟节点,所以我们得到的距离为实际最短路径长度的两倍。同时我们并未计算起点对答案的贡献,所以我们应当返回距离的一半再加一的结果。
代码
class Solution {public:unordered_map<string, int> wordId;vector<vector<int>> edge;int nodeNum = 0;void addWord(string& word) {if (!wordId.count(word)) {wordId[word] = nodeNum++;edge.emplace_back();}}void addEdge(string& word) {addWord(word);int id1 = wordId[word];for (char& it : word) {char tmp = it;it = '*';addWord(word);int id2 = wordId[word];edge[id1].push_back(id2);edge[id2].push_back(id1);it = tmp;}}int ladderLength(string beginWord, string endWord, vector<string>& wordList) {for (string& word : wordList) {addEdge(word);}addEdge(beginWord);if (!wordId.count(endWord)) {return 0;}vector<int> dis(nodeNum, INT_MAX);int beginId = wordId[beginWord], endId = wordId[endWord];dis[beginId] = 0;queue<int> que;que.push(beginId);while (!que.empty()) {int x = que.front();que.pop();if (x == endId) {return dis[endId] / 2 + 1;}for (int& it : edge[x]) {if (dis[it] == INT_MAX) {dis[it] = dis[x] + 1;que.push(it);}}}return 0;}};

若有收获,就点个赞吧
0 人点赞
