- 注意列表切片是左闭右开(取左不取右),容易导致边界问题。同样,
range(n,0,-1)也是取不到0的。 - 进制转换
十进制转二进制bin(100) “0b1100100”
二进制转十进制int('0b1100100',2) 100
字符串转数字 int(s)
字符串转为n进制的数字 int(s, n),比如 n=2。
python入门
变量与运算符
类型转换
int():将一个数值或字符串转换成整数,可以指定进制。float():将一个字符串转换成浮点数。str():将指定的对象转换成字符串形式,可以指定编码。chr():将整数转换成该编码对应的字符串(一个字符)。ord():将字符串(一个字符)转换成对应的编码(整数)。
在使用print函数输出时,也可以对字符串内容进行格式化处理:
f = float(input('请输入华氏温度: '))c = (f - 32) / 1.8print('%.1f华氏度 = %.1f摄氏度' % (f, c))
上面print函数中的字符串%.1f是一个占位符,稍后会由一个float类型的变量值替换掉它。同理,如果字符串中有%d,后面可以用一个int类型的变量值替换掉它,而%s会被字符串的值替换掉。
除了这种格式化字符串的方式外,还可以用下面的方式来格式化字符串:
print(f'{f:.1f}华氏度 = {c:.1f}摄氏度')
其中{f:.1f}和{c:.1f}可以先看成是{f}和{c},表示输出时会用变量f和变量c的值替换掉这两个占位符,后面的:.1f表示这是一个浮点数,小数点后保留1位有效数字。
| 运算符 | 描述 |
|---|---|
[]``[:] |
下标,切片 |
** |
指数 |
~``+``- |
按位取反, 正负号 |
*``/``%``// |
乘,除,模,整除 |
+``- |
加,减 |
>>``<< |
右移,左移 |
& |
按位与 |
^``\\| |
按位异或,按位或 |
<=``<``>``>= |
小于等于,小于,大于,大于等于 |
==``!= |
等于,不等于 |
is``is not |
身份运算符 |
in``not in |
成员运算符 |
not``or``and |
逻辑运算符 |
=``+=``-=``*=``/=``%=``//=``**=``&=``|=``^=``>>=``<<= |
(复合)赋值运算符 |
说明: 上面这个表格实际上是按照运算符的优先级从上到下列出了各种运算符。在实际开发中,如果搞不清楚运算符的优先级,可以使用圆括号来确保运算的执行顺序。
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \” | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数yy代表的字符,例如:\o12代表换行 |
| \xyy | 十进制数yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
分支与循环
if: elif: else
x = float(input('x = '))if x > 1:y = 3 * x - 5elif x >= -1:y = x + 2else:y = 5 * x + 3print(f'f({x}) = {y}')
for-in: 循环
total = 0for x in range(1, 101):total += xprint(total)
range(101):0到100。range(1, 101)左闭右开,也就是取值从1到100,取不到101。range(1, 101, 2):产生1到100的奇数,其中2是步长,即每次递增的值。range(100, 0, -2):产生100到1的偶数,其中-2是步长,即每次递减的值。
while 循环
正整数反转:
num = int(input('num = '))reversed_num = 0while num > 0:reversed_num = reversed_num * 10 + num % 10num //= 10print(reversed_num)
python数据结构
列表 list
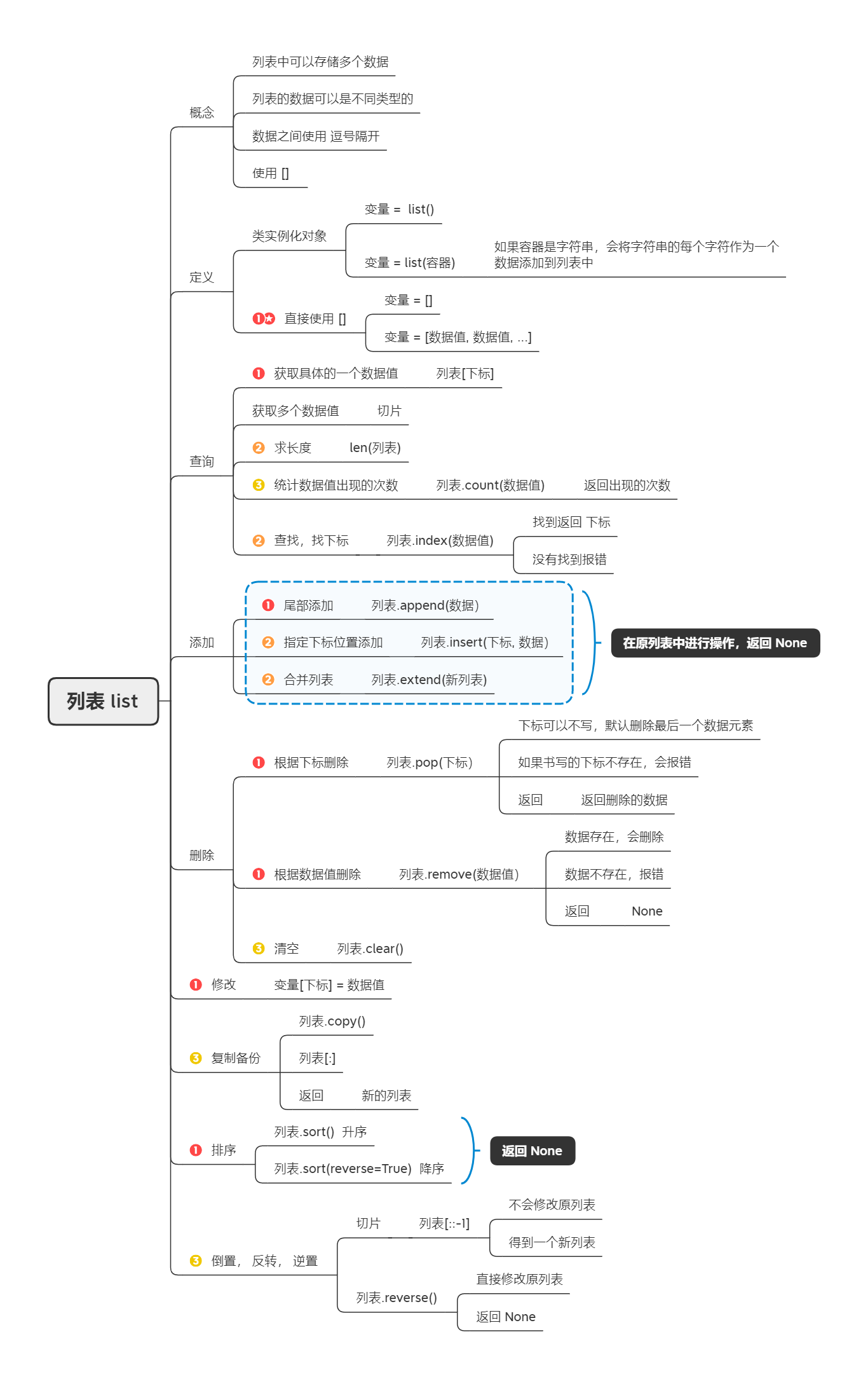
创建列表
列表是由一系元素按特定顺序构成的数据序列,这样就意味着定义一个列表类型的变量,可以保存多个数据,而且允许有重复的数据。跟上一课我们讲到的字符串类型一样,列表也是一种结构化的、非标量类型,操作一个列表类型的变量,除了可以使用运算符还可以使用它的方法。
- 在Python中,可以使用
[]字面量语法来定义列表,列表中的多个元素用逗号进行分隔,代码如下所示。
items1 = [35, 12, 99, 68, 55, 87]items2 = ['Python', 'Java', 'Go', 'Kotlin']
- 除此以外,还可以通过Python内置的
list函数将其他序列变成列表。准确的说,list并不是一个普通的函数,它是创建列表对象的构造器(后面会讲到对象和构造器这两个概念)。
items1 = list(range(1, 10))print(items1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]items2 = list('hello')print(items2) # ['h', 'e', 'l', 'l', 'o']
需要说明的是,列表是一种可变数据类型,也就是说列表可以添加元素、删除元素、更新元素,这一点跟我们上一课讲到的字符串有着鲜明的差别。字符串是一种不可变数据类型,也就是说对字符串做拼接、重复、转换大小写、修剪空格等操作的时候会产生新的字符串,原来的字符串并没有发生任何改变。
运算
items1 = [35, 12, 99, 68, 55, 87]items2 = [45, 8, 29]# 列表的拼接items3 = items1 + items2 # [35, 12, 99, 68, 55, 87, 45, 8, 29]# 列表的重复items4 = ['hello'] * 3 # ['hello', 'hello', 'hello']# 列表的成员运算print(100 in items3) # Falseprint('hello' in items4) # True# 获取列表的长度(元素个数)size = len(items3) # 9# 列表的索引print(items3[0], items3[-size]) # 35 35items3[-1] = 100print(items3[size - 1], items3[-1]) # 100 100# 列表的切片print(items3[:5]) # [35, 12, 99, 68, 55]print(items3[4:]) # [55, 87, 45, 8, 100]print(items3[-5:-7:-1]) # [55, 68]print(items3[::-2]) # [100, 45, 55, 99, 35]# 列表的比较运算items5 = [1, 2, 3, 4]items6 = list(range(1, 5))# 两个列表比较相等性比的是对应索引位置上的元素是否相等print(items5 == items6) # Trueitems7 = [3, 2, 1]# 两个列表比较大小比的是对应索引位置上的元素的大小print(items5 <= items7) # True
由于列表是可变类型,所以通过索引操作既可以获取列表中的元素,也可以更新列表中的元素。对列表做索引操作一样要注意索引越界的问题,对于有N个元素的列表,正向索引的范围是0到N-1,负向索引的范围是-1到-N,如果超出这个范围,将引发IndexError异常,错误信息为:list index out of range。
增删改查
items = ['Python', 'Java', 'Go', 'Kotlin']# 列表元素的遍历-方法一for index in range(len(items)):print(items[index])# 列表元素的遍历-方法二for item in items:print(item)# 使用append方法在列表尾部添加元素items.append('Swift') # ['Python', 'Java', 'Go', 'Kotlin', 'Swift']# 使用insert方法在列表指定索引位置插入元素items.insert(2, 'SQL') # ['Python', 'Java', 'SQL', 'Go', 'Kotlin', 'Swift']# 删除指定的元素items.remove('Java') # ['Python', 'SQL', 'Go', 'Kotlin', 'Swift']# 删除指定索引位置的元素items.pop(0)items.pop(len(items) - 1) # ['SQL', 'Go', 'Kotlin']# 清空列表中的元素items.clear() # []
- 在使用
remove方法删除元素时,如果要删除的元素并不在列表中,会引发ValueError异常,错误消息是:list.remove(x): x not in list。 - 在使用
pop方法删除元素时,如果索引的值超出了范围,会引发IndexError异常,错误消息是:pop index out of range。 - 从列表中删除元素其实还有一种方式,就是使用Python中的
del关键字后面跟要删除的元素,这种做法跟使用pop方法指定索引删除元素没有实质性的区别,但后者会返回删除的元素,前者在性能上略优(del对应字节码指令是DELETE_SUBSCR,而pop对应的字节码指令是CALL_METHOD和POP_TOP)。
items = ['Python', 'Java', 'Go', 'Kotlin']del items[1]print(items) # ['Python', 'Go', 'Kotlin']
- 列表类型的
index方法可以查找某个元素在列表中的索引位置; - 因为列表中允许有重复的元素,所以列表类型提供了
count方法来统计一个元素在列表中出现的次数。 - 列表的
sort操作可以实现列表元素的排序,而reverse操作可以实现元素的反转
items = ['Python', 'Java', 'Java', 'Go', 'Kotlin', 'Python']# 查找元素的索引位置print(items.index('Python')) # 0print(items.index('Python', 2)) # 5# 注意:虽然列表中有'Java',但是从索引为3这个位置开始后面是没有'Java'的print(items.index('Java', 3)) # ValueError: 'Java' is not in list# 查找元素出现的次数print(items.count('Python')) # 2print(items.count('Go')) # 1print(items.count('Swfit')) # 0# 排序items.sort() # ['Go', 'Java', 'Kotlin', 'Python', 'Python']# 反转items.reverse() # ['Python', 'Python', 'Kotlin', 'Java', 'Go']
列表生成式
# 创建一个由1到9的数字构成的列表items1 = [x for x in range(1, 10)]print(items1) # [1, 2, 3, 4, 5, 6, 7, 8, 9]# 创建一个由'hello world'中除空格和元音字母外的字符构成的列表items2 = [x for x in 'hello world' if x not in ' aeiou']print(items2) # ['h', 'l', 'l', 'w', 'r', 'l', 'd']# 创建一个由个两个字符串中字符的笛卡尔积构成的列表items3 = [x + y for x in 'ABC' for y in '12']print(items3) # ['A1', 'A2', 'B1', 'B2', 'C1', 'C2']# 如果用for循环创建列表:items4 = []for x in 'ABC':for y in '12':items4.append(x + y)print(items4) # ['A1', 'A2', 'B1', 'B2', 'C1', 'C2']
- 列表生成式拥有更好的性能,因为Python解释器的字节码指令中有专门针对生成式的指令(
LIST_APPEND指令);而for循环是通过方法调用(LOAD_METHOD和CALL_METHOD指令)的方式为列表添加元素,方法调用本身就是一个相对耗时的操作。对这一点不理解也没有关系,记住“强烈建议用生成式语法来创建列表”这个结论就可以了。
嵌套的列表
如果用下面的方式来生成二维数组,是有问题的。
scores = [[0] * 3] * 5 # [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]scores[0][0] = 95print(scores) # [[95, 0, 0], [95, 0, 0], [95, 0, 0], [95, 0, 0], [95, 0, 0]]
在Python Tutor网站的可视化代码执行功能里我们可以看到上述代码的结构是
正确的创建嵌套列表的方法是
scores = [[0] * 3 for _ in range(5)]scores[0][0] = 95print(scores) # [[95, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
元组 tuple
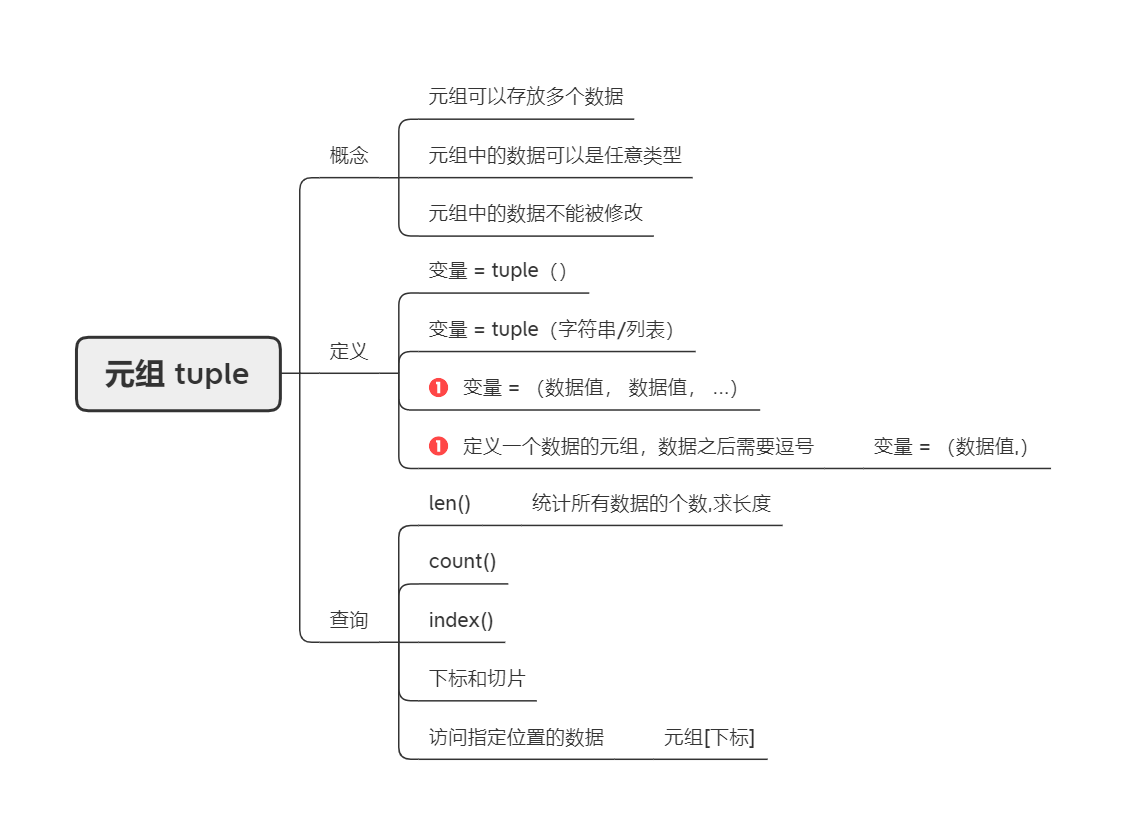
- 元组和列表的不同之处在于,元组是不可变类型,这就意味着元组类型的变量一旦定义,其中的元素不能再添加或删除,而且元素的值也不能进行修改。
- 定义元组通常使用
()字面量语法,也建议大家使用这种方式来创建元组。 - 元组类型支持的运算符跟列表一样。
- 一个元组中如果有两个元素,我们就称之为二元组;一个元组中如果五个元素,我们就称之为五元组。需要提醒大家注意的是,
()表示空元组,但是如果元组中只有一个元素,需要加上一个逗号,否则**()**就不是代表元组的字面量语法,而是改变运算优先级的圆括号,所以**('hello', )**和**(100, )**才是一元组,而**('hello')**和**(100)**只是字符串和整数。我们可以通过type()来查看元素类型。
打包和解包
- 当我们把多个用逗号分隔的值赋给一个变量时,多个值会打包成一个元组类型;
- 当我们把一个元组赋值给多个变量时,元组会解包成多个值然后分别赋给对应的变量。
# 打包a = 1, 10, 100print(type(a), a) # <class 'tuple'> (1, 10, 100)# 解包i, j, k = aprint(i, j, k) # 1 10 100
- 在解包时,如果解包出来的元素个数和变量个数不对应,会引发
ValueError异常,错误信息为:too many values to unpack(解包的值太多)或not enough values to unpack(解包的值不足)。 - 有一种解决变量个数少于元素的个数方法,就是使用星号表达式,我们之前讲函数的可变参数时使用过星号表达式。有了星号表达式,我们就可以让一个变量接收多个值,代码如下所示。需要注意的是,用星号表达式修饰的变量会变成一个列表,列表中有0个或多个元素。还有在解包语法中,星号表达式只能出现一次。
a = 1, 10, 100, 1000i, j, *k = aprint(i, j, k) # 1 10 [100, 1000]i, *j, k = aprint(i, j, k) # 1 [10, 100] 1000*i, j, k = aprint(i, j, k) # [1, 10] 100 1000*i, j = aprint(i, j) # [1, 10, 100] 1000i, *j = aprint(i, j) # 1 [10, 100, 1000]i, j, k, *l = aprint(i, j, k, l) # 1 10 100 [1000]i, j, k, l, *m = aprint(i, j, k, l, m) # 1 10 100 1000 []
需要说明一点,解包语法对所有的序列都成立,这就意味着对列表以及我们之前讲到的range函数返回的范围序列都可以使用解包语法。大家可以尝试运行下面的代码,看看会出现怎样的结果。
a, b, *c = range(1, 10)print(a, b, c)a, b, c = [1, 10, 100]print(a, b, c)a, *b, c = 'hello'print(a, b, c) #h ['e', 'l', 'l'] o
交换两个变量的值
在Python中,交换两个变量a和b的值不需要借助中间变量,可以使用如下所示的代码。
a, b = b, aa, b, c = b, c, a
需要说明的是,上面并没有用到打包和解包语法,Python的字节码指令中有ROT_TWO和ROT_THREE这样的指令可以实现这个操作,效率是非常高的。但是如果有多于三个变量的值要依次互换,这个时候没有直接可用的字节码指令,执行的原理就是我们上面讲解的打包和解包操作。
元组和列表的比较
- 元组是不可变类型,不可变类型更适合多线程环境,因为它降低了并发访问变量的同步化开销。关于这一点,我们会在后面讲解多线程的时候为大家详细论述。
- 元组是不可变类型,通常不可变类型在创建时间和占用空间上面都优于对应的可变类型。我们可以使用
sys模块的getsizeof函数来检查保存相同元素的元组和列表各自占用了多少内存空间。我们也可以使用timeit模块的timeit函数来看看创建保存相同元素的元组和列表各自花费的时间,代码如下所示。
```python import sys import timeit
a = list(range(100000)) b = tuple(range(100000)) print(sys.getsizeof(a), sys.getsizeof(b)) # 900120 800056
print(timeit.timeit(‘[1, 2, 3, 4, 5, 6, 7, 8, 9]’)) # 0.05915190000000001 print(timeit.timeit(‘(1, 2, 3, 4, 5, 6, 7, 8, 9)’)) # 0.006949700000000003
3. Python中的元组和列表是可以相互转换的,我们可以通过下面的代码来做到。```python# 将元组转换成列表info = ('骆昊', 175, True, '四川成都')print(list(info)) # ['骆昊', 175, True, '四川成都']# 将列表转换成元组fruits = ['apple', 'banana', 'orange']print(tuple(fruits)) # ('apple', 'banana', 'orange')
总结:列表和元组都是容器型的数据类型,即一个变量可以保存多个数据。列表是可变数据类型,元组是不可变数据类型,所以列表添加元素、删除元素、清空、排序等方法对于元组来说是不成立的。但是列表和元组都可以进行拼接、成员运算、索引和切片这些操作,后面我们要讲到的字符串类型也是这样,因为字符串就是字符按一定顺序构成的序列,在这一点上三者并没有什么区别。我们推荐大家使用列表的生成式语法来创建列表,它很好用,也是Python中非常有特色的语法。
字符串 str
- 在Python程序中,如果我们把单/多个字符用单/双引号包围起来,就表示它是一个字符串。不论是单个字符还是多个字符,用单引号或者双引号都可以。
- 字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等。
s1 = 'hello, world!'s2 = "你好,世界!"# 以三个双/单引号开头的字符串可以折行s3 = '''hello,world!'''print(s3, end='')# 输出带有单引号或反斜杠的字符串s1 = '\'hello, world!\'' # 'hello, world!'s2 = '\\hello, world!\\' # \hello, world!\s1 = '\141\142\143\x61\x62\x63' # abcabc
print函数中的end=''表示输出后不换行,即将默认的结束符\n(换行符)更换为''(空字符)。\(反斜杠)来表示转义,例如\n表示换行;\t表示制表符。所以如果字符串本身又包含了'、"、\这些特殊的字符,必须要通过\进行转义处理。\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。另外一种表示字符的方式是在\u后面跟Unicode字符编码。
运算
- 与列表相似,我们可以使用
+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in(成员运算)来判断一个字符串是否包含另外一个字符串,用len(s)获取字符串长度。 - 比较运算符,用来比较相等性
==!=或大小><,比较的是每个字符对应的编码的大小。例如A的编码是65, 而a的编码是97,所以'A' < 'a'。如果不清楚两个字符对应的编码到底是多少,可以使用ord函数来获得。 身份运算符
is,比较两个变量对应的字符串对象的内存地址,简单的说就是两个变量是否对应内存中的同一个字符串。s1 = 'hello world's2 = 'hello world's3 = s2# 比较字符串的内容print(s1 == s2, s2 == s3) # True True# 比较字符串的内存地址print(s1 is s2, s2 is s3) # False True
索引和切片,我们可以用
[]和[:]运算符从字符串取出某个字符或某些字符,使用[i:j:k]时k是步长。- 大小写转换,
s1.capitalize()使字符串首字母大写,s1.title()使字符串中每个单词的首字母大写,s1.upper()使字符串每个字母全部大写,s1.lower()使字符串每个字母全部小写。
增删改查
- 字符串是不可变类型,所以不能通过索引运算修改字符串中的字符。
- 如果想在一个字符串中从前向后查找有没有另外一个字符串,可以使用字符串的
find或index方法,作用都是返回所查找字符串的首字符的索引。找不到时,find返回-1,index引发异常ValueError: substring not found。注:列表只有index方法,没有find。 - 在使用
find和index方法时还可以通过方法的参数来指定查找的起始位置。也有逆向查找(从后向前查找)的版本,分别是rfind和rindex。
s = 'hello, world!'# 循环遍历每个字符有2种方法for index in range(len(s)):print(s[index])for ch in s:print(ch)# 查找print(s.find('or')) # 8print(s.index('o')) # 4print(s.find('o', 5)) # 8,指定查找的起始位置print(s.rfind('o')) # 8
startswith、endswith来判断字符串是否以某个字符串开头和结尾。is开头的方法判断字符串的特征,这些方法都返回布尔值。- 字符串类型可以通过
center、ljust、rjust方法做居中、左对齐和右对齐的处理。如果要在字符串的左侧补零,也可以使用zfill方法。
s1 = 'hello, world!'# startwith方法检查字符串是否以指定的字符串开头print(s1.startswith('He')) # Falseprint(s1.startswith('hel')) # True# endswith方法检查字符串是否以指定的字符串结尾print(s1.endswith('!')) # Trues2 = 'abc123456'# isdigit,检查字符串是否由数字构成print(s2.isdigit()) # False# isalpha,检查字符串是否以字母构成print(s2.isalpha()) # False# isalnum,检查字符串是否以数字和字母构成print(s2.isalnum()) # True
格式化字符串
- 字符串类型可以通过
center、ljust、rjust方法做居中、左对齐和右对齐的处理。如果要在字符串的左侧补零,也可以使用zfill方法。
s = 'hello, world'# center方法以宽度20将字符串居中并在两侧填充*print(s.center(20, '*')) # ****hello, world****# rjust方法以宽度20将字符串右对齐并在左侧填充空格print(s.rjust(20)) # hello, world# ljust方法以宽度20将字符串左对齐并在右侧填充~print(s.ljust(20, '~')) # hello, world~~~~~~~~# 在字符串的左侧补零print('33'.zfill(5)) # 00033print('-33'.zfill(5)) # -0033
print()输出时字符串时,有3种方法格式化字符串:%d / %f、{}.format()、f'{}'
a = 321b = 123print('%d * %d = %f' % (a, b, a * b)) # %f 默认输出6位小数print('{0} * {1} = {2}'.format(a, b, a * b))print(f'{a} * {b} = {a * b}')
如果需要进一步控制格式化语法中变量值的形式,可以参照下面的表格来进行字符串格式化操作。
| 变量值 | 占位符 | 格式化结果 | 说明 |
|---|---|---|---|
3.1415926 |
{:.2f} |
'3.14' |
保留小数点后两位 |
3.1415926 |
{:+.2f} |
'+3.14' |
带符号保留小数点后两位 |
-1 |
{:+.2f} |
'-1.00' |
带符号保留小数点后两位 |
3.1415926 |
{:.0f} |
'3' |
不带小数 |
123 |
{:0>10d} |
'0000000123' |
左边补0,补够10位 |
123 |
{:x<10d} |
'123xxxxxxx' |
右边补x,补够10位 |
123 |
{:>10d} |
' 123' |
左边补空格,补够10位 |
123 |
{:<10d} |
'123 ' |
右边补空格,补够10位 |
123456789 |
{:,} |
'123,456,789' |
逗号分隔格式 |
0.123 |
{:.2%} |
'12.30%' |
百分比格式 |
123456789 |
{:.2e} |
'1.23e+08' |
科学计数法格式 |
- 修剪,字符串的
strip方法可以修剪掉原字符串左右两端的空格,通常用来将用户输入中因为不小心键入的头尾空格去掉。strip方法还有lstrip和rstrip两个版本,剪左或者剪右。 - 替换,
replace方法的第一个参数是被替换的内容,第二个参数是替换后的内容,还可以通过第三个参数指定替换的次数。 - 拆分,
split方法将一个字符串拆分为多个字符串并放在一个列表中。默认使用空格进行拆分,也可以指定其他的字符来拆分字符串,而且还可以指定最大拆分次数来控制拆分的效果。 - 合并,
join方法将列表中的多个字符串连接成一个字符串。
# 修剪s = ' jackfrued@126.com \t\r\n'print(s.strip()) # jackfrued@126.com# 替换s = 'hello, world'print(s.replace('o', '@')) # hell@, w@rldprint(s.replace('o', '@', 1)) # hell@, world# 拆分s = 'I love you'words = s.split() # ['I', 'love', 'you']s = 'I#love#you#so#much'words = s.split('#') # ['I', 'love', 'you', 'so', 'much']words = s.split('#', 3) # ['I', 'love', 'you', 'so#much']# 合并print('-'.join(words)) # I-love-you-so#much
- 编码和解码,Python中除了字符串
str类型外,还有一种表示二进制数据的字节串类型(bytes)。所谓字节串,就是由零个或多个字节组成的有限序列。通过字符串的encode方法,我们可以按照某种编码方式将字符串编码为字节串,我们也可以使用字节串的decode方法,将字节串解码为字符串。
a = '你好'b = a.encode('utf-8')c = a.encode('gbk')print(b, c) # b'\xe4\xbd\xa0\xe5\xa5\xbd' b'\xc4\xe3\xba\xc3'print(b.decode('utf-8')) # 要用和编码相同的方法解码,否则结果与输入不同。print(c.decode('gbk'))
字典 dict
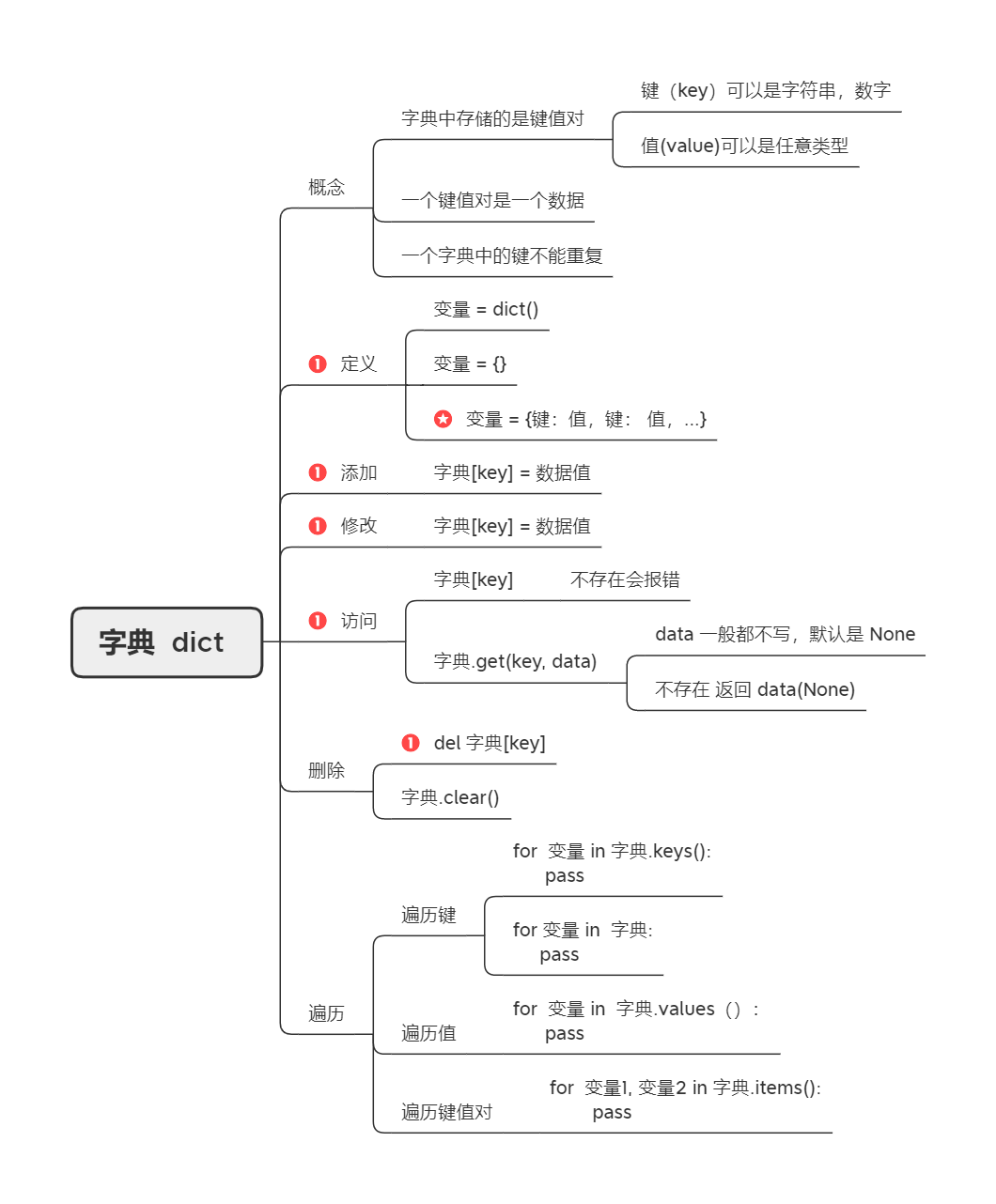
字典以键值对(键和值的组合)的方式把数据组织到一起,我们可以通过键找到与之对应的值并进行操作。就像《新华字典》中,每个字(键)都有与它对应的解释(值)一样。
键必须是不可变类型,例如整数(int)、浮点数(float)、字符串(str)、元组(tuple)等类型的值;显然,列表(list)和集合(set)不能作为字典中的键。
创建字典:一个条目以{}表示,冒号分隔键和值。
person = {'name': '王大锤', 'age': 55, 'weight': 60, 'office': '科华北路62号','home': '中同仁路8号', 'tel': '13122334455', 'econtact': '13800998877'}
也使用内置函数dict或字典的生成式语法来创建字典:
# dict函数(构造器)中的每一组参数就是字典中的一组键值对person = dict(name='王大锤', age=55, weight=60, home='中同仁路8号')print(person) # {'name': '王大锤', 'age': 55, 'weight': 60, 'home': '中同仁路8号'}# 可以通过Python内置函数zip压缩两个序列并创建字典items1 = dict(zip('ABCDE', '12345'))print(items1) # {'A': '1', 'B': '2', 'C': '3', 'D': '4', 'E': '5'}items2 = dict(zip('ABCDE', range(1, 10)))print(items2) # {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5}# 用字典生成式语法创建字典items3 = {x: x ** 3 for x in range(1, 6)}print(items3) # {1: 1, 2: 8, 3: 27, 4: 64, 5: 125}
len()获取字典中有多少组键值对。for循环只遍历键,通过键可以获取该键对应的值。
字典的运算
person = {'name': '王大锤', 'age': 55, 'weight': 60, 'office': '科华北路62号'}# 检查name和tel两个键在不在person字典中print('name' in person, 'tel' in person) # True False# 修改值if 'age' in person:person['age'] = 25# 存入新的键值对person['tel'] = '13122334455'# 检查person字典中键值对的数量print(len(person)) # 5# 对字典的键进行循环并通索引运算获取键对应的值for key in person:print(f'{key}: {person[key]}')
字典的方法
- 字典的索引是键值对中的键,如指定的键没有在字典中,将会引发
KeyError异常。 - 使用
get方法通过键获取对应的值,如果取不到不会引发KeyError异常而是返回None或设定的默认值。 - 字典的键只能是不可变类型,但值可以是任意类型,因此可以做到嵌套字典。
- 跟列表一样,从字典中删除元素也可以使用
del关键字,在删除元素的时候如果指定的键索引不到对应的值,一样会引发KeyError异常。
# 字典中的值又是一个字典(嵌套的字典)students = {1001: {'name': '狄仁杰', 'sex': True, 'age': 22, 'place': '山西大同'},1002: {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'},1003: {'name': '武则天', 'sex': False, 'age': 20, 'place': '四川广元'}}# 使用get方法通过键获取对应的值,如果取不到不会引发KeyError异常而是返回None或设定的默认值print(students.get(1002)) # {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'}print(students.get(1005)) # Noneprint(students.get(1005, {'name': '无名氏'})) # {'name': '无名氏'}# 获取字典中所有的键print(students.keys()) # dict_keys([1001, 1002, 1003])# 获取字典中所有的值print(students.values()) # dict_values([{...}, {...}, {...}])# 获取字典中所有的键值对print(students.items()) # dict_items([(1001, {...}), (1002, {....}), (1003, {...})])# 对字典中所有的键值对进行循环遍历for key, value in students.items():print(key, '--->', value)# 使用pop方法通过键删除对应的键值对并返回该值stu1 = students.pop(1002)print(stu1) # {'name': '白元芳', 'sex': True, 'age': 23, 'place': '河北保定'}print(len(students)) # 2# stu2 = students.pop(1005) # KeyError: 1005stu2 = students.pop(1005, {})print(stu2) # {}# 使用popitem方法删除字典中最后一组键值对并返回对应的二元组# 如果字典中没有元素,调用该方法将引发KeyError异常key, value = students.popitem()print(key, value) # 1003 {'name': '武则天', 'sex': False, 'age': 20, 'place': '四川广元'}# setdefault可以向字典中存入新的键值对或返回指定的键对应的值result = students.setdefault(1005, {'name': '方启鹤', 'sex': True})print(result) # {'name': '方启鹤', 'sex': True}print(students) # {1001: {...}, 1005: {...}}# 使用update更新字典元素,相同的键会用新值覆盖掉旧值,不同的键会添加到字典中others = {1005: {'name': '乔峰', 'sex': True, 'age': 32, 'place': '北京大兴'},1010: {'name': '王语嫣', 'sex': False, 'age': 19},1008: {'name': '钟灵', 'sex': False}}students.update(others) # {1001: {...}, 1005: {...}, 1010: {...}, 1008: {...}}# 使用del删除元素person = {'name': '王大锤', 'age': 25, 'sex': True}del person['age'] # {'name': '王大锤', 'sex': True}
字典的应用
我们通过几个简单的例子来讲解字典的应用。
例子1:输入一段话,统计每个英文字母出现的次数。
sentence = input('请输入一段话: ')counter = {}for ch in sentence:if 'A' <= ch <= 'Z' or 'a' <= ch <= 'z':counter[ch] = counter.get(ch, 0) + 1for key, value in counter.items():print(f'字母{key}出现了{value}次.')
例子2:在一个字典中保存了股票的代码和价格,找出股价大于100元的股票并创建一个新的字典。
stocks = {'AAPL': 191.88,'GOOG': 1186.96,'IBM': 149.24,'ORCL': 48.44,'ACN': 166.89,'FB': 208.09,'SYMC': 21.29}stocks2 = {key: value for key, value in stocks.items() if value > 100}print(stocks2)
集合 set
集合的特性:无序性、互异性、确定性。
无序,所以集合不支持索引;互异,即集合里没有重复的元素。确定,是指一个元素是否属于一个集合是确定的。
集合的成员运算在性能上要优于列表的成员运算,这是集合的底层存储特性(哈希存储)决定的。
创建集合
- 在Python中,创建集合可以使用
{}字面量语法,{}中需要至少有一个元素,因为没有元素的{}并不是空集合而是一个空字典。 - 也可以使用内置函数
set来创建一个集合,准确的说set并不是一个函数,而是创建集合对象的构造器。创建空集合可以使用set()。 - 也可以将其他序列(str、list类型)转换成集合,例如:
set('hello')会得到一个包含了4个字符的集合(重复的l会被去掉)。 - 还可以使用生成式语法来创建集合,就像我们之前用生成式创建列表那样。
# 创建集合的字面量语法(重复元素不会出现在集合中)set1 = {1, 2, 3, 3, 3, 2}print(set1) # {1, 2, 3}print(len(set1)) # 3# 创建集合的构造器语法(后面会讲到什么是构造器)set2 = set('hello') # {'h', 'l', 'o', 'e'}# 将列表转换成集合(可以去掉列表中的重复元素)set3 = set([1, 2, 3, 3, 2, 1])print(set3) # {1, 2, 3}# 创建集合的生成式语法(将列表生成式的[]换成{})set4 = {num for num in range(1, 20) if num % 3 == 0 or num % 5 == 0}print(set4) # {3, 5, 6, 9, 10, 12, 15, 18}
len()计算集合中元素的个数;for循环实现对集合元素的遍历。- 集合中的元素必须是
hashable类型。- 所谓
hashable类型指的是能够计算出哈希码的数据类型,大家可以暂时将哈希码理解为和变量对应的唯一的ID值。 - 通常不可变类型都是
hashable类型,如整数、浮点、字符串、元组等,而可变类型都不是hashable类型,因为可变类型无法确定唯一的ID值,所以也就不能放到集合中。 - 集合本身是可变类型,所以集合不能够作为集合中的元素,这一点在使用集合的时候一定要注意。
- 所谓
集合的运算
Python为集合类型提供了非常丰富的运算符,主要包括:成员运算、交集运算、并集运算、差集运算、比较运算(相等性、子集、超集)等。
- 成员运算:
in和not in,检查元素是否存在于集合中。 - 交并差运算:运算符
&|-^,或者方法调用。
# 成员运算set1 = {'Python', 'Java', 'Go', 'Swift'}print('Ruby' in set1) # Falseset1 = {1, 2, 3, 4, 5, 6, 7}set2 = {2, 4, 6, 8, 10}# 交集print(set1 & set2) # {2, 4, 6}print(set1.intersection(set2)) # {2, 4, 6}# 并集print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8, 10}print(set1.union(set2)) # {1, 2, 3, 4, 5, 6, 7, 8, 10}# 差集print(set1 - set2) # {1, 3, 5, 7}print(set1.difference(set2)) # {1, 3, 5, 7}# 对称差print(set1 ^ set2) # {1, 3, 5, 7, 8, 10}print(set1.symmetric_difference(set2)) # {1, 3, 5, 7, 8, 10}# 方法三: 对称差相当于两个集合的并集减去交集print((set1 | set2) - (set1 & set2)) # {1, 3, 5, 7, 8, 10}

集合的交集、并集、差集运算还可以跟赋值运算一起构成复合赋值运算,如下所示。
set1 = {1, 3, 5, 7}set2 = {2, 4, 6}# 将set1和set2求并集再赋值给set1# 也可以通过set1.update(set2)来实现set1 |= set2print(set1) # {1, 2, 3, 4, 5, 6, 7}set3 = {3, 6, 9}# 将set1和set3求交集再赋值给set1# 也可以通过set1.intersection_update(set3)来实现set1 &= set3print(set1) # {3, 6}
- 比较运算:
==!=,判断子集和超集(A是B的子集反过来称B是A的超集)用>和<。如果A是B的子集且A不等于B,那么A是B的真子集。
set1 = {1, 3, 5}set2 = {1, 2, 3, 4, 5}set3 = set2# <运算符表示真子集,<=运算符表示子集print(set1 < set2, set1 <= set2) # True Trueprint(set2 < set3, set2 <= set3) # False True# 通过issubset方法也能进行子集判断print(set1.issubset(set2)) # True# 反过来可以用issuperset或>运算符进行超集判断print(set2.issuperset(set1)) # Trueprint(set2 > set1) # True
如果要判断两个集合有没有相同的元素可以使用isdisjoint方法,没有相同元素返回True,否则返回False,代码如下所示。
set1 = {'Java', 'Python', 'Go', 'Kotlin'}set2 = {'Kotlin', 'Swift', 'Java', 'Objective-C', 'Dart'}set3 = {'HTML', 'CSS', 'JavaScript'}print(set1.isdisjoint(set2)) # Falseprint(set1.isdisjoint(set3)) # True
集合的方法(增删)
- add(x)、update({x1, x2 …}) 添加
- discard(x) 删除,元素不存在不会报错
- remove(x) 删除,元素不存在引发 keyError 异常
- pop() 随机删除并返回该元素
- clear() 全部删除
# 创建一个空集合set1 = set()# 通过add方法添加元素set1.add(33)set1.add(55)set1.update({1, 10, 100, 1000})print(set1) # {33, 1, 100, 55, 1000, 10}# 通过discard方法删除指定元素set1.discard(100)set1.discard(99)print(set1) # {1, 10, 33, 55, 1000}# 通过remove方法删除指定元素,建议先做成员运算再删除# 否则元素如果不在集合中就会引发KeyError异常if 10 in set1:set1.remove(10)print(set1) # {33, 1, 55, 1000}# pop方法可以从集合中随机删除一个元素并返回该元素print(set1.pop())# clear方法可以清空整个集合set1.clear()print(set1) # set()
集合是可变类型,python中有一种不可变类型的集合frozenset。set跟frozenset的区别就如同list跟tuple的区别,frozenset由于是不可变类型,能够计算出哈希码,因此它可以作为set中的元素。除了不能添加和删除元素,frozenset在其他方面跟set基本是一样的,下面的代码简单的展示了frozenset的用法。
set1 = frozenset({1, 3, 5, 7})set2 = frozenset(range(1, 6))print(set1 & set2) # frozenset({1, 3, 5})print(set1 | set2) # frozenset({1, 2, 3, 4, 5, 7})print(set1 - set2) # frozenset({7})print(set1 < set2) # False
函数
解决代码重复问题,将需要重复的代码封装到一个代码块中,它称为函数。
重构,是在不影响代码执行结果的前提下对代码的结构进行调整。例如将某块代码封装起来。
变量
变量的引用
- 在定义变量的时候,Python解释器会在内存中开辟两块空间,变量和数据都有自己的空间。
- 简单理解,将数据保存到变量的内存中,本质是将数据的地址保存到变量对应的内存中。
- 变量中存储数据地址的行为就是引用(变量引用了数据的地址),存储的地址称为引用地址。
- 可以使用
id()来获取变量中的引用地址(即数据的地址)。 - 只有赋值运算符
=可以改变变量(等号左边数据)的引用。
局部变量
在函数内部定义的变量,称为是局部变量。特点:
- 局部变量只能在当前函数内部使用,不能在其他函数和函数外部使用。
- 在不同函数中,可以定义名字相同的局部变量,两者之间没有影响。
- 生存周期(生命周期,作用范围)—>在哪能用在函数被调用的时候,局部变量被创建,函数调用结束,局部变量的值被销毁(删除),不能使用。
所以函数中的局部变量的值,如果想要在函数外部使用,需要使用return关键字,将这个值进行返回。
全局变量
在函数外部定义的变量,称为是全局变量。特点:
- 可以在任何函数中读取(获取)全局变量的值。
- 如何在函数中存在和全局变量名字相同的局部变量,在函数中使用的是局部变量的值(就近)。
- 在函数内部想要修改全局变量的引用,需要在函数内添加
global关键字,声明该变量是全局变量。 - 生命周期:代码执行的时候被创建,代码执行结束,被销毁(删除)。
函数传参
完整的参数顺序:
def 函数名(普通函数, *args, 缺省参数, **kwargs):pass
函数传参的方式
- 位置传参:在函数调用的时候,按照形参的顺序,将实参值传递给形参。
- 关键字传参:在函数调用的时候,指定数据值给到那个形参。
- 混合使用:关键字传参必须写在位置传参的后面,且不要给一个形参传递多个数据值。 ```python def func(a, b, c): print(f’a: {a}, b: {b}, c: {c}’)
func(1, 2, 3) # 位置传参 func(a=2, b=3, c=1) # 关键字传参 func(1, 3, c=5) # 混合使⽤
**缺省参数/默认参数**<br />定义方式:在函数定义的时候,给形参一个默认的数据值,这个形参就变为缺省参数。<br />注意,缺省参数的书写要放在普通参数的后边。<br />特点(好处):缺省参数,在函数调用的时候,可以传递实参值,也可以不传递实参值。如果不传参,使用的就是默认值。<a name="Ff8xR"></a>#### 可变参数- 带默认值的参数必须放在不带默认值的参数之后,否则将产生`SyntaxError`错误,错误消息是:`non-default argument follows default argument`。- 函数可以通过星号表达式语法来支持**可变参数**。所谓可变参数指的是在调用函数时,可以向函数传入`0`个或任意多个参数。**不定长位置参数(不定长元组参数)**- 书写,在普通参数的前边,加上一个*,这个参数就变为不定长位置参数。- 特点,这个形参可以接收任意多个位置传参的数据。- 数据类型,形参的类型是元组。- 注意,不定长位置参数要写在普通的参数的后面。- 一般写法,不定长位置参数的名字为args,即`*args` # arguments```python# 用星号表达式来表示args可以接收0个或任意多个参数def add(*args):total = 0# 可变参数可以放在for循环中取出每个参数的值for val in args:if type(val) in (int, float):total += valreturn total
- 如果我们从两个不同的模块中导入了同名的函数,后导入的函数会覆盖掉先前的导入。
不定长关键字参数(不定长字典参数)
- 书写,在普通参数的前边,加上两个*,这个参数就变为不定长关键字参数。
- 特点,这个形参可以接收任意多个关键字传参的数据。
- 数据类型,形参的类型是字典。
- 注意,不定长关键字参数,要写在所有参数的最后边。
- 一般写法,不定长关键字参数的名字为kwargs,即
**kwargs, keyword arguments。
关键字参数
- 在调用函数传入参数时,我们可以指定参数名,也可以不指定参数名,不指定时传入的参数依次对号入座。
- 如果希望调用函数时必须指定参数名,可以使用命名关键字参数(keyword-only argument),它是在函数的参数列表中写在
*之后的参数,代码如下所示。
```python def is_triangle(*, a, b, c): print(f’a = {a}, b = {b}, c = {c}’) return a + b > c and b + c > a and a + c > b
传参时必须使用“参数名=参数值”的方式,位置不重要
print(is_triangle(a=3, b=4, c=5)) print(is_triangle(c=5, b=4, a=3))
> **注意**:上面的`is_triangle`函数,参数列表中的`*`是一个分隔符,`*`前面的参数都是位置参数,而`*`后面的参数就是命名关键字参数。- 我们之前讲过在函数的参数列表中可以使用**可变参数**`*args`来接收任意数量的参数,但`*args`不能接收带参数名的参数。```pythondef calc(*args):result = 0for arg in args:if type(arg) in (int, float):result += argreturn resultprint(calc(a=1, b=2, c=3))# 引发`TypeError`错误,错误消息为`calc() got an unexpected keyword argument 'a'`
- 我们在设计函数时,如果既不知道调用者会传入的参数个数,也不知道调用者会不会指定参数名,那么同时使用可变参数和关键字参数。关键字参数会将传入的带参数名的参数组装成一个字典,参数名就是字典中键值对的键,而参数值就是字典中键值对的值,代码如下所示。
def calc(*args, **kwargs):result = -1for arg in args:if type(arg) in (int, float):result += argfor value in kwargs.values():if type(value) in (int, float):result *= valuereturn resultprint(calc()) # -1print(calc(2, 3)) # 4print(calc(a=4, b=2, c=3)) # -24print(calc(2, c=3, d=4)) # 12
不带参数名的参数(位置参数)必须出现在带参数名的参数(关键字参数)之前,否则将会引发异常。例如,执行calc(1, 2, c=3, d=4, 5)将会引发SyntaxError错误,错误消息为positional argument follows keyword argument,翻译成中文意思是“位置参数出现在关键字参数之后”。
内置函数
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数。下面的表格列出了一部分内置函数。
| 内置函数 | 说明 |
|---|---|
abs |
返回一个数的绝对值,例如:abs(-1.3)返回1.3 |
bin |
把一个整数转换成以'0b'开头的二进制字符串,例如:bin(123)返回'0b1111011' |
chr |
将Unicode编码转换成对应的字符,例如:chr(8364)返回'€' |
hex |
将一个整数转换成以'0x'开头的十六进制字符串,例如:hex(123)返回'0x7b' |
input |
从输入中读取一行,返回读到的字符串。 |
len |
获取字符串、列表等的长度。 |
max |
返回多个参数或一个可迭代对象中的最大值,例如:max(12, 95, 37)返回95 |
min |
返回多个参数或一个可迭代对象中的最小值,例如:min(12, 95, 37)返回12 |
oct |
把一个整数转换成以'0o'开头的八进制字符串,例如:oct(123)返回'0o173' |
open |
打开一个文件并返回文件对象。 |
ord |
将字符转换成对应的Unicode编码,例如:ord('€')返回8364 |
pow |
求幂运算,例如:pow(2, 3)会返回8;pow(2, 0.5)会返回1.4142135623730951 |
print |
打印输出。 |
range |
构造一个范围序列,例如:range(100)会产生0到99的整数序列。 |
round |
按照指定的精度对数值进行四舍五入,例如:round(1.23456, 4)会返回1.2346 |
sum |
对一个序列中的项从左到右进行求和运算,例如:sum(range(1, 101))返回5050 |
type |
返回对象的类型,例如:type(10)返回int;而type('hello')返回 str。 |
print函数,默认end='\n',默认以在多个参数之间打印空格sep=' '。
可以在print时修改结束符和间隔符。
print(1,end=' ')print(1,2,3,4,5,6,sep='_')print(1, 2, 3, 4, 5, 6, sep='_*_')
高阶函数的用法
在面向对象的世界中,一切皆为对象,类和函数也是对象。函数的参数和返回值可以是任意类型的对象,这就意味着函数本身也可以作为函数的参数或返回值,这就是所谓的高阶函数。
如果我们希望上面的calc函数不仅仅可以做多个参数求和,还可以做多个参数求乘积甚至更多的二元运算,我们就可以使用高阶函数的方式来改写上面的代码:
def calc(*args, init_value, op, **kwargs):result = init_valuefor arg in args:if type(arg) in (int, float):result = op(result, arg)for value in kwargs.values():if type(value) in (int, float):result = op(result, value)return result
init_value代表运算的初始值,op代表二元运算函数。经过改造的calc函数不仅仅可以实现多个参数的累加求和,也可以实现多个参数的累乘运算,这是一种解耦合的编程技巧:
def add(x, y):return x + ydef mul(x, y):return x * yprint(calc(1, 2, 3, init_value=0, op=add, x=4, y=5)) # 15print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=mul)) # 120
将函数作为参数和调用函数是有显著的区别的,调用函数需要在函数名后面跟上圆括号,而把函数作为参数时只需要函数名即可。上面的代码也可以不用定义add和mul函数,因为Python标准库中的operator模块提供了代表加法运算的add和代表乘法运算的mul函数,我们直接使用即可,代码如下所示。
import operatorprint(calc(1, 2, 3, init_value=0, op=operator.add, x=4, y=5)) # 15print(calc(1, 2, x=3, y=4, z=5, init_value=1, op=operator.mul)) # 120
Python内置函数中有不少高阶函数,比如filter和map函数,前者实现对序列中元素的过滤,后者实现对序列中元素的映射。例如,去掉一个整数列表中的奇数,并对所有的偶数求平方得到一个新的列表:
def is_even(num):return num % 2 == 0def square(num):return num ** 2numbers1 = [35, 12, 8, 99, 60, 52]numbers2 = list(map(square, filter(is_even, numbers1)))print(numbers2) # [144, 64, 3600, 2704]
- filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。它接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
- 注意: Python2.7 返回列表,Python3.x 返回迭代器对象。
- python3 中 filter 类实现了
__iter__和__next__方法, 可以看成是一个迭代器, 有惰性运算的特性, 相对 python2 提升了性能, 可以节约内存。
- map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
当然,要完成上面代码的功能,也可以使用列表生成式,列表生成式的做法更为简单优雅。
numbers1 = [35, 12, 8, 99, 60, 52]numbers2 = [num ** 2 for num in numbers1 if num % 2 == 0]print(numbers2) # [144, 64, 3600, 2704]
Lambda函数
在使用高阶函数的时候,如果作为参数或者返回值的函数本身非常简单,一行代码就能够完成,那么我们可以使用Lambda函数来表示。Python中的Lambda函数是没有的名字函数,所以也称为匿名函数,匿名函数只能有一行代码,代码中的表达式产生的运算结果就是这个匿名函数的返回值。上面代码中的is_even和square函数都只有一行代码,我们可以用Lambda函数来替换掉它们,代码如下所示。
numbers1 = [35, 12, 8, 99, 60, 52]numbers2 = list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 0, numbers1)))print(numbers2) # [144, 64, 3600, 2704]
通过上面的代码可以看出,定义Lambda函数的关键字是lambda,后面跟函数的参数,如果有多个参数用逗号进行分隔;冒号后面的部分就是函数的执行体,通常是一个表达式,表达式的运算结果就是Lambda函数的返回值,不需要写return 关键字。
如果需要使用加减乘除这种简单的二元函数,也可以用Lambda函数来书写,例如调用上面的calc函数时,可以通过传入Lambda函数来作为op参数的参数值。当然,op参数也可以有默认值,例如我们可以用一个代表加法运算的Lambda函数来作为op参数的默认值。
def calc(*args, init_value=0, op=lambda x, y: x + y, **kwargs):result = init_valuefor arg in args:if type(arg) in (int, float):result = op(result, arg)for value in kwargs.values():if type(value) in (int, float):result = op(result, value)return result# 调用calc函数,使用init_value和op的默认值print(calc(1, 2, 3, x=4, y=5)) # 15# 调用calc函数,通过lambda函数给op参数赋值print(calc(1, 2, 3, x=4, y=5, init_value=1, op=lambda x, y: x * y)) # 120
注意上面的代码中的calc函数,它同时使用了可变参数、关键字参数、命名关键字参数,其中命名关键字参数要放在可变参数和关键字参数之间,传参时先传入可变参数,关键字参数和命名关键字参数的先后顺序并不重要。
有很多函数在Python中用一行代码就能实现,我们可以用Lambda函数来定义这些函数,调用Lambda函数就跟调用普通函数一样,代码如下所示。
import operator, functools# 一行代码定义求阶乘的函数fac = lambda num: functools.reduce(operator.mul, range(1, num + 1), 1)# 一行代码定义判断素数的函数is_prime = lambda x: x > 1 and all(map(lambda f: x % f, range(2, int(x ** 0.5) + 1)))# 调用Lambda函数print(fac(10)) # 3628800print(is_prime(9)) # False
- reduce(function, iterable[, initializer]) 函数会对参数序列中元素进行累积。它将一个数据集合(链表,元组等)中的所有数据进行下列操作:先对集合中的第 1、2 个元素进行 function(有两个参数)操作,得到的结果再与第三个数据用 function 函数运算…直到最后。
- all( ) 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为
True,如果是返回 True,否则返回 False。元素除了是 0、空、None、False 外都算 True。
提示1:上面使用的
reduce函数是Python标准库functools模块中的函数,它可以实现对数据的归约操作,通常情况下,过滤(filter)、映射(map)和归约(reduce)是处理数据中非常关键的三个步骤,而Python的标准库也提供了对这三个操作的支持。
装饰器 Decorators
装饰器是Python中用一个函数装饰另外一个函数或类并为其提供额外功能的语法现象。装饰器本身是一个函数,它的参数是被装饰的函数或类,它的返回值是一个带有装饰功能的函数。很显然,装饰器是一个高阶函数,它的参数和返回值都是函数。
下面我们先通过一个简单的例子来说明装饰器的写法和作用:
import randomimport timedef download(filename):print(f'开始下载{filename}.')time.sleep(random.randint(2, 6)) # 随机休眠几秒print(f'{filename}下载完成.')def upload(filename):print(f'开始上传{filename}.')time.sleep(random.randint(4, 8)) # 随机休眠几秒print(f'{filename}上传完成.')start = time.time()download('MySQL从删库到跑路.avi')end = time.time()print(f'花费时间: {end - start:.3f}秒')start = time.time()upload('Python从入门到住院.pdf')end = time.time()print(f'花费时间: {end - start:.3f}秒')
通过上面的代码,我们可以得到下载和上传花费的时间。需要注意到,上面记录时间、计算和显示执行时间的代码都是重复代码。有编程经验的人都知道,重复的代码是万恶之源,那么有没有办法在不写重复代码的前提下,用一种简单优雅的方式记录下函数的执行时间呢?在Python中,装饰器就是解决这类问题的最佳选择。
我们可以把记录函数执行时间的功能封装到一个装饰器中,在有需要的地方直接使用这个装饰器就可以了,代码如下所示。
import time# 定义装饰器函数,它的参数是被装饰的函数或类def record_time(func):# 定义一个带装饰功能(记录被装饰函数的执行时间)的函数# 因为不知道被装饰的函数有怎样的参数所以使用*args和**kwargs接收所有参数# 在Python中函数可以嵌套的定义(函数中可以再定义函数)def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs)end = time.time()print(f'{func.__name__}执行时间: {end - start:.3f}秒')# 返回被装饰函数的返回值(装饰器通常不会改变被装饰函数的执行结果)return result# 返回带装饰功能的wrapper函数return wrapperdownload = record_time(download)upload = record_time(upload)download('MySQL从删库到跑路.avi')upload('Python从入门到住院.pdf')
使用上面的装饰器函数有两种方式,第一种方式就是直接调用装饰器函数,传入被装饰的函数并获得返回值,我们可以用这个返回值直接覆盖原来的函数,那么在调用时就已经获得了装饰器提供的额外的功能(记录执行时间)。wrapper()函数的参数定义是(*args, **kwargs),因此,wrapper()函数可以接受任意参数的调用。
在Python中,使用装饰器很有更为便捷的语法糖,可以用@装饰器函数将装饰器函数直接放在被装饰的函数上,效果跟上面的代码相同,这就是第二种方式。下面是完整的代码。
import randomimport timedef record_time(func):def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs)end = time.time()print(f'{func.__name__}执行时间: {end - start:.3f}秒')return resultreturn wrapper@record_timedef download(filename):print(f'开始下载{filename}.')time.sleep(random.randint(2, 6))print(f'{filename}下载完成.')@record_timedef upload(filename):print(f'开始上传{filename}.')time.sleep(random.randint(4, 8))print(f'{filename}上传完成.')download('MySQL从删库到跑路.avi')upload('Python从入门到住院.pdf')
上面被装饰后的download和upload函数是我们在装饰器record_time中返回的wrapper函数,调用它们其实就是在调用wrapper函数,所以拥有了记录函数执行时间的功能。相当于执行了语句 download = record_time(download)。
如果希望取消装饰器的作用,那么在定义装饰器函数的时候,需要做一些额外的工作。Python标准库functools模块的wraps函数也是一个装饰器,我们将它放在wrapper函数上,这个装饰器可以帮我们保留被装饰之前的函数,这样在需要取消装饰器时,可以通过被装饰函数的__wrapped__属性获得被装饰之前的函数。
import randomimport timefrom functools import wrapsdef record_time(func):@wraps(func)def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs)end = time.time()print(f'{func.__name__}执行时间: {end - start:.3f}秒')return resultreturn wrapper@record_timedef download(filename):print(f'开始下载{filename}.')time.sleep(random.randint(2, 6))print(f'{filename}下载完成.')@record_timedef upload(filename):print(f'开始上传{filename}.')time.sleep(random.randint(4, 8))print(f'{filename}上传完成.')download('MySQL从删库到跑路.avi')upload('Python从入门到住院.pdf')# 取消装饰器download.__wrapped__('MySQL必知必会.pdf')upload = upload.__wrapped__upload('Python从新手到大师.pdf')
装饰器函数本身也可以参数化,简单的说就是通过我们的装饰器也是可以通过调用者传入的参数来定制的,这个知识点我们在后面用到它的时候再为大家讲解。
递归调用
函数自己调用自己称为递归调用。
求阶乘:
def fac(num):if num in (0, 1):return 1return num * fac(num - 1)
上面的代码中,fac函数中又调用了fac函数,这就是所谓的递归调用。代码第2行的if条件叫做递归的收敛条件,简单的说就是什么时候要结束函数的递归调用,在计算阶乘时,如果计算到0或1的阶乘,就停止递归调用,直接返回1;代码第4行的num * fac(num - 1)是递归公式,也就是阶乘的递归定义。下面,我们简单的分析下,如果用fac(5)计算5的阶乘,整个过程会是怎样的。
# 递归调用函数入栈# 5 * fac(4)# 5 * (4 * fac(3))# 5 * (4 * (3 * fac(2)))# 5 * (4 * (3 * (2 * fac(1))))# 停止递归函数出栈# 5 * (4 * (3 * (2 * 1)))# 5 * (4 * (3 * 2))# 5 * (4 * 6)# 5 * 24# 120print(fac(5)) # 120
注意,函数调用会通过内存中称为“栈”(stack)的数据结构来保存当前代码的执行现场,函数调用结束后会通过这个栈结构恢复之前的执行现场。每进入一个函数调用,栈就会增加一层栈帧(stack frame),栈帧就是我们刚才提到的保存当前代码执行现场的结构;每当函数调用结束后,栈就会减少一层栈帧。
通常,内存中的栈空间很小,因此递归调用的次数如果太多,会导致栈溢出(stack overflow),所以递归调用一定要确保能够快速收敛。我们可以尝试执行fac(5000),看看是不是会提示RecursionError错误,错误消息为:maximum recursion depth exceeded in comparison(超出最大递归深度),其实就是发生了栈溢出。
我们使用的Python官方解释器,默认将函数调用的栈结构最大深度设置为1000层。如果超出这个深度,就会发生上面说的RecursionError。当然,我们可以使用sys模块的setrecursionlimit函数来改变递归调用的最大深度,例如:sys.setrecursionlimit(10000),这样就可以让上面的fac(5000)顺利执行出结果,但是我们不建议这样做,因为让递归快速收敛才是我们应该做的事情,否则就应该考虑使用循环递推而不是递归。
生成斐波那契数列:斐波那契数列前两个数都是1,从第3个数开始,每个数是前两个数相加的和,可以记为f(n) = f(n - 1) + f(n - 2)
def fib(n):if n in (1, 2):return 1return fib(n - 1) + fib(n - 2)# 打印前20个斐波那契数for i in range(1, 21):print(fib(i))
需要提醒大家,上面计算斐波那契数的代码虽然看起来非常简单明了,但执行性能是比较糟糕的,原因大家可以自己思考一下,更好的做法还是之前讲过的使用循环递推的方式,代码如下所示。
def fib(n):a, b = 0, 1for _ in range(n):a, b = b, a + breturn a
面向对象
在面向对象编程的世界里,程序中的数据和操作数据的函数是一个逻辑上的整体,我们称之为对象,对象可以接收消息,解决问题的方法就是创建对象并向对象发出各种各样的消息;通过消息传递,程序中的多个对象可以协同工作,这样就能构造出复杂的系统并解决现实中的问题。
面向对象编程:把一组数据和处理数据的方法组成对象,把行为相同的对象归纳为类,通过封装隐藏对象的内部细节,通过继承实现类的特化和泛化,通过多态实现基于对象类型的动态分派。
几个关键词:对象(object)、类(class)、封装(encapsulation)、继承(inheritance)、多态(polymorphism)。
类和对象
- 类是一个抽象的概念,对象是一个具体的概念。
- 我们把同一类对象的共同特征抽取出来就是一个类,比说人类是一个抽象概念,而每个人就是一个对象。
- 简而言之,类是对象的蓝图和模板,对象是类的实例,是可以接受消息的实体。
- 在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定属于某个类。
- 对象的属性是对象的静态特征,对象的行为是对象的动态特征。
- 如果我们把拥有共同特征的对象的属性和行为都抽取出来,就可以定义出一个类。
定义类
- 在类的代码块中,我们需要写一些函数,我们说过类是一个抽象概念,那么这些函数就是我们对一类对象共同的动态特征的提取。
- 写在类里面的函数我们通常称之为方法,方法就是对象的行为,也就是对象可以接收的消息。
- 方法的第一个参数通常都是
self,它代表了接收这个消息的对象本身。
class Student:def study(self, course_name):print(f'学生正在学习{course_name}.')def play(self):print(f'学生正在玩游戏.')
创建和使用对象
在我们定义好一个类之后,可以使用构造器语法来创建对象。在类的名字后跟上圆括号就是所谓的构造器语法,代码如下所示。
stu1 = Student()stu2 = Student()print(stu1) # <__main__.Student object at 0x10ad5ac50>print(stu2) # <__main__.Student object at 0x10ad5acd0>print(hex(id(stu1)), hex(id(stu2))) # 0x10ad5ac50 0x10ad5acd0
上面的代码创建了两个学生对象,当我们用print函数打印stu1和stu2两个变量时,我们会看到输出了对象在内存中的地址(十六进制形式),跟我们用id函数查看对象标识获得的值是相同的。
现在我们可以告诉大家,我们定义的变量其实保存的是一个对象在内存中的逻辑地址(位置),通过这个逻辑地址,我们就可以在内存中找到这个对象。所以stu3 = stu2这样的赋值语句并没有创建新的对象,只是用一个新的变量保存了已有对象的地址。
接下来,我们尝试给对象发消息。Python中,给对象发消息有两种方式,请看下面的代码。
# 通过“类.方法”调用方法,第一个参数是接收消息的对象,第二个参数是学习的课程名称Student.study(stu1, 'Python程序设计') # 学生正在学习Python程序设计.# 通过“对象.方法”调用方法,点前面的对象就是接收消息的对象,只需要传入第二个参数stu1.study('Python程序设计') # 学生正在学习Python程序设计.Student.play(stu2) # 学生正在玩游戏.stu2.play() # 学生正在玩游戏.
初始化方法
刚才我们创建的学生对象只有行为没有属性,如果要给学生对象定义属性,可以添加一个名为__init__的方法。在我们调用Student类的构造器创建对象时,首先会在内存中获得保存学生对象所需的内存空间,然后通过自动执行__init__方法,完成对内存的初始化操作,也就是把数据放到内存空间中。
我们对上面的Student类稍作修改,给学生对象添加name(姓名)和age(年龄)两个属性。
class Student:def __init__(self, name, age):、self.name = nameself.age = agedef study(self, course_name):print(f'{self.name}正在学习{course_name}.')def play(self):print(f'{self.name}正在玩游戏.')# 初始化方法除了self之外还有两个参数,所以调用Student类的构造器创建对象时要传入这两个参数stu1 = Student('骆昊', 40)stu2 = Student('王大锤', 15)stu1.study('Python程序设计') # 骆昊正在学习Python程序设计.stu2.play() # 王大锤正在玩游戏.
打印对象
在Python中,以两个下划线__(读作“dunder”)开头和结尾的方法通常都是有特殊用途和意义的方法,我们一般称之为魔术方法或魔法方法。如果我们在打印对象的时候不希望看到对象的地址而是看到我们自定义的信息,可以通过在类中放置__repr__魔术方法来做到,该方法返回的字符串就是用print函数打印对象的时候会显示的内容,代码如下所示。
class Student:def __init__(self, name, age):self.name = nameself.age = agedef study(self, course_name):print(f'{self.name}正在学习{course_name}.')def play(self):print(f'{self.name}正在玩游戏.')def __repr__(self):return f'{self.name}: {self.age}'stu1 = Student('骆昊', 40)print(stu1) # 骆昊: 40students = [stu1, Student('李元芳', 36), Student('王大锤', 25)]print(students) # [骆昊: 40, 李元芳: 36, 王大锤: 25]
封装
面向对象编程有三大支柱:封装、继承和多态。我们先说一下什么是封装。我自己对封装的理解是:隐藏一切可以隐藏的实现细节,只向外界暴露简单的调用接口。我们在类中定义的对象方法其实就是一种封装,这种封装可以让我们在创建对象之后,只需要给对象发送一个消息就可以执行方法中的代码,也就是说我们在只知道方法的名字和参数(方法的外部视图),不知道方法内部实现细节(方法的内部视图)的情况下就完成了对方法的使用。
举一个例子,假如要控制一个机器人帮我倒杯水,如果不使用面向对象编程,不做任何的封装,那么就需要向这个机器人发出一系列的指令,如站起来、向左转、向前走5步、拿起面前的水杯、向后转、向前走10步、弯腰、放下水杯、按下出水按钮、等待10秒、松开出水按钮、拿起水杯、向右转、向前走5步、放下水杯等,才能完成这个简单的操作,想想都觉得麻烦。按照面向对象编程的思想,我们可以将倒水的操作封装到机器人的一个方法中,当需要机器人帮我们倒水的时候,只需要向机器人对象发出倒水的消息就可以了,这样做不是更好吗?
在很多场景下,面向对象编程其实就是一个三步走的问题。第一步定义类,第二步创建对象,第三步给对象发消息。当然,有的时候我们是不需要第一步的,因为我们想用的类可能已经存在了。之前我们说过,Python内置的list、set、dict其实都不是函数而是类,如果要创建列表、集合、字典对象,我们就不用自定义类了。在某些特殊的场景中,我们会用到名为“内置对象”的对象,所谓“内置对象”就是类已经存在而且对象已然创建过了,直接向对象发消息就可以了。
经典案例
案例1:定义一个类描述数字时钟。
import time# 定义数字时钟类class Clock(object):def __init__(self, hour=0, minute=0, second=0):self.hour = hourself.min = minuteself.sec = seconddef run(self):"""走字"""self.sec += 1if self.sec == 60:self.sec = 0self.min += 1if self.min == 60:self.min = 0self.hour += 1if self.hour == 24:self.hour = 0def show(self):"""显示时间"""return f'{self.hour:0>2d}:{self.min:0>2d}:{self.sec:0>2d}'# 创建时钟对象clock = Clock(23, 59, 58)while True:# 给时钟对象发消息读取时间print(clock.show())# 休眠1秒钟time.sleep(1)# 给时钟对象发消息使其走字clock.run()
案例2:定义一个类描述平面上的点,要求提供计算到另一个点距离的方法。
class Point(object):def __init__(self, x=0, y=0):self.x, self.y = x, ydef distance_to(self, other):dx = self.x - other.xdy = self.y - other.yreturn (dx * dx + dy * dy) ** 0.5def __str__(self):return f'({self.x}, {self.y})'p1 = Point(3, 5)p2 = Point(6, 9)print(p1, p2) # (3, 5) (6, 9)print(p1.distance_to(p2)) # 5.0
可见性和属性装饰器
- 在很多面向对象编程语言中,对象的属性通常会被设置为私有(private)或受保护(protected)的成员,简单的说就是不允许直接访问这些属性;对象的方法通常都是公开的(public),因为公开的方法是对象能够接受的消息,也是对象暴露给外界的调用接口,这就是所谓的访问可见性。
- 在Python中,可以通过给对象属性名添加前缀下划线的方式来说明属性的访问可见性。例如,可以用
__name表示一个私有属性,_name表示一个受保护属性,代码如下所示。
class Student:def __init__(self, name, age):self.__name = nameself.__age = agedef study(self, course_name):print(f'{self.__name}正在学习{course_name}.')stu = Student('王大锤', 20)stu.study('Python程序设计')print(stu.__name) # AttributeError: 'Student' object has no attribute '__name'
以__开头的属性__name是私有的,在类的外面无法直接访问。类里面的study方法中可以通过self.__name访问该属性。
需要提醒大家的是,Python并没有从语法上严格保证私有属性的私密性,它只是给私有的属性和方法换了一个名字来阻挠对它们的访问,事实上如果你知道更换名字的规则仍然可以访问到它们,我们可以对上面的代码稍作修改就可以访问到私有的属性。
print(stu._Student__name, stu._Student__age) # 王大锤 20
- Python中可以通过
property装饰器为“私有”属性提供读取和修改的方法。之前我们提到过,装饰器通常会放在类、函数或方法的声明之前,通过一个@符号表示将装饰器应用于类、函数或方法。
class Student:def __init__(self, name, age):self.__name = nameself.__age = age# 属性访问器(getter方法) - 获取__name属性@propertydef name(self):return self.__name# 属性修改器(setter方法) - 修改__name属性@name.setterdef name(self, name):# 如果name参数不为空就赋值给对象的__name属性# 否则将__name属性赋值为'无名氏',有两种写法# self.__name = name if name else '无名氏'self.__name = name or '无名氏'@propertydef age(self):return self.__agestu = Student('王大锤', 20)print(stu.name, stu.age) # 王大锤 20stu.name = ''print(stu.name) # 无名氏# stu.age = 30 # AttributeError: can't set attribute
在实际项目开发中,我们并不经常使用私有属性,属性装饰器的使用也比较少,所以上面的知识点大家简单了解一下就可以了。
动态属性
- 在Python中,我们可以动态为对象添加属性,这是Python作为动态类型语言的一项特权,代码如下所示。
- 需要提醒大家的是,对象的方法其实本质上也是对象的属性,如果给对象发送一个无法接收的消息,引发的异常仍然是
AttributeError。 - 如果不希望在使用对象时动态的为对象添加属性,可以使用Python的
__slots__魔法。对于Student类来说,可以在类中指定__slots__ = ('name', 'age'),这样Student类的对象只能有name和age属性,如果想动态添加其他属性将会引发异常,代码如下所示。
class Student:__slots__ = ('name', 'age') # 加了这行就不能动态添加属性了def __init__(self, name, age):self.name = nameself.age = agestu = Student('王大锤', 20)# AttributeError: 'Student' object has no attribute 'sex'stu.sex = '男'
静态方法和类方法
- 之前我们在类中定义的方法都是对象方法,换句话说这些方法都是对象可以接收的消息。除了对象方法之外,类中还可以有静态方法和类方法,这两类方法是发给类的消息,二者并没有实质性的区别。
- 在面向对象的世界中,一切皆为对象,我们定义的类也是对象,所以类也可以接收消息,对应的方法是类方法或静态方法。
那么,什么样的消息会直接发送给类呢?举一个例子,定义一个三角形类,通过传入三条边的长度来构造三角形,并提供计算周长和面积的方法。计算周长和面积肯定是三角形对象的方法,这一点毫无疑问。但是在创建三角形对象时,传入的三条边长未必能构造出三角形,为此我们可以先写一个方法来验证给定的三条边长是否可以构成三角形,这种方法很显然就不是对象方法,因为在调用这个方法时三角形对象还没有创建出来。我们可以把这类方法设计为静态方法或类方法,也就是说这类方法不是发送给三角形对象的消息,而是发送给三角形类的消息,代码如下所示。
class Triangle(object):def __init__(self, a, b, c):self.a = aself.b = bself.c = c@staticmethoddef is_valid(a, b, c):"""判断三条边长能否构成三角形(静态方法)"""return a + b > c and b + c > a and a + c > b# @classmethod# def is_valid(cls, a, b, c):# """判断三条边长能否构成三角形(类方法)"""# return a + b > c and b + c > a and a + c > bdef perimeter(self):"""计算周长"""return self.a + self.b + self.cdef area(self):"""计算面积"""p = self.perimeter() / 2return (p * (p - self.a) * (p - self.b) * (p - self.c)) ** 0.5
上面的代码使用staticmethod装饰器声明了is_valid方法是Triangle类的静态方法,如果要声明类方法,可以使用classmethod装饰器。可以直接使用类名.方法名的方式来调用静态方法和类方法,二者的区别在于,类方法的第一个参数是类对象本身 cls,而静态方法则没有这个参数。
简单的总结一下,对象方法、类方法、静态方法都可以通过**类名.方法名**的方式来调用,区别在于方法的第一个参数到底是普通对象 self 还是类对象 cls,还是没有接受消息的对象。
静态方法通常也可以直接写成一个独立的函数,因为它并没有跟特定的对象绑定。
继承和多态
- 通过继承,我们可以从已有的类创建新类,实现对已有类代码的复用。
- 提供继承信息的类叫做父类(超类、基类),得到继承信息的类叫做子类(派生类、衍生类)。
- 例如,我们定义一个学生类和一个老师类,我们会发现他们有大量的重复代码,而这些重复代码都是老师和学生作为人的公共属性和行为,所以在这种情况下,我们应该先定义人类,再通过继承,从人类派生出老师类和学生类,代码如下所示。
class Person:def __init__(self, name, age):self.name = nameself.age = agedef eat(self):print(f'{self.name}正在吃饭.')def sleep(self):print(f'{self.name}正在睡觉.')class Student(Person):def __init__(self, name, age):# super(Student, self).__init__(name, age)super().__init__(name, age)def study(self, course_name):print(f'{self.name}正在学习{course_name}.')class Teacher(Person):def __init__(self, name, age, title):# super(Teacher, self).__init__(name, age)super().__init__(name, age)self.title = titledef teach(self, course_name):print(f'{self.name}{self.title}正在讲授{course_name}.')stu1 = Student('白元芳', 21)stu2 = Student('狄仁杰', 22)teacher = Teacher('武则天', 35, '副教授')stu1.eat()stu2.sleep()teacher.teach('Python程序设计')stu1.study('Python程序设计')
- 继承的语法是在定义类的时候,在类名后的圆括号中指定当前类的父类。
- 如果定义一个类的时候没有指定它的父类是谁,那么默认的父类是
object类。object类是Python中的顶级类,这也就意味着所有的类都是它的子类,要么直接继承它,要么间接继承它。 - Python语言允许多重继承,也就是说一个类可以有一个或多个父类,关于多重继承的问题我们在后面会有更为详细的讨论。
- 在子类的初始化方法中,我们可以通过
super().__init__()来调用父类初始化方法,super函数是Python内置函数中专门为获取当前对象的父类对象而设计的。 - 从上面的代码可以看出,子类除了可以通过继承得到父类提供的属性和方法外,还可以定义自己特有的属性和方法,所以子类比父类拥有的更多的能力。在实际开发中,我们经常会用子类对象去替换掉一个父类对象,这是面向对象编程中一个常见的行为,也叫做“里氏替换原则”(Liskov Substitution Principle)。
- 子类继承父类的方法后,还可以对方法进行重写(重新实现该方法),不同的子类可以对父类的同一个方法给出不同的实现版本,这样的方法在程序运行时就会表现出多态行为(调用相同的方法,做了不同的事情)。
class在继承父类时,super的作用是什么
在子类里执行父类的初始化逻辑,直接调用父类的init,在类体系复杂的时候,比如多重继承的时候,父类们不一定会按照它们在子类class语句中的声明顺序执行,引发混乱。
super 的原始代码如下:
其中,cls 代表类,inst 代表实例,上面的代码做了两件事:def super(cls, inst):mro = inst.__class__.mro()return mro[mro.index(cls) + 1]
- 获取 inst 的 MRO 列表
- 查找 cls 在当前 MRO 列表中的 index, 并返回它的下一个类,即 mro[index + 1]
当你使用 super(cls, inst) 时,Python 会在 inst 的 MRO 列表上搜索 cls 的下一个类。
举例来说,A和B类继承了Base类,C同时继承A类和B类,那么 C 的实例self.**class**.mro()结果是[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.Base'>, <class 'object'>]
子类继承父类的构造函数,分以下几种情况
- 子类不重写 init,实例化子类时,会自动调用父类定义的 init。
- 如果重写了init 时,实例化子类,就不会调用父类已经定义的 init。
- 如果重写了init ,又想继承父类的构造方法,有2种方法
- 直接调用父类里的方法
父类名称.__init__(self,参数1,参数2,...),但它会出现以下问题:- 比如在多重继承时,超类(父类)的构造逻辑不一定会按照它们在子类class语句中的声明顺序执行。那么运行结果可能与计划的不同。
- 无法正确处理菱形继承(diamond inheritance)。这种继承指的是子类通过类体系里两条不同路径的类继承了同一个超类。如果采用刚才那种常见的写法来调用超类的init,那么会让超类的初始化逻辑重复执行,从而引发混乱。
- 使用 super 关键字
super(子类名称,self).__init__(参数1,参数2,....)- 为了解决直接调用父类init所产生的问题,Python内置了super函数并且规定了标准的方法解析顺序(method resolution order,MRO)。MRO列表代表了类继承的顺序,我们可以使用下面的方式获得某个类的 MRO 列表:
print(子类名称.mro()) - super能够确保菱形继承体系中的共同超类只初始化一次(其他案例参见第48条)。MRO可以确定超类之间的初始化顺序,它遵循C3线性化(C3 linearization)算法。
- 通过super()调用init,与在子类内通过类名直接调用init相比,可使代码更容易维护,修改父类的类名,无序调整super这一部分的代码。
- 为了解决直接调用父类init所产生的问题,Python内置了super函数并且规定了标准的方法解析顺序(method resolution order,MRO)。MRO列表代表了类继承的顺序,我们可以使用下面的方式获得某个类的 MRO 列表:
- 直接调用父类里的方法
面向对象编程经典案例
面向对象编程对初学者来说不难理解但很难应用,虽然我们为大家总结过面向对象的三步走方法(定义类、创建对象、给对象发消息),但是说起来容易做起来难。大量的编程练习和阅读优质的代码可能是这个阶段最能够帮助到大家的两件事情。接下来我们还是通过经典的案例来剖析面向对象编程的知识,同时也通过这些案例为大家讲解如何运用之前学过的Python知识。
案例1:扑克游戏。
说明:简单起见,我们的扑克只有52张牌(没有大小王),游戏需要将52张牌发到4个玩家的手上,每个玩家手上有13张牌,按照黑桃、红心、草花、方块的顺序和点数从小到大排列,暂时不实现其他的功能。
- 首先需要从问题的需求中找到对象并抽象出对应的类,此外还要找到对象的属性和行为。我们可以从需求的描述中找出名词和动词,名词通常就是对象或者是对象的属性,而动词通常是对象的行为。
- 扑克游戏中至少应该有三类对象,分别是牌、扑克和玩家,牌、扑克、玩家三个类也并不是孤立的。
- 类和类之间的关系可以粗略的分为is-a关系(继承)、has-a关系(关联)和use-a关系(依赖)。很显然扑克和牌是has-a关系,因为一副扑克有(has-a)52张牌;玩家和牌之间不仅有关联关系还有依赖关系,因为玩家手上有(has-a)牌而且玩家使用了(use-a)牌。
牌的属性显而易见,有花色和点数。我们可以用0到3的四个数字来代表四种不同的花色,但是这样的代码可读性会非常糟糕,因为我们并不知道黑桃、红心、草花、方块跟0到3的数字的对应关系。如果一个变量的取值只有有限多个选项,我们可以使用枚举。与C、Java等语言不同的是,Python中没有声明枚举类型的关键字,但是可以通过继承enum模块的Enum类来创建枚举类型,代码如下所示。
from enum import Enumclass Suite(Enum):"""花色(枚举)"""SPADE, HEART, CLUB, DIAMOND = range(4)for suite in Suite:print(f'{suite}: {suite.value}')
- 通过上面的代码可以看出,定义枚举类型其实就是定义符号常量,如
SPADE、HEART等。每个符号常量都有与之对应的值,这样表示黑桃就可以不用数字0,而是用Suite.SPADE;同理,表示方块可以不用数字3, 而是用Suite.DIAMOND。 - 注意,使用符号常量肯定是优于使用字面常量的,因为能够读懂英文就能理解符号常量的含义,代码的可读性会提升很多。
- Python中的枚举类型是可迭代类型,简单的说就是可以将枚举类型放到
for-in循环中,依次取出每一个符号常量及其对应的值。
接下来我们可以定义牌类。
class Card:def __init__(self, suite, face):self.suite = suiteself.face = facedef __repr__(self):suites = '♠♥♣♦'faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']# 根据牌的花色和点数取到对应的字符return f'{suites[self.suite.value]}{faces[self.face]}'card1 = Card(Suite.SPADE, 5)card2 = Card(Suite.HEART, 13)print(card1, card2) # ♠5 ♥K
接下来我们定义扑克类。
import randomclass Poker:"""扑克"""def __init__(self):# 通过列表的生成式语法创建一个装52张牌的列表self.cards = [Card(suite, face) for suite in Suitefor face in range(1, 14)]# current属性表示发牌的位置self.current = 0def shuffle(self):"""洗牌"""self.current = 0# 通过random模块的shuffle函数实现列表的随机乱序random.shuffle(self.cards)def deal(self):"""发牌"""card = self.cards[self.current]self.current += 1return card@propertydef has_next(self):"""还有没有牌可以发"""return self.current < len(self.cards)poker = Poker()poker.shuffle()print(poker.cards)
定义玩家类。
class Player:"""玩家"""def __init__(self, name):self.name = nameself.cards = []def get_one(self, card):"""摸牌"""self.cards.append(card)def arrange(self):self.cards.sort()
创建四个玩家并将牌发到玩家的手上。
poker = Poker()poker.shuffle()players = [Player('东邪'), Player('西毒'), Player('南帝'), Player('北丐')]for _ in range(13):for player in players:player.get_one(poker.deal())for player in players:player.arrange() # TypeError: '<' not supported between instances of 'Card' and 'Card'print(f'{player.name}: ', end='')print(player.cards)
执行上面的代码会在player.arrange()那里出现异常,因为Player的arrange方法使用了列表的sort对玩家手上的牌进行排序,排序需要比较两个Card对象的大小,而<运算符又不能直接作用于Card类型,所以就出现了TypeError异常,异常消息为:'<' not supported between instances of 'Card' and 'Card'。
为了解决这个问题,我们可以对Card类的代码稍作修改,使得两个Card对象可以直接用<进行大小的比较。这里用到技术叫运算符重载,Python中要实现对<运算符的重载,需要在类中添加一个名为__lt__的魔术方法。很显然,魔术方法__lt__中的lt是英文单词“less than”的缩写,以此类推,魔术方法__gt__对应>运算符,魔术方法__le__对应<=运算符,__ge__对应>=运算符,__eq__对应==运算符,__ne__对应!=运算符。
修改后的Card类代码如下所示。
class Card: """牌"""def __init__(self, suite, face):self.suite = suiteself.face = facedef __repr__(self):suites = '♠♥♣♦'faces = ['', 'A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K'] # 根据牌的花色和点数取到对应的字符return f'{suites[self.suite.value]}{faces[self.face]}'def __lt__(self, other):# 花色相同比较点数的大小if self.suite == other.suite:return self.face < other.face# 花色不同比较花色对应的值return self.suite.value < other.suite.value
说明: 大家可以尝试在上面代码的基础上写一个简单的扑克游戏,如21点游戏(Black Jack),游戏的规则可以自己在网上找一找。
案例2:工资结算系统。
要求:某公司有三种类型的员工,分别是部门经理、程序员和销售员。需要设计一个工资结算系统,根据提供的员工信息来计算员工的月薪。其中,部门经理的月薪是固定15000元;程序员按工作时间(以小时为单位)支付月薪,每小时200元;销售员的月薪由1800元底薪加上销售额5%的提成两部分构成。
通过对上述需求的分析,可以看出部门经理、程序员、销售员都是员工,有相同的属性和行为,那么我们可以先设计一个名为Employee的父类,再通过继承的方式从这个父类派生出部门经理、程序员和销售员三个子类。很显然,后续的代码不会创建Employee 类的对象,因为我们需要的是具体的员工对象,所以这个类可以设计成专门用于继承的抽象类。Python中没有定义抽象类的关键字,但是可以通过abc模块中名为ABCMeta 的元类来定义抽象类。关于元类的知识,后面的课程中会有专门的讲解,这里不用太纠结这个概念,记住用法即可。
from abc import ABCMeta, abstractmethodclass Employee(metaclass=ABCMeta): """员工"""def __init__(self, name):self.name = name@abstractmethoddef get_salary(self): """结算月薪"""pass
在上面的员工类中,有一个名为get_salary的方法用于结算月薪,但是由于还没有确定是哪一类员工,所以结算月薪虽然是员工的公共行为但这里却没有办法实现。对于暂时无法实现的方法,我们可以使用abstractmethod装饰器将其声明为抽象方法,所谓抽象方法就是只有声明没有实现的方法,声明这个方法是为了让子类去重写这个方法。接下来的代码展示了如何从员工类派生出部门经理、程序员、销售员这三个子类以及子类如何重写父类的抽象方法。
class Manager(Employee): """部门经理"""def get_salary(self):return 15000.0class Programmer(Employee): """程序员"""def __init__(self, name, working_hour=0):super().__init__(name)self.working_hour = working_hourdef get_salary(self):return 200 * self.working_hourclass Salesman(Employee): """销售员"""def __init__(self, name, sales=0):super().__init__(name)self.sales = salesdef get_salary(self):return 1800 + self.sales * 0.05
上面的Manager、Programmer、Salesman三个类都继承自Employee,三个类都分别重写了get_salary方法。重写就是子类对父类已有的方法重新做出实现。相信大家已经注意到了,三个子类中的get_salary各不相同,所以这个方法在程序运行时会产生多态行为,多态简单的说就是调用相同的方法,不同的子类对象做不同的事情。
我们通过下面的代码来完成这个工资结算系统,由于程序员和销售员需要分别录入本月的工作时间和销售额,所以在下面的代码中我们使用了Python内置的isinstance函数来判断员工对象的类型。我们之前讲过的type函数也能识别对象的类型,但是isinstance函数更加强大,因为它可以判断出一个对象是不是某个继承结构下的子类型,你可以简答的理解为type函数是对对象类型的精准匹配,而isinstance函数是对对象类型的模糊匹配。
emps = [Manager('刘备'), Programmer('诸葛亮'), Manager('曹操'), Programmer('荀彧'), Salesman('吕布'), Programmer('张辽'),]for emp in emps:if isinstance(emp, Programmer):emp.working_hour = int(input(f'请输入{emp.name}本月工作时间: '))elif isinstance(emp, Salesman):emp.sales = float(input(f'请输入{emp.name}本月销售额: '))print(f'{emp.name}本月工资为: ¥{emp.get_salary():.2f}元')
经典计算题
计算两个正整数最大公约数和最小公倍数的函数
def gcd_and_lcm(x: int, y: int) -> int:"""求最大公约数和最小公倍数"""a, b = x, ywhile b % a != 0:a, b = b % a, a # 辗转相除法return a, x * y // a
斐波那契数列
说明:斐波那契数列(Fibonacci sequence),通常也被称作黄金分割数列,是意大利数学家莱昂纳多·斐波那契(Leonardoda Fibonacci)在《计算之书》中研究在理想假设条件下兔子成长率问题而引入的数列,因此这个数列也常被戏称为“兔子数列”。斐波那契数列的特点是数列的前两个数都是1,从第三个数开始,每个数都是它前面两个数的和,按照这个规律,斐波那契数列的前10个数是:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55。
a, b = 0, 1for _ in range(20):a, b = b, a + bprint(a)
100以内的素数:
说明:素数指的是只能被1和自身整除的正整数(不包括1)。
for num in range(2, 100):# 假设num是素数is_prime = True# 在2到num-1之间找num的因子for factor in range(2, num):# 如果找到了num的因子,num就不是素数if num % factor == 0:is_prime = Falsebreak# 如果布尔值为True在num是素数if is_prime:print(num)

若有收获,就点个赞吧
0 人点赞
