LeNet-5
LeCun et al., 1998. Gradient-based learning applied to document recognition
训练灰度图片,用于手写数字识别。
- 在这篇论文写成的那个年代,人们更喜欢使用平均池化,而现在我们可能用最大池化更多一些。当时人们并不使用 padding,或者总是使用 valid 卷积,所以每进行一次卷积,图像的高度和宽度都会缩小。
- 这里的网络结构是 Conv1 + avg Pool1 + Cov2 + avg Pool2 + FC3 + FC4 + softmax。
这个神经网络的排列方式至今仍经常用到,即一个或多个卷积层后面跟着一个池化层,然后又是若干个卷积层再接一个池化层,然后是全连接层,最后是输出。
模型特点
每个卷积层包含3个部分:卷积、池化和非线性激活函数。
- 使用卷积提取空间特征。
- 采用降采样(Subsample)的平均池化层(Average Pooling)。
- 使用双曲正切(Tanh)的激活函数。
- 最后用MLP作为分类器。
AlexNet
Krizhevsky et al., 2012. ImageNet classification with deep convolutional neural networks
用于图像分类任务。5个卷积层加上池化层,然后是2个全连接层,最后是 softmax 层。
它和 LeNet 结构十分相似,但参数量大得多。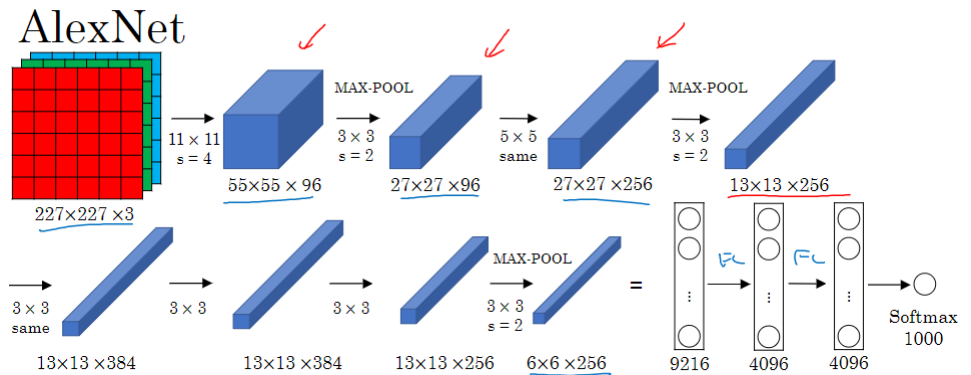
AlexNet 较之前的改进
- AlexNet 比 LeNet 表现更为出色的一个原因是它使用了修正线性单元(Rectified Linear Unit, ReLU)作为激活函数,替换了之前常用的 Sigmoid 函数,缓解了深层网络训练时的梯度消失问题。
- AlexNet 结构还有另一种类型的层,叫作局部响应归一化层(Local Response Normalization,LRN)。它的基本思路是,假如这是网络的一块,比如是13×13×256,LRN要做的就是选取一个位置(比如上图右侧立方体中画的),从这个位置穿过整个通道,能得到256个数字,并进行归一化。但是后来发现LRN起不到太大作用。

- 应用了 Dropout 和数据扩充(data augmentation)技术来提升训练效果。
- 用分组卷积来突破当时GPU的显存瓶颈。
模型特点
- 由5层卷积和3层全连接组成,输入图像为3通道224×224大小,网络规模远大于 LeNet。
- 使用ReLU激活函数。
- 使用Dropout,可以作为正则项防止过拟合,提升模型鲁棒性。
- 具备一些很好的训练技巧,包括数据增广、学习率策略、Weight Decay等。
VGG-16
Simonvan & Zisserman 2015. Very deep convolutional networks for large-scale image recognition
VGG-16 网络没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。它全部用3×3、步幅为1的过滤器构建卷积层,用2×2、步幅为2的过滤器构建最大池化层。因此VGG网络的一大优点是它确实简化了神经网络结构。×2代表有2个相同的层。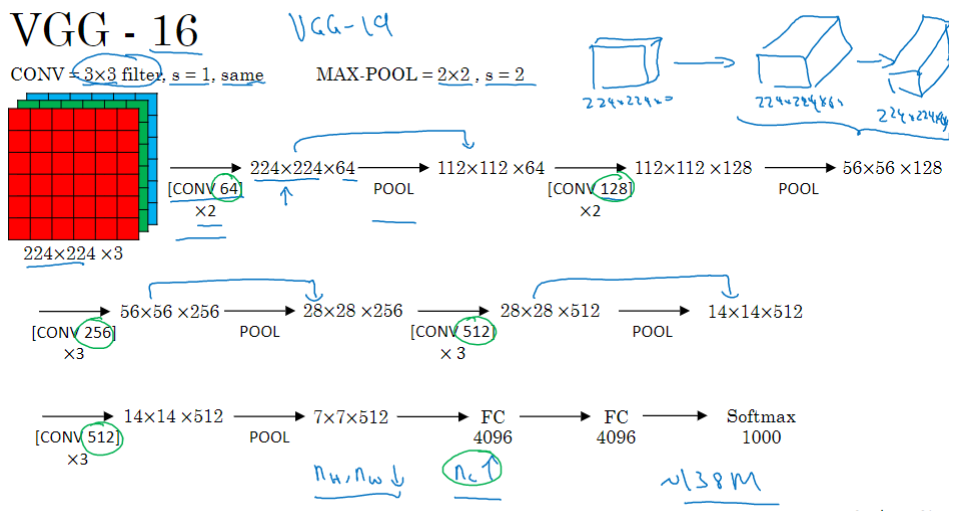
这是VGGNet结构设计简单。图像的高度和宽度每次池化后刚好缩小一半,而通道数量在每组卷积操作后增加一倍。每一步都进行翻倍,正是设计此种网络结构的另一个简单原则。
VGGNet 较之前的改进
相比于AlexNet,VGGNet做了如下改变。
- 用多个3×3小卷积核代替之前的5×5、7×7等大卷积核,这样可以在更少的参数量、更小的计算量下,获得同样的感受野以及更大的网络深度。
- 用2×2池化核代替之前的3×3池化核。
- 去掉了局部响应归一化模块。
整体来说,VGGNet 整个网络采用同一种卷积核尺寸(3×3)和池化核尺寸(2×2),并重复堆叠了很多基础模块,最终的网络深度达到16层。
模型特点
- 更深的网络结构:网络层数由AlexNet的8层增至16和19层,更深的网络意味着更强大的网络能力,也意味着需要更强大的计算力,不过后来硬件发展也很快,显卡运算力也在快速增长,以此助推深度学习的快速发展。
- 使用较小的3×3的卷积核:模型中使用3×3的卷积核,因为两个3×3的感受野相当于一个5×5,同时参数量更少,之后的网络都基本遵循这个范式。
Inception(GoogleNet)
Szegedy et al. 2014. Going deeper with convolutions
1×1卷积
Lin et al. 2013. Network in network
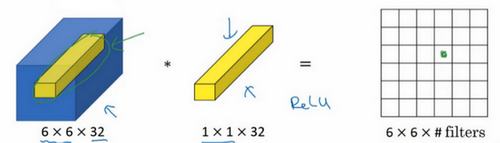
以输入层的某个单元切片为例,一个神经元的输入是32个数字(输入图片中左侧位置32个通道中的数字),乘以32个权重(过滤器中的32个数),然后应用ReLU非线性函数,在这里输出相应的结果。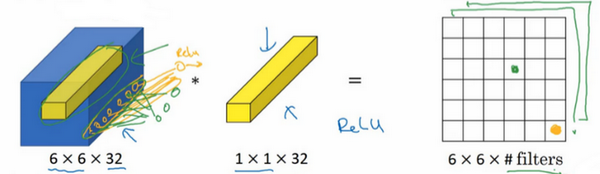
如果过滤器不止一个,而是多个,那么输出结果是6×6×n,n是过滤器数量。
1×1卷积的应用是增加或降低通道数。你可以使用池化层压缩特征图的高度和宽度,而通道数则可以通过使用 个过滤器将其改变为
个过滤器将其改变为 。
。
比如一个28×28×192的输入层,你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了32个过滤器,输出层为28×28×32,这就是压缩通道数的方法。
Inception 模块
构建卷积层时,你要决定过滤器的大小究竟是1×1,3×3还是5×5,或者要不要添加池化层。谷歌 Inception 网络的作用就是代替人工来确定卷积层中的过滤器类型,或者确定是否需要创建卷积层或池化层。虽然网络架构因此变得更加复杂,但网络表现却非常好。
举个例子,输入层的维度是28×28×192,如果使用1×1卷积,假设使用64个过滤器,则输出为28×28×64;如果再使用3×3的过滤器,输出是28×28×128;再尝试一下5×5的过滤器,输出变成28×28×32;如果是池化层,那么输出是28×28×32。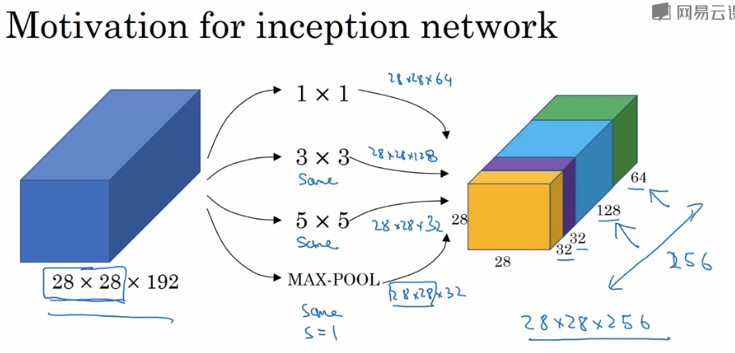
这些过滤器的输出堆叠在一起,32+32+128+64=256,所以这个Inception模块的输入为28×28×192,输出为28×28×256。这就是Inception网络的核心内容,基本思想是你可以给网络添加过滤器、池化等所有可能值,然后把这些输出连接起来。
bottlenet 瓶颈层
不难发现 Inception 层有一个问题,就是计算成本,我们来看看该模块中5×5过滤器的计算成本。
一个 28×28×192 的输入块,执行一个 5×5 卷积,它有32个过滤器,输出为28×28×32。可以看到输出有28×28×32个数字,对于输出的每个数字来说,是通过5×5×192次乘法运算后求和得到的,所以乘法运算的总次数为(5×5×192)×(28×28×32)= 1.2亿(120M)。即使在现在,用计算机执行1.2亿次乘法运算,成本也是相当高的。
这里还有另外一种架构,输入输出不变,还是输入28×28×192输出28×28×32。只是中间增加了个1×1的卷积,把输入值从192个通道减少到16个通道,对这个较小层运行5×5卷积,得到最终输出。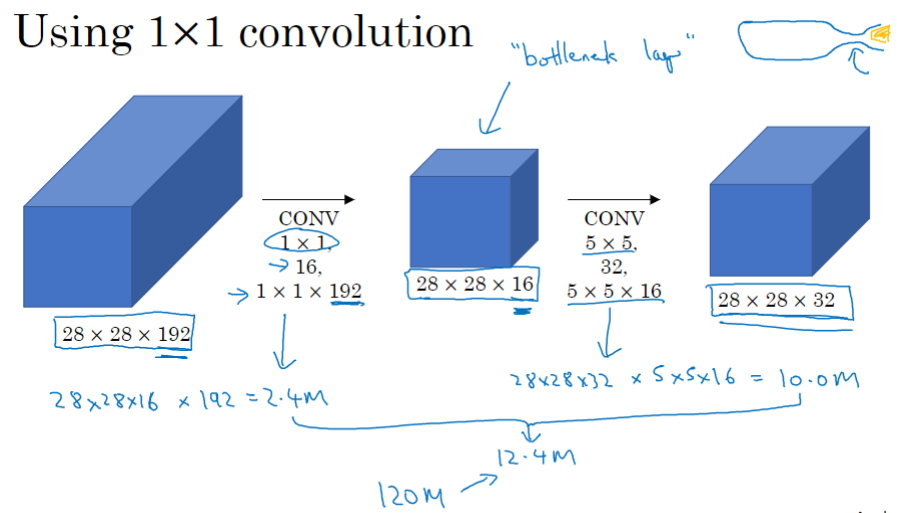
中间这层有时被称为瓶颈层,先缩小网络表示,然后再扩大它。我们看看它的计算成本,应用1×1卷积,过滤器个数为16,每个过滤器大小为1×1×192,输入通道数与过滤器通道数相匹配,28×28×16这个层的计算成本是28×28×192×16=240万,第二个卷积层的计算成本为1000万,所以所需要乘法运算的总次数是这两层的计算成本之和,1204万,与直接执行5×5的卷积做比较,计算成本从1.2亿下降到了原来的十分之一。
事实证明,只要合理构建瓶颈层,你既可以显著缩小表示层规模,又不会降低网络性能,从而节省了计算。
构建 Inception 网络 / GoogleLeNet
上节我们处理的例子是,为了在5×5的卷积层中节省运算量,我们增加了1×1×16的中间层。同样,在3×3的卷积层之前,我们也可以做相同的操作来减少运算量。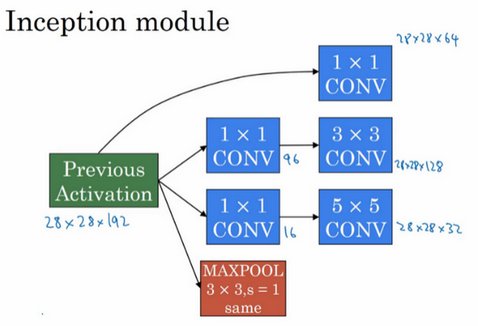
为了能在最后将这些输出都连接起来,我们会使用 same 类型的 padding 来池化,使得输出的高和宽依然是28×28,这样才能将它与其他输出连接起来。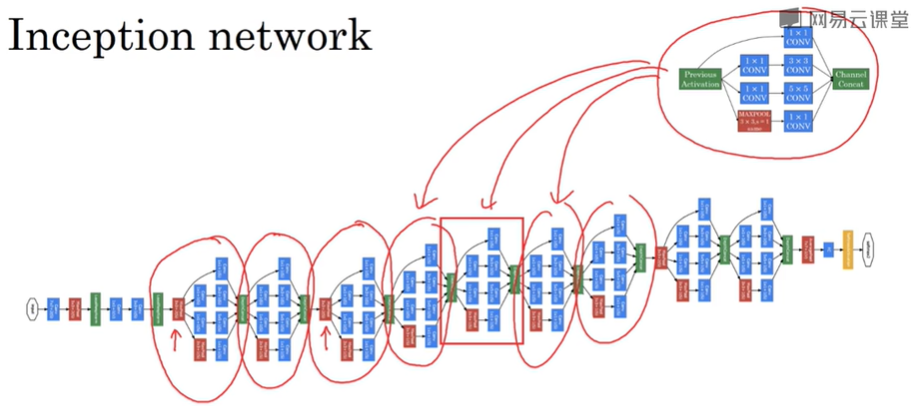
这是一张取自 Szegety et al 的论文中关于 Inception 网络的图片,可能整张图看上去很复杂,但其实是许多重复的 Inception 模块。图中红色箭头是一些额外的池化层来修改宽和高的维度。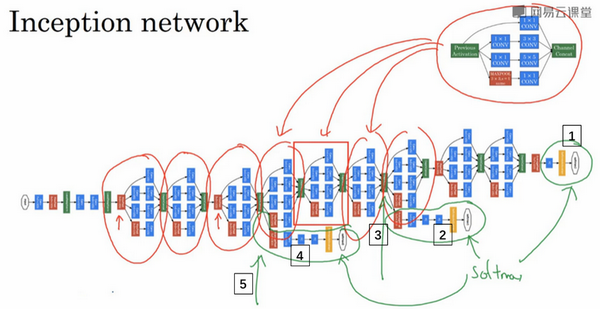
这里其实还有一些分支,它们通过隐藏层(编号3)来做出预测,所以这其实是是输出(编号1和2)。编号4也包含了一个隐藏层,通过一些全连接层,然后有一个softmax来预测,输出结果的标签。
你应该把它看做Inception网络的一个细节,它确保了即便是隐藏单元和中间层(编号5)也参与了特征计算,它们也能预测图片的分类。它在Inception网络中,起到一种调整的效果,并且能防止网络发生过拟合。
Inception 的创新点
- 提出 Inception 模块,将大通道卷积层替换为小通道卷积层组成的多分支结构。数学依据是,一个大型稀疏矩阵通常可以分解为多个小的稠密矩阵,也就是说,可以用多个小的稠密矩阵来近似一个大型稀疏矩阵。实际上,Inception模块会同时使用1×1、3×3、5×5的3种卷积核进行多路特征提取,这样能使网络稀疏化的同时,增强网络对多尺度特征的适应性。
- 提出了瓶颈(bottleneck)结构,即在计算比较大的卷积层之前,先使用1x1卷积对其通道进行压缩以减少计算量(在较大卷积层完成计算之后,根据需要有时候会再次使用1×1卷积将其通道数复原),如图1.11(b)所示。
- 从网络中间层拉出多条支线,连接辅助分类器,用于计算损失并进行误差反向传播,以缓解梯度消失问题。
- 修改了之前VGGNet等网络在网络末端加入多个全连接层进行分类的做法,转而将第一个全连接层换成全局平均池化层(GlobalAverage Pooling)。
模型特点
- 引入Inception结构,这是一种网中网(Network In Network)的结构。
通过网络的水平排布,可以用较浅的网络得到较好的模型能力,并进行多特征融合,同时更容易训练。另外,为了减少计算量,使用了1×1卷积来先对特征通道进行降维。堆叠Inception模块就叫作Inception网络,而GoogLeNet就是一个精心设计的性能良好的Inception网络(Inception v1)的实例,即GoogLeNet是Inception v1网络的一种。
- 采用全局平均池化层。
将后面的全连接层全部替换为简单的全局平均池化,在最后参数会变得更少。而在 AlexNet 中最后3层的全连接层参数差不多占总参数的90%,使用大网络在宽度和深度上允许 GoogleNet 移除全连接层,但并不会影响到结果的精度,在ImageNet中实现93.3%的精度,而且要比 VGG 还快。不过,网络太深无法很好训练的问题还是没有得到解决,直到 ResNet 提出了 Residual Connection。
ResNets
He et al., 2015. Deep residual networks for image recognition
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。这节课我们学习跳跃连接(Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。
ResNets 是由残差块(Residual block)构建的,首先解释一下什么是残差块。
Residual block
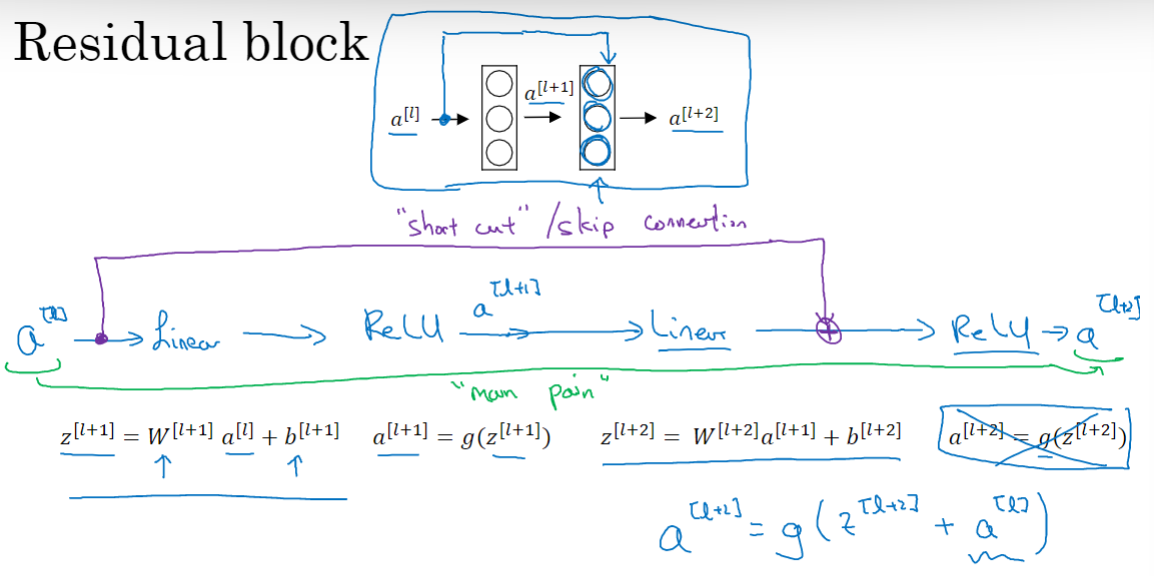
在残差网络中,我们将 直接向后,拷贝到神经网络的深层,插入在线性激活之后,ReLU非线性激活函数之前。
直接向后,拷贝到神经网络的深层,插入在线性激活之后,ReLU非线性激活函数之前。 的信息直接到达神经网络的深层,不再沿着主路径传递计算,这就意味着最后这个等式
的信息直接到达神经网络的深层,不再沿着主路径传递计算,这就意味着最后这个等式 变成了
变成了 。
。
使用残差块能够训练更深的神经网络。如果没有残差,没有跳跃连接,凭经验你会发现随着网络深度的加深,训练错误会先减少,然后增多。而理论上,随着网络深度的加深,应该训练得越来越好才对。
Residual Network
构建 ResNet 网络,就是将很多残差块堆积在一起,形成一个很深神经网络。
在一个普通网络结构上,每两层增加一个捷径,构成一个残差块。如图所示,5个残差块连接在一起构成一个残差网络。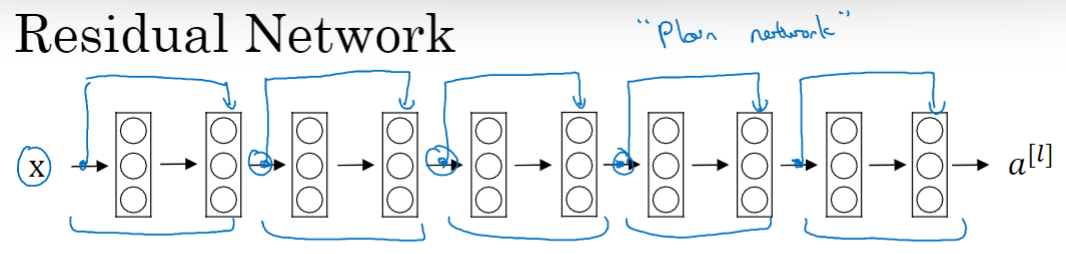
也许从另外一个角度来看,随着网络越来深,网络连接会变得臃肿,但是ResNet确实在训练深度网络方面非常有效。
关于残差网络另一个值得探讨的细节是, 与
与 具有相同维度,之所以能实现跳跃连接是因为使用了same卷积保留维度,所以很容易得出这个捷径连接,并输出这两个相同维度的向量。
具有相同维度,之所以能实现跳跃连接是因为使用了same卷积保留维度,所以很容易得出这个捷径连接,并输出这两个相同维度的向量。
模型特点
- 层数非常深,已经超过百层。
- 引入残差单元来解决退化问题。
ResNet 做图片识别
He et al. 2015. Deep residual networks for image recognition.
下图是从何凯明等人论文中截取的,这是一个普通网络,我们给它输入一张图片,它有多个卷积层,最后输出了一个Softmax。如何把它转化为ResNets呢?只需要添加跳跃连接。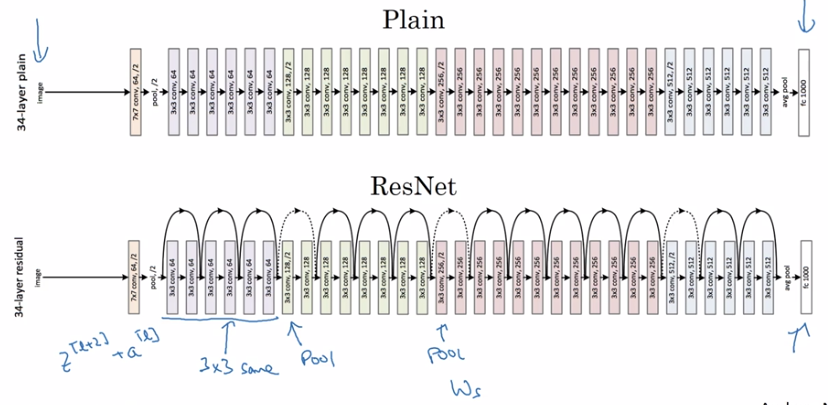
这里我们只讨论几个细节,这个网络有很多层3×3卷积,而且它们大多都是same卷积,这就是添加 等维 特征向量的原因。所以这些都是卷积层,而不是全连接层,因为它们是same卷积,维度得以保留,这也解释了 能够相加。
ResNets 类似于其它很多网络,有很多卷积层,其中偶尔会有池化层或类池化层的层,不论这些池化层是什么类型,你只需要调整矩阵的维度。
普通网络和 ResNets 网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过 softmax 进行预测的全连接层。
跳跃连接的优点
- 能缩短误差反向传播到各层的路径,有效抑制梯度消失的现象,从而使网络在不断加深时性能不会下降。
- 由于有“近道”的存在,若网络在层数加深时性能退化,则它可以通过控制网络中“近道”和“非近道”的组合比例来退回到之前浅层时的状态,即“近道”具备自我关闭能力。

若有收获,就点个赞吧
0 人点赞
