训练神经网络时,我们需要做出很多决策,例如:
- 神经网络分多少层
- 每层含有多少个隐藏单元
- 学习速率是多少
- 各层采用哪些激活函数
- …
数据集划分
- 验证集的目的就是验证不同的算法,检验哪种算法更有效。
- 测试集的主要目的是正确评估分类器的性能。
- 验证集和测试集要来自同一分布。(比如不能训练数据是精修图片而测试、验证数据是随手拍图片)
- 没有测试集也可以。测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。
- 搭建训练验证集和测试集能够加速神经网络的集成,也可以更有效地衡量算法地偏差和方差,从而帮助我们更高效地选择合适方法来优化算法。
偏差,方差(Bias /Variance)
- 训练error-偏差,验证error-方差。
- 训练error低,验证error高:高方差(high variance),过拟合(overfitting)。
- 训练error高,验证error和训练error一样:高偏差(high bias),称为“欠拟合”(underfitting。
- 训练高,验证更高:既高偏差又高方差。

- 首先看偏差,偏差大的话可以调整网络、训练更久等。
- 偏差小了之后看方差,方差大可以增加数据、正则化来减小过拟合。

正则化
L2正则化
正则化就是在损失函数中多加一项。对逻辑回归来说,计算公式是:
如果用L1正则化,W最终会是稀疏的,也就是向量中有很多0。人们越来越倾向于选择L2正则。
在神经网络中,L2正则的公式是:
L2正则化也被称为权重衰减,它使W像梯度下降一样地每次都被减小。
正则化可以减小过拟合的原因
直观理解是,如果正则化设置得足够大,权重矩阵W被设置为接近0的值,那么基本消除了许多隐藏单元的影响,深度神经网络被简化成很小的网络,近似一个有深度的逻辑回归单元。
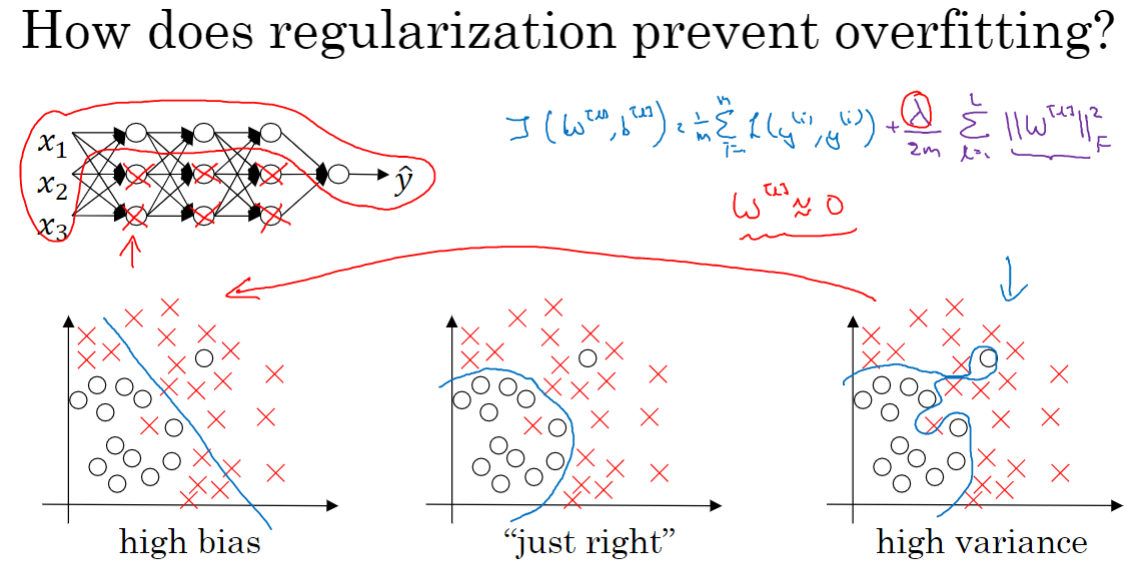
再比如,我们使用 tanh 激活函数。当 z 比较小时,激活函数几乎是线性的,整个神经网络近似计算线性函数,不会拟合成有许多弯弯绕绕的曲线。
dropout正则化
当神经网络过拟合时,dropout正则化做的是,遍历每一层并设置消除节点的概率,得到一个节点更少、规模更小的网络。对每一个样本都这样以抛硬币的方式设置概率。因此我们在每个样本上的训练网络都比原始网络小许多。
- inverted dropput
- 参数 keep-prob: 保留每一层神经元的概率。对于可能产生过拟合和参数比较多的层(W维度较大),就把 keep-pro 设置小一点,这样可以降低过拟合的概率。
- keep-pro = 1 代表在这一层不使用dropput。
- 缺点是代价函数 J 不再被明确定义。Ng通常先关闭dropout,确保代价函数会单调递减,再设置dropout。
- dropout正则 和 L2 正则的效果差不多。
其他正则化
- 数据增强。对于图片,可以图片翻转、旋转并随意放大后裁剪。对于手写识别,可以随意旋转或扭曲数字。
- early stopping。当验证集的误差逐渐下降后在某个节点开始逐渐上升时,说明神经网络在那个节点是效果最好的,在那里就可以停止训练了。缺点是使用了early stopping,也就停止了优化代价函数 J,这时 J 可能还不够小。可以使用L2正则化,但它训练时间更久,搜索大量
值的计算代价较高。early stopping的优点是只运行一次梯度下降,就可以找出W的较小值、中间值和较大值。
正则化输入
normalize,也翻译成归一化。步骤:
- 零均值化。(把数据分布移到以O点为中心)
- 归一化方差。(使特征x1、x2的方差都等于1)

为什么要归一化输入?
如果不归一化,得到的代价函数可能会非常细长狭窄,运行梯度下降法必须使用一个非常小的学习率,如果初始化在狭长的一端,需要迭代的次数更多。归一化后代价函数平均看起来更对称,那么不论初始化在哪都一样。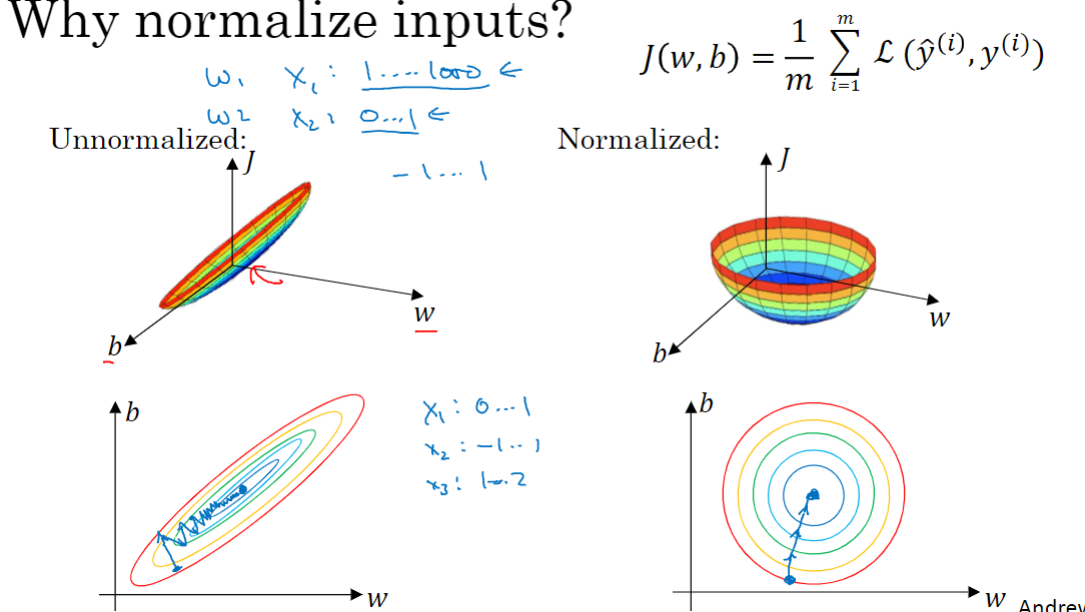
梯度消失和梯度爆炸
梯度爆炸/消失的原因
即在训练过程中导数变得非常小或者非常大,这加大了训练的难度。
为了简单起见,假设我们使用激活函数%3Dz#card=math&code=g%28z%29%3Dz&id=mzide),也就是线性激活函数,我们忽略
,假设
=0,输出
。
假设每个权重矩阵,(除了最后一层,因为从技术上来讲,最后一项有不同维度),那么
%7Dx#card=math&code=y%3D%20W%5E%7B%5B1%5D%7D%5Cbegin%7Bbmatrix%7D%201.5%20%26%200%20%5C%5C%200%20%26%201.5%20%5C%5C%5Cend%7Bbmatrix%7D%5E%7B%28L%20-1%29%7Dx&id=j4e7v),最后的计算结果就是
=
%7Dx#card=math&code=%7B1.5%7D%5E%7B%28L-1%29%7Dx&id=snKyd)。如果深度神经网络的
值较大,那么
的值呈指数级增长,因此对于一个深度神经网络,
的值将爆炸式增长。
相反的,如果权重是0.5,,矩阵
%7Dx#card=math&code=y%3D%20W%5E%7B%5B1%5D%7D%5Cbegin%7Bbmatrix%7D%200.5%20%26%200%20%5C%5C%200%20%26%200.5%20%5C%5C%5Cend%7Bbmatrix%7D%5E%7B%28L%20-%201%29%7Dx&id=H9nOv),激活函数的值将以指数级下降,它是与网络层数数量
相关的函数,在深度网络中,激活函数以指数级递减。
如果激活函数或梯度函数以与相关的指数增长或递减,它们的值将会变得极大或极小,从而导致训练难度上升,尤其是梯度指数小于
时,梯度下降算法的步长会非常非常小,梯度下降算法将花费很长时间来学习。
解决方法:权重初始化
以单个神经元举例。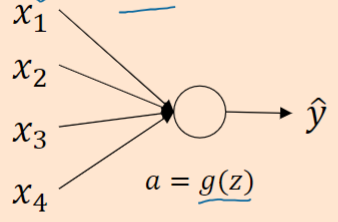
,令
忽略
。为了预防
值过大或过小,你可以看到
越大时希望
越小,因为
是
的和。如果你把很多此类项相加,希望每项值更小,最合理的方法就是设置
,
表示神经元的输入特征数量。如果你是用的是Relu激活函数,而不是
,方差设置为
,效果会更好。你常常发现,初始化时,尤其是使用Relu激活函数时,
%20%3DRelu(z)#card=math&code=g%5E%7B%5Bl%5D%7D%28z%29%20%3DRelu%28z%29&id=w5RTC),它取决于你对随机变量的熟悉程度。
实际上,你要做的就是设置某层权重矩阵*%5Ctext%7Bnp.%7D%5Ctext%7Bsqrt%7D(%5Cfrac%7B2%7D%7Bn%5E%7B%5Bl-1%5D%7D%7D)#card=math&code=w%5E%7B%5Bl%5D%7D%20%3D%20np.random.randn%28%20%5Ctext%7Bshape%7D%29%2A%5Ctext%7Bnp.%7D%5Ctext%7Bsqrt%7D%28%5Cfrac%7B2%7D%7Bn%5E%7B%5Bl-1%5D%7D%7D%29&id=kIEX8),
就是我喂给第
层神经单元的数量(即第
层神经元数量)。这是高斯随机变量,然后乘以它的平方根,也就是引用这个方差
。这里,我用的是
,因为本例中,逻辑回归的特征是不变的。但一般情况下
层上的每个神经元都有
个输入。
如果激活函数的输入特征被零均值和标准方差化,方差是1,也会调整到相似范围,它没解决问题,但确实能降低了梯度消失和爆炸的风险,因为它给权重矩阵
设置了合理值,你也知道,它不能比1大很多,也不能比1小很多,所以梯度没有爆炸或消失过快。

刚刚提到的函数是Relu激活函数,对于几个其它变体函数,如tanh激活函数,常量1比常量2的效率更高。对于tanh函数来说,它是,被称为Xavier初始化。Yoshua Bengio和他的同事还提出另一种方法,是公式
。如果你想用Relu激活函数(最常用的激活函数),我会用这个公式
#card=math&code=%5Ctext%7Bnp.%7D%5Ctext%7Bsqrt%7D%28%5Cfrac%7B2%7D%7Bn%5E%7B%5Bl-1%5D%7D%7D%29&id=m6fZG),如果使用tanh函数,可以用公式
。
实际上,我认为所有这些公式只是给你一个起点,它们给出初始化权重矩阵的方差的默认值。如果你想添加方差,方差参数则是另一个你需要调整的超级参数,可以给公式#card=math&code=%5Ctext%7Bnp.%7D%5Ctext%7Bsqrt%7D%28%5Cfrac%7B2%7D%7Bn%5E%7B%5Bl-1%5D%7D%7D%29&id=xGQy4)添加一个乘数参数,调优作为超级参数激增一份子的乘子参数。虽然调优该参数能起到一定作用,但考虑到相比调优,其它超级参数的重要性
希望你设置的权重矩阵既不会增长过快,也不会太快下降到0,从而训练出一个权重或梯度不会增长或消失过快的深度网络。这也是一个加快训练速度的技巧。
梯度检验 grad check
梯度检验的作用是确保backprop正确实施。
首先计算梯度的数值逼近(Numerical approximation of gradients):计算双边公差而不是单边公差。在梯度检验和反向传播中使用该方法时,最终,它与运行两次单边公差的速度一样,实际上,我认为这种方法还是非常值得使用的,因为它的结果更准确。
假设你的网络中含有下列参数,和
……
和
,为了执行梯度检验,首先要做的就是,把所有参数转换成向量,然后做连接运算,得到一个巨型向量
。代价函数
是所有
和
的函数,现在你得到了一个
的代价函数
(即
#card=math&code=J%28%5Ctheta%29&id=dOFSl))。接着,你得到与
和
顺序相同的数据,你同样可以把
和
……
和
转换成一个新的向量,用它们来初始化大向量
,它与
具有相同维度。
同样的,把转换成矩阵,
已经是一个向量了,直到把
转换成矩阵,这样所有的
都已经是矩阵,注意
与
具有相同维度,
与
具有相同维度。经过相同的转换和连接运算操作之后,你可以把所有导数转换成一个大向量
,它与
具有相同维度。
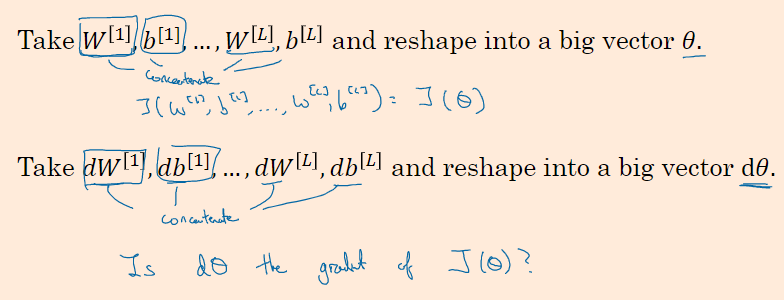
现在的问题是,和代价函数
的梯度或坡度有什么关系?
首先,我们要清楚是超参数
的一个函数,你也可以将J函数展开为
#card=math&code=J%28%5Ctheta%7B1%7D%2C%5Ctheta%7B2%7D%2C%5Ctheta%7B3%7D%2C%5Cldots%5Cldots%29&id=JF2Sg)。实施梯度检验你要做的就是循环执行,从而对每个
也就是对每个
组成元素计算的值。我使用双边误差,也就是
%20-%20J%5Cleft(%20%5Ctheta%7B1%7D%2C%5Ctheta%7B2%7D%2C%5Cldots%5Ctheta%7Bi%7D%20-%20%5Cvarepsilon%2C%5Cldots%20%5Cright)%7D%7B2%5Cvarepsilon%7D#card=math&code=d%5Ctheta%7B%5Ctext%7Bapprox%7D%7D%5Cleft%5Bi%20%5Cright%5D%20%3D%20%5Cfrac%7BJ%5Cleft%28%20%5Ctheta%7B1%7D%2C%5Ctheta%7B2%7D%2C%5Cldots%5Ctheta%7Bi%7D%20%2B%20%5Cvarepsilon%2C%5Cldots%20%5Cright%29%20-%20J%5Cleft%28%20%5Ctheta%7B1%7D%2C%5Ctheta%7B2%7D%2C%5Cldots%5Ctheta%7Bi%7D%20-%20%5Cvarepsilon%2C%5Cldots%20%5Cright%29%7D%7B2%5Cvarepsilon%7D&id=Vt1zk)
只对增加
和减去
,
其它项全都保持不变。从上节课中我们了解到这个值(
)应该逼近
=
,
是代价函数的偏导数。

你需要对 i 的每个值都执行这个运算,最后得到两个向量,得到的逼近值
,它与
具有相同维度,它们两个与
具有相同维度,你要做的就是验证这些向量是否彼此接近。我一般计算这两个向量的距离,
的欧几里得范数,注意这里(
)没有平方,它是误差平方之和,然后求平方根,得到欧式距离,然后用向量长度归一化,使用向量长度的欧几里得范数。分母只是用于预防这些向量太小或太大,分母使得这个方程式变成比率。
如果计算方程式得到的值为
或更小,这就意味着导数逼近很有可能是正确的,它的值非常小。如果它的值在
范围内就要小心了,也许这个值没问题,但我会再次检查这个向量的所有项,确保没有一项误差过大,可能这里有bug。如果结果是
,我就会担心是否存在bug,这时应该仔细检查所有
项,看是否有一个具体的
值,使得
与$ d\theta[i]$大不相同,并用它来追踪一些求导计算是否正确,经过一些调试,最终结果会是这种非常小的值(
)。
梯度检验应用时的注意事项

首先,不要在训练中使用梯度检验,它只用于调试。梯度检验的每一个迭代过程都不执行它,因为它太慢了。
第二点,如果算法的梯度检验失败,要检查所有项。也就是说,如果与dθ[i]的值相差很大,我们要做的就是查找不同的 i 值,看看是哪个导致
与
的值相差这么多。你会发现所有这些项目都来自于
或某层的
,可能帮你定位bug的位置,虽然未必能够帮你准确定位bug的位置,但它可以帮助你估测需要在哪些地方追踪bug。
第三点,在实施梯度检验时,如果使用正则化,请注意正则项。如果代价函数%20%3D%20%5Cfrac%7B1%7D%7Bm%7D%5Csum%7B%7D%5E%7B%7D%7BL(%5Chat%20y%5E%7B(i)%7D%2Cy%5E%7B(i)%7D)%7D%20%2B%20%5Cfrac%7B%5Clambda%7D%7B2m%7D%5Csum%7B%7D%5E%7B%7D%7B%7C%7CW%5E%7B%5Bl%5D%7D%7C%7C%7D%5E%7B2%7D#card=math&code=J%28%5Ctheta%29%20%3D%20%5Cfrac%7B1%7D%7Bm%7D%5Csum%7B%7D%5E%7B%7D%7BL%28%5Chat%20y%5E%7B%28i%29%7D%2Cy%5E%7B%28i%29%7D%29%7D%20%2B%20%5Cfrac%7B%5Clambda%7D%7B2m%7D%5Csum%7B%7D%5E%7B%7D%7B%7C%7CW%5E%7B%5Bl%5D%7D%7C%7C%7D%5E%7B2%7D&id=RfXlZ),这就是代价函数
的定义,
等于与
相关的
函数的梯度,包括这个正则项,记住一定要包括这个正则项。
第四点,梯度检验不能与dropout同时使用。因为每次迭代过程中,dropout会随机消除隐藏层单元的不同子集,难以计算dropout在梯度下降上的代价函数。可以先在没有dropout的情况下,用梯度检验进行双重检查,你的算法至少是正确的,然后打开dropout。
最后一点,也是比较微妙的一点,现实中几乎不会出现这种情况。当和
接近0时,梯度下降的实施是正确的,在随机初始化过程中……,但是在运行梯度下降时,
和
变得更大。可能只有在
和
接近0时,backprop的实施才是正确的。但是当
和
变大时,它会变得越来越不准确。你需要做一件事,我不经常这么做,就是在随机初始化过程中,运行梯度检验,然后再训练网络,
和
会有一段时间远离0,如果随机初始化值比较小,反复训练网络之后,再重新运行梯度检验。

若有收获,就点个赞吧
0 人点赞
