mini-batch GD
在继续课程之前,先确定一下符号:
- 上角小括号
#card=math&code=%28i%29&id=yaSre)表示训练集里的值,所以
%7D#card=math&code=x%5E%7B%28i%29%7D&id=ndXij)是第
个训练样本。
- 上角中括号
来表示神经网络的层数,
表示神经网络中第
层的
值。
- 大括号
来代表不同的mini-batch,
和
表示单个mini-batch 。
假设你的训练样本一共有500万个,每个mini-batch都有1000个样本,那么你有5000个mini-batch。最后得到是 。对Y也要进行相同处理,你相应地拆分Y的训练集。
。对Y也要进行相同处理,你相应地拆分Y的训练集。
- 把训练集分割成小的子集,每次在一个子集上执行梯度下降法、更新参数,而不是同时处理所有的训练数据。
- 一个 epoch 代表完整遍历了全部数据集一次。
理解
使用batch梯度下降法,遍历一次训练集只能做一个梯度下降,而使用mini-batch梯度下降法,遍历一次训练集能做5000个梯度下降。
使用batch梯度下降法时,每次迭代你都需要历遍整个训练集,可以预期每次迭代成本都会下降。如果在某次迭代中增加了,那肯定出了问题,也许你的学习率太大。
使用mini-batch梯度下降法,如果你作出代价函数在整个过程中的图,会发现并不是每次迭代都是下降的。在每次迭代中,你要处理的是和
,也就是每次迭代下你都在训练不同的样本集(mini-batch)。
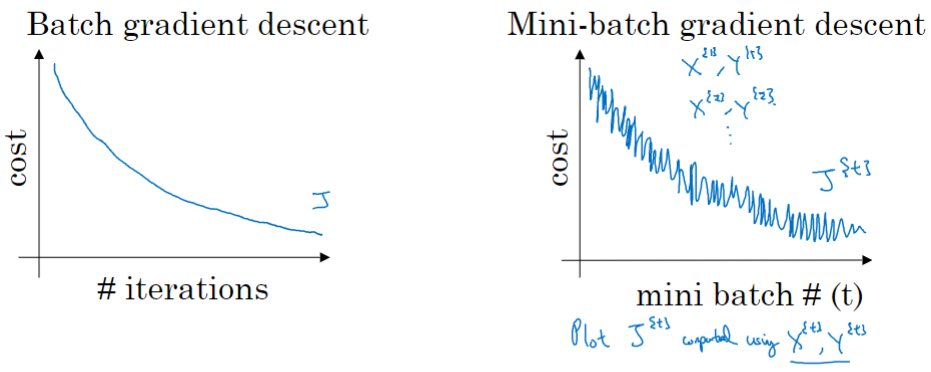
没有每次迭代都下降是不要紧的,但走势应该向下,噪声产生的原因在于也许和
是比较容易计算的mini-batch,因此成本会低一些。不过也许出于偶然,
和
是比较难运算的mini-batch,或许你有一些残缺的样本,这样一来,成本会更高一些,所以才会出现这些摆动。
mini-batch、BGD 和 SGD
你需要决定的变量之一是mini-batch的大小,就是训练集的大小。
- 极端情况下,如果mini-batch的大小等于
,其实就是batch梯度下降法。
- 另一个极端情况,假设mini-batch大小为1,称为随机梯度下降法,每个样本都是独立的mini-batch,一次只处理一个样本。

在两种极端下成本函数的优化情况:
- batch梯度下降法从某处开始,相对噪声低些,幅度也大一些。
- 在随机梯度下降法中,每次迭代只对一个样本进行梯度下降。
- 大部分时候你向着全局最小值靠近,有时候你会远离最小值,因为那个样本恰好给你指的方向不对,因此SGD是有很多噪声的。
- 平均来看,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但它并不会在达到最小值并停留在此。
mini-batch的大小在1和之间。
- 如果训练样本不大,batch梯度下降法可以运行得很好。BGD的主要弊端在于特别是在训练样本数量巨大的时候,单次迭代耗时太长。
- 如果使用SGD随机梯度下降法,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,你会失去所有向量化带给你的加速,因为一次性只处理了一个训练样本,这样效率过于低下。
- 选择不大不小的mini-batch尺寸,实际上学习率达到最快。你会发现两个好处,一方面,你得到了大量向量化,比如mini-batch大小为1000个样本,你就可以对1000个样本向量化。另一方面,你不需要等待整个训练集被处理完就可以开始进行后续工作。它不会总朝向最小值靠近,但它比随机梯度下降要更持续地靠近最小值的方向。它也不一定在很小的范围内收敛或者波动,如果出现这个问题,可以慢慢减少学习率。
mini-batch的大小该如何选择呢?
- 首先,如果训练集较小,直接使用batch梯度下降法,这里的少是说小于2000个样本。
- 样本数目较大的话,一般的mini-batch大小为64到512。因为电脑内存设置和使用的方式,使mini-batch大小是2的
次方,代码会运行地快一些。
- 最后需要注意的是在你的mini-batch中,要确保
和
要符合CPU/GPU内存,取决于你的应用方向以及训练集的大小。
事实上mini-batch大小是另一个重要的变量,你需要做一个快速尝试,才能找到能够最有效地减少成本函数的那个,我一般会尝试几个不同的值,几个不同的2次方,然后看能否找到一个让梯度下降优化算法最高效的大小。
优化算法
指数加权平均数
(Exponentially weighted averages)
我想向你展示几个优化算法,它们比梯度下降法快,要理解这些算法,你需要用到指数加权平均,在统计中也叫做指数加权移动平均,我们首先讲这个,然后再来讲更复杂的优化算法。
方程:%7B%7B%5Ctheta%20%7D%7Bt%7D%7D#card=math&code=%7B%7Bv%7D%7Bt%7D%7D%3D%5Cbeta%20%7B%7Bv%7D%7Bt-1%7D%7D%2B%281-%5Cbeta%20%29%7B%7B%5Ctheta%20%7D%7Bt%7D%7D&id=VWJaX)
以一年的温度数据为例。用数据作图,可以得到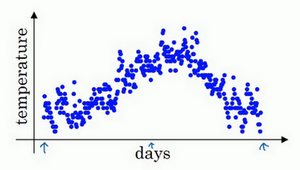
如果要计算趋势,也就是温度的局部平均值(或者说移动平均值),可以用上面那个方程。 是第 t 天的温度。
是第 t 天的温度。
这里我们使用 0.9 为加权数,首先使,对每一天,用0.9的加权数乘以之前的数值、加上当日温度的0.1倍,即
,得到第一天的温度值。第二天,又可以获得一个加权平均数,0.9乘以之前的值加上当日的温度0.1倍,即
,以此类推,得到结果如图中红线。
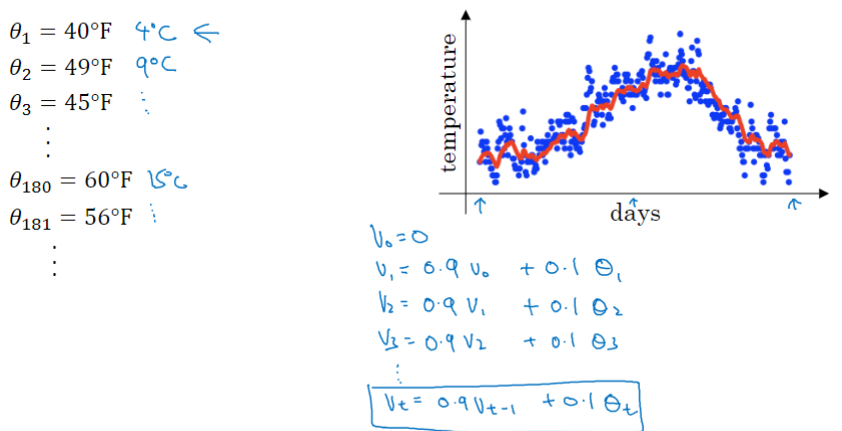
在计算时,可视大概是
%7D#card=math&code=%5Cfrac%7B1%7D%7B%281%20-%5Cbeta%29%7D&id=LjBrk)的每日温度,如果
是0.9,意思这是十天的平均值。将
设置为接近1的一个值,比如0.98,计算
%7D%20%3D50#card=math&code=%5Cfrac%7B1%7D%7B%281%20-%200.98%29%7D%20%3D50&id=wLoGk),这就是粗略平均了过去50天的温度,这时作图可以得到绿线。

这个高值得到的曲线要平坦一些,原因在于你平均了几十天的温度,所以这个曲线波动更小,更加平坦,缺点是曲线进一步右移,因为当
,相当于给前一天的值加了太多权重,只有0.02的权重给了当日的值,所以温度变化时,温度上下起伏更缓慢一些。当
较大时,指数加权平均值适应地更缓慢一些。
我们可以再换一个值试一试,如果是另一个极端值,比如说0.5,根据右边的公式(
%7D%3D2#card=math&code=%5Cfrac%7B1%7D%7B%281-%5Cbeta%29%7D%3D2&id=br6y5)),这是平均了两天的温度。作图得到黄线。由于仅平均了两天的温度,平均的数据太少,所以得到的曲线有更多的噪声,有可能出现异常值,但是这个曲线能够更快适应温度变化。
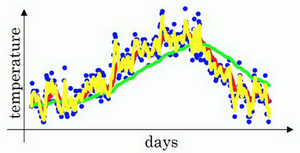
理解
我们分析的组成,也就是在一年第100天计算的数据,
)%20%20%5C%5C%3D%200.1%5Ctheta%7B100%7D%20%2B%200.1%20%5Ctimes%200.9%20%5Ctheta%7B99%7D%20%2B%200.1%20%5Ctimes%20%7B(0.9)%7D%5E%7B2%7D%5Ctheta%7B98%7D%20%2B%200.1%20%5Ctimes%20%7B(0.9)%7D%5E%7B3%7D%5Ctheta%7B97%7D%20%2B%200.1%20%5Ctimes%20%7B(0.9)%7D%5E%7B4%7D%5Ctheta%7B96%7D%20%2B%20%5Cldots%0A#card=math&code=v%7B100%7D%3D%200.1%5Ctheta%7B100%7D%20%2B%200.9v%7B99%7D%3D%200.1%5Ctheta%7B100%7D%20%2B%200.9%280.1%5Ctheta%7B99%7D%20%2B%200.9%280.1%5Ctheta%7B98%7D%20%2B0.9v%7B97%7D%29%29%20%20%5C%5C%3D%200.1%5Ctheta%7B100%7D%20%2B%200.1%20%5Ctimes%200.9%20%5Ctheta%7B99%7D%20%2B%200.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B2%7D%5Ctheta%7B98%7D%20%2B%200.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B3%7D%5Ctheta%7B97%7D%20%2B%200.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B4%7D%5Ctheta_%7B96%7D%20%2B%20%5Cldots%0A&id=N8zsq)
我们构建一个指数衰减函数,从0.1开始,到,到
%7D%5E%7B2%7D#card=math&code=0.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B2%7D&id=OROFa),以此类推,所以就有了这个指数衰减函数。计算
是通过,把两个函数对应的元素,然后求和。所以选取每日温度,将其与指数衰减函数相乘,然后求和,就得到了
。
稍后我们详细讲解,不过所有的这些系数(%7D%5E%7B2%7D0.1%20%5Ctimes%20%7B(0.9)%7D%5E%7B3%7D%5Cldots#card=math&code=0.10.1%20%5Ctimes%200.90.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B2%7D0.1%20%5Ctimes%20%7B%280.9%29%7D%5E%7B3%7D%5Cldots&id=FGF35)),相加起来为1或者逼近1,我们称之为偏差修正,下个视频会涉及。
最后也许你会问,到底需要平均多少天的温度。
实际上%7D%5E%7B10%7D#card=math&code=%7B%280.9%29%7D%5E%7B10%7D&id=VzzaS)大约为0.35,这大约是
,e是自然算法的基础之一。大体上说,如果有
,在这个例子中,
,所以
,
%7D%5E%7B(%5Cfrac%7B1%7D%7B%5Cvarepsilon%7D)%7D#card=math&code=%7B%281-%5Cvarepsilon%29%7D%5E%7B%28%5Cfrac%7B1%7D%7B%5Cvarepsilon%7D%29%7D&id=oD4IJ)约等于
,大约是0.34,0.35,换句话说,10天后,曲线的高度下降到
,相当于在峰值的
。
相反,如果,那么0.98需要多少次方才能达到这么小的数值?%7D%5E%7B50%7D#card=math&code=%7B%280.98%29%7D%5E%7B50%7D&id=AEnc6)大约等于
,所以前50天这个数值比
大,数值会快速衰减,所以本质上这是一个下降幅度很大的函数,你可以看作平均了50天的温度。因为在例子中,要代入等式的左边,
,所以
为50,我们由此得到公式,我们平均了大约
%7D#card=math&code=%5Cfrac%7B1%7D%7B%281-%5Cbeta%29%7D&id=bpJkA)天的温度。
这里代替了
,也就是说根据一些常数,你能大概知道能够平均多少日的温度,不过这只是思考的大致方向,并不是正式的数学证明。
最后讲讲如何在实际中执行。一开始将初始化为0,
,然后每一天,拿到第
天的数据,把
更新为
%5Ctheta%7Bt%7D#card=math&code=v%3A%20%3D%20%5Cbeta%20v%7B%5Ctheta%7D%20%2B%20%281%20-%5Cbeta%29%5Ctheta_%7Bt%7D&id=TUFMN)。
指数加权平均数公式的好处之一在于,它占用极少内存,电脑内存中只占用一行数字而已,然后把最新数据代入公式,不断覆盖就可以了,正因为这个原因,其效率,它基本上只占用一行代码,计算指数加权平均数也只占用单行数字的存储和内存。当然它并不是最好的,也不是最精准的计算平均数的方法。但从计算和内存效率来说,这是一个有效的方法,所以在机器学习中会经常使用,更不用说只要一行代码,这也是一个优势。
偏差修正
在上一个视频中,这个(红色)曲线对应的值为0.9,这个(绿色)曲线对应的
=0.98,如果你执行写在这里的公式,在
等于0.98的时候,得到的并不是绿色曲线,而是紫色曲线,你可以注意到紫色曲线的起点较低,我们来看看怎么处理。

计算移动平均数的时候,初始化,
,所以如果一天温度是40华氏度,那么
,得到的值会小很多,所以第一天温度的估测不准。
,假设
和
都是正数,计算后
要远小于
和
,所以
也不能很好估测出这一年前两天的温度。
有个办法可以修改这一估测,那就是不用,而是用
,t 就是现在的天数。
举个具体例子,当时,
,因此对第二天温度的估测变成了
,也就是
和
的加权平均数,并去除了偏差。你会发现随着
增加,
接近于0,所以当
很大的时候,偏差修正几乎没有作用。因此当
较大的时候,紫线基本和绿线重合了。不过在开始学习阶段,你才开始预测热身练习,偏差修正可以帮助你更好预测温度,偏差修正可以帮助你使结果从紫线变成绿线。
在机器学习中,在计算指数加权平均数的大部分时候,大家不在乎执行偏差修正,因为大部分人宁愿熬过初始时期,拿到具有偏差的估测,然后继续计算下去。如果你关心初始时期的偏差,在刚开始计算指数加权移动平均数的时候,偏差修正能帮助你在早期获取更好的估测。
1. 动量梯度下降 Momentum
(Gradient descent with Momentum)
还有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准的梯度下降算法,其基本的想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。
因为小批量梯度下降仅在看到示例的子集后才进行参数更新,所以更新的方向具有一定的差异,因此小批量梯度下降所采取的路径将“朝着收敛”振荡。
利用冲量则可以减少这些振荡。冲量将过去的梯度考虑在内,以平滑梯度下降的步骤。它可以应用于批量梯度下降,小批次梯度下降或随机梯度下降。
冲量考虑了过去的梯度以平滑更新。我们将先前梯度的“方向”存储在变量 𝑣 中。这将是先前步骤中梯度的指数加权平均值,你也可以将 𝑣 看作是下坡滚动的球的“速度”,根据山坡的坡度/坡度的方向来提高速度(和冲量)。
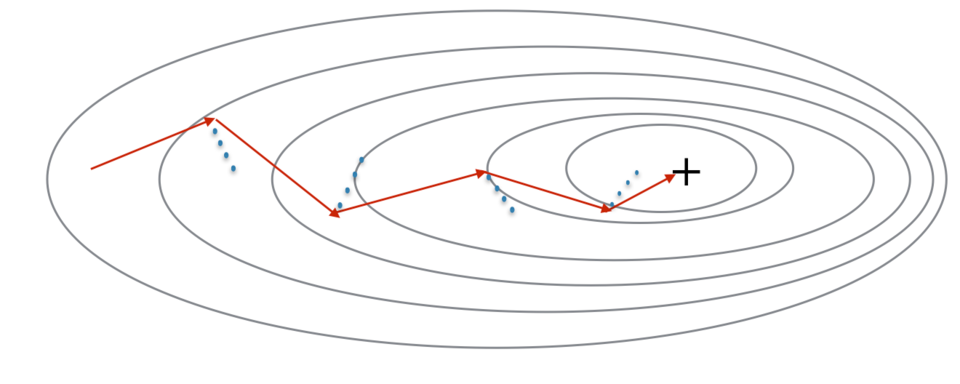
红色箭头显示了带冲量的小批次梯度下降步骤所采取的方向。蓝点表示每一步的梯度方向(相对于当前的小批量)。让梯度影响 𝑣 而不是仅遵循梯度,然后朝 𝑣 的方向迈出一步。
使用动量梯度下降法,你需要做的是,在每次迭代中,假设用现有的 mini-batch 计算,
,你要做的是计算
dW#card=math&code=v%7B%7BdW%7D%7D%3D%20%5Cbeta%20v%7B%7BdW%7D%7D%20%2B%20%5Cleft%28%201%20-%20%5Cbeta%20%5Cright%29dW&id=VxpMc)
这跟我们之前的计算相似,也就是%5Ctheta%7Bt%7D#card=math&code=v%20%3D%20%5Cbeta%20v%20%2B%20%5Cleft%28%201%20-%20%5Cbeta%20%5Cright%29%5Ctheta%7Bt%7D&id=Ud3yJ),
的移动平均数。接着同样地计算
,
%7Bdb%7D#card=math&code=v%7Bdb%7D%20%3D%20%5Cbeta%20v%7B%7Bdb%7D%7D%20%2B%20%28%201%20-%20%5Cbeta%29%7Bdb%7D&id=klRaa)
然后重新赋值权重,
这样就可以减缓梯度下降的幅度。如红色箭头路线: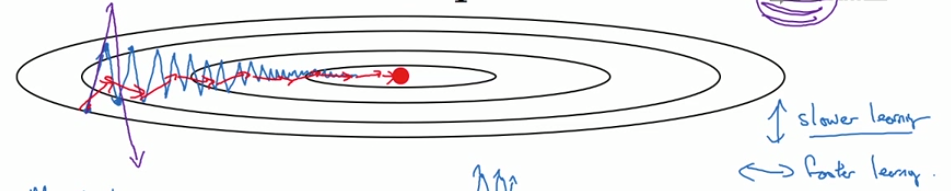
在上面这几个导数中,你会发现这些纵轴上的摆动平均值接近于零,因为正负数相互抵消。而在横轴方向的平均值仍然较大。因此用算法几次迭代后,动量梯度下降法使得纵轴方向的摆动变小了,横轴方向运动更快,因此你的算法走了一条更加直接的路径,在抵达最小值的路上减少了摆动。
动量梯度下降法的一个本质,就是最小化碗状函数。这些微分项,想象它们为加速度,Momentum项相当于速度。
想象你有一个碗,你拿一个球,微分项给了这个球一个加速度,此时球正向碗底滚,球因为加速度越滚越快,而因为 稍小于1,表现出一些摩擦力,所以球不会无限加速下去。它不像梯度下降法每一步都独立于之前的步骤,你的球可以向下滚,获得动量,可以从碗向下加速获得动量。

最后我们来看具体如何计算。
现在有两个超参数,学习率以及参数
,
控制着指数加权平均数。
最常用的值是 0.9,平均前十次迭代的梯度。可以做一些超参数的研究,不过0.9是很棒的鲁棒数。
- 速度用零初始化。
- 如果
,则它变为没有冲量的标准梯度下降。
的常用值范围是0.8到0.999。如果你不想调整它,则
通常是一个合理的默认值。
- 冲量
越大,更新越平滑,因为我们对过去的梯度的考虑也更多。但是,如果
太大,也可能使更新变得过于平滑。
- 调整模型的最佳
可能需要尝试几个值,以了解在降低损失函数
的值方面最有效的方法。
那么关于偏差修正,所以你要拿和
除以
,实际上人们不这么做,因为10次迭代之后,因为你的移动平均已经过了初始阶段,不再是一个具有偏差的预测。当然
初始值是0,要注意到这是和
拥有相同维数的零矩阵,也就是跟
拥有相同的维数;
的初始值也是向量零,和
拥有相同的维数,也就是和
是同一维数。

最后要说一点,如果你查阅了动量梯度下降法相关资料,你经常会看到公式中被删除了,用的是
所以缩小了
倍,相当于乘以
,用梯度下降最新值的时候,
也会根据
相应变化。实际上,二者效果都不错,只会影响到学习率
的最佳值。
我觉得这个公式用起来没有那么自然,因为如果最后要调整超参数,就会影响到
和
,你也许还要修改学习率
,所以我更喜欢左边的公式,而不是删去了
的这个公式。但是两个公式都将
设置为0.9,是超参数的常见选择,只是在这两个公式中,学习率
的调整会有所不同。
2. RMSprop 均方根
全称是root mean square prop算法,它和Momentum算法一样,也可以加速梯度下降。

回忆一下执行梯度下降时(蓝箭头),虽然横轴方向正在推进,但纵轴方向会有大幅度摆动。假设纵轴代表参数,横轴代表参数
,可能有
,
或者其它重要的参数,为了便于理解,称之为
和
。
所以,你想减缓方向的学习,即纵轴方向,同时加快(至少不是减缓)横轴方向的学习,RMSprop算法可以实现这一点。
在第次迭代中,本算法会照常计算当下 mini-batch 的微分
,
,所以我会保留这个指数加权平均数。我们用到新符号
,
%20%7BdW%7D%5E%7B2%7D#card=math&code=S%7BdW%7D%3D%20%5Cbeta%20S%7BdW%7D%20%2B%20%281%20-%5Cbeta%29%20%7BdW%7D%5E%7B2%7D&id=phu5y),澄清一下,这个平方的操作是针对
这一整个符号的。这样做能够保留微分平方的加权平均数,同样
%7Bdb%7D%5E%7B2%7D#card=math&code=S%7Bdb%7D%3D%20%5Cbeta%20S%7Bdb%7D%20%2B%20%281%20-%20%5Cbeta%29%7Bdb%7D%5E%7B2%7D&id=qdGVA)。
接着更新参数值,,
。
所以这就是RMSprop,全称是均方根,因为你将微分进行平方,然后最后使用了平方根。
理解原理
我们希望在横轴方向的学习速度快,而减缓纵轴方向上的摆动,所以有了和
,我们希望
会相对较小,所以要除以一个较小的数,而希望
较大,所以它要除以较大的数字,这样就可以减缓纵轴上的变化。

你看这些微分,垂直方向的要比水平方向的大得多,所以斜率在方向特别大,也就是
较大,
较小。
的平方较大,所以
也会较大,而相比之下,
会小一些,所以结果就是纵轴上的更新要被一个较大的数相除,就能消除摆动,而水平方向的更新则被较小的数相除。

RMSprop的影响就是你的更新最后会变成这样(绿色线),纵轴方向上摆动较小,而横轴方向继续推进。还有个影响就是,你可以用一个更大学习率,然后加快学习,而无须在纵轴上垂直方向偏离。

要说明一点,这里把纵轴和横轴方向分别称为和
,只是为了方便展示而已。实际中,你会处于参数的高维度空间,所以需要消除摆动的垂直维度,你需要消除摆动,实际上是参数
,
等的合集,水平维度可能
,
等等,因此把
和
分开只是方便说明。实际中
是一个高维度的参数向量,
也是一个高维度参数向量,但是你的直觉是,在你要消除摆动的维度中,最终你要计算一个更大的和值,这个平方和微分的加权平均值,所以你最后去掉了那些有摆动的方向。
最后再说一个这个算法的细节:要确保你的算法不会除以0。如果的平方根趋近于0怎么办?解决方法是在分母上加上一个很小很小的
,
是多少没关系,
是个不错的选择,这只是保证数值能稳定一些。
所以RMSprop跟Momentum有很相似的一点,可以消除梯度下降中的摆动,包括mini-batch梯度下降,并允许你使用一个更大的学习率,从而加快你的算法学习速度。
3. Adam 前两者的结合
Adam优化算法基本上就是将Momentum和RMSprop结合在一起,得到的一个更好的优化算法。
原理
- 计算过去梯度的指数加权平均值,并将其存储在变量 𝑣(使用偏差校正之前)和 𝑣𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑑(使用偏差校正)中。
- 计算过去梯度的平方的指数加权平均值,并将其存储在变量 𝑠(偏差校正之前)和 𝑠𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑑(偏差校正中)中。
- 组合“1”和“2”的信息,在一个方向上更新参数。

计算规则
在第次迭代中,你要计算微分,一般用mini-batch梯度下降法计算
,
。
接下来计算Momentum指数加权平均数,dW#card=math&code=v%7BdW%7D%3D%20%5Cbeta%7B1%7Dv%7BdW%7D%20%2B%20%28%201%20-%20%5Cbeta%7B1%7D%29dW&id=KAsh2)
%7Bdb%7D#card=math&code=v%7Bdb%7D%3D%20%5Cbeta%7B1%7Dv%7Bdb%7D%20%2B%20%28%201%20-%5Cbeta%7B1%7D%20%29%7Bdb%7D&id=sqCpi)。
接着你用RMSprop进行更新,%7B(dW)%7D%5E%7B2%7D#card=math&code=S%7BdW%7D%3D%5Cbeta%7B2%7DS%7BdW%7D%20%2B%20%28%201%20-%20%5Cbeta%7B2%7D%29%7B%28dW%29%7D%5E%7B2%7D&id=G6zdb)
%7B(db)%7D%5E%7B2%7D#card=math&code=S%7Bdb%7D%20%3D%5Cbeta%7B2%7DS%7Bdb%7D%20%2B%20%5Cleft%28%201%20-%20%5Cbeta%7B2%7D%20%5Cright%29%7B%28db%29%7D%5E%7B2%7D&id=DWz5J)。
相当于Momentum更新了超参数,RMSprop更新了超参数
。
一般使用Adam算法的时候,要计算偏差修正,
也使用偏差修正,
。
t 是 Adam 采取的步骤数,表示第 t 次迭代。
最后更新权重,所以更新后是 ,
,
如果你只是用Momentum,使用或者修正后的
,但现在我们加入了RMSprop的部分,所以我们要除以修正后
的平方根加上
。𝜀 是一个很小的数字,以避免被零除。
本算法中有很多超参数,
- 超参数学习率
很重要,也经常需要调试,你可以尝试一系列值,然后看哪个有效。
常用的缺省值为0.9,这是dW的移动平均数,也就是
的加权平均数,这是Momentum涉及的项。
- 至于超参数
,Adam论文作者推荐使用0.999,这是在计算
%7D%5E%7B2%7D#card=math&code=%7B%28dW%29%7D%5E%7B2%7D&id=rS65K)以及
%7D%5E%7B2%7D#card=math&code=%7B%28db%29%7D%5E%7B2%7D&id=o6Zwp)的移动加权平均值,关于
的选择其实没那么重要,Adam论文的作者建议
为
,但你并不需要设置它,因为它并不会影响算法表现。
但是在使用Adam的时候,人们往往使用缺省值即可,,
和
都是如此,我觉得没人会去调整
,然后尝试不同的
值,看看哪个效果最好。你也可以调整
和
,但我认识的业内人士很少这么干。
为什么这个算法叫做Adam?Adam代表的是Adaptive Moment Estimation,用于计算这个微分(
),叫做第一Moment,
用来计算平方数的指数加权平均数(
%7D%5E%7B2%7D#card=math&code=%7B%28dW%29%7D%5E%7B2%7D&id=ci3ei)),叫做第二Moment,所以Adam的名字由此而来。
4. 学习率衰减
Learning rate decay
加快学习算法的一个办法就是随时间慢慢减少学习率,我们将之称为学习率衰减。
对于固定值,不同的mini-batch在迭代过程中有噪音(蓝线),它下降朝向最小值,但是不会精确地收敛,所以你的算法最后在最小值附近以较大的幅度摆动。

如果慢慢减小学习率的话,在初期的时候,
学习率较大,学习相对较快,但随着
变小,你的步伐也会变慢变小,所以最后你的曲线(绿色线)会在最小值附近的一小块区域里摆动。
所以慢慢减少的本质在于,在学习初期,你能有较大的步伐,但当开始收敛的时候,小一些的学习率能让你步伐小一些。
你可以将学习率设为
(decay-rate称为衰减率,epoch-num为代数,
为初始学习率),注意这个衰减率是另一个你需要调整的超参数。
还有一种衰减方法是指数衰减,其中相当于一个小于1的值,如
,所以你的学习率呈指数下降。
人们用到的其它公式有或者
,
为mini-batch的数字,k是常数(也是一个超参数)。
有时人们也会用一个离散下降的学习率,也就是某个步骤有某个学习率,一会之后,学习率减少了一半,一会儿减少一半,一会儿又一半,这就是离散下降(discrete stair cease)的意思。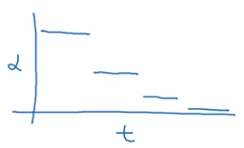
手动衰减,只有模型数量小的时候有用,但有时候人们也会这么做。
对我而言,学习率衰减并不是我尝试的要点,设定一个固定的,然后好好调整,会有很大的影响,学习率衰减的确大有裨益,有时候可以加快训练,但它并不是我会率先尝试的内容。
关于局部最优

曾经人们在提到局部最优时脑海里出现的图是左图这样的,但是这些理解并不正确。对于凸函数或凹函数,每个方向都是相同的(都在上升或都是下降)。但是一个具有高维度空间的函数,如果梯度为0,那么在每个方向,它可能是凸函数,也可能是凹函数。如果你在2万维空间中,想要得到局部最优,需要所有的2万个方向都一样,这发生的机率也许很小,也许是,你更有可能遇到有些方向的曲线会这样向上弯曲,另一些方向曲线向下弯,而不是所有的都向上弯曲,因此在高维度空间,你更可能碰到鞍点,如右图所示。
所以我们从深度学习历史中学到的一课就是,我们对低维度空间的大部分直觉,比如你可以画出上面的图,并不能应用到高维度空间中。
局部最优不是问题了,但问题在于导数长时间趋近于0的平缓段会减缓学习。我们会沿着这段长坡走,直到这里,然后走出平稳段。
所以此次视频的要点是,
首先,你不太可能困在极差的局部最优中,条件是你在训练较大的神经网络,存在大量参数,并且成本函数被定义在较高的维度空间。
第二点,平稳段是一个问题,这样使得学习十分缓慢,这也是像Momentum或是RMSprop,Adam这样的算法,能够加速学习算法的地方,能让你尽早往下走出平稳段。

若有收获,就点个赞吧
0 人点赞
