1. 梳理节点概念
节点是一个 ES 的实例,其本质就是一个 java 进程
- 一个机器上可以运行多个 ES 进程,但是生产环境一般建议一台机器上就运行一个 ES 实例;
- 每一个节点在启动之后,会分配一个 UID,保存在 data 目录下;
Coordinating Node,处理请求的节点
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master 节点;
- 所有节点默认都是 Coordinating Node;
- 通过将其他类型设置成 False,使其成为 Dedicated Coordinating Node;
Data Node,可以保存数据的节点
- 节点启动后,默认就是数据节点。可以设置 node.data: false 禁止;
- 由 Master Node 决定如何把分片分发到数据节点上;
Master Node,主节点
- 职责:
- 处理创建、删除索引等请求;
- 决定分片被分配到哪个 Data Node;
- 负责索引的创建、删除;
- 维护并且更新 Cluster State;
- 最佳实践:
- Master 非常重要,在部署上需要考虑解决单点的问题,防止 Master 宕机;
- 为一个集群设置多个 Master 节点;
- 每个节点只承担 Master 的单一角色;
- 职责:
Master Eligible Node,具备成为 Master 资格的节点
- 每个节点启动后,默认就是一个 Master eligible 节点,可以设置 ndoe.master: false 禁止;
- 当集群内第一个 Master elibible 节点启动时候,它会将自己选举成 Master 节点;
- 一个集群,支持配置多个 Master Eligible 节点。这些节点可以在必要时(如 Master 节点出现故障,网络故障时)参与选主流程,成为 Master 节点;
Cluster State,集群状态包括以下信息:
- 集群层面的配置;
- 集群内由哪些节点;
- 所有的索引和其相关的 Mapping 与 Setting 信息;
- 索引内各分片所在的节点位置; :::tips ES 集群中的每个节点都会存储 Cluster State,知道索引内各分片所在的节点位置,因此在整个集群中的任意节点都可以知道一条数据该往哪个节点分片上存储。反之也知道该去哪个分片读。所以,Elasticsearch 不需要将读写请求发送到 Master 节点,任何节点都可以作为数据读写的切入点对请求进行响应。这样进一步减轻了Master节点的网络压力,同时提高了集群的整体路由性能。 :::
2. ElasticSearch 7.x 之前的选主流程
7.x 之前版本的 elasticsearch 选举算法是基于Bully算法改造的。
它假定所有节点都有一个惟一的 ID,使用该 ID 对节点进行排序,选择最高 ID 节点作为 Master。 该算法的优点是易于实现,但是容易出现脑裂问题。
1. 什么时候开始选主?
- 集群启动;
- Master 失效
- 非 Master 节点运行的 MasterFaultDetection 检测到 Master 失效,执行 rejoin 操作,重新选主;
- 注意,即使一个节点认为 Master 失效也会进入选主流程;
2. ZenDiscovery流程概述
- 每个节点计算最高的已知节点 ID,并向该节点发送领导投票;
- 如果一个节点收到足够多的票数,并且该节点也为自己投票,那么它将扮演领导者的角色,开始发布集群状态;
- 所有节点都会参数选举,并参与投票,但是只有有资格成为 master 的节点的投票才有效;
有多少选票才算是赢得选举的定义,就是所谓的法定人数。在弹性搜索中,法定大小是一个可配置的参数。(一般配置成:可以成为 master 节点数 n/2+1)
3. 流程分析
整体流程可以概括为:选举临时 Master,如果本节点当选,等待确立 Master,如果其他节点当选,等待加入 Master,然后启动节点失效探测器。流程图如下所示: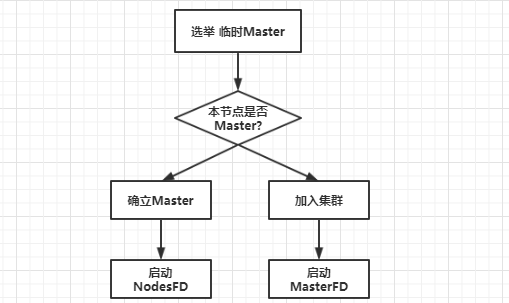
3.1 选举临时 Master 流程
临时 Master 的选举过程如下:
“ping” 所有节点,获取节点列表 fullPingResponses,ping 结果不包含本节点,把本节点单独添加到fullPingResponses 中;
构建两个列表
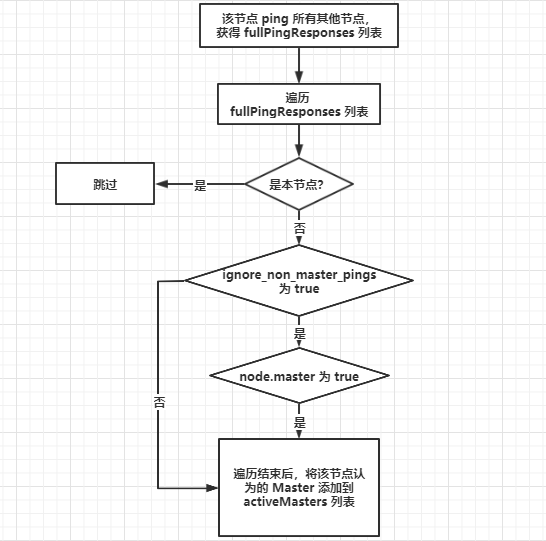
- activeMasters 列表:存储集群当前活跃 Master 列表。遍历第一步获取的所有节点,将每个节点所认为的当前 Master 节点加入 activeMasters 列表中(不包括本节点)。在遍历过程中,如果配置了
discovery.zen.master_election.ignore_non_master_pings: true(默认为 false)而节点又不具备Master 资格,则跳过该节点。
- activeMasters 列表:存储集群当前活跃 Master 列表。遍历第一步获取的所有节点,将每个节点所认为的当前 Master 节点加入 activeMasters 列表中(不包括本节点)。在遍历过程中,如果配置了
 :::tips
这个过程是将集群当前已存在的 Master 加入 activeMasters 列表,正常情况下只有一个。如果集群已存在Master,则每个节点都记录了当前 Master是哪个,考虑到异常情况下,可能各个节点看到的当前 Master 不同,这种场景可能会在节点之间网络延迟比较大的情况下出现,在启动进程之后,出现选主结果不一致的情况。在构建 activeMasters 列表过程中,如果节点不具备 Master 资格,则可以通过 ignore_non_master_pings 选项忽略它认为的那个 Master。 (过滤掉没有)
:::
:::tips
这个过程是将集群当前已存在的 Master 加入 activeMasters 列表,正常情况下只有一个。如果集群已存在Master,则每个节点都记录了当前 Master是哪个,考虑到异常情况下,可能各个节点看到的当前 Master 不同,这种场景可能会在节点之间网络延迟比较大的情况下出现,在启动进程之后,出现选主结果不一致的情况。在构建 activeMasters 列表过程中,如果节点不具备 Master 资格,则可以通过 ignore_non_master_pings 选项忽略它认为的那个 Master。 (过滤掉没有)
:::
- masterCandidates 列表:存储 master 候选者列表。遍历第一步获取列表,去掉不具备 Master 资格的节点,添加到这个列表中。
- 如果 activeMasters 为空,则从 masterCandidates 中选举,结果可能选举成功,也可能选举失败。如果不为空,则从 activeMasters 中选择最合适的作为 Master。
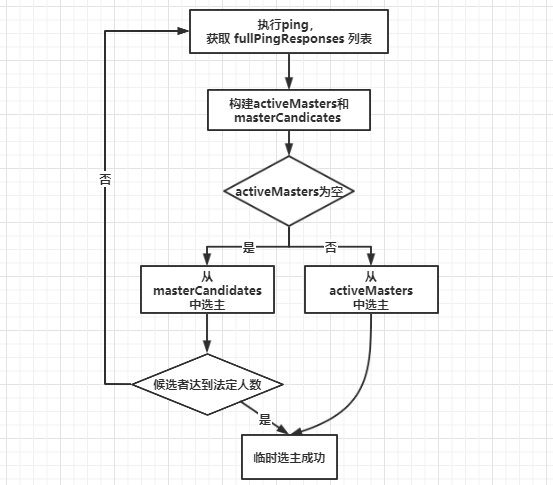
3.2 投票
在 ES 中,发送投票,就是发送加入集群(JoinRequest)请求。得票,就是申请加入该节点的请求的数量。 收集投票,进行统计,这里的投票就是加入它的连接数,当节点检查收到的投票是否足够时,就是检查加入它的连接数是否足够, 其中会去掉没有 Master 资格节点的投票。
3.3 确认master
选举出的临时 Master 有两种情况:该临时 Master 是本节点或非本节点。
- 如果临时 Master 是本节点:
- 等待足够多的具备 Master 资格的节点加入本节点(投票达到 法定人数),以完成选举。
- 超时(默认为30秒,可配置)后还没有满足数量的 join 请求, 则选举失败,需要进行新一轮选举。
- 成功后发布新的 ClusterState。
- 如果其他节点被选为 Master:
- 不再接受其他节点的 join 请求。
- 向 Master 发送加入请求,并等待回复。超时时间默认为1分钟 (可配置),如果遇到异常,则默认重试3次(可配置)。
- 最终当选的 Master 会先发布集群状态,才确认其他节点的 join 请求,并且已经收到了集群状态。本步骤检查收到的集群状态中的 Master 节点如果为空,或者当选的 Master 不是之前选择的节点,则重新选举。
3.4 完整的流程图
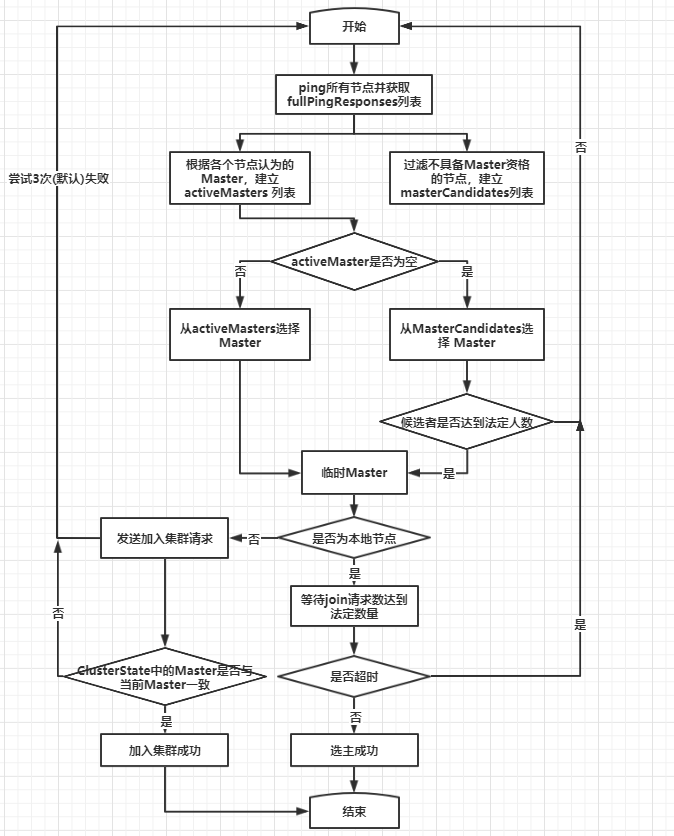
4. 节点失效检测
选主流程已执行完毕,Master身份已确认,非 Master 节点已加入集群。节点失效检测会监控节点是否离线,然后处理其中的异常。失效检测是选主流程之后不可或缺的步骤,不执行失效检测可能会产生脑裂(双主或多主)。
我们需要启动两种失效探测器:
- 在 Master 节点,启动 NodesFaultDetection,简称 NodesFD。定期探测加入集群的节点是否活跃。
在非 Master 节点,启动 MasterFaultDetection,简称 MasterFD。定期探测 Master 节点是否活跃。
NodesFaultDetection 和 MasterFaultDetection 都是通过定期(默认为1秒)发送的 ping 请求探测节点是否正常的,当失败达到一定次数(默认为3次),或者收到来自底层连接模块的节点离线通知时,开始处理节点离开事件。
5. 极其重要的参数 minimum_master_nodes
防止脑裂、防止数据丢失的极其重要的参数:
discovery.zen.minimum_master_nodes=(master_eligible_nodes)/2+1
这个参数会用于至少以下多个重要时机的判断:
- 触发选主:进入选举临时的 Master 之前,参选的节点数需要达到法定人数;
- 决定 Master:选出临时的 Master 之后,得票数需要达到法定人数,才确认选主成功;
- gateway 选举元信息:向有 Master 资格的节点发起请求,获取元数据,获取的响应数量必须达到法定人数,也就是参与元信息选举的节点数;
- Master 发布集群状态:成功向节点发布集群状态信息的数量要达到法定人数;
- NodesFaultDetection 事件中是否触发 rejoin:当发现有节点连不上时,会执行 removeNode。接着审视此时的法定人数是否达标(discovery.zen.minimum_master_nodes),不达标就主动放弃 Master 身份执行 rejoin 以避免脑裂;
Master 扩容场景:目前有3个 master_eligible_nodes,可以配置法定数量 为2。如果将master_eligible_nodes 扩容到4个,那么法定数量就要提高到3。此时需要先把discovery.zen.minimum_master_nodes 配置设置为3,再扩容 Master 节点。这个配置可以动态设置:
PUT /_cluster/settings{"persistent": {"discovery.zen.minimum_master_nodes": 3}}
Master 减容场景:缩容与扩容是完全相反的流程,需要先缩减 Master 节点,再把法定数降低;
:::warning 修改 Master 以及集群相关的配置一定要非常谨慎!配置错误很有可能导致脑裂,甚至数据写坏、数据丢失等场景; ::: :::tips 注意:**最新版本 ES 7已经移除 minimum_master_nodes 配置,让 Elasticsearch 自己选择可以形成仲裁的节点。 :::
3. ElasticSearch 7.x之后的选主流程
3.1 Raft算法选主标准流程
其设计原则如下:
- 容易理解
- 减少状态的数量,尽可能消除不确定性
在 Raft 中,节点可能的状态有三种,其转换关系如下: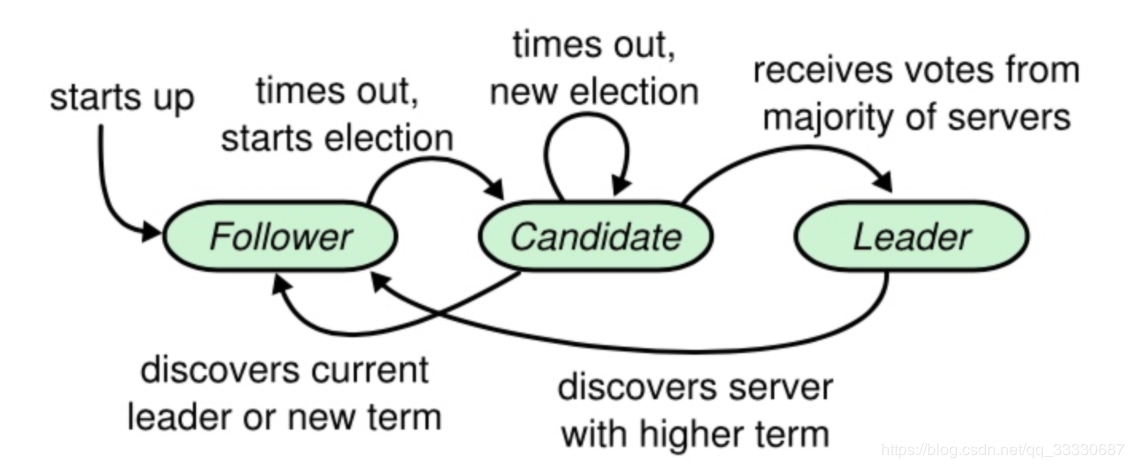
正常情况下,集群中只有一个 Leader,其他节点全是 Follower 。Follower 都是被动接收请求,从不主动发送任何请求。Candidate 是从 Follower 到 Leader 的中间状态。
Raft 中引入任期(term)的概念,每个 term 内最多只有一个 Leader。term 在 Raft 算法中充当逻辑时钟的作用。服务器之间通信的时候会携带这个 term,如果节点发现消息中的 term 小于自己的 term,则拒绝这个消息;如果大于本节点的 term,则更新自己的 term。如果一个 Candidate 或者 Leader 发现自己的任期过期了,它会立即回到 Follower 状态。
Raft 选举流程为:
- 增加节点本地的 current term ,切换到Candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPC(让大家投他)。
然后等待其他节点的响应,会有如下三种结果:
- 如果接收到大多数服务器的选票,那么就变成 Leader
- 如果收到了别人的投票请求,且别人的term比自己的大,那么候选者退化为 follower
- 如果选举过程超时,再次发起一轮选举
通过下面的约束来确定唯一 Leader(选举安全性):
- 同一任期内,每个节点只有一票
- 得票(日志信息不旧于Candidate的日志信息)过半则当选为 Leader
成为 Leader 后,向其他节点发送心跳消息来确定自己的地位并阻止新的选举。
当同时满足以下条件时,Follower 同意投票:
- RequestVote 请求包含的 term 大于等于当前 term
- 日志信息不旧于 Candidate 的日志信息
- first-come-first-served 先来先得
3.2 ES实现的Raft算法选主流程
ES 实现的 Raft 中,选举流程与标准的有很多区别:
- 初始为 Candidate 状态
- 执行 PreVote 流程,并拿到 maxTermSeen
- 准备 RequestVote 请求(StartJoinRequest),基于 maxTermSeen,将请求中的 term 加1(尚未增加节点当前 term)
- 并行发送 RequestVote,异步处理。目标节点列表中包括本节点。
ES 实现中,候选人不先投自己,而是直接并行发起 RequestVote,这相当于候选人有投票给其他候选人的机会。这样的好处是可以在一定程度上避免3个节点同时成为候选人时,都投自己,无法成功选主的情况。
ES 不限制每个节点在某个 term 上只能投一票,节点可以投多票,这样会产生选出多个主的情况: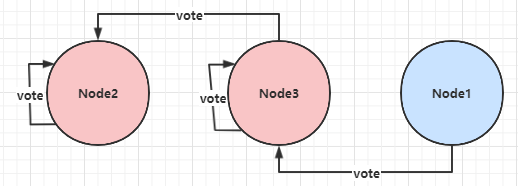
Node2 被选为主,收到的投票为:Node2、Node3;
Node3 被选为主,收到的投票为:Node3、Node1;
对于这种情况,ES 的处理是让最后当选的 Leader 成功。作为 Leader,如果收到 RequestVote 请求,他会无条件退出 Leader 状态。在本例中,Node2 先被选为主,随后他收到 Node3 的 RequestVote 请求,那么他退出 Leader 状态,切换为 CANDIDATE,并同意向发起 RequestVote 候选人投票。因此最终 Node3 成功当选为 Leader。
3.3 动态维护参选节点列表
在此之前,我们讨论的前提是在集群节点数量不变的情况下,现在考虑下集群扩容,缩容,节点临时或永久离线时是如何处理的。在 7.x 之前的版本中,用户需要手工配置 minimum_master_nodes,来明确告诉集群过半节点数应该是多少,并在集群扩缩容时调整他。现在,集群可以自行维护。
在取消了 discovery.zen.minimum_master_nodes 配置后,ES 如何判断多数?是自己计算和维护 minimum_master_nodes 值么?不,现在的做法不再记录“quorum” 法定数量的具体数值,取而代之的是记录一个节点列表,这个列表中保存所有具备 master 资格的节点(有些情况下不是这样,例如集群原本只有1个节点,当增加到2个的时候,这个列表维持不变,因为如果变成2,当集群任意节点离线,都会导致无法选主。这时如果再增加一个节点,集群变成3个,这个列表中就会更新为3个节点),称为 VotingConfiguration,他会持久化到集群状态中。
在节点加入或离开集群之后,Elasticsearch 会自动对 VotingConfiguration 做出相应的更改,以确保集群具有尽可能高的弹性。在从集群中删除更多节点之前,等待这个调整完成是很重要的。你不能一次性停止半数或更多的节点。(感觉大面积缩容时候这个操作就比较感人了,一部分一部分缩)
默认情况下,ES 自动维护 VotingConfiguration,有新节点加入的时候比较好办,但是当有节点离开的时候,他可能是暂时的重启,也可能是永久下线。你也可以人工维护 VotingConfiguration,配置项为:cluster.auto_shrink_voting_configuration,当你选择人工维护时,有节点永久下线,需要通过 voting exclusions API 将节点排除出去。如果使用默认的自动维护 VotingConfiguration,也可以使用 voting exclusions API 来排除节点,例如一次性下线半数以上的节点。
如果在维护 VotingConfiguration 时发现节点数量为偶数,ES 会将其中一个排除在外,保证 VotingConfiguration是奇数。因为当是偶数的情况下,网络分区将集群划分为大小相等的两部分,那么两个子集群都无法达到“多数”的条件。

若有收获,就点个赞吧
0 人点赞
