一、简介
您可以创建和应用索引生命周期管理 (ILM) 策略,根据性能、弹性和保留需求来让 ES 自动管理索引。索引生命周期策略可以触发如下操作:
- Rollover:当现有索引达到一定的年龄、文档数量或大小时,重定向别名以开始写新索引;
- Shrink:减少索引中的主碎片数量;
- Force merge:手动触发合并,以减少索引中每个分片中的 segments,并释放被删除文档所占用的空间;
- Freeze:设置索引只读并最小化它的内存占用;
- Delete:永久删除索引,包括索引的所有数据和元数据;
ILM 使在 hot-warm-cold 体系结构中管理索引变得更加容易,这在处理 logs 和 metrics 等时间序列数据时很常见。
您可以指定:
- shard 大小,文档数量或年龄的最大值,当达到时就可以 rollover 到一个新的索引;
- 此时,旧索引不再被更新,并且可以减少旧索引的 primary shard 的数量;
- 何时通过 Force merge 来永久删除被标记为 deletion 的文档;
- 此时,旧索引可以移动到性能较差的硬件上;
- 此时,可用性不那么重要,可以减少副本的数量;
- 何时索引被安全删除;
例如,如果你从一个 atm 机群中索引 metrics 数据到 Elasticsearch,你可以定义一个策略:
- 当索引达到50GB时,rollover 到一个新索引;
- 将旧索引移动到 warm 阶段,将其设置为只读,并将其缩小为单个分片。
- 7天后,将索引移到 cold 阶段,并将其移到较便宜的硬件上;
- 一旦达到所需的30天保留期,就删除索引; :::info 要使用 ILM,集群中的所有节点必须运行相同的版本。尽管可以在混合版本的集群中创建和应用策略,但不能保证它们将按预期工作。如果使用集群中不是所有节点都支持的策略将导致错误。 :::
二、基本概念
1. 索引生命周期
ILM 定义了四个索引生命周期阶段:
- Hot:索引还存在大量的读写操作;
- Warm:索引不存在写操作,还有被查询的需要;
- Cold:数据不存在写操作,读操作也不多;
- Delete:索引不再需要,可以被安全删除;
:::info
在创建索引时,可以手动应用生命周期策略;
对于时间序列索引,需要将生命周期策略与创建新索引的索引模板关联起来,当 Rollover 时,手动应用的生命周期策略不会自动应用到新索引; :::
生命周期阶段的转变:
- ILM 根据索引的年龄在生命周期中移动索引。为了控制索引阶段转变的时间,可以为每个阶段设置最小年龄。要将索引移动到下一个阶段,当前阶段中的所有操作都必须完成,并且索引的年龄必须大于下一个阶段的最小年龄;
- 最小年龄默认为零,这将导致 ILM 在当前阶段的所有操作完成后立即将索引移动到下一阶段;
- 如果索引有未分配的碎片,并且集群运行状况状态为黄色,该索引仍然可以根据其索引生命周期管理策略转换到下一个阶段。然而,由于 Elasticsearch 只能在绿色集群上执行某些清理任务,因此可能会出现意想不到的副作用。
生命周期阶段的执行:
- ILM 控制一个阶段中 action 的执行顺序,以及每个 action 需要执行哪些步骤;
- 当索引进入一个阶段时,ILM 在索引元数据中缓存阶段的 definition。这确保了策略更新不会将索引置于永远不能退出该阶段的状态。如果策略的更新内容可以被安全的使用,ILM 将更新缓存中阶段 definition。如果不能,则继续使用缓存中阶段 definition 进行执行;
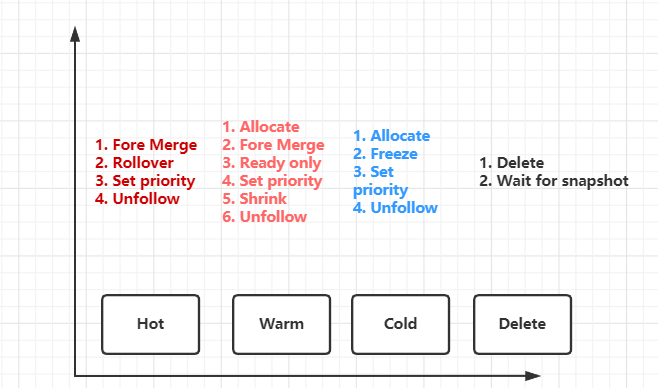
阶段的 action:
- Hot:
- Set Priority
- Unfollow
- Rollover
- Warm:
- Set Priority
- Unfollow
- Read-Only
- Allocate
- Shrink
- Force Merge
- Cold:
- Set Priority
- Unfollow
- Allocate
- Freeze
- Delete:
- Wait For Snapshot
- Delete
- Hot:
2. Rollover
在索引时间序列数据 (如日志或指标) 时,不能无限期地写入单个索引。为了满足索引和搜索性能的要求并管理资源的使用,需要写入一个索引,直到达到某个阈值,然后创建一个新索引并开始写入;
使用 Rollover 有以下好处:
- 优化 Hot 节点的高性能的读写操作;
- 优化 Warm 节点的搜索性能;
- 将较旧的、访问频率较低的数据转移到更便宜的 Cold 节点;
- 根据 retention 保留策略,通过删除整个索引,还删除数据;
Rollover 依赖三件事:
- 索引模板,用于指定系列中每个新索引的设置。您可以优化此配置以便提高读写效率,通常使用与 Hot 节点相同数量的碎片。
- 索引别名,用于引用整个索引集。
- 一个单独索引被指定为 写入索引,这是处理所有写请求的活跃索引,在每次 rollover 时,新索引成为写索引。
自动 Rollover
- ILM 允许您根据索引大小、文档数量或年龄自动转到新索引。当触发 rollover 时,将创建一个新索引,写入别名将更新为指向新索引,并将所有后续更新写入新索引。
3. 生命周期策略更新
- 可以修改当前的策略,或者切换到不同的策略;
- 为了确保策略更新不会将索引置于无法退出当前阶段的状态,当进入该阶段时,将在索引元数据中缓存阶段定义。此缓存的定义用于完成该阶段。
当索引推进到下一个阶段时,它使用更新策略中的阶段定义。
当策略最初应用于索引时,该索引将获得策略的最新版本。如果您更新了策略,策略版本就会发生冲突,ILM 可以检测到索引使用了需要更新的早期版本。
对 min_age 的更改不会传播到缓存的定义。更改一个阶段的 min_age 不会影响当前正在执行该阶段的索引。
例如,如果您创建了一个策略,该策略的 Hot 阶段没有指定 min_age,那么在应用该策略时,索引将立即进入 Hot 阶段。如果您随后更新策略,为 Hot 阶段指定 min_age 为1天,那么这对已经处于 Hot 阶段的索引没有影响。策略更新之后创建的索引会直到一天之后才会进入 Hot 阶段。
当对被管理的索引切换到不同策略时,该索引使用前一个策略缓存的定义完成当前阶段。索引在进入下一阶段时开始使用新策略。
三、使用 ILM 来自动 Rollover
当连续地将带时间戳的文档索引到 Elasticsearch 时,通常会使用索引别名,以便周期性地 rollover 到新索引。这使您能够实现一种 hot-warm-cold 的体系结构,以满足您对最新数据的性能需求,成本的控制,执行保留策略,并且仍然能够最大限度地利用数据。
使用 ILM 自动 Rollover 来管理时间序列索引的步骤如下:
- 创建生命周期策略,在其中定义合适的阶段和 action;
- 创建索引模板,将策略应用于每个新索引;
- 开始时,将初始索引定义为写索引;
- 验证索引按预期在生命周期阶段中移动;
当为 Beats 或 Logstash 这类 Elasticsearch 输出插件启用索引生命周期管理时,生命周期策略将自动设置。您不需要引导初始索引或采取任何其他操作。您可以通过 Kibana 管理或 ILM API 修改默认策略。
1. Create a lifecycle policy
- 生命周期策略指定索引生命周期中的阶段以及在每个阶段中执行的操作。生命周期最多可以有四个阶段:hot, warm, cold, 和 delete。
您可以通过 Kibana Management 或使用 put policy API 定义和管理策略。
例如,您可以定义一个策略 timeseries_policy,它有两个阶段:
- 一个 Hot phase,定义了一个 Rollover 操作,以指定索引在 max_size 达到 50gb 或 max_age 达到30天时 rollover。
- 一个Delete phase,设置 min_age 在 rollover 操作的90天后删除索引。注意,这个值是相对于 rollover 时间,而不是索引创建时间。 :::warning
ILM 在 rollover action 时,会不停的轮询检查是否满足 rollover 的条件,默认轮询间隔是 10 分钟,如果通过 ReIndex 数据来实验 rollover 效果时,最好修改轮询间隔为1s,这样就不会出现 ReIndex 已经完成了,ILM 还没有来得及开始 rollover action;(详细查看5.1,设置 poll_interval) :::
# put policy API 创建策略PUT _ilm/policy/timeseries_policy{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_size": "50GB","max_age": "30d"}}},"delete": {"min_age": "90d","actions": {"delete": {}}}}}}#1. min_age 为默认值0ms,因此新索引立即进入 hot phase;#2. 当满足任何一个条件时,触发 rollover action;#3. 在 rollover action 之后90天,将索引移动到 delete phase;#4. 当索引进入 delete phase 时触发 delete action;
2. Create an index template to apply the policy
- 若要在 rollover 时,自动将生命周期策略应用到新的写索引,要在创建新索引的索引模板中指定该策略;
- 要启用自动 rollover,模板需要配置两个 ILM 设置:
- index.lifecycle.name:指定策略名字;
- index.lifecycle.rollover_alias:指定索引别名;
- 可以使用 Kibana Create template wizard 的方式添加索引模板,实际上也是调用 Put Template API;
PUT _template/timeseries_template { "index_patterns": ["timeseries-*"], "settings": { "number_of_shards": 1, "number_of_replicas": 1, "index.lifecycle.name": "timeseries_policy", "index.lifecycle.rollover_alias": "timeseries" } }
3. Bootstrap the initial time-series index
- 创建一个名为 timeseries-000001 的索引,并且将别名指向的索引设定为 写索引;
PUT timeseries-000001 { "aliases": { "timeseries": { "is_write_index": true } } }
4. Check lifecycle progress
- 可以使用 ILM explain API 获得被管理索引的状态信息:
查看索引别名对应的所有索引(包含只读和写索引)
GET _cat/indices/logs?v
获取timeseries索引集合的状态信息;
GET timeseries-*/_ilm/explain
返回结果
初始索引正处于hot phase,attempt-rollover步骤,等待达到 rollover 条件
{ “indices”: { “timeseries-000001”: { “index”: “timeseries-000001”, “managed”: true, “policy”: “timeseries_policy”, # 使用的策略 “lifecycle_date_millis”: 1538475653281, “age”: “30s”, # index目前的age “phase”: “hot”, “phase_time_millis”: 1538475653317, “action”: “rollover”, “action_time_millis”: 1538475653317, “step”: “attempt-rollover”, # ILM正在执行的步骤 “step_time_millis”: 1538475653317, “phase_execution”: { “policy”: “timeseries_policy”, “phase_definition”: { # 当前phase的definition “min_age”: “0ms”, “actions”: { “rollover”: { “max_size”: “50gb”, “max_age”: “30d” } } }, “version”: 1, “modified_date_in_millis”: 1539609701576 } } } }
<a name="tL9a0"></a>
# 四、索引生命周期的 action
<a name="DJKol"></a>
## 1. Allocate
- 此操作可以处于:Warm、Cold phase;
- 更新索引的 Settings 来更改哪些节点允许承载索引的 shard,并且可以更改 replica 的数量;
- 在 Hot phase 不允许配置 Allocate action,因为索引的初次 Allocation 必须手动完成,或通过索引模板完成;
- 可以配置此操作,同时修改分配规则和副本数量,或仅修改分配规则,或仅修改副本数量。
- Option 可选项:必须指定副本的数量,或至少指定一个 include、exclude 或 require选项。空的 allocate 操作是无效。
- number_of_replicas:分配给索引的副本分片个数;
- include:分配索引到节点上,节点至少具有一个指定的自定义属性;
- exclude:将索引分配给不具有指定自定义属性的节点;
- require:将索引分配给具有所有指定自定义属性的节点;
- 示例:
- 下面策略中的allocate操作将索引的副本数量更改为2。索引分配规则不会改变
```json
#下面策略中的allocate操作将索引的副本数量更改为2。索引分配规则不会改变
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"allocate" : {
"number_of_replicas" : 2
}
}
}
}
}
}
使用自定义属性为节点分配索引
- 下面策略中的 allocate 操作将索引分配给 box_type 为 hot 或 warm 的节点。
- 在节点的 elasticsearch.yml 中配置 node.attr.box_type: hot,可以自定义节点的属性;
#下面策略中的 allocate 操作将索引分配给 box_type 为 hot 或 warm 的节点 PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "allocate" : { "include" : { "box_type": "hot,warm" } } } } } } }
将索引分配到指定节点,并修改副本数量
#将索引分配到指定节点,并修改副本数量 PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "allocate" : { "number_of_replicas": 1, "require" : { "box_type": "cold" } } } } } } }2. Delete
- 永久删除索引
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "delete": { "actions": { "delete" : { } } } } } }3. Force merge
此操作可以处于:Hot、Warm phase;
- 强制将索引合并到指定的最大段数中;
- 此操作使索引为只读;
要在 Hot phase 使用 force merge 动作,必须存在 rollover 动作。如果没有配置 rollover 操作,ILM 将拒绝该策略;
Options 可选项:
- max_num_segments:(必选)要合并的段数。要完全合并索引,请设置为1。
- codec:(可选)使用 best_compression 编解码器。有效值:best_compression。
- 设置 “codec”:”best_compression” 在 ILM force merge 动作中会导致 {ILM -int} 关闭,然后在force merge 之前重新打开索引。在此期间,索引对于读和写操作都不可用。
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "forcemerge" : { "max_num_segments": 1 } } } } } }4. Freeze
此操作可处于:Cold phase;
- 冻结索引以最小化其内存占用;
- 冻结一个索引将关闭该索引,并在同一个API调用中重新打开它。这意味着在短时间内不分配初选。在主节点被分配之前,集群将呈现红色。这个限制可能在将来被删除。
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "cold": { "actions": { "freeze" : { } } } } } }5. Ready only
此操作可以处于:Warm phase;
- 此操作会让索引变成只读;
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "readonly" : { } } } } } }6. Rollover
此操作可允许处于:Hot phase;
- 当现有索引满足其中一个滚动条件时,将别名 rollover 到新索引;
要想启动 rollover,索引必须符合以下要求:
- 索引名称必须符合正则表达式 “^.*-\d+$”,例如 my_index-000001;
- index.lifecycle.rollover_alias 配置上索引别名;
- 索引别名配置为指向写索引;
Options 可选项,必须指定一个配置项,空的 rollover 操作是不合法的;
- max_age:距离索引创建后的最大时间间隔;
- max_docs:触发器在达到指定的最大文档数后会 rollover。自上次刷新以来添加的文档不包括在文档计数中。
- max_size:触发器在索引达到一定大小时 rollover。这是索引中所有 primary shard 的总大小。副本不计入最大索引大小。 :::info
要查看当前索引大小,请使用 _cat indexes API。pri.store.size 值显示所有主碎片的合并大小。 :::
示例:
PUT my_index-000001 { "settings": { "index.lifecycle.name": "my_policy", "index.lifecycle.rollover_alias": "my_data" }, "aliases": { "my_data": { "is_write_index": true } } }7. Set priority
此操作可处于:Hot、Warm、Cold phase;
- 一旦策略进入热、温或冷阶段,就设置索引的优先级。在节点重启后,优先级较高的索引会在优先级较低的索引之前恢复。
一般来说,热阶段的索引值应该是最高的,冷阶段的索引值应该是最低的。例如:热阶段为100,暖阶段为50,冷阶段为0。没有设置此值的索引的默认优先级为1。
Options 可选项:
- priority:(必选)索引的优先级。必须大于等于0。设置为 null 以删除优先级。
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "set_priority" : { "priority": 50 } } } } } }8. Shrink
此操作可处于:Warm phase;
- 将索引设置为只读,并将其压缩为具有更少主碎片的新索引。新索引的名称采用 shrink-<原始索引名称> 的形式。例如,如果源索引的名称是 logs,那么压缩索引的名称就是 shrink-logs。
收缩操作将索引的所有主碎片分配给一个节点,以便它可以调用 Shrink API 来收缩索引。收缩后,它将指向原始索引的别名转换为新的收缩索引。
Option 可选项:
- number_of_shards:(必选)要缩小到的碎片数。必须是源索引中碎片数量的因数。
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "shrink" : { "number_of_shards": 1 } } } } } }9. Unfollow
此操作可处于:Hot、Warm、Cold phase;
- 当 rollover 和 shrink 操作应用于追随者索引时,将自动触发此操作。
示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "hot": { "actions": { "unfollow" : {} } } } } }10. Wait for snapshot
此操作可处于:Delete phase;
- 在删除索引之前,等待执行指定的SLM策略。这确保了已删除索引的快照可用。
- Option 可选项:
- policy:(必选)删除操作应该等待的SLM策略的名称;
- 示例:
PUT _ilm/policy/my_policy { "policy": { "phases": { "delete": { "actions": { "wait_for_snapshot" : { "policy": "slm-policy-name" } } } } } }
五、用 ILM 管理现有 Index
如果之前使用 Curator 或其他工具来管理周期性的索性,有两个方法迁移到 ILM 来管理:
将现有索引迁移到 ILM 进行管理的最简单办法,是配置一个索引模板,将策略应用到新的索引。一旦当前的写索引被 ILM 管理,你就可以手动地将策略应用到旧索引上;
为旧索引应用一个忽略 rollover action 的策略,因为 rollover 都是用于管理新数据导入的,因此 rollover 不适用于旧索引;
应用于现有索引的策略会将每个阶段的 min_age 与索引的原始创建日期进行比较,并且可能会立即进行多个阶段。如果你的策略执行诸如 Force merge 之类的资源密集型操作,那么当你j将索引迁移到 ILM 时,你绝对不希望同时有许多索引执行这些操作。
那么可以在策略中为现有索引指定不同的 min_age 值,或者设置 index.lifecycle.origination_date 控制索引年龄的计算方式。
一旦所有 ILM 管理的索引过期并被删除,那么就可以删除用于管理它们的策略。
2. Reindex into a managed index
- 对现有索引应用策略的另一种方法是将数据重新索引到一个 ILM 管理的索引中;
以下情况可以这么做:
- 当创建的周期性索引只有少量数据时,可能会导致 shard 数量过多;
- 不断将数据索引到相同的索引,可能会导致碎片过大或性能问题;
你首先需要设置一个新的被 ILM 管理的索引:
- 更新索引模板以包含必要的 ILM 设置;
- 创建一个初始索引作为写索引来启动;
- 停止对旧索引的写入,并使用指向引导索引的别名为新文档建立索引;
通过减少 ILM 轮询间隔,以确保在等待 rollover check 时索引不会增长得太大。默认情况下,ILM 每10分钟检查一次 rollover 情况。
#每分钟检查一次,看看是否需要执行ILM操作,如 rollover PUT _cluster/settings { "transient": { "indices.lifecycle.poll_interval": "1m" } }使用 Reindex API 重新索引数据。如果希望按照原始索引的顺序对数据进行分区,可以运行单独的重新索引请求。
- 如果想要文档保留其原始 id,而不使用自动生成的文档 id,并且从多个源索引做 ReIndex,那么可能需要执行额外的处理以确保文档 id 不会冲突。
一种方法是在 reindex 调用中使用脚本将原始索引的名称追加到文档 ID 的后面。
POST _reindex { "source": { "index": "mylogs-*" #-----------1 }, "dest": { "index": "mylogs", "op_type": "create" #-----------2 } } # 1. 匹配现有索引,使用正则模式可以从多个源索引中 ReIndex; # 2. 如果来自多源索引的文档中有相同的 ID,则停止 ReIndex。建议这样做是为了防止在不同源索引中的 # 文档具有相同的 ID 时,意外覆盖文档;当 ReIndex 完成时,将 ILM 轮询间隔设置回默认值,以防止在主节点上不必要的负载;
PUT _cluster/settings { "transient": { "indices.lifecycle.poll_interval": null } }继续使用相同的别名索引新数据;
- 使用索引别名进行查询时,会搜索新数据,以及之前 ReIndex 导入过来的旧数据;
- 一旦验证了所有 ReIndex 导入过来的数据,都在 ILM 管理的索引中可用后,就可以安全删除旧索引了;

若有收获,就点个赞吧
0 人点赞
