1. 为什么不用数据库做搜索呢?
系统数据大多数都是存储在数据库里面的,比如电商网站的商品信息、招聘网站的职位信息、新闻网站的新闻信息等等。
:::danger 那么,要实现电商网站内部的搜索功能的话,完全可以考虑使用数据库去进行搜索,为什么还需要使用搜索引擎 ElasticSearch 呢? :::
- 情况一:如果每条记录的指定字段的文本,可能会很长,比如“商品描述”字段的长度,有长达数千个,甚至数万个字符,这个时候,每次都要对每条记录的所有文本进行扫描,去进行判断:你包不包含我指定的这个关键词(比如说“牙膏”);
- 情况二:不能将搜索词拆分开,尽可能去搜索更多的符合你期望的结果,比如输入“生危机”,就搜索不出来“生化危机”;
用数据库来实现搜索,是不太靠谱的,通常来说,性能会很差。
2. 什么是全文检索、倒排索引、Lucene?
假设有100万条文本数据,将100万条数据进行合理的拆分,假设变成1000万个词语,用这些词语建立一个索引表,将拆分的关键词和文本数据建立关联,这就是倒排索引;
将搜索关键词去倒排索引表进行检索,找到匹配的词语后,会返回关联的文本记录,然后只需要对有限的文本进行检索就可以了,这就是全文检索。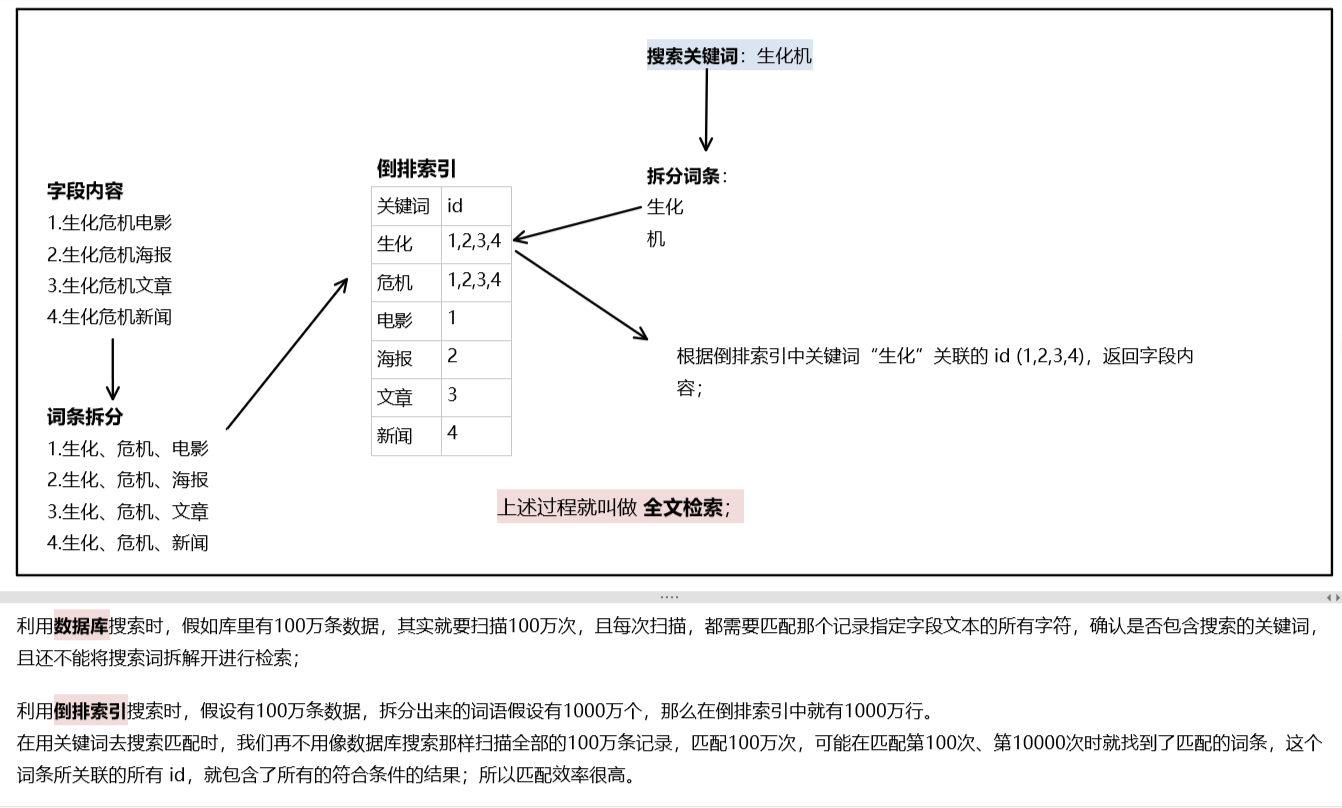
Lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引,以及进行搜索的代码,包含各种算法;直接基于 lucene 开发,非常复杂,实现一些简单的功能需要写大量的 java 代码。
3. 什么是 ElasticSearch?
Elasticsearch 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
3.1 适用场景
- 维基百科:全文检索,高亮,搜索推荐;
- 搜狐新闻:用户行为日志(点击、浏览、收藏、评论)+ 社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好、坏、热门、垃圾、鄙视);
- Stack Overflow:程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案;
- GitHub:搜索上千亿行代码;
- 电商网站:搜索商品;
- 日志数据分析:logstash 采集日志,ES 进行复杂的数据分析(elasticsearch+logstash+kibana);
BI系统,商业智能,Business Intelligence:比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
3.2 功能
分布式的搜索引擎和数据分析引擎
- 搜索:百度,网站的站内搜索;
- 数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些;
- 全文检索,结构化检索,数据分析
- 全文检索:我想搜索商品名称包含牙膏的商品;
- 结构化检索:我想搜索商品分类为日化用品的商品都有哪些;
- 部分匹配、自动完成、搜索纠错、搜索推荐;
- 数据分析:我想计算每一个商品分类下有多少个商品;
- 对海量数据进行近实时的处理
- 分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索;
- 海量数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了;
- 近实时:两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级;
4. ElasticSearch 核心概念
4.1 Document 文档
ES 中的最小数据单元,一个 document 可以是一条客户数据,一条商品分类数据,一条订单数据,通常用 JSON 数据结构表示,每个 index 下的 type 中,都可以去存储多个 document。一个 document 里面有多个 field,每个 field 就是一个数据字段。
# 文档的元素据{"_index" : "movies","_type" : "_doc","_id" : "1","_score" : 14.69302,"_source" : {"year" : 1995,"@version" : "1","genre" : ["Adventure","Animation","Children","Comedy","Fantasy"],"id" : "1","title" : "Toy Story"}}
- ElasticSearch 是面向文档的,文档是所有可搜索数据的最小单位;
- 文档会被序列化成 JSON 格式,保存在 ElasticSearch 中;
- 每个文档都有一个 Unique ID,可以指定 ID,可以 ES 自动生成;
文档的元素据,用于标注文档的相关信息
- _index:文档所属的索引名
- _type:文档所属的类型名
- _score:相关性打分
- _id:文档唯一 id
- _source:文档的原始 Json 数据
- _all:整合所有字段内容到该字段,已被废除
- _version:文档的版本信息
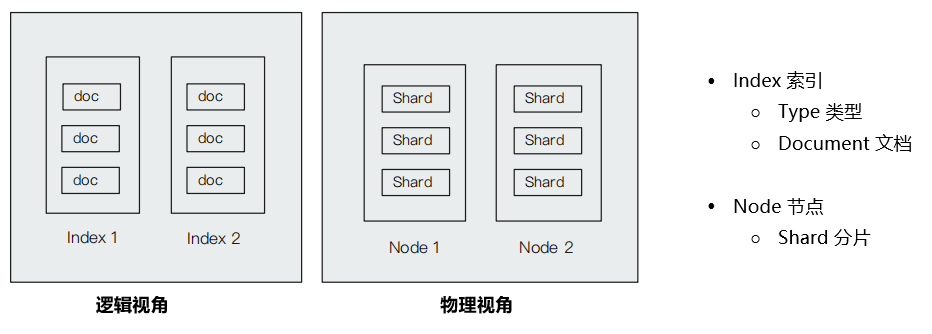
4.2 Index 索引
索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个 index 包含很多 document,一个 index 就代表了一类类似的或者相同的 document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品 document。{"moives" : {"settings" : {"index" : {"creation_data" : "1552737458543","number_of_shards" : "2","number_of_replicas": "0","uuid" : "Qnd7lMrNqPgdaeJ9or0tfQ","version" : {"created" : "6060299"},"provided_name" : "movies"}}}}
索引是文档的容器,是一类文档的结合
- Index 体现了逻辑空间的概念:每个索引都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型;
- Shard 体现了物理空间的概念:索引中的数据分散在 Shard 上;
索引的 Mapping 与 Settings
在 7.0 之前,一个 Index 可以设置多个 Types;
6.0 开始,Type 已经被 Deprecated。 :::tips 7.0 开始,一个索引只能创建一个 Type - “_doc”; :::
4.4 Primary Shard 主数据分片
shard:主数据分片,单台机器无法存储大量数据,es 可以将一个 Index 索引中的数据切分为多个 shard,分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。
主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点智商;
副本,用以解决数据高可用的问题。副本是主分片的拷贝;
- 副本分片数目,可以动态的调整;
- 增加副本数目,还可以在一定程度上提高服务的可用性(读操作的吞吐); :::tips es 规定,primary shard 和 replica shard 不能在同一个节点上,最小的高可用就是2台机器,primary shard 和 replica shard 均匀散落在两台机器,两台机器都会有部分 primary shard 和 replica shard,互为主备。 :::
4.6 节点
- 节点是一个 ElasticSearch 的实例
- 本质上是一个 JAVA 进程
- 一个机器上可以运行多个 ES 进程,但是生产环境一般建议一台机器只运行一个 ES 实例;
- 每一个节点都有名字,通过配置文件配置,或启动时候
-E node.name=node1指定; 开发环境中一个节点可以承担多种角色,但是生产环境中,应该设置节点为单一的角色;
- Master node
- 当第一个节点启动的时候,他会将自己选举成 Master 节点;
- 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息;
- 集群状态,维护了一个集群的必要信息:所有节点的信息、所有索引和其相关的 Mapping 与 Setting 信息、分片的路由信息;
- Master-eligible node
- 每个节点启动后,默认就是一个 master-eligible 节点的角色;
- master-eligible 节点可以参加选举流程,成为 Master 角色的节点;
- Data node
- 负责保存分片数据,在数据扩展上起了重要作用;
- Coordinating node
- Master node
Green:主分片与副本都正常分配;
- Yellow:主分片全部正常分配,有副本分片未能正常分配;
- Red:有主分片未能分配;
5. ES核心概念 vs. 数据库核心概念
| 数据库 | ES |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Filed |
| Schema | Mapping |
| SQL | DSL |

若有收获,就点个赞吧
0 人点赞
