1. 索引过程

- 文档 document 由 分词器 Analyzer 组件对其执行一些操作将其拆分为 token/term;
- Analyzers 组件以某些定界符(有默认定界符,例如空格,句号等)将它们分割开获取 token,再对每个 token 应用特定的过滤器。经过分析的这些标记称为 term;
- 然后将这些 term 针对该字段存储在倒排列表中;
2. 正排索引和倒排索引
- 正排索引 - 文档 ID 到文档内容和单词的关联
- 倒排索引 - 单词到文档 ID 的关系
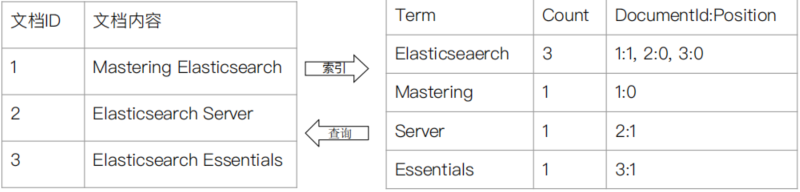
3. 倒排索引的核心组成
- 两个组成部分
- 单词词典 (Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系;
- 单词词典一般较大,可以通过 B+ 树或哈希拉链法实现,以满足高性能的插入与查询;
- 倒排列表 (Posting List),记录了单词对应的文档结合,由以下的倒排索引项组成
- 文档 ID
- 词频 TF - 该单词在 Index 下所有文档中出现的次数,用于相关性评分
- 位置 (Position) - 单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移 (Offset) - 记录单词的开始结束位置,实现高亮显示
- 单词词典 (Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系;
4. 举例
针对单词 Elasticsearch 进行搜索,在倒排索引的单词词典中匹配到 Term (Elasticsearch),获得对应的倒排列表: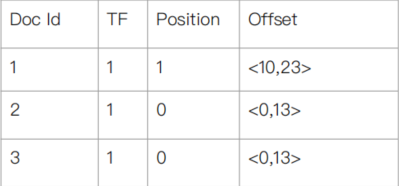
就得到了符合结果的 doc1、doc2、doc3。
:::tips
- Elasticsearch 的 JSON 文档对象中的每个字段,都有自己的倒排索引
- 可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索 :::
5. 倒排索引不可变
- 倒排索引采用 不可变 设计,一旦生成,不可改变;
- 不可变性,带来的好处:
- 不需要锁来解决并发写文件的问题,提升并发能力,避免锁带来的性能问题;
- 倒排索引文件数据不变,一旦读入内核的文件系统缓存,便留在那里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能;
- 数据可以被压缩,节省 cpu 和 IO 开销;
- 带来的坏处:
- 如果需要让一个新的文档可以被搜索,需要重建整个索引;

若有收获,就点个赞吧
0 人点赞
