1. 分词和分词器
- Analysis 分词:把全文本转换成一系列单词
- Analyzer 是通过 Analyzer 来实现的
- 可使用 ElasticSearch 内置的分析器,或按需定制化分析器
- 除了在数据写入时转换词条,匹配 Query 语句时也需要用相同的分析器对查询语句进行分析
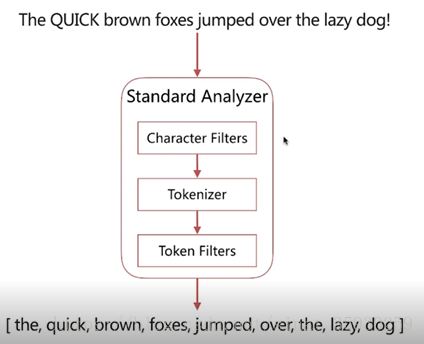
2. 分词器的组成
| 组成 | 功能 |
|---|---|
| Character Filters | 针对原始文本进行处理,比如去除 html 标记符 |
| Tokenizer | 将原始文本按照一定规则切分为单词 |
| Token Filters | 针对切分的单词进行加工,比如转为小写、删除 stopwords、增加同义词 |
- 分词器组成的调用是有顺序的:
3. Analyze API
es 提供了一个测试分词的 api 接口,方便验证分词效果,endpoint 是 _analyze;
这个 api 具有以下特点:
- 可以直接指定 analyzer 进行测试;
- 可以直接指定索引中的字段进行测试;
- 可以自定义分词器进行测试;
3.1 直接指定analyzer进行测试
analyzer 表示指定的分词器,这里使用 es 自带的分词器 standard,text 用来指定待分词的文本。POST _analyze{"analyzer": "standard","text": "hello world"}
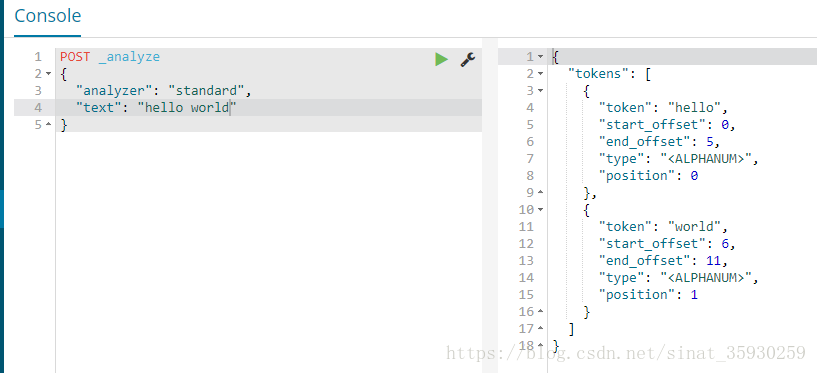
从结果中可以看到,分词器将文本分成了 hello 和 world 两个单词。
3.2 指定索引中的字段进行测试
应用场景:当创建好索引后发现某一字段的查询和预期不一样,就可以对这个字段进行分词测试。
POST text_index/_analyze{"field": "username","text": "hello world"}
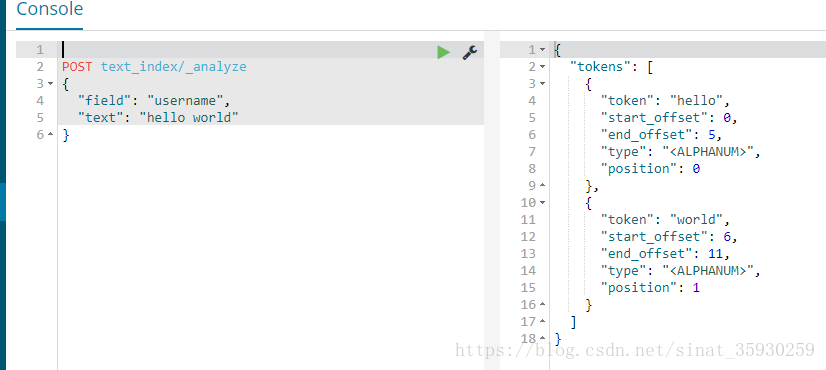
当没有指定分词器的时候默认使用 standard。
3.3 自定义分词器进行测试
POST _analyze{"tokenizer": "standard","filter": [ "lowercase" ],"text": "Hello World"}
根据分词的流程,首先通过 tokenizer 指定的分词方法 standard 进行分词,然后会经过 filter 将大写转化为小写。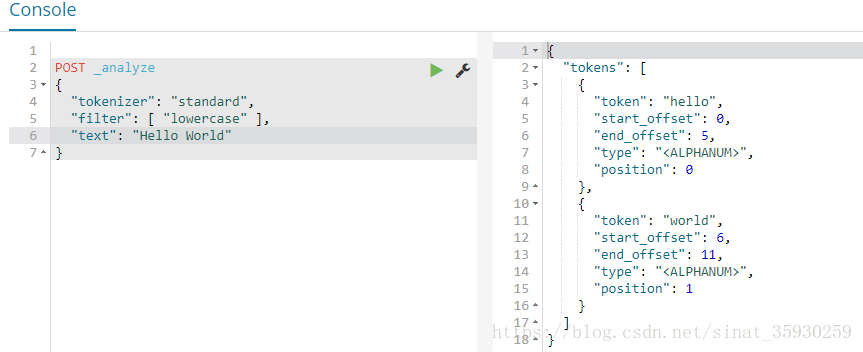
4. ES 的内置分词器
4.1 Standard Analyzer
默认分词器,具有按词切分、支持多语言、小写处理的特点。 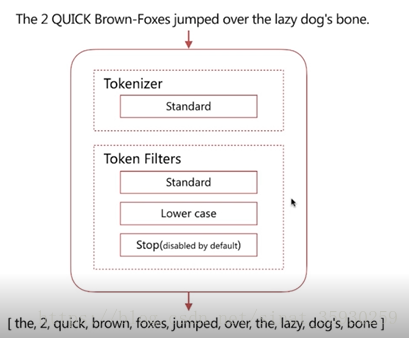
可以看到,standerd 将 stop word 默认关闭了,也就是这些词还是会在分词后保留。
stop word 就是例如 and、the、or 这种词,可以通过配置将它打开。其实搜索引擎应该将这些 stop word 过滤掉,这样可以减少压力的同时保证搜索的准确性。
4.2 Simple Analyzer
具有特性是:按照非字母切分(数字,符号被过滤掉)、小写处理。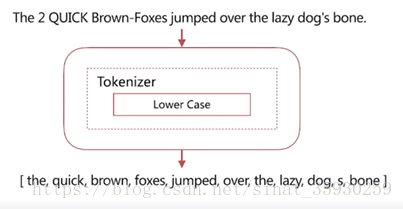
可以看到它将非字母的字符切掉了,例如横线、标点、数字都被干掉了。
4.3 Whitespace Analyzer
具有的特性是:按照空格切分,不转小写。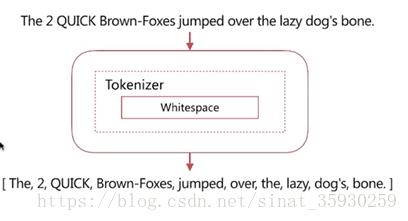
可以看到它按照空格切分,并且没有进行小写转化。
4.4 Stop Analyzer
具有的特性是:将 stop word 停用词过滤掉,小写处理。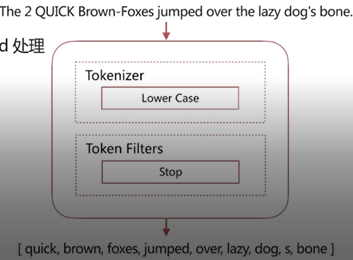
4.5 Keyword Analyzer
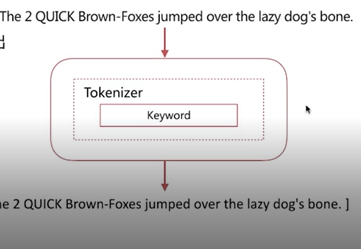
4.6 Pattern Analyzer
具有的特性是:通过正则表达式自定义分隔符,默认是 \W+,即非字词的符号作为分隔符,小写转化 。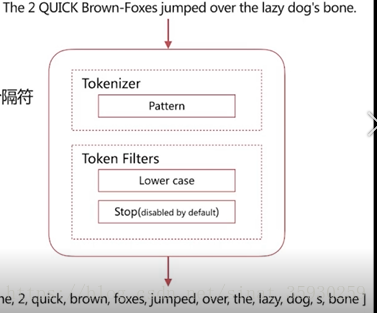
4.7 Language Analyzer
具有的特性是:提供了 30+ 常见语言的分词器。
5. 中文分词器
中文分词是指讲一个汉字序列切分成一个一个独立的词。在英文中,单词间以空格作为自然分界符,汉语中词没有一个形式上的分界符。
5.1 常见中文分词器
- IK
- 可以实现中英文单词的分词,支持ik_smart、ik_maxword等模式;可以自定义词库,支持热更新分词词典。
- jieba
- python中最流行的分词系统,支持分词和词性标注;支持繁体分词、自定义词典、并行分词。
基于自然语言的分词系统:
这种分词系统可以通过创建一个模型,然后该模型经过训练可以通过根据上下文进行合理的分词,常见的有:
- Hanlp
- 有一系列模型预算法组成的 Java 工具包,目标是普及自然语言处理在生产环境中的应用。
- THULAC
- 清华大学推出,具有中文分词和词性标注的功能。

若有收获,就点个赞吧
0 人点赞
