1. 文档的 CURD
| Index | PUT my_index/_doc/1 {“user”: “mike”, “comment”: “You know, for search”} |
|---|---|
| Create | PUT my_index/_create/1 {“user”: “mike”, “comment”: “You know, for search”} POST my_index/_doc (不指定 ID,自动生成) {“user”: “mike”, “comment”: “You know, for search”} |
| Read | GET my_index/_doc/1 |
| Update | POST my_index/_update/1 { “doc”: {“user”: “mike”, “comment”: “You know, ElasticSearch”} } |
| Delete | DELETE my_index/_doc/1 |
- Type 名,7.x 以后,约定都用 _doc;
- Create,如果 ID 已经存在,会失败;
- Index,如果 ID 不存在,创建新的文档。否则,先删除现有文档,再创建新的文档,版本会增加;
- Update,文档必须已经存在,更新只会对相应字段做增量修改;
- Delete,不会立刻物理删除,只会将其标记为 deleted 状态,当数据越来越多的时候,在后台自动删除(细节内容参考:分片内部原理 )
1.1 Create 一个文档
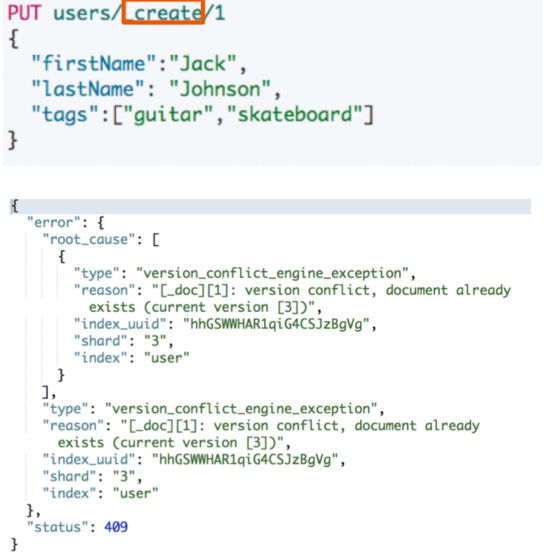
- 支持自动生成文档 ID 和指定文档 ID 两种方式;
- 通过调用 “POST my_index/_doc”,系统会自动生成 document id;
- 使用 PUT my_index/_create/1 创建时,URI 中显示指定 _create,此时如果该 id 的文档已经存在,操作失败;
1.2 Index 一个文档
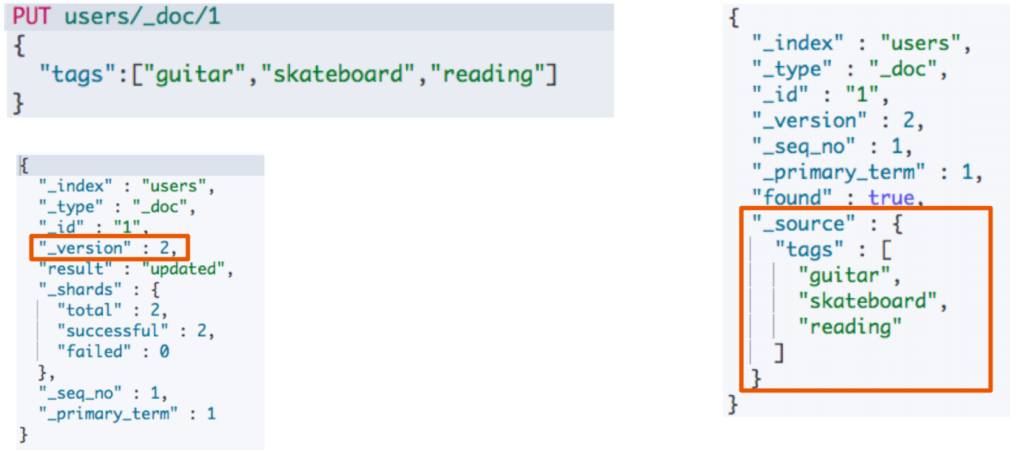
- Index 和 Create 不一样的地方:如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引。版本信息 +1;
document 一旦被索引是不可变的,如果要修改 document 的内容,可以使用 Index 对 document 重新建立索引,相当于全量替换,旧的 document 被标记为 deleted,ES 会在后台适当的时候自动删除;
Index 全量替换修改 document,每次的执行流程是这样的:
- 应用程序先发起一个 get 请求,获取到 document,展示到前台界面,供用户查看和修改;
- 用户在前台界面修改数据,发送到后台;
- 后台代码,会将用户修改的数据在内存中进行执行,然后封装好修改后的全量数据;
- 然后发送 PUT 请求,到 es 中,进行全量替换;
- es 将老的 document 标记为 deleted,然后重新创建一个新的 document;
1.3 Update 一个文档
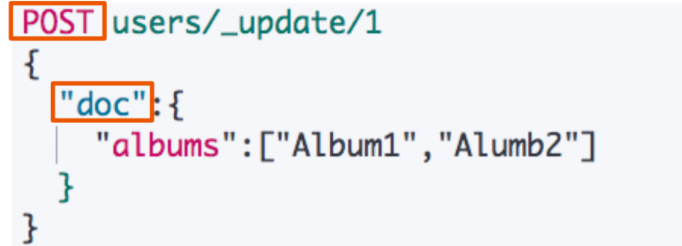
- Update,文档必须已经存在,更新只会对相应字段做增量修改;
- Update 方法不会删除原来的文档,而是实现真正的数据更新;
- POST 方法 / Payload 需要包含在 “doc” 中;
- Update 可以在原文档的基础上增加字段;
POST users/_update/1/{"doc":{"post_date" : "2019-05-15T14:12:12","message" : "trying out Elasticsearch"}}
看起来,好像比较方便,每次就传递少数几个发生修改的 field 即可,不需要将全量的 document 数据发过去;
:::tips
那么 Partial Update 的实际内部原理是怎样的,它的优点是什么呢?
:::
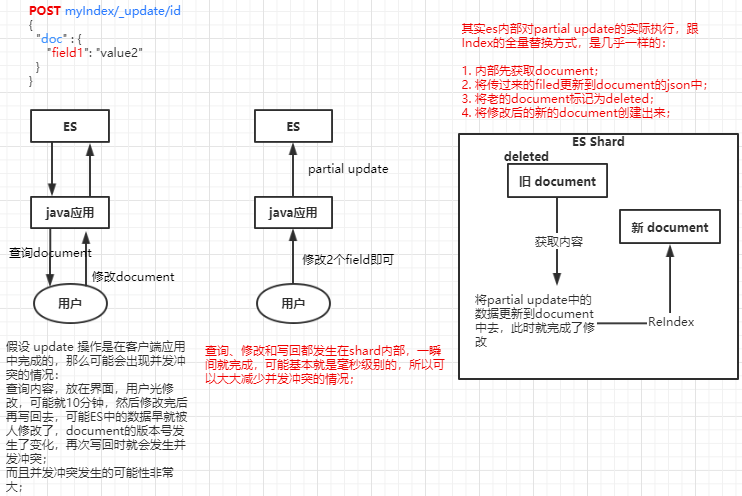
- Partial Update 相较于全量替换的优点:
- 所有的查询、修改和写回操作,都发生在 ES 中的一个 shard 内部,避免了所有的网路数据传输的开销(减少了2次网络请求),大大提升了性能;
- 减少了查找和修改中的时间间隔,可以有效减少并发冲突的情况;
1.4 Get 一个文档

- 找到文档,返回 HTTP 200
- 文档源信息
- _index / _type /
- 版本信息,同一个 ID 的文档,即使被删除,Version 号也会不断增加;
- _source 中默认包含了文档的所有原始信息;
- 文档源信息
- 找不到文档,返回 HTTP 404;
2. Bulk API 批量增、删、改
- 支持再一次 API 调用中,对不同的索引进行操作;
- 支持四种类型操作
- Index,普通的 put 操作,可以是创建文档,也可以是全量替换文档;
- Create,PUT /index/_create/id 操作,强制创建文档;
- Update,执行的 partial update 部分更新操作;
- Delete,删除一个文档,只要一个 json 串就可以了;
- 可以在 URI 中指定 Index,也可以在请求的 Payload 中进行;
- 操作中单挑操作失败,并不会影响其他操作;
- 返回结果包括了每一条操作执行的结果;
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test2", "_id" : "2"} }
{ "field1" : "value3" }
{ "update" : { "_index" : "test2", "_id" : "2"} }
{ "doc" : { "field2" : "value2"} }
{ "delete" : { "_index" : "test2", "_id": "2" } }
- 除了 delete 操作,其他每一个操作需要两行,要两个 JSON 串,语法如下:
元素据:{ “action” : { “metadata” }}
document 中的真实数据:{ “data” }
Bulk API 对 JSON 的语法,有严格的要求:
- 每个 JSON 不能像 JSON 对象那样进行格式换行,一个 JSON 只能作为一个字符串只能放在一行;
- 同时一个 JSON 串和一个 JSON 串之间,必须有一个换行;
Bulk Size 最佳大小
- bulk request 会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的 bulk size;
- 一般从 1000~5000 条数据开始,尝试逐渐增加。
- 另外,如果看大小的话,最好是在 5~15 MB 之间;
3. mget 批量读取
批量查询的好处:
- 就是一条一条的查询,比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的;
- 如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的性能开销缩减100倍;
GET 请求进行查询,在 Body 中的 docs 数组里面,用 _index、_id 来定位 document; ```json GET _mget { “docs”: [ {
"_index": "user", "_id": 1}, {
"_index": "comment", "_id": 1} ] }
URI中指定index
GET /test/_mget { “docs” : [ { “_id” : “1” }, { “_id” : “2” } ] }
指定返回的document内容部分
GET /_mget { “docs” : [ { “_index” : “test”, “_id” : “1”, “_source” : false }, { “_index” : “test”, “_id” : “2”, “_source” : [“field3”, “field4”] }, { “_index” : “test”, “_id” : “3”, “_source” : { “include”: [“user”], “exclude”: [“user.location”] } } ] }
- mget 的重要性
- 一般来说,在进行查询的时候,如果一次性要查询多条数据的话,那么一定要用 batch 批量操作的 api;
- 尽可能减少网络开销次数,可能可以将性能提升数倍,甚至数十倍,非常非常之重要;
<a name="BQQ7T"></a>
# 4. msearch 批量条件查询
```json
### msearch 操作
POST kibana_sample_data_ecommerce/_msearch
{}
{"query" : {"match_all" : {}},"size":1}
{"index" : "kibana_sample_data_flights"}
{"query" : {"match_all" : {}},"size":2}
5. 常见的错误返回
| 问题 | 原因 |
|---|---|
| 无法连接 | 网络故障或集群挂了 |
| 连接无法关闭 | 网络故障或节点出错 |
| 429 | 集群过于繁忙 |
| 4xx | 请求体格式有错 |
| 500 | 集群内部错误 |

若有收获,就点个赞吧
0 人点赞
