1. Script 简介
- ES 默认的脚本语言是 Painless,也同时支持其他集中语言编写的脚本:

2. 如何使用 Script
2.1 脚本语法
"script": {"lang": "...","source" | "id": "...","params": { ... }}
- 参数解释:

- 在 ES API 中,只要是支持 Script 的,都使用相同的脚本语法。
- 例如,除了在 Script Processor 中使用脚本处理文档,还可以在 Request Body Search 的 script_fields 中使用脚本:
PUT my_index/_doc/1 { "my_field": 5 } #返回结果中会对索引下的所有文档进行 my_field*2 的计算,返回结果保存在 _source.my_doubled_field 中 GET my_index/_search { "script_fields": { "my_doubled_field": { "script": { "lang": "expression", "source": "doc['my_field'] * multiplier", "params": { "multiplier": 2 } } } } } #####返回结果的部分内容 "hits" : [ { "_index" : "my_index", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "fields" : { "my_doubled_field" : [ 10.0 ] } } ]
- 例如,除了在 Script Processor 中使用脚本处理文档,还可以在 Request Body Search 的 script_fields 中使用脚本:
:::info ES 遇到一个新脚本时,将对其进行编译并将编译后的版本存储在缓存中。编译可能是一个繁重的过程。如果我们有相同逻辑的脚本只是参数不一样的时候,应该将它们以参数的形式传入脚本,而不是将值硬编码到脚本本身中。 :::
例如,如果你想让一个字段值乘以不同的乘数,不要在脚本中硬编码乘数,每一次乘数的改变都必须重新编译;
"source": "doc['my_field'] * 2"更推荐的方式是,命名一个参数,在 params 选项中以参数的形式传递进脚本,这样脚本只会编译一次,然后保存在 Script Cache 中;
- ES 默认一分钟最多编译 15 个脚本,如果在短时间内编译了太多的脚本,ES 会抛出 circuit_breaking_exception 错误,并拒绝编译新的脚本;
- 可以通过修改 script.max_compilations_rate 配置,改变每分钟最大允许编译的脚本个数;
"source": "doc['my_field'] * multiplier", "params": { "multiplier": 2 }
2.2 inline scripts
- 当脚本中 source 只有很简单的内容,不涉及参数变化等复杂逻辑可以直接在 script 后使用字符串而不是对象:
```json
下面两个脚本是等价的
“script”: “ctx._source.likes++”
“script”: { “source”: “ctx._source.likes++” }
<a name="vU7Cs"></a>
## 2.3 stored scripts
我们可以将脚本保存在集群状态中,然后使用它的时候只需要指定脚本 ID。
:::info
- 如果启用了 Elasticsearch security 特性,就必须拥有以下权限来创建、检索和删除存储的脚本;
- cluster:all or manage
:::
- 脚本保存
- 保存脚本需要使用 _scripts/{id} 的 POST 请求
```json
POST _scripts/calculate-score
{
"script": {
"lang": "painless",
"source": "Math.log(_score * 2) + params.my_modifier"
}
}
查询脚本
- 查询脚本需要使用 _scripts/{id} 的 GET 请求
GET _scripts/calculate-score
- 查询脚本需要使用 _scripts/{id} 的 GET 请求
使用保存的脚本
- 后续再使用脚本的时候就可以指定 ID,而不是再次编写脚本了
GET twitter/_search { "query": { "script_score": { "query": { "match": { "message": "some message" } }, "script": { "id": "calculate-score", "params": { "my_modifier": 2 } } } } }
- 后续再使用脚本的时候就可以指定 ID,而不是再次编写脚本了
删除脚本
DELETE _scripts/calculate-score
2.4 脚本缓存
- 默认情况下,所有脚本都被缓存,因此它们只需要在更新发生时重新编译;
- 默认情况下,脚本没有开启时间上的有效期限,但是可以通过 script.cache.expire 来更改;
- 可以通过 script.cache.max_size 来配置缓存的大小,默认大小是 100;
- 脚本的大小被限制为 65,535 字节,可以通过 script.max_size_in_bytes 来改变这个配置;
- 如果脚本真的是很大的话,可以考虑使用 native script engine;
3. 脚本中访问文档字段和特殊变量
根据脚本使用的地方不同,它们可以访问的变量的文档字段是不同的。
3.1 更新操作中脚本访问数据
在 update,update-by-query 或 reindex API 中使用的脚本将有权访问显示以下内容的 ctx 变量。
3.2 在搜索和聚合中脚本访问数据
- 在使用 Request Body Search 的 script_fields 进行搜索的情况时,只有当命中匹配的文档时才会执行一次脚本;
- 其他情况下的搜索,以及聚合分析中使用 script 时,会对每一个可能符合条件的文档都执行一次,这使得脚本执行的次数可能会是百万、千万,这取决于你的文档数量;所以要求脚本必须足够的效率;
- 官方建议使用 doc values,_source field,或者 stored field 从脚本访问字段值;
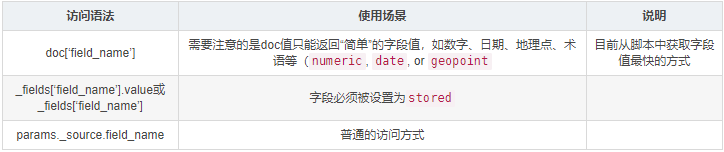
三种访问方式的比较:
- _source **v.s** stored field
- _source 本身就是一个特殊的 stored 字段,它的性能和其他 stored 字段的性能很接近;
- 使用 stored 字段而不是 _source 字段取值的场景是,当 _source 非常大的时候,访问的却只是几个很小的 stored 字段而不是整个 _source 时,那么直接使用 stored field 成本更小些;
- doc values **v.s** _source
- _source **v.s** stored field
目前从脚本中获取字段值最快的方式是使用 doc[‘field_name’] 格式,此方法会从 doc values 中检索字段数据,但是需要注意的是 doc values 只能返回“简单”的字段值,如数字、日期、地理点、terms 词项等,如果字段是多值的,则只能返回这些值的数组。它不能返回 JSON 对象。
- doc values 默认在所有类型的字段上开启,除了被分词的 text 字段;
- 默认情况下,如果 doc[‘field’] 对 可分词的 text 字段使用,会报如下的错误:{“reason”: “Fielddata is disabled on text fields by default. Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.”}
- 如果启用了 fielddata,doc[‘field’] 语法也可以用于可分词的 text 字段,但是要注意:在 text 字段开启 field 需要将所有分词 terms 加载到 JVM Heap,这在内存和 CPU 的性能方面将付出很大的代价。一般情况下,不推荐这样做;
```json
PUT my_index/_doc/1?refresh
{
“cost_price”: 100,
“product”: “clothes”
}
1. 对数字类型进行操作
GET my_index/_search { “script_fields”: { “sales_price”: { “script”: { “lang”: “expression”, “source”: “doc[‘cost_price’] * markup”, “params”: {
} } } } }"markup": 0.2#返回结果的部分内容
{ “_index” : “my_index”, “_type” : “_doc”, “_id” : “1”, “_score” : 1.0, “fields” : { “sales_price” : [ 20.0 ] } }
2. 对text类型进行操作
GET my_index/_search { “script_fields”: { “name”: { “script”: { “lang”: “expression”, “source”: “doc[‘product’]” } } } }
执行第二个脚本对text字段进行操作,出现错误
:::tips
- 如果 field 在索引 Mapping 中不存在,那么 doc['field'] 语法将会抛出一个错误;
- 在 Painless 脚本,提供了 doc.containskey('field') 语法来避免这个问题,它会在访问 doc 前检查字段是否存在;
- 在 expression 脚本,没有提供类似的字段是否存在的检查,所以要注意可能字段不存会抛出错误;
:::
<a name="tmmZm"></a>
### 2) _source field
- 使用 params._source.field_name 语法,可以访问文档中 _source 源数据;
- 可以使用 params._source.name.first 访问对象类型的字段中所有属性;
```json
#mapping设置两个text字段
PUT my_index
{
"mappings": {
"properties": {
"first_name": {
"type": "text"
},
"last_name": {
"type": "text"
}
}
}
}
#插入数据
PUT my_index/_doc/1?refresh
{
"first_name": "Barry",
"last_name": "White"
}
# params._source.first_name 来访问document中 _source 数据
GET my_index/_search
{
"script_fields": {
"full_name": {
"script": {
"lang": "painless",
"source": "params._source.first_name + ' ' + params._source.last_name"
}
}
}
}
3) stored field
- 使用 params._fields[‘field_name’].value 或 params._fields[‘field_name’],可以访问在 Mapping 被设置为 “store”: true” 的字段。
- 对没有设置此参数的字段使用此方法时会抛出异常:”reason”: “cannot write xcontent for unknown value of type class org.elasticsearch.search.lookup.FieldLookup”;
#mapping中添加两个stored字段,一个普通text字段 PUT my_index { "mappings": { "properties": { "full_name": { "type": "text", "store": true }, "title": { "type": "text", "store": true }, "desc": { "type": "text" } } } } #插入数据 PUT my_index/_doc/1?refresh { "full_name": "Alice Ball", "title": "Professor", "desc": "test unstored field" } # params._fields['title'].value 访问 stored 字段 GET my_index/_search { "script_fields": { "name_with_title": { "script": { "lang": "painless", "source": "params._fields['title'].value + ' ' + params._fields['full_name'].value" } } } } #params._fields['desc'] 访问 unstored 字段会报错 GET my_index/_search { "script_fields": { "test_unstored_field":{ "script": { "lang": "painless", "source": "params._fields['desc']" } } } }
- 对没有设置此参数的字段使用此方法时会抛出异常:”reason”: “cannot write xcontent for unknown value of type class org.elasticsearch.search.lookup.FieldLookup”;
3.3 在脚本访问文档的 score
- 在 function_socre 查询中使用脚本,当实现基于脚本排序,或进行聚合分析时,可以访问 _score 变量,该变量表示文档的当前相关性得分;
```json
改变符合条件的文档的 _socre
PUT my_index/_doc/1?refresh { “text”: “quick brown fox”, “popularity”: 1 }
PUT my_index/_doc/2?refresh { “text”: “quick fox”, “popularity”: 5 }
GET my_index/_search { “query”: { “function_score”: { “query”: { “match”: { “text”: “quick brown fox” } }, “script_score”: { “script”: { “lang”: “expression”, “source”: “_score * doc[‘popularity’]” } } } } }
<a name="J2sgu"></a>
# 4. 脚本的安全问题
- 不使用 root 用户运行 ES
- root 用户的权限可能可以绕过服务器上的安全措施,所以如果 ES 检测到是以 root 身份运行,那么 Elasticsearch 会拒绝启动;
- 不直接向用户暴露 ES
- 推荐的做法是,不要直接向用户公开 Elasticsearch,而是让应用程序代表用户发出请求;
- 如果这无法做到的话,应该要有一个应用程序来对用户发出的请求进行审查;
- 如果上述都无法实现的话,最好有一些机制来跟踪哪些用户做了什么。因为很有可能用户编写了一个 _search 会使得 Elasticsearch 集群崩溃,所有的这类搜索请求都应该被认为是 bug;
- 推荐执行过程:
- 用户在搜索框中输入文本,文本将直接发送给 match、match phrase、simple query string 或其他类型搜索;
- 上述各种包含脚本的查询语法结构体,在开发阶段已经被写好在应用程序中,由应用程序去触发执行这些查询;
- 用户输入的文本被作为参数传入脚本;
- 用户操作文档的行为被应用程序限制在一个固定的结构内了
- 存在风险的执行过程:
- 用户可以随意的编写脚本、查询、_search 请求;
- 配置脚本类型:
- 默认情况下,允许执行所有脚本类型。通过修改 script.allowed_types 我们可以指定允许执行的类型;
```json
# 只允许执行内联脚本,而不允许执行存储脚本(或任何其他类型)。
script.allowed_types: inline
配置脚本上下:
- 默认情况下,允许执行所有脚本上下文;
通过修改 script.allowed_contexts 只允许一部分操作执行;
#这将只允许执行评分和更新脚本,而不允许执行aggs或插件脚本(或任何其他上下文)。 script.allowed_contexts: score, update禁用脚本上下文:
script.allowed_contexts: none

若有收获,就点个赞吧
0 人点赞
