1. ElasticSearch 的基础分布式架构
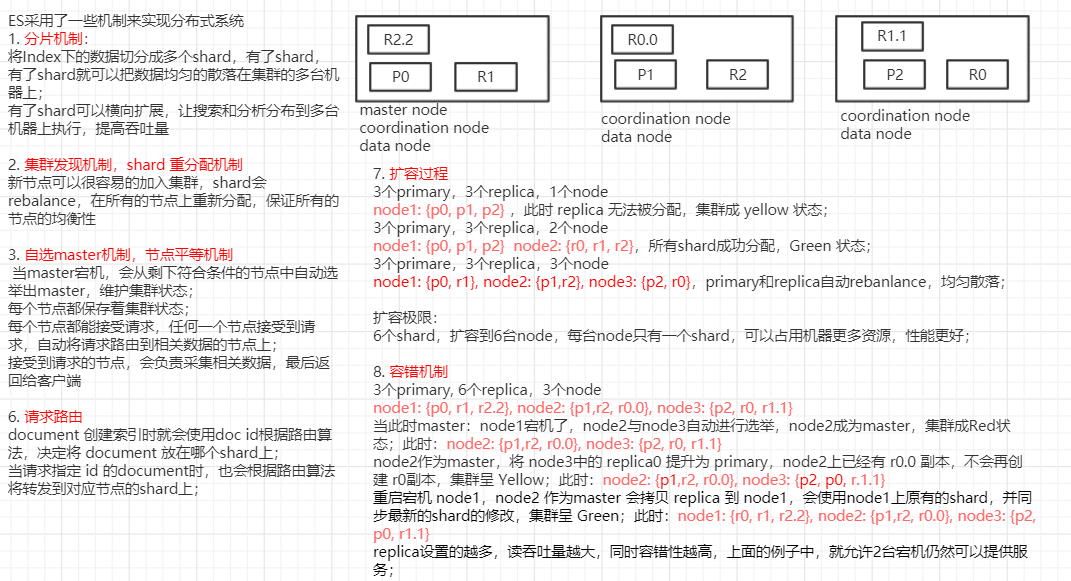
1.1 elasticsearch 隐藏了复杂的分布式机制
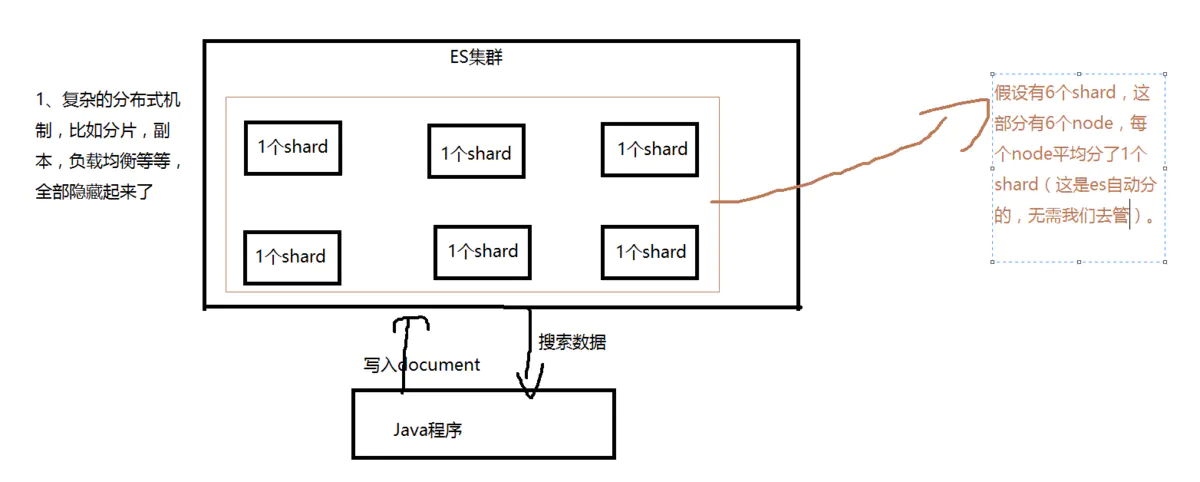
Elasticsearch 是一套分布式的系统,分布式是为了应对大数据量。它实现分布式的时候就已经将所有复杂的操作自己都实现了,对用户来说是感受不到其中复杂的分布式实现机制的。
- 分片机制
- 我们可以随随便便就将一些 document 插入到 es 集群中去了,我们没有 care 过数据怎么进行分片的,数据到哪个 shard 中去;
- 集群发现机制
- 之前做过的那个集群 status 从 yellow 转 green 的实验里,直接启动了第二个 es 进程,那个进程作为一个 node 自动就发现了集群,并且加入了进去,还接受了部分数据;
- shard 负载均衡
- 假设现在有3个节点,总共有25个 shard 要分配到3个节点上去,es 会自动进行均匀分配,以保持每个节点的均衡的读写负载请求;
- shard副本
- 没有关注怎么创建 replica;
- 请求路由
- 没有关注怎么把请求路由到有相关数据的节点上去;
- 集群扩容
- 新节点自动发现集群,且加入进去,实现扩容;
- shard重分配
- 新节点加入集群后,shard 会 rebalance,重新分配到所有节点,保证所有节点的均衡性;
1.2 elasticsearch 的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器?(考虑资金…..)
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力。(推荐。划算,还不会瓶颈)
扩容方案
假设:6台服务器,每台容纳1T数据,马上数据量要增长到8T,这时候两个方案:
(1)垂直扩容:重新购置两台服务器,每台服务器的容量是2T,替换掉老的两台服务器,那么现在是6台服务器的总容量就是:4 1T + 2 2T = 8T;
(2)水平扩容:重新购置两台服务器,每台服务器的容量是1T,直接加入到集群中去,那么现在是8台服务器,总容量就是8 * 1T = 8T。(业界几乎都采取这种方式。)
1.3 增减或减少节点时的数据 rebalance
shard 负载均衡(总有某些服务器的负载会重一些,承载的数量和请求量会大一些。当有新的节点加入集群,shard 数据会重新分配到新节点,保持平衡性);
1.4 master 节点
master 节点不用承载所有的请求,所以不会是一个单点瓶颈;
coordinating 节点负责接收客户端请求,默认所有的节点都具有 coordinating 节点的角色;
master 节点管理 es 集群的元素据:
(1)创建或删除索引
(2)增加或删除节点
默认情况下,会自动选择出一台节点,作为 master 节点;
1.5 节点平等的分布式架构
- 节点对等:每个节点都能接收所有的请求;
- 自由请求路由:任何一个节点接受到请求,自动将请求路由到有相关数据的节点上;
- 响应收集:接受到请求的节点,会负责采集相关的数据,最后返回给客户端;
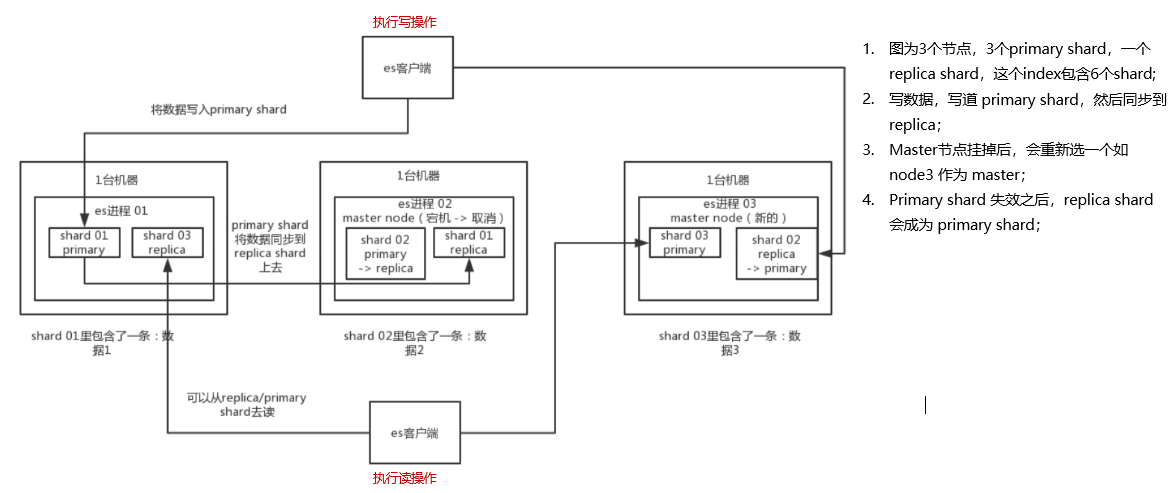
2. shard & replica 机制再次梳理
- index 包含多个 shard (es 将设置的 shard 的个数先分布式的在每个节点上创建,然后每个 shard 承载部分数据);
- 每个 shard 都是一个最小工作单元,承载部分数据。es 底层是 lucene 实现的,一个 shard 就是一个 lucene 实例,每个 shard 有完整的建立索引和处理请求的能力;
- 增减节点时,shard 会自动在 node 中负载均衡;
- shard 有两类:primary shard 和 replica shard,每个 document 肯定只存在于某一个 primary shard 以及其对应的 replica shard 中,不可能存在于多个 primary shard;
- replica shard 是 primary shard 的副本,负责容错,以及承担读请求负载;
- primary shard 的数量在创建索引的时候就固定了,replica shard 的数量可以随时修改;(有三台机器,创建索引时设置创建3个shard,如果之后有增加一台机器,是无法增加 primary shard 的,但是可以增加 replica shard 分布到新机器上)
- primary shard 的默认数量在版本 7.0 以后是1,replica 默认是1,默认有2个 shard,1个 primary shard,1个replica shard;
- primary shard 不能和自己的 replica shard 放在同一个节点上(否则节点宕机,primary shard 和副本都丢失,起不到容错的作用),但是可以和其他 primary shard 的 replica shard 放在同一个节点上;
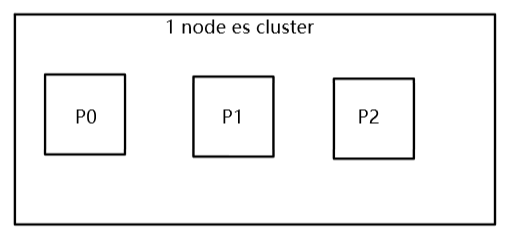
3. 图解单node环境下创建index是什么样子的
单node环境下,创建一个index,有3个primary shard,3个replica shard
PUT /test_index{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}}
集群 status 是 yellow;
GET _cat/health这个时候,只会将3个 primary shard 分配到仅有的一个 node 上去,另外3个 replica shard 是无法分配的;(primary shard 不能和自己的 replica shard 放在同一个节点上)
集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求;
4. 图解2个node环境下replica shard是如何分配的
- replica shard分配:3个primary shard,3个replica shard,1 node;
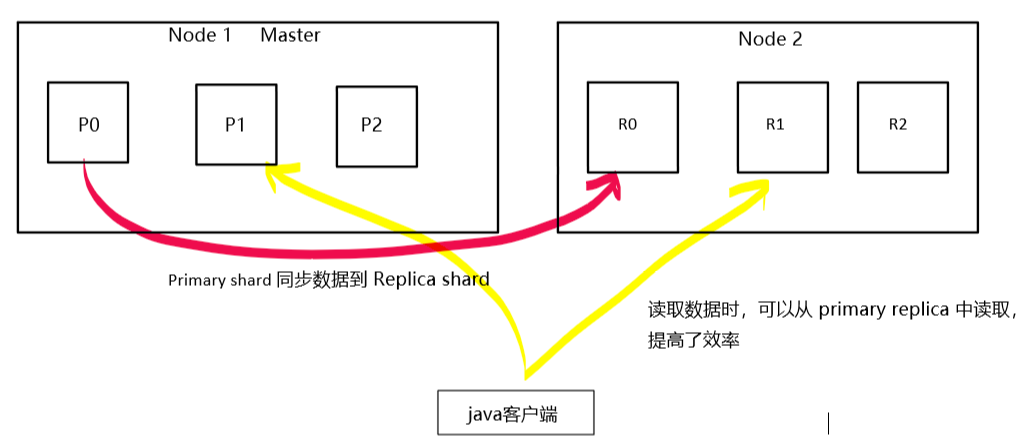
- 在新增第二个节点后,没有被分配的 replica shard 就会被分配到 node2。
- primary —-> replica同步;
- es 会将 primary shard 的数据拷贝到 replica shard。
- 读请求:primary/replica;
- primary shard 和 replica shard 会共同承载读请求。
5. 横向扩容过程,如何超出扩容极限,以及如何提升容错性
primary&replica 自动负载均衡,6个 shard,3 primary,3 replica;
- 每个 node 会尽量保持相同的 shard 的数量,总共 6 个 shard,添加第三个 node 后,每个 node 会自动调整到 2 个 shard;
横向扩容后,每个 node 有更少的shard,IO/CPU/Memory资源给每个shard分配更多,每个shard性能更好;
扩容的极限,6个 shard(3 primary,3 replica),最多扩容到6台机器,每个 node 只有一个 shard,每个shard可以占用单台服务器的所有资源,性能最好;
超出扩容极限,动态修改 replica 数量,9个shard(3primary,6 replica),扩容到9台机器,比3台机器时,拥有3倍的读吞吐量;
3台机器下,9个shard(3 primary,6 replica),资源更少,但是容错性更好,最多容纳2台机器宕机,6个shard只能容纳0台机器宕机;
这里的这些知识点,综合起来看,就是说,一方面告诉你扩容的原理,怎么扩容,怎么提升系统整体吞吐量;另一方面要考虑到系统的容错性,怎么保证提高容错性,让尽可能多的服务器宕机,保证数据不丢失;

若有收获,就点个赞吧
0 人点赞
