1. 什么是Mapping?
- Mapping 类似数据库中的 schema 的定义,作用如下:
- 定义索引中的字段的名称;
- 定义字段的数据类型;
- 字段,倒排索引的相关配置(是否分词、分词器)
- Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式
- 一个 Mapping 属于一个索引的 Type
- 每个文档都属于一个 Type;
- 一个 Type 有一个 Mapping 定义;
- 7.0 开始,不需要在 Mapping 定义指定 type 信息;
2. ES数据如何选型?
2.1 字符串类型选型
- text 类型的作用:分词,将大段的问资根据分词器切分成独立的词或词组,以便全文检索
- 适用:email 内容,产品描述等需要分词全文检索的字段;
- 不适用:排序、聚合;
- keyword 类型的作用:无需分词、整段完整精确匹配
- 适用:email 地址、住址、状态码、分类 tags;
2.2 数值类型选型
- long 长整型:一个带符号的64位整数,数值大小在万亿级别,-2 ~ 2-1;
- integer 整数:一个带符号的32位整数,数值大小在20亿级别,-2 ~ 2-1;
- short 短整形:一个带符号的16位整数,数值大小在3万级别,-32,768 ~ 32,767;
- byte 字节型:一个带符号的8位整数,最小值为-128,最大值为127;
- double 双精度浮点型:双精度64位 IEEE 754 浮点数;
- float 单精度浮点型:单精度32位 IEEE 754 浮点数;
- half_float 半精度浮点型:半精度16位 IEEE 754 浮点数;
- scaled_float:由长度固定的缩放因子支持的浮点数;
以上,根据长度和精度选型即可。
2.3 日期类型选型
{ "date": "2015-01-01" }{ "date": "2015-01-01T12:10:30Z" }{ "date": 1420070400001 }
如上,日期类型或者时间戳类型。
参考模板:
"date": {"type": "date","format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"}
2.4 布尔类型选型
布尔字段接受 JSON true 和 false 值,但也可以接受被解释为 true 或 false 的字符串和数字。
- false 值举例:
- false,“false”,“off”,“no”,“0”,“”(空字符串),0,0.0
- true 值举例:
- 以上false示例的反面,一切非假值。
2.5 二进制类型选型
blob 二进制类型接受二进制值作为 Base64 编码字符串。 该字段默认情况下不存储,不可搜索。
如: “blob”: “U29tZSBiaW5hcnkgYmxvYg==”
2.6 范围类型选型
- integer_range :整型范围类型;
- float_range :单精度浮点范围类型;
- long_range :长整型范围类型;
- double_range :双精度范围类型;
- date_range :时间范围类型;
- ip_range :IP范围类型。
以上,根据类型&范围需要选型即可。
2.7 数组类型选型
在 Elasticsearch 中,没有专门的数组类型。
默认情况下,任何字段都可以包含零个或多个值,但是数组中的所有值必须是相同的数据类型。
例如:
字符串数组:[ “one”, “two” ];
整数数组:[1,2];
阵列数组:[1,[2,3]],相当于[1,2,3];
一系列对象数组:[{“name”:“Mary”,“age”:12},{“name”:“John”,“age”:10}] ;
可以理解为单类型扩展多个值的类型。
:::info
如果需要根据数组值进行查询操作,官网建议使用 nested 嵌套类型。
:::
数组类型:没有明显的字段类型设置,任何一个字段的值,都可以被添加0个到多个,当类型一直含有多个值存储到 ES 中会自动转化成数组类型
对于数组类型的数据,是一个数组元素做一个数据单元,如果是分词的话也只是会依一个数组元素作为词源进行分词,不会是所有的数组元素整合到一起。
在查询的时候如果数组里面的元素有一个能够命中那么将视为命中,被召回。
2.8 Object对象类型
JSON 文档本质上是分层的:存储类似 json 具有层级的数据,文档可能包含内部对象,而内部对象又可能包含其他内部对象。
PUT my_index/my_type/1{"region": "US","manager": {"age": 30,"name": {"first": "John","last": "Smith"}}}
这和 Json 类型的初衷是一致的。
访问方式举例: “manager.name.last”: “Smith”。
2.9 nested嵌套类型
nested 嵌套类型是 Object 数据类型的特定版本,允许对象数组彼此独立地进行索引和查询。
#配置mappingPUT my_index{"mappings": {"properties": {"user": {"type": "nested"}}}}#插入数据PUT my_index/_doc/1{"group" : "fans","user" : [{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]}#查询GET my_index/_search{"query": {"nested": {"path": "user","query": {"bool": {"must": [{ "match": { "user.first": "Alice" }},{ "match": { "user.last": "Smith" }}]}}}}}
能完成嵌套查询&检索,对于非一对一关系的字段适用。
在 ElasticSearch 内部,嵌套的文档(Nested Documents)被索引为很多独立的隐藏文档(separate documents),这些隐藏文档只能通过嵌套查询(Nested Query)访问。每一个嵌套的文档都是嵌套字段(文档数组)的一个元素。
嵌套文档的内部字段之间的关联被 ElasticSearch 引擎保留,而嵌套文档之间是相互独立的。
默认情况下,每个索引最多创建50个嵌套文档,可以通过索引设置选项:index.mapping.nested_fields.limit 修改默认的限制。
2.10 IP类型
存储IPV4或IPV6地址。
如:
“ip_addr”: “192.168.1.1”
2.11 completion suggester类型
suggester 类型对应 suggester 检索,完成自动补全。
2.12 令牌计数类型
类型为 token_count 的字段实际上是一个接受字符串值的整数字段,对它们进行分析,然后对字符串中的令牌数进行索引。
3. Dynamic Mapping
3.1 什么是Dynamic Mapping机制?
- 在写入文档时候,如果索引不存在,会自动创建索引;
- Dynamic Mapping 的机制,使得我们无需手动定义 Mapping;
- ES 会自动根据文档信息,推算出字段的类型,但是有时候会推算的不对,例如地理位置信息。
- 当类型如果设置不对时会导致一些功能无法正常运行,例如 Range 查询;
:::info 查看 Mapping: GET my_index/_mappings :::
3.2 类型的自动识别
| JSON类型 | Elasticsearch类型 |
|---|---|
| 字符串 | - 匹配日期格式的,设置成 Date - 设置为 Text,并且增加 keyword 子字段 - 数字设置为 float 或 long,该选项默认关闭 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
:::tips 注意:
- 布尔值、数字用引号,默认当 Text;
- 日期格式会推导成 Date; :::
3.3 能否更改 Mapping 的字段类型?
两种情况
- 新增字段
- Dynamic 设为 true 时,一旦有新增字段的文档写入,Mapping 也同时被更新;
- Dynamic 设为 false 时,Mapping 不会被更新,新增字段会被丢弃,数据不会被索引,但是新增字段会保存在 _source 中;
- Dynamic 设为 strict 时,文档写入失败;
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引,一旦生成后,就不允许修改;
- 如果希望改变字段类型,必须 Reindex API,重建索引
- 新增字段
原因
- 如果修改了字段的数据类型,会导致已被索引的数据无法被搜索;
- 但是如果是增加新的字段,就不会有这样的影响;
3.4 Dynamic Mapping测试Demo
4. 显式Mapping设置与常见参数介绍
4.1 如何显式定义一个 Mapping?
PUT moives{"mappings": {// define your mappings here"properties": {...}}}
4.2 自定义 Mapping 的一些方法
- 可以参考 API 手册,纯手写
- 为了减少输入的工作量,减少出错概率,可以依照以下步骤:
- 创建一个临时的 index,写入一些样本数据;
- 通过访问 Mapping API 获得该临时文件的 Dynamic Mapping 定义;
- 修改后,使用该配置创建你的索引;
- 删除临时索引;
4.3 常见参数介绍
1)index
- index:控制当前字段是否被索引。默认 true。如果设置成 false,该字段不可被搜索;
```json
设置index为false, mobile字段不会被索引
PUT users { “mappings” : {
} }"properties" : { "firstName" : { "type" : "text" }, "lastName" : { "type" : "text" }, "mobile" : { "type" : "text", "index": false } }
插入数据
PUT users/_doc/1 { “firstName”:”Ruan”, “lastName”: “Yiming”, “mobile”: “12345678” }
搜索mobile,报错400
POST users/_search { “query”: { “match”: { “mobile”: “12345678” } } }
返回结果的部分内容:
{ { “index_uuid”: “SElYj8yfQAWfxs3GzdKBIQ”, “index”: “users”, “caused_by”: { “type”: “illegal_argument_exception”, “reason”: “Cannot search on field [mobile] since it is not indexed.” } “status”: 400 }
<a name="Xuv06"></a>
### 2) index options
- Index Option
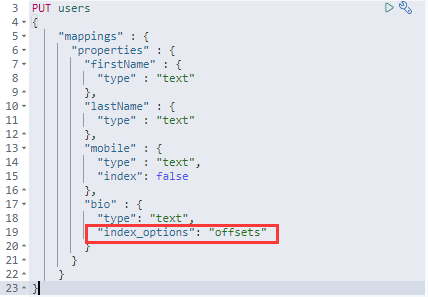
- 四种不同级别的 Index Options 配置,可以控制倒排索引记录的内容
- docs:记录 doc id;
- freqs:记录 doc id 和 term frequencies(词频);
- positions:记录 doc id、term frequencies、term position;
- offsets:记录 doc id、term frequencies、term position、character offsets;
- Text 类型默认记录 positions,其他默认位 docs
- 记录内容越多,占用存储空间越大
<a name="FMyuC"></a>
### 3)null_value
- Null_Value:如何实现对 Null 值的搜索需求
- 只有 keyword 类型支持设定 null_value;
```json
DELETE users
#配置mobile支持对Null值的搜索
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
#插入测试数据
PUT users/_doc/1
{
"firstName":"Ruan",
"lastName": "Yiming",
"mobile": null
}
PUT users/_doc/2
{
"firstName":"Ruan2",
"lastName": "Yiming2"
}
#搜索mobile值为Null的结果
GET users/_search
{
"query": {
"match": {
"mobile":"NULL"
}
}
}
#####返回结果只匹配了 doc 1
4)copy_to
- copy_to
- _all 在 7 中被 copy_to 所代替
- 满足一些特定的搜索需求:
- 假如希望直接可以搜索所有的 filed,任意一个 field 包含指定的关键字就可以搜索出来。难道我们在进行搜索时,要对 document 中的每一个 field 都进行一次搜索吗?!不是的,使用 copy_to;
- copy to 将字段的数值拷贝到目标字段,实现类似 _all 的作用
- copy_to 的目标字段不出现在 _source 中
- 原理:在 mapping 配置时给目标字段设置了 copy_to,那么在建立索引时,我们插入一条 document,ES 会将自动把配置好的目标字段的值,全部用字符串的方式串联起来,变成一个长的字符串,作为 copy_to_filed_name 的值,同时建立索引(生产环境不建议使用,占用存储空间) ```json DELETE users
建立索引时,lastName、firstName字段的值会copy到fullName
PUT users { “mappings”: { “properties”: { “firstName”:{ “type”: “text”, “copy_to”: “fullName” }, “lastName”:{ “type”: “text”, “copy_to”: “fullName” } } } }
插入数据
PUT users/_doc/1 { “firstName”:”Ruan”, “lastName”: “Yiming” }
查询方法1
GET users/_search?q=fullName:(Ruan Yiming)
查询方法2
POST users/_search { “query”: { “match”: { “fullName”:{ “query”: “Ruan Yiming”, “operator”: “and” } } } }
返回结果:匹配到 document中同时含有 Ruan Yiming 两个词就返回
<a name="vDcbp"></a>
### 5)数组类型
- ES 中不提供专门的数组类型。但是任何字段,都可以包含多个相同类型的数值
```json
DELETE users
# text类型中包含一个字符串
PUT users/_doc/1
{
"name":"onebird",
"interests":"reading"
}
# text类型中使用[]包含多个字符串
PUT users/_doc/1
{
"name":"twobirds",
"interests":["reading","music"]
}
#查询
POST users/_search
{
"query": {
"match_all": {}
}
}
######返回结果的部分内容
{
"_source" : {
"name" : "twobirds",
"interests" : [
"reading",
"music"
]
}
}
#查看 mapping 中字段的配置还是 text,而没有专门的数组类型
GET users/_mapping
5. ElasticSearch Mapping 万能模板

若有收获,就点个赞吧
0 人点赞
