ElasticSearch 的分布式搜索采用的是 Query-then-Fetch 运行机制,分两个阶段进行的。
1. Query 阶段
1.1 query phase 工作流程
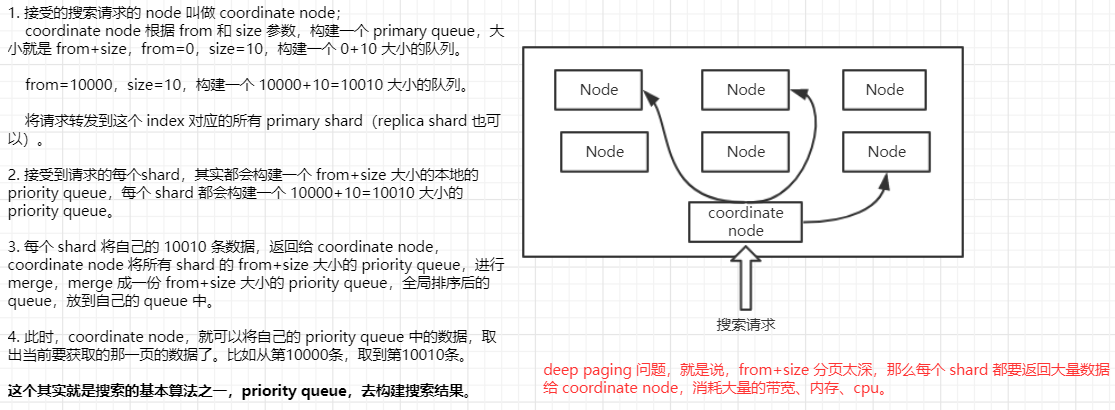
- 搜索请求发送到某一个 coordinate node,构建一个 priority queue,长度以 paging 操作的 from 和 size 为准,默认为10;
- coordinate node 将请求转发到所有 shard,每个 shard 本地搜索,并构建一个本地的 priority queue;
- 各个 shard 将自己的 priority queue 返回给 coordinate node ,并构建一个全局的 priority queue;
1.2 replica shard 如何提升搜索吞吐量
- 一次请求要打到所有 shard 的一个 replica/primary 上去,如果每个 shard 都有多个 replica,那么同时并发过来的搜索请求可以同时打到其他的 replica 上去;
2. Fetch 阶段
2.1 fetch phase 工作流程
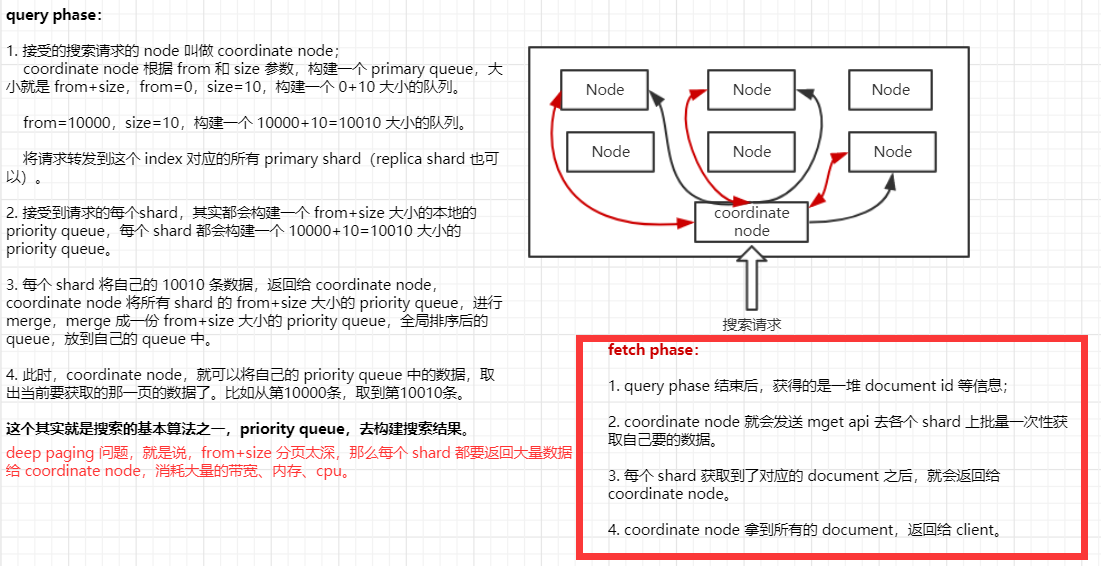
- coordinate node 构建完 priority queue 之后,就发送 mget 请求去所有 shard 上获取对应的 document;
- 各个 shard 将 document 返回给 coordinate node;
- coordinate node 将合并后的 document 结果返回给 client 客户端;
 :::tips
一般搜索,如果不加 from 和 size,就默认搜索前10条,按照 _score 排序;
:::
:::tips
一般搜索,如果不加 from 和 size,就默认搜索前10条,按照 _score 排序;
:::
3. Query-then-Fetch 潜在的问题
性能问题
- 每个分片上需要差的文档个数 = from + size;
- 最终协调节点需要处理:number_of_shard * ( from + size );
- 深度分页(使用 Search After 解决);
相关性算分
- 每个分片都基于自己的分片上的数据进行相关度计算。这会导致打分偏离的情况,特别是数据量很少时。相关性算分在分片之间时相互独立的。当文档总数很少的情况下,如果主分片大于 1,主分片数越多,相关性算分会越不准;
4. 解决算分不准的方法
- 数据量不大的时候,可以将主分片数设置为 1;
- 当数据量足够大的时候,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差;
使用 DFS Query-then-Fetch
- 搜索的 URL 中指定参数 “_search?search_type=dfs_query_then_fetch”;
- 到每个分片把各个分片的词频和文档频率进行搜索,然后完整的进行一次相关算分,耗费更多的 CPU 和内存,执行性能低下,一般不建议使用;
演示 Demo:
- 写入 3 条记录 “Good”、”Good morning”、”good morning everyone”;
- 使用 1 个主分片测试,Good 应该排在第一,Good DF 数值应该是 3;
- 使用 20 个主分片,测试;
- 当多个主分片时,3 个文档的算分都一样。可以通过 Explain API 进行分析;
- 在 3 个主分片上执行 DFS Query-then-Fetch,结果和一个分片上一致;

若有收获,就点个赞吧
0 人点赞
