1. document 路由原理
1.1 文档存储在分片上
文档会存储在具体的某个 Primary Shard 和 Replica Shard 上:例如,文档 1 会存储在 P0 和 R0 分片上;
文档到分片的映射算法:
- 确保文档能均匀分布在所有分片上,充分利用硬件资源,避免部分机器空闲,部分机器繁忙;
1.2 文档到分片的路由算法
- shard = hash( _routing ) % number_of_primary_shards
- Hash 算法确保文档均匀分散到分片中;
- 默认的 _routing 值是文档 id;
- 可以自行指定 routing 数值,例如将相同国家的商品,都分配到指定的 shard;
- 设置 Index Settings 后,Primary 数,不能随意修改的根本原因;
PUT posts/_doc/1?routing=bigdata{"title": "Mastering Elasticsearch","body": "Let's Study"}
举个例子,一个 index 有 3 个 primary shard,P0,P1,P2
每次增删改查一个 document 的时候,都会带过来一个 routing number,默认就是这个 document 的 _id(可能是手动指定,也可能是自动生成);
routing = _id,假设 _id =1;
会将这个 routing 值,传入一个 hash 函数中,产出一个 routing 值的 hash 值,hash(routing) = 21;
然后将 hash 函数产出的值对这个 index 的 primary shard 的数量求余数,21 % 3 = 0;
就决定了,这个 document 就放在 P0 上;
决定一个 document 在哪个 shard 上,最重要的一个值就是 routing 值,默认是 _id,也可以手动指定,相同的 routing 值,每次过来,从 hash 函数中,产出的 hash 值一定是相同的;
无论 hash 值是几,无论是什么数字,对 number_of_primary_shards 求余数,结果一定是在0~number_of_primary_shards-1之间这个范围内的(0、1、2)。
:::tips 手动指定 routing value 是很有用的,可以保证说,某一类 document 一定被路由到一个 shard 上去,那么在后续进行应用级别的负载均衡,以及提升批量读取的性能的时候,是很有帮助的。 :::
- Primary Shard 数量不可变的谜底
- 创建索引后,primary shard 数量不可变跟路由有关,创建一个 document 时根据路由算法(_id=1, hash=21, 21%3=0, 路由到 p0),假设将在 P0 primary shard (现有 p0~p2 三个 primary shard) 上创建这个 document。
- 假设可以改变 primary shard,增加了 P3;
- 现在执行查询 document 操作:get /posts/_doc/1,先进行路由来寻找保存目标 document 的 primary shard 位置;_id = 1, hash=21, 21%4=1, 路由到 p1;
- 结果发现没有找到,就会间接导致数据丢失。 :::tips primary shard 一旦 index 建立,是不允许修改的。但是 replica shard 可以随时修改,因为和路由没有关系; :::
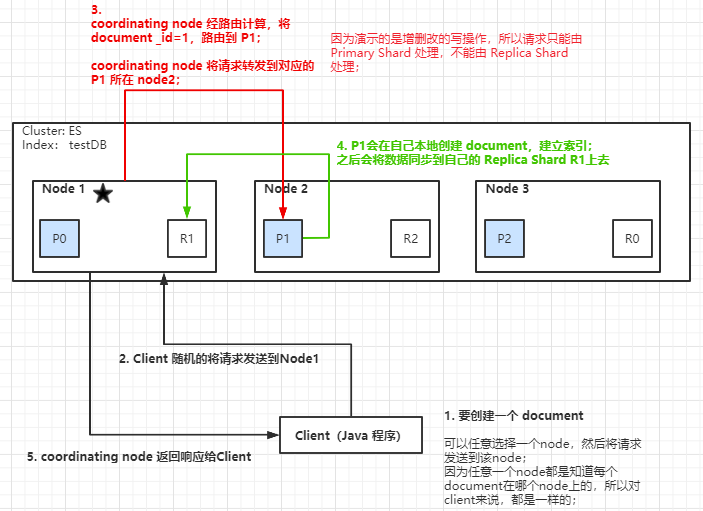
2. document 增删改内部原理图解
- 客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点);
- coordinating node,对 document 进行路由,将请求转发给对应的 node(有 primary shard);
- 实际的 node 上的 primary shard 处理请求,然后将数据同步到 replica 所在的 node;
- coordinating node,如果发现 primary node 和所有 replica node 都搞定之后,就返回响应结果给客户端;
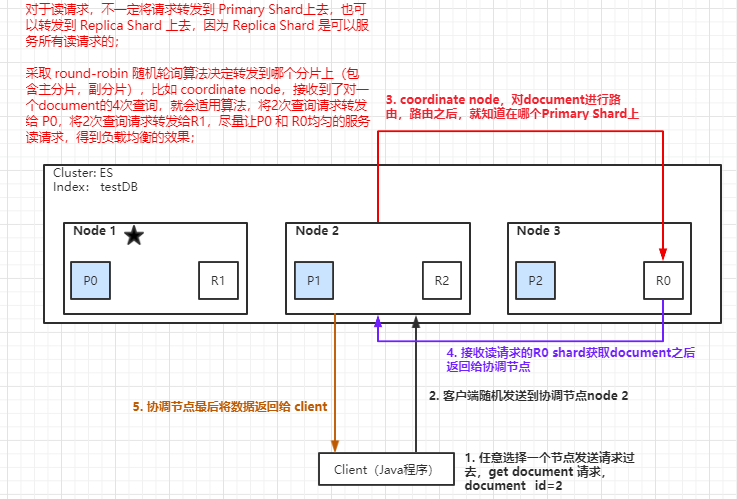
3. document 查询内部原理图解
- 客户端发送请求到任意一个 node,成为 coordinate node;
- coordinate node 对 document 进行路由,将请求转发到对应的 node,此时会使用 round-robin 随机轮询算法,在 primary shard 以及它所有的 replica 中随机选择一个,让读请求负载均衡;
- 接收请求的 node 返回 document 给 coordinate node;
- coordinate node 返回 document 给客户端;
- 特殊情况:document 如果还在建立索引过程中,可能只有 primary shard 有,任何一个 replica shard 都没有,此时可能会导致无法读取到 document,但是 document 完成索引建立之后,primary shard 和 replica shard 就都有了;
:::tips 小结
- 可以通过设置 Index Settings,控制数据的分片;
- Primary Shard 的值不能修改,修改需要重新 Index。默认值是5,从 7.x 开始,默认值改为1;
- 索引写入数据后,Replica 的可以修改。增加副本,可以提高并发下的读取性能;
- 通过控制集群的节点数,设置 Primary Shard 数,实现水平扩展; :::

若有收获,就点个赞吧
0 人点赞
