http的本质就是 tcp/ip 请求。
了解 三次握手建立链接。四次挥手断开连接。
三次握手,举了一个例子
客户端:hello,你是server么? 服务端:hello,我是server,你是client么 客户端:yes,我是client 建立链接之后,开始传输数据。 需要四次挥手,数据传输结束。因为是 全双工。 主动方:我已经关闭了向你那边的主动通道了,只能被动接收了 被动方:收到通道关闭的信息 被动方:那我也告诉你,我这边向你的主动通道也关闭了 主动方:最后收到数据,之后双方无法通信 tcp/ip 并发限制 在http1 中,一个资源对应一个tcp/ip请求。 get和 post区别 get 一个数据包,把 header 和 data 一起发送出去,服务器响应200 ok返回数据 post 两个数据包,先发送header ,响应100continue ,再发送 data,返回200
1.1.1 TCP/IP
这里重提三个概念,后面细节其实有更仔细的解释。
- IP 一般指 IP网络协议,也指ip地址也就是远程主机的网路地址
- UDP 特点不保证数据可靠性,但传输快,比如语音通话、直播,允许丢失部分信息
- TCP 面向连接的、可靠的、基于字节流的传输协议。
提及TCP的可靠,一般会提到每次TCP连接都会产生
- 三次握手。
three-wayhandshakingsyn - syn/ack - ack
用TCP协议把数据包送出去后,TCP不会对传送后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了TCP的标志(flag)——SYN(synchronize)和ACK(acknowledgement)。发送端首先发送一个带SYN标志的数据包给对方。接收端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息。最后,发送端再回传一个带ACK标志的数据包,代表“握手”结束。
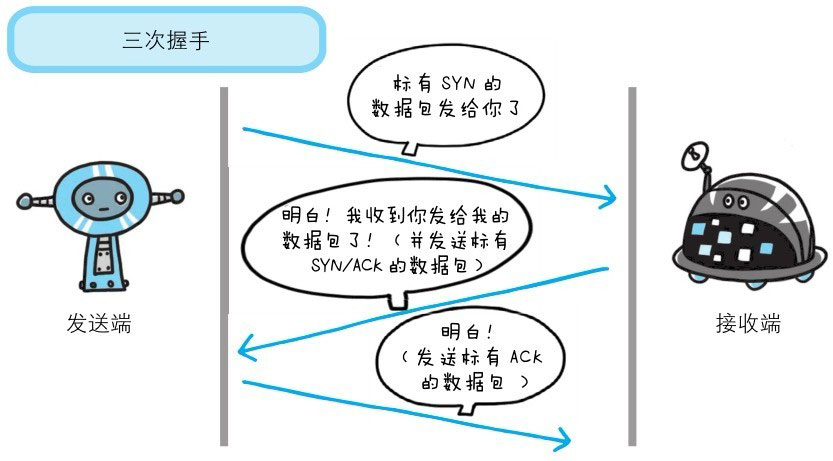
图片来自《图解HTTP》
- 四次挥手 FIN - ACK + FIN - ACK
1.2 HTTP过去、现在和未来
http协议依次经历了: 0.9 - 1.0 - 1.1(主流) - 2.0 - 3.0
HTTP/0.9
最早的协议,比较简单:
- 只有一个请求行,没有请求头 请求体
- 没有返回头、只有数据
- 都是html,内容都是 ascii 字符流传输 。
当然,DNS获取IP、三次握手、四次挥手还是存在的。
HTTP/1.0
基本完善了,补充了一些东西:
- 引入请求头、响应头,支持更多细节
- 引入 状态码
- 提供 cache 缓存机制。有缺点,依赖浏览器本地时间,精度秒不够精确。
- 加入ua区分。目前的ua区别很小,但还是能区分操作系统和浏览器版本
HTTP/1.1
在1.0的基础上,补充了一些特点,弥补缺点:
- 默认开启 connect: keep-alive ,允许一个tcp传输多个http请求
- cookie 、安全机制
- 不成熟的http管线化,每个域名同时最大6个tcp持久连接。如果还不够可以多域名绕过。tcp队头阻塞。后面补充
- 增加host字段,支持虚拟主机
- 动态生成内容的完美支持 chunk transfer ,也就是BigPipe ,需要大量内容传输时候分块。后来弃用了。
传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。这种把实体主体分块的功能称为分块传输编码(Chunked Transfer Coding)。
还是有问题:
- 对带宽利用率不高,还是有并发数限制
- tcp的慢启动,需要三次握手建立信任
- 并发tcp连接,会相互竞争网宽,不能区分优先级
- 队头阻塞问题,如果单个数据包丢失会造成阻塞。
问 keep-alive 怎么理解
- 省掉的是握手 挥手。只有开始和结束存在
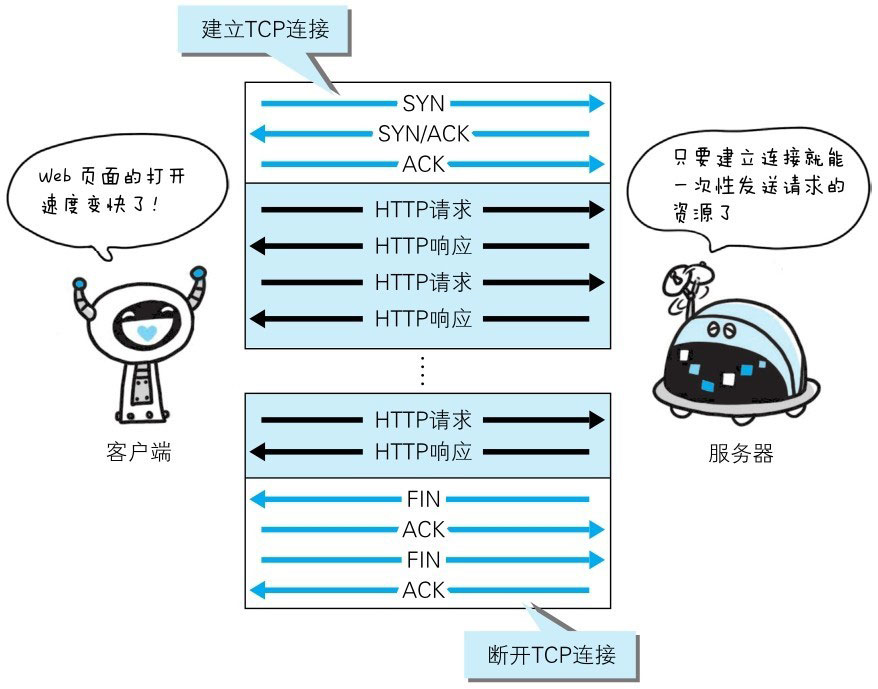
图片来自《图解HTTP》
持久连接的好处在于减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。另外,减少开销的那部分时间,使HTTP请求和响应能够更早地结束,这样Web页面的显示速度也就相应提高了。
补充管线化、对头阻塞。
持久连接使得多数请求以管线化(pipelining)方式发送成为可能。从前发送请求后需等待并收到响应,才能发送下一个请求。管线化技术出现后,不用等待响应亦可直接发送下一个请求。
这里发送可以并行,但响应还是要按照顺序的。如果下面的3丢失了,需要重新来。
比如传输1234 的数据包,3丢了,只能等3重传,其他包要等等
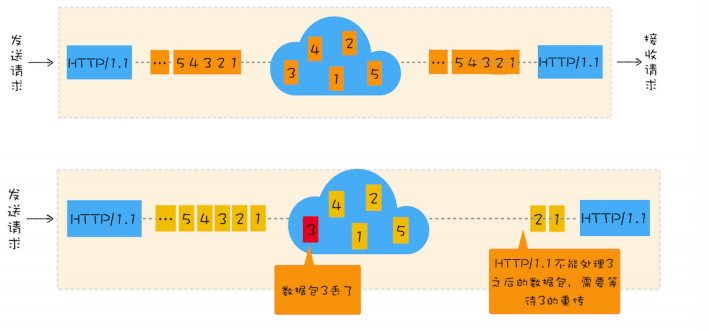
CDN
这里提到了CDN,其实涉及到DNS转发时候的
- A 记录,指向ip
- NS 转发,一般只有一次,指定域名解析商
- CNAME 别名,把域名解析交给其他网址
CDN就利用了CNAME,交给其他服务商来完成解析。
HTTP/2.0
http2 变成了二进制的帧。有ID区分最后再拼起来。
也是为了解决问题而出现:
- 多路复用:一个域名使用一个tcp,有ID不怕阻塞,放心复用。
- 设置请求优先级
- 服务器推送
- 头部压缩。很可观。
解决了http层面的对头阻塞,但底层是tcp,tcp的传输某个数据包可能会丢,会导致阻塞,这是tcp层面上的队头阻塞。如果有丢包,1.1反而比2好
HTTP/3.0
TCP最初的目的是为单连接而设计,刚才提到的缺陷并不容易解决。
因此谷歌推出了基于UDP的 QUIC协议。
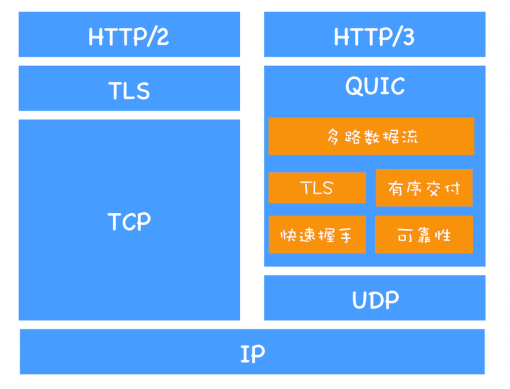
这里可以发现,拿掉了 TCP,对UDP进行了改进。
- 实现了TCP的流量控制、传输可靠
- 支持TLS加密
- 快速握手
- 多路复用
HTTP/3 完美了,但服务器兼容性、浏览器兼容性都不好,系统内核对UDP的优化还不够,因此不建议使用,需要等待时机。
TLS
hash。对称、非对称加密。
HTTP
特点
无连接,无状态。简单快速,灵活。
连接一次就断开。每次连接无法区分状态。
超文本传输协议。
请求过程
这里我们看一个请求的发出和响应。去请求百度
➜ curl -v http://www.baidu.com/ #用户发起一个请求* Trying 182.61.200.7... # tcp握手1* TCP_NODELAY set # tcp握手2* Connected to www.baidu.com (182.61.200.7) port 80 (#0) # tcp握手3 # 接下来是请求报文> GET / HTTP/1.1 # 请求行> Host: www.baidu.com # 请求头> User-Agent: curl/7.58.0> Accept: */*> # 空行< HTTP/1.1 200 OK # 响应报文< Accept-Ranges: bytes # 以下都是响应头< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform< Connection: Keep-Alive< Content-Length: 2381< Content-Type: text/html< Date: Mon, 04 Nov 2019 14:00:38 GMT< Etag: "588604c8-94d"< Last-Modified: Mon, 23 Jan 2017 13:27:36 GMT< Pragma: no-cache< Server: bfe/1.0.8.18< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/< # 空行<!DOCTYPE html> # 以下是响应体</html>* Connection #0 to host www.baidu.com left intact # 断开
请求内容
- 请求行
- 头
- 实体
方法
状态码
- 1xx
- 200 ok
- 206 客户端range。 video 时候206
- 301 永久重定向
- 302 临时重定向
- 304 有缓存
- 400 语法错误
- 401 未授权
- 403 禁止访问
- 404 不存在
- 5xx 服务器问题
持久连接
http1.1 通过 keep-alive中间不断开。
管线化。先打包请求,打包一次响应。只有get和head可以进行管线化,由于各种问题,现代浏览器默认不开启管线化。
TLS
加密,对称加密,非对称加密
对称加密:两边都有密钥,都知道怎么加密解密。如果密钥在网络传输中被拦截,就不行了
非对称加密:公钥 私钥。用公钥加密,用私钥解密,私钥只有发公钥的才知道。
http/2
多路复用
以前为了优化,会使用雪碧图,小图内联,多域名cdn。
有了 多路复用,一个tcp可以传输所有数据,解决了统一域名请求数量限制的问题。
二进制传输
把文本变成二进制编码
header 压缩
相同的内容就压缩了,减少了后续header的大小
服务端push
收到某个请求后,主动推送其他资源。兼容性的话,可以 prefetch
HTTP/3
如果多路复用时候丢包了,那性能就差了。
后来google基于udp搞了一个quic协议,使用 http/3
http3最大的改造就是 使用了 quic
细节有点儿没掌握。

若有收获,就点个赞吧
0 人点赞
