关系型数据库回顾
- 什么是关系型数据库?
关系型数据库指的是基于关系模型所提出的一种数据库,关系模型指的是最终用一张二维表行和列的方式来存储数据。如mysql、oracle等。在设计关系型数据库时,很重要的一点是需要遵循范式的要求。第一、二、三范式。
- 为什么设计数据库的时候,需要遵循范式的要求?
优点是可以减少数据冗余(比如外键关联查询),缺点是降低性能。
BigTable大表思想
思想:将所有的数据存入一张表。缺点是有数据冗余,优点是提高性能。它和关系型数据库恰好相反。因为在以前,数据空间是比较小的,存储介质比较贵,所以需要节约一点。但是在现在,存储已经很便宜了,更注重性能。他们采用两种不同的角度去解决问题。
HBase简介
HBase(Hadoop Database)是一个高可靠性、分布式的、可扩展、面向列、实时读写、支持海量数据存储的 NoSQL 数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。HBase在Hadoop之上提供了类似于Bigtable的能力。
HBase数据模型
HBase逻辑结构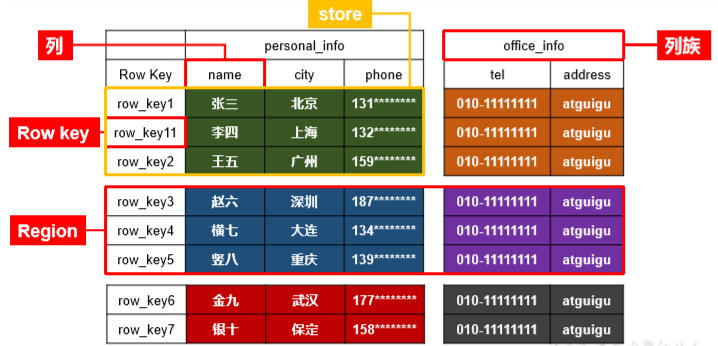
HBase物理结构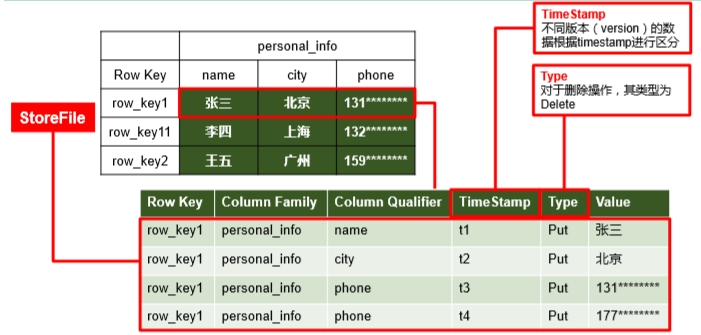
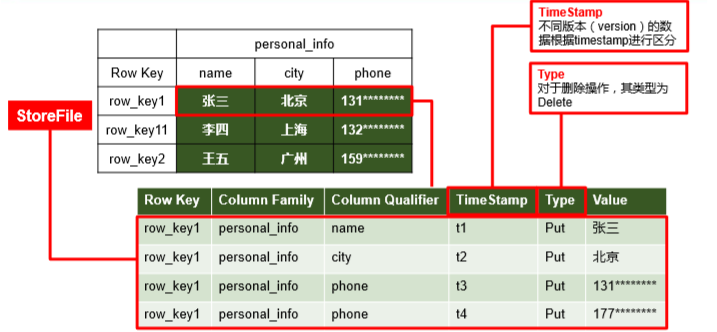
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。RowKey(行键):类似关系型数据库的id、主键。唯一标识一行记录,决定一行数据。按照字典顺序进行排序只能存储64k的字节数据,rowkey设计越短越好,一般10-100字节。Name Space命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。RowHBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。Column Family列族,标识一组列的集合。假设有200个列,可以将他们分别存放在不同的列族中。在hbase中,列族是最小控制单元,意思是如果要修改某个列族中某个列的数据,是修改不了的。HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列)进行限定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。hbase把同一列族里面的数据存储在同一目录下,由几个文件进行保存。Time Stamp时间戳,用于标识数据的不同版本(version),它可以记录多版本的数据,每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入 HBase 的时间。不同版本按照时间倒序进行排序,默认取最新。因为hbase没有update操作。Cell单元格,由行和列的坐标交叉决定。单元格是有版本的,内容是未解析的字节数组。由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
Hbase KeyValue结构详解
在HBase写入过程中,会检查Put中每个单元格Cell的KeyValue大小是否大于设置的maxKeyValueSize。要计算KeyValue的大小就需要了解KeyValue的的格式以及占用空间的计算方式。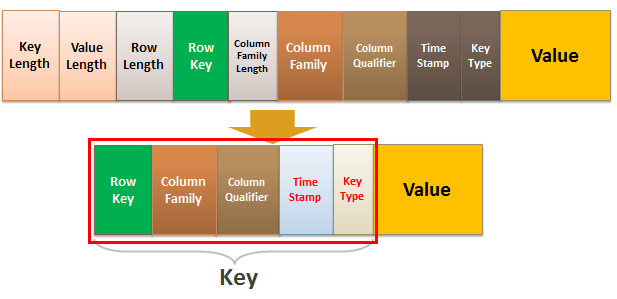
KeyValue类是HBase中数据存储的核心,由keylength、valuelength、key、value四个部分组成,其中Key又由Row Length、Row、Column Family Length、Column Family、Column Qualifier、Time Stamp、Key Type七部分组成。
KeyValue不会在块之间拆分。例如,如果有一个8 MB的KeyValue,即使块大小是64kb,这个KeyValue将作为一个连贯块读取。
- KeyLength存储Key的长度,占4B;
- ValueLength存储Value的长度,4B;
- Key存储具体的Cell数据:
- Row Length:存储rowkey的长度,占2B (Bytes.SIZEOF_INT);
- Row:存储Rowkey实际内容,其大小为Row Length ;
- Column Family Length:存储列族Column Family的长度,占1B (Bytes.SIZEOF_BYTE);
- Column Family:存储Column Family实际内容,大小为Column Family Length;
- Column Qualifier:存储Column Qualifier对应的数据。
- Time Stamp:存储时间戳Time Stamp,占8B (Bytes.SIZEOF_LONG);
- Key Type:存储Key类型Key Type,占1B ( Bytes.SIZEOF_BYTE),Type分为Put、Delete、DeleteColumn、DeleteFamilyVersion、DeleteFamily、Maximum、Minimum等类型,标记这个KeyValue的类型;
- 由于Key中其它的字段占用大小已经知道,并且知道整个Key的大小,因此没有存储Column Qualifier的大小。
- Value:存储单元格Cell对应的实际的值Value。
- 示例:对于
Put : rowkey=row1, cf:attr1=value1操作,Key对应关系如下:rowlength -----------→ 4row -----------------→ row1column family length --→ 2column family --------→ cfcolumn qualifier -----→ attr1timestamp -----------→ server time of Putkey type -------------→ Putrow length占用2B空间,因此解释了rowkey的最大长度不能超过64kb。
- 示例:对于
KeyValue占用空间计算
validatePut()方法中会使用KeyValueUtil.length(cell)来检查每个Cell的大小是否大于maxKeyValueSize。因此涉及到如何计算KeyValue整个占用的空间大小。
KeyValue类中提供了getKeyValueDataStructureSize()方法用于计算KeyValue的大小。
public static long getKeyValueDataStructureSize(int rlength,int flength, int qlength, int vlength) {return KeyValue.KEYVALUE_INFRASTRUCTURE_SIZE+ getKeyDataStructureSize(rlength, flength, qlength) + vlength;}主要包含三部分:1、KeyValue.KEYVALUE_INFRASTRUCTURE_SIZE:等于key length和value length占用空间大小之和,为8B2、KeyDataStructureSize:整个Key结构的大小KeyDataStructureSize = KeyValue.KEY_INFRASTRUCTURE_SIZE + rlength + flength + qlength= 12 + cell.getRowLength()+cell.getFamilyLength()+cell.getQualifierLength()3、vlength:等于valuelength 的值,使用cell.getValueLength()获取因此整个KeyValue占用的空间大小:KeyValueDataStructureSize=20B+cell.getRowLength()+cell.getFamilyLength()+cell.getQualifierLength()
HBase基本架构
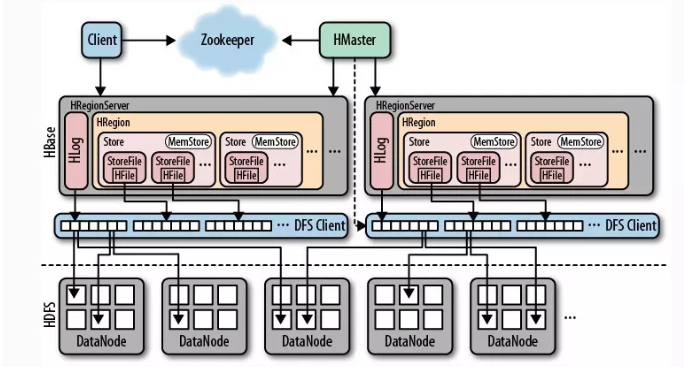
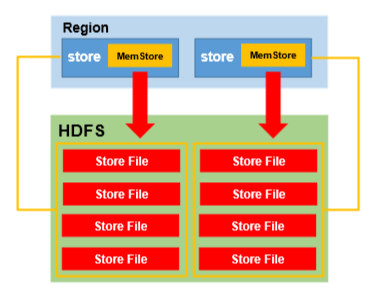
包括了HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等。HBase底层依赖HDFS,通过DFS Cilent进行HDFS操作。HMaster负责把HRegion分配给HRegionServer,每一个HRegionServer可以包含多个HRegion,多个HRegion共享HLog,HLog用来做灾难恢复。每一个HRegion由一个或多个Store组成,一个Store对应表的一个列族,每个Store中包含与其对应的MemStore以及一个或多个StoreFile(是实际数据存储文件HFile的轻量级封装),MemStore是在内存中的,保存了修改的数据,MemStore中的数据写到文件中就是StoreFile。HMasterHMaster的主要功能有:1.把HRegion分配到某一个RegionServer。2.有RegionServer宕机了,HMaster可以把这台机器上的Region迁移到active的RegionServer上。3.对HRegionServer进行负载均衡。4.通过HDFS的dfs client接口回收垃圾文件(无效日志等)注:HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。HRegionServer1.维护HMaster分配给它的HRegion,处理对这些HRegion的IO请求,也就是说客户端直接和HRegionServer打交道。(从图中也能看出来)2.负责切分正在运行过程中变得过大的HRegionHRegion (如下图)类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。每个HRegion由多个Store构成,每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store,每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件后就是StoreFile。StoreFile底层是以HFile的格式保存。
HRegion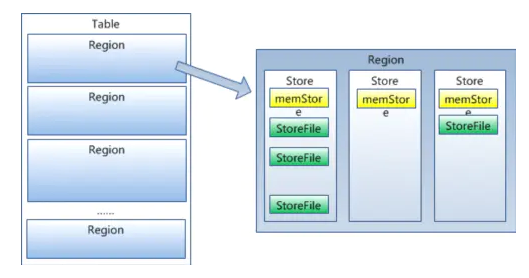
HFile
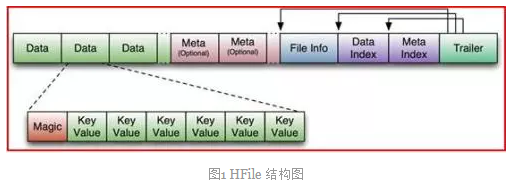
HFile是HBase中KeyValue数据的存储格式(这里不要把KeyValue想成Map的那种形式,理解起来会好一点),HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile 。HFile由六部分组成:Data(数据块):保存表中的数据(KeyValue的形式),这部分可以被压缩。Meta (元数据块):存储用户自定义KeyValueFile Info:定长;记录了文件的一些元信息,例如:AVG_KEY_LEN,AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等Data Index(数据块索引):记录了每个Data块的起始索引Meta Index(元数据块索引):记录了每个Meta块的起始索引Trailer:定长;用于指向其他数据块的起始点。
HLog
HLog(WAL log):WAL意为write ahead log(预写日志),用来做灾难恢复使用,HLog记录数据的变更,包括序列号和实际数据,所以一旦region server 宕机,就可以从log中回滚还没有持久化的数据。
HBase写数据流程
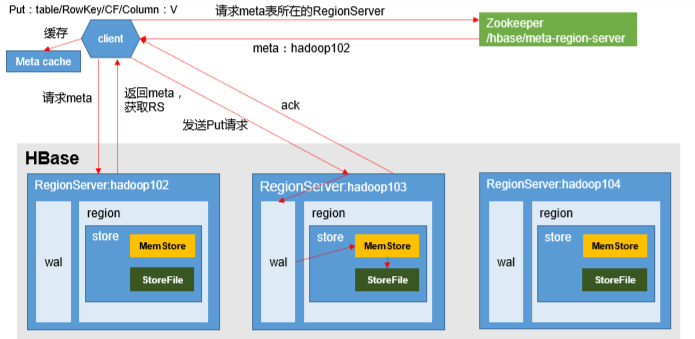
HBase默认适用于写多读少的应用,正是依赖于它相当出色的写入性能:一个100台RS的集群可以轻松地支撑每天10T 的写入量。当然,为了支持更高吞吐量的写入。插入一条数据到某个表,因为HBase通过Zookeeper协调。1.客户端访问zookeeper,从Zookeeper中获取获取元数据存储所在的regionserver。2.找到regionserver以后,找到对应表所在的regionserver。3.到对应的regionserver获取表region相关信息。4.查找对应的region,在region中寻找列族,先向memstore(内存中,也称写缓存)中写入数据,数据会在 MemStore 进行排序。5.当memstore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile6.当溢写的文件过多时,会触发文件的合并(Compact)操作,合并有两种方式(major,minor)多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除minor compaction:小范围合并,默认是3-10个文件进行合并,不会删除其他版本的数据。major compaction:将当前目录下的所有文件全部合并,一般手动触发,会删除其他版本的数据(不同时间戳的)7、当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变(一个region等分为两个region,并分配到不同的regionserver),原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。由此可知HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的,所以用户写操作只需要进入到内存即可立即返回,从而保证I/O高性能读写。
memstore触发flush溢写条件
1.(hbase.regionserver.global.memstore.size)默认;堆大小的40%regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写2.(hbase.hregion.memstore.flush.size)默认:128M单个region里memstore的缓存大小,超过那么整个HRegion就会flush,3.(hbase.regionserver.optionalcacheflushinterval)默认:1h内存中的文件在自动刷新之前能够存活的最长时间4.(hbase.regionserver.global.memstore.size.lower.limit)默认:堆大小 * 0.4 * 0.95有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小,这个大小就是默认值是堆大小 * 0.4 * 0.95,也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止5.(hbase.hregion.preclose.flush.size)默认为:5M当一个 region 中的 memstore 的大小大于这个值的时候,我们又触发 了 close.会先运行“pre-flush”操作,清理这个需要关闭的memstore,然后 将这个 region 下线。当一个 region 下线了,我们无法再进行任何写操作。如果一个 memstore 很大的时候,flush 操作会消耗很多时间。"pre-flush" 操作意味着在 region 下线之前,会先把 memstore 清空。这样在最终执行 close 操作的时候,flush 操作会很快。6.(hbase.hstore.compactionThreshold)默认:超过3个一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面,也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当超过3个hfile的时候就会对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长。
HLog的的功能: 宕机数据恢复
在分布式系统环境中,我们是无法避免系统出错或者宕机的,一旦HRegionServer意外退出,
MemStore中的内存数据就会丢失,而引入HLog就是为了防止这种情况。
工作机制:
每个HRegionServer中都会有一个HLog对象,HLog是一个实现Write Ahead Log的类,
每次用户操作写入Memstore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新,
并删除旧的文件(已持久化到Storefile中的数据),当HRegionServer意外终止后,
HMaster会通过Zookeeper感知,HMaster首先处理遗留的HLog文件,将不同region的log数据拆分,
分别放在相应region目录下,然后再将失效的region(带有刚刚拆分的log)重新分配,
领取到这些region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,
因此会Replay HLog中的数据到Memstore中,然后flush到StoreFile,完成数据恢复。
HLog是磁盘还是内存?
在写入memstory之前时,先写入HLog,
向HLog写入时,先写入内存,它的后台有一个logsync的一个线程,默认1秒溢写1次。
HBase读数据流程
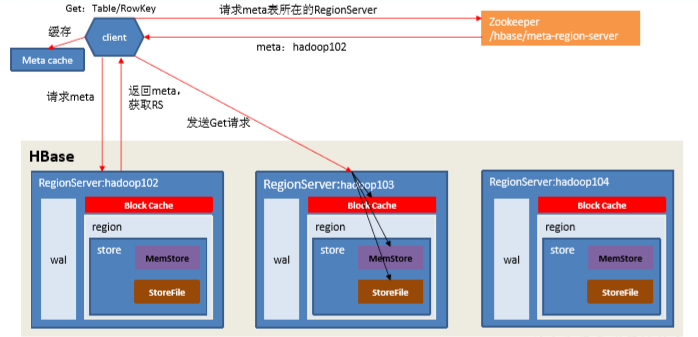
1.客户端访问zookeeper,从Zookeeper中获取元数据存储所在的regionserver。
2.找到regionserver以后,找到对应表所在的regionserver。
3.到对应的regionserver获取表region相关信息。
4.查找对应的region,在region中寻找列族,先找到memstore,找不到去blockcache(内存中,也称读缓存)中寻找,
再找不到就进行storefile的遍历
5.找到数据之后会先缓存到blockcache中,再将结果返回
blockcache逐渐满了之后,会采用LRU的淘汰策略。但它的大小是可设置的。
HBase - rowkey设计
标识符+时间戳反转(用Long.MAX_VALUE - 时间戳,来实现最新一条数据在第一条)
查询时,startRow(大值),stopRow(小值)
设计原则(根据业务)
- Rowkey的唯一原则:保证Rowkey的唯一性
- Rowkey的排序原则:ASCII有序设计,字典序
- Rowkey的散列原则:均匀的分布在各个HBase节点上,防止Region热点问题
- Rowkey的长度原则:建议设计在10~100个字节,越短越好
**

若有收获,就点个赞吧
0 人点赞
