什么是 ShardingSphere
Apache ShardingSphere 是一款开源分布式数据库生态项目,由 JDBC、Proxy 和 Sidecar(规划中) 3 款产品组成。其核心采用可插拔架构,通过组件扩展功能。对上以数据库协议及 SQL 方式提供诸多增强功能,包括数据分片、访问路由、数据安全等;对下原生支持 MySQL、PostgreSQL、SQL Server、Oracle 等多种数据存储引擎。
分库分表
- 方案1:硬件层面。提升服务器性能,加内存、CPU等,但并不能根本解决。
- 方案2:分库分表。分库分表分为垂直切分和水平切分。
垂直切分
垂直分表
将数据库中某张表,按照字段进行拆分成多张表,每张表中存储一部分字段
例:现有一个文章表,字段包括title(标题)、content(内容)、auth(作者)、path(文章来源)、create_time(创建时间)、like_count(点赞数)等等约20个字段,现在可根据业务将标题、作者、创建时间、点赞数拆分出来单独存到一张新表,专门用于列表页的展示,因为列表页只需要这些字段就够了;再将文章来源、文章内容等其余字段拆分出来存到另一张新表中,专门用于在进入详情页展示。

垂直分库
按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用
例:现有订单表、文章表、商品表等。将订单分一个数据库,文章分一个数据库,商品分一个数据库。
水平切分
水平分库
把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上
例:现有一个订单数据库,将订单数据库拆成多个相同的数据库,部署在不同的服务器上,在存储数据时,通过一定规则,最终决定数据存储到哪个数据库上。比如根据id,奇数存到A库,偶数存到B库。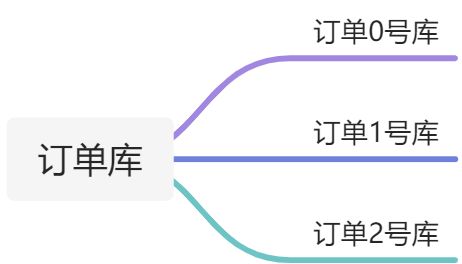
水平分表
在同一个数据库内,把同一个表的数据按一定规则拆到多个表中
例:现有一个订单库,订单库中有一张order订单表,将order表复制多份,order0,order1,order2…order200,分了200张order表,表结构一致。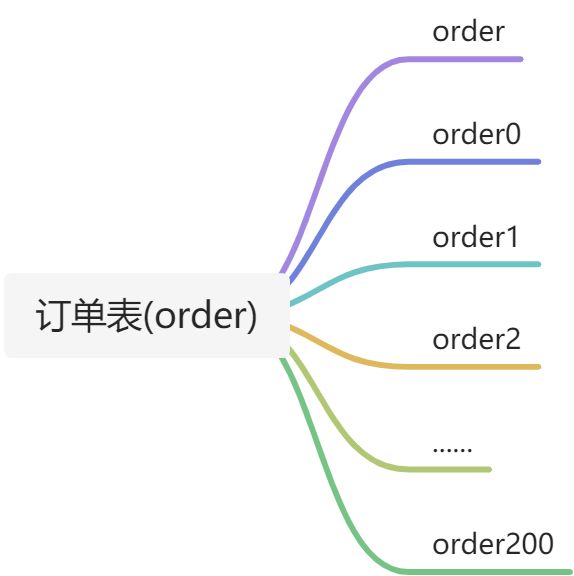
分库分表带来的问题
- 事务一致性问题:由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
- 跨节点关联查询:可将原关联查询分为两次查询。
- 跨节点分页、排序函数:跨节点多库进行查询时,limit分页、order by排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
- 主键避重:,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
- 公共表:实际的应用场景中,参数表、数据字典表等都是数据量较小,变动少,而且属于高频联合查询的依赖表。可以将这类表在每个数据库都保存一份,所有对公共表的更新操作都同时发送到所有分库执行。
总结
不管是怎么分库分表,都是为了解决数据量庞大带来的一系列问题,但也不要草率的分库分表,数据量大时,首先考虑热点数据缓存,数据库读写分离,数据库索引等方式,若不能解决问题,在考虑做分库分表。
个人理解:还是要结合自己情况来决定,没有说绝对多少条就一定需要分库分表,一切都是要结合业务、服务器性能、成本等多方面考虑。

若有收获,就点个赞吧
0 人点赞
