HDFS由3部分组成:NameNode、DataNode、Secondary NameNode
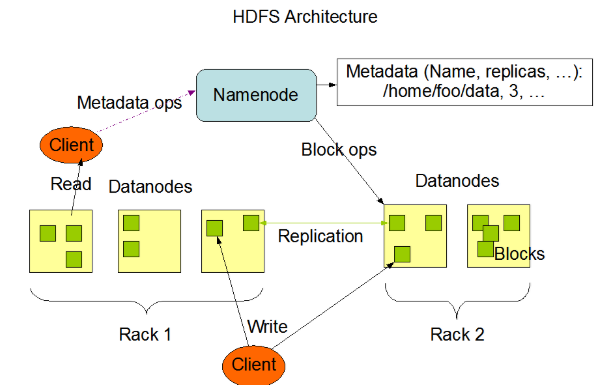
角色1:NameNode(名称节点)
NameNode是hdfs的管理员,名称节点,它不负责数据存储,但它会基于内存存储文件元数据,目录结构,文件block映射。NameNode职责如下:
1、管理HDFS的名称空间。
2、记录客户端操作的日志(edits文件)
3、管理数据块(block)的映射信息,(元信息)并维护了一个层次型的文件目录树。
4、接受客户端的请求: 上传文件、下载文件、创建目录等等。
角色2:DataNode(数据节点)
基于本地磁盘存储block(block以文件形式存储),NameNode下达指令,DataNode执行实际操作。
1.以数据块block为单位,保存数据,并提供block的读写
(1)Hadoop 1.0的数据块大小: 64M
(2)Hadoop 2.0 的数据块大小:128M
2.DataNode与NameNode维持心跳,并汇报自己持有的block信息
角色3:Secondary NameNode(第二名称节点)
与NameNode运行在同一台机器上。辅助NameNode,并非NameNode的热备,当NameNode挂掉时,并不能马上替换NameNode并提供服务。
1、主要职责就是进行日志合并(checkpoint),定期合并Fsimage和edits文件。
HDFS中的block、packet、chunk
block(数据块)
文件上传前需要分块,这个块就是block,一般为128MB,当然也可以改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。可以把数据块理解成逻辑单位。例如:200M的数据会被切分为2个数据块,1格式128M,1个是72M(不够128M传输和存储将按照实际大小进行传输和存储,也就是占用的物理存储是72M,占用的数据块大小是128M)
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
HDFS数据块冗余度
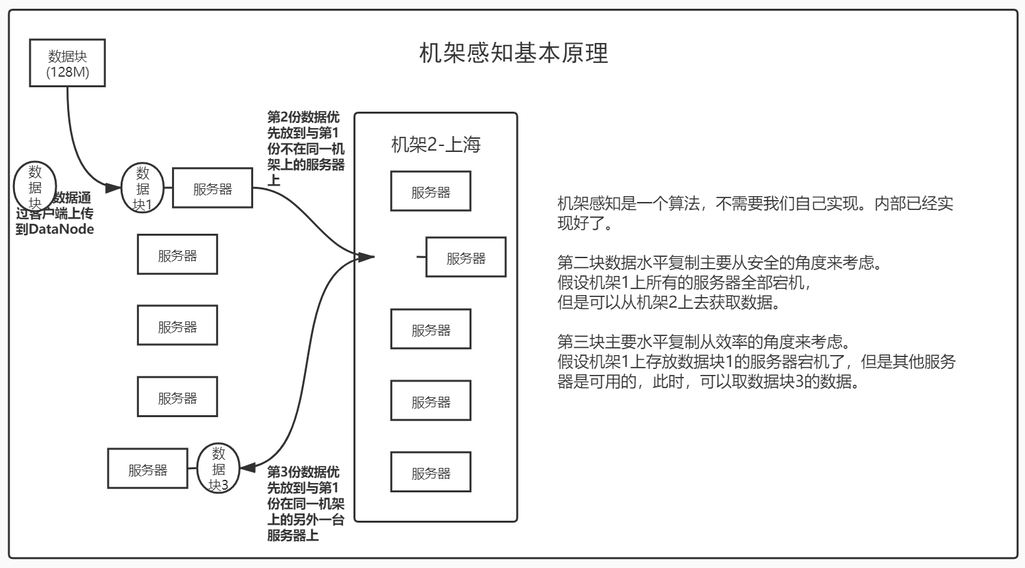
hdfs分布式文件系统,默认是3份,可通过参数修改。这3份数据是怎么存放的?只有第1份是客户端上传上来的。
1、首先会把第1份数据上传到其中1个数据节点(DataNode)上,后面的2份跟客户端无关。
2、数据节点彼此之间会进行水平复制(机架感知)。
什么是机架感知
元信息(数据块的位置信息) - 存放NameNode中
fsimage文件(元信息文件),该文件以fsimage打头后面跟一串数字,是一个二进制文件,是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息。保存目录:$HADOOP_HOME/tmp/dfs/name/currentfsimage。可以使用hdfs oiv -i命令将日志(二进制)输出为文本(文本和XML)。例如:hdfs oiv -i fsimage_0000000000000000121 -o ~/temp/fsimage.txt 或者 hdfs oiv -i fsimage_0000000000000000121 -o ~/temp/fsimage.xml -p XML。
日志文件 - 存放NameNode中
edits文件。保存目录:$HADOOP_HOME/tmp/dfs/name/current。该文件以edits打头后面跟一串数字,也是二进制文件。可以使用hdfs oev -i命令将日志(二进制)输出为XML文件,例如:hdfs oev -i edits_inprogress_0000000000000122 -o ~/tmp/log.xml。
NameNode、DataNode、Secondary NameNode联合工作
NameNode和Secondary NameNode工作机制
- fsimage文件的产生:在首次启动hadoop之前,需要对其进行格式化操作,格式化后fsimage文件会生成。
- NameNode因经常被客户端访问和其他等操作,如果把fsimage文件放在磁盘中,将会导致效率过低,所以NameNode将fsimage文件和edits文件存放于内存中,此时如遇断电、宕机等情况,必然会造成数据丢失。所以需要将元数据等信息持久化到fsimage文件中去。
- 当在内存中的元数据更新时,如果实时更新到fsimage文件中,就会导致效率过低。因此,引入edits文件,该文件只进行追加操作,每当有元数据更新或者添加时,修改内存中的元数据并追加到edits中。
- 如果长时间的添加日志到edits中,会导致该文件越来越大,因此需要定期进行fsimage文件和edits合并。如果这个操作由NameNode来完成,又会降低效率,因此,Secondary NameNode节点诞生,专门负责fsimage和edits文件合并。
- 通常情况下,SecondaryNamenode会每60分钟的执行1次合并,请求NameNode停止使用edits文件,暂时将新的操作日志写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
- Secondary Namenode通过HTTP GET方式从NameNode上获取到fsimage和edits文件,并下载到本地的相应目录下,而后进行合并。
合并后生成新的镜像文件,fsimage.checkpoint,上传到NameNode,而后对其进行重命名。
DataNode工作机制
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
- 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
Hadoop全分布环境至少需要3台机器(NameNode和Secondary NameNode为1台,DataNode2台),数据存放在DataNode节点上,并且以数据块为单位进行存储。
HDFS存在的问题
- NameNode单点故障,难以应用二在线场景
解决方案:Hadoop 1.0中,没有解决方案。
Hadoop 2.0 中,使用ZooKeeper实现NameNode的HA功能。
- NameNode压力过大,且内存受限,影响系统扩展性
解决方案:Hadoop 1.0 中,没有解决方案。
Hadoop 2.0 中,使用NameNode的联盟实现其水平扩展。
HDFS启动过程
首次启动有一个format格式化的操作,这个操作是生成fsimage文件
1、首此启动hdfs过程:
启动namenode:读取fsimage生成内存中元数据镜像。
启动datanode:向namenode注册;向namenode发送blockreport。
启动成功后,client可以对HDFS进行目录创建、文件上传、下载、查看、重命名等操作,更改namespace的操作将被记录在edits文件中。
2、之后启动HDFS文件系统过程:
第一阶段:读取fsimage元数据镜像文件,加载到内存中。
第二阶段:读取edits文件,加载到内存中,使当前内存中元数据信息与上次关闭系统时保持一致。
第三阶段:触发checkpoint检查点
第四阶段:hdfs进入安全模式
- 什么时候安全模式?
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。如果HDFS处于安全模式,则表示HDFS是只读状态。
当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是5,那么在datanode上就应该有5个副本存在,假设只存在3个副本,那么比例就是3/5=0.6。在配置文件hdfs-default.xml中定义了一个最小的副本的副本率0.999,如图:
<br />我们的副本率0.6明显小于0.99,因此系统会自动的复制副本到其他的dataNode,使得副本率不小于0.999.如果系统中有8个副本,超过我们设定的5个副本,那么系统也会删除多余的3个副本。
虽然不能进行修改文件的操作,但是可以浏览目录结构、查看文件内容的。
- 在命令行下是可以控制安全模式的进入、退出和查看的。
- 命令 hdfs dfsadmin -safemode get 查看安全模式状态
- 命令 hdfs dfsadmin -safemode enter 进入安全模式状态
- 命令 hdfs dfsadmin -safemode leave 离开安全模式
HDFS文件上传(写)流程
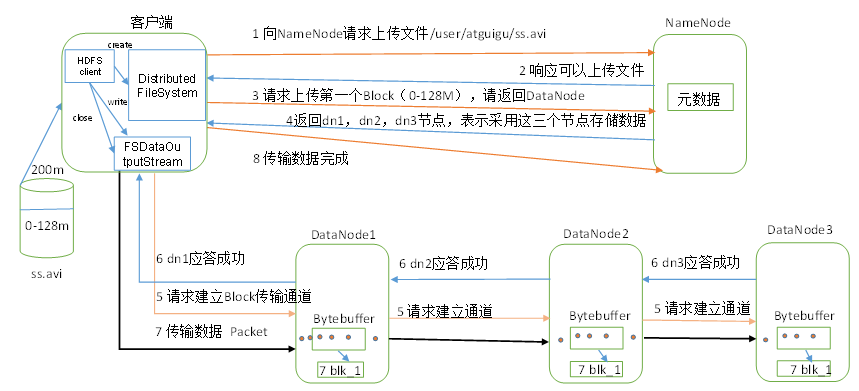
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS文件下载(读)流程
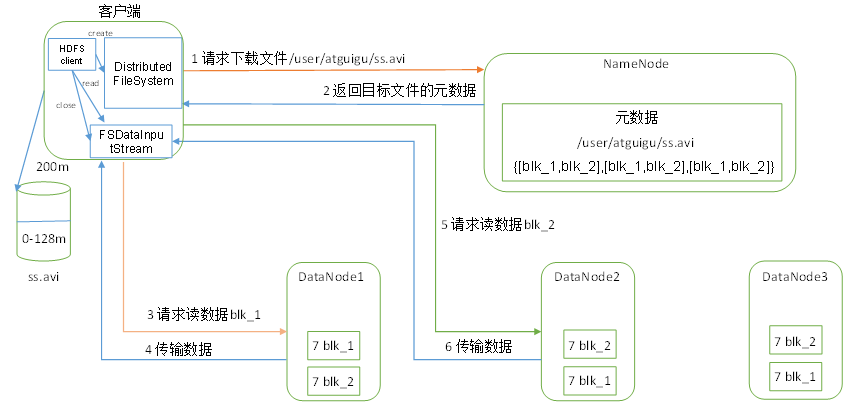
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
读写过程,数据完整性如何保持?
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
总的来说,HDFS 会对写入的数据计算校验和,并在读取数据时验证校验和。

若有收获,就点个赞吧
0 人点赞
